基于AUC及Q統(tǒng)計值的集成學習訓練方法
2019-08-01 01:54:12章寧陳欽
計算機應用 2019年4期
章寧 陳欽

摘 要:針對借貸過程中的信息不對稱問題,為更有效地整合不同的數(shù)據(jù)源和貸款違約預測模型,提出一種集成學習的訓練方法,使用AUC(Area Under Curve)值和Q統(tǒng)計值對學習器的準確性和多樣性進行度量,并實現(xiàn)了基于AUC和Q統(tǒng)計值的集成學習訓練算法(TABAQ)。基于個人對個(P2P)貸款數(shù)據(jù)進行實證分析,發(fā)現(xiàn)集成學習的效果與基學習器的準確性和多樣性關系密切,而與所集成的基學習器數(shù)量相關性較低,并且各種集成學習方法中統(tǒng)計集成表現(xiàn)最好。實驗還發(fā)現(xiàn),通過融合借款人端和投資人端的信息,可以有效地降低貸款違約預測中的信息不對稱性。TABAQ能有效發(fā)揮數(shù)據(jù)源融合和學習器集成兩方面的優(yōu)勢,在保持預測準確性穩(wěn)步提升的同時,預測的一類錯誤數(shù)量更是進一步下降了4.85%。
關鍵詞:集成學習;曲線下面積;Q統(tǒng)計值;貸款違約預測;信息不對稱性;個人對個人借貸
中圖分類號:TP181;TP391.77
文獻標志碼:A
文章編號:1001-9081(2019)04-0935-05
Abstract: Focusing on the information asymmetry problem in the process of lending, in order to integrate different data sources and loan default prediction models more effectively, an ensemble learning training method was proposed, which measured the accuracy and the diversity of learners by Area Under Curve (AUC) value and Q statistics, and an ensemble learning training method named TABAQ (Training Algorithm Based on AUC and Q statistics) was implemented. By empirical analyses based on Peer-to-Peer (P2P) loan data, it was found that the performance of ensemble learning was closely related to the accuracy and diversity of the base learners and had low correlation with the number of base learners, and statistical ensemble performed best in all ensemble learning methods. It was also found in the experiments that by integrating the information sources of borrower side and investor side, the information asymmetry in loan default prediction was effectively reduced. TABAQ can combine the advantages of both information sources fusion and ensemble learning. With the accuracy of prediction steadily improved, the number of forecast errors further reduced by 4.85%.
Key words: ensemble learning; Area Under Curve (AUC); Q statistics; loan default prediction; information asymmetry; Peer-to-Peer loan (P2P loan)
銀行信貸風險一般是指借款人違約不償還貸款的風險,相關研究包括借款人信用評級、貸款違約預測、金融欺詐分析等,其中貸款違約預測與保障信貸資金安全、防范投資損失直接相關,是銀行信貸風險研究中非常重要的子領域。數(shù)據(jù)統(tǒng)計和機器學習等方法和技術在該領域研究中得到了廣泛使用,但由于相關研究主要還是基于借款人提供的信息開展,實際效果受借貸雙方間信息不對稱性的限制較大。
個人對個人借貸(Peer-to-Peer Lending或Peer-to-Peer Loan)即個人對個人貸款,整個借貸交易過程都在電子平臺線上完成。除了借款人方提供的個人基本情況、經濟信用、借款用途等信息以外,交易平臺也會將投資人投標、貸款還款與違約、投資人收益等信息予以公開,以這些數(shù)據(jù)為基礎,逐步形成了基于投資人端信息的預測模型,這為研究如何降低借貸交易的信息不對稱性提供了基礎。
機器學習(Machine Learning, ML)主要研究計算機怎樣模擬或實現(xiàn)人類的學習行為,以獲取新的知識或技能,或者重新組織已有知識結構使之不斷改善自身性能。集成學習(Ensemble Learning, EL)屬于機器學習的一個重要分支,是指通過把多個學習器進行整合,獲得比單個學習器更好學習效果的方法,集成學習越來越廣泛地被運用在計算機視覺識別、信息安全、輔助醫(yī)療診斷、金融欺詐預防、銀行貸款違約預測等領域[1]。但在貸款違約預測的研究中,目前缺乏具體方法對集成學習構建、優(yōu)化和檢驗的全過程進行有效指導。
以P2P借貸為切入點,提出一種集成學習的訓練方法,將不同預測模型以及不同來源的數(shù)據(jù)信息進行集成融合,對于降低信息不對稱性、提升貸款違約預測準確性、減少可能的投資失誤和資金損失具有較大研究意義。
1?研究背景
1.1?傳統(tǒng)銀行貸款違約預測
傳統(tǒng)的貸款違約預測是指對銀行貸款是否會出現(xiàn)違約進行預判,是對銀行信貸業(yè)務中各類風險進行有效管理的基礎。20世紀90年代以前,該領域研究主要使用線性判別分析(Linear Discriminant Analysis,LDA)、邏輯回歸(Logistic Regression, LR)等數(shù)據(jù)統(tǒng)計方法和技術[2-3],進入20世紀90年代以后,各類機器學習算法,包括支持向量機(Support Vector Machine,SVM)、決策樹(Decision Tree,DT)、人工神經網(wǎng)絡(Artificial Neural Network, ANN)等[4-6],逐漸得到了較廣泛的應用。決策樹是目前使用最多的方法,文獻[7]認為基于C4.5算法的決策樹方法較之基于ID3算法表現(xiàn)更優(yōu),而如果將決策樹與ANN方法進行集成,貸款違約預測的準確度將獲得進一步提升[8]。
但從總體上來說,目前還沒有發(fā)現(xiàn)某一種單一的方法,可以在所有數(shù)據(jù)集上都保持最好的預測表現(xiàn)。從2010年以后,集成學習由于具有綜合多種方法優(yōu)勢的特點,逐步成為了信用風險評估領域研究的熱點方向[9-10]。
1.2?P2P貸款違約預測
目前對P2P貸款的違約預測方法主要分為基于借款人端信息和基于投資人端信息兩類。前一類方法與傳統(tǒng)銀行貸款違約預測方法類似,基于借款人提供的各類信息對貸款違約概率進行預測,主要算法包括線性判別分析[11]、決策樹[12]、邏輯回歸[13-14]、支持向量機[15]、貝葉斯網(wǎng)絡(Bayesian Network)[15]等,這些研究發(fā)現(xiàn)借款總期數(shù)、借款金額、借款人收入、借款人負債收入比、借款人信用級別都與貸款是否違約有較強關聯(lián)性。
針對P2P貸款的借貸雙方信息不對稱性問題[16-17],文獻[18-19]提出利用貸款投資人端信息,構建基于投資人投資穩(wěn)定性的P2P貸款違約預測(Lender Stability,LS)模型;文獻[20]則基于投資效用理論,利用投資人歷史收益率、貸款利率出價等信息,使用TF-IDF算法構造逆向比例權重因子,建立了優(yōu)化的基于投資人效用的貸款違約預測模型(Lender Utility2, LU2),并取得了更為準確和穩(wěn)定的預測效果。
1.3?集成學習
集成學習也被稱為多分類器系統(tǒng)(Multiple Classifier System, MCS),一般來說機器學習中的學習器(Learner)通常是由一個現(xiàn)有的學習算法從訓練數(shù)據(jù)中產生,比如決策樹、支持向量機、神經網(wǎng)絡等,而集成學習則通過某種規(guī)則,將多個學習器進行組合,集成產生新的學習器。
集成學習中被集成的學習器稱為基學習器(Base Learner),將單一算法訓練而成的基學習器進行集成的方法被稱為同質集成(Homogeneous Ensemble);與之對應,若集成包含了多種不同類型算法生成的基學習器,則被稱為異質集成(Heterogeneous Ensemble)。異質集成中基學習器也被稱為個體學習器(Individual Learner)或組件學習器(Component Leaner)。為使最終得到的學習器表現(xiàn)更好,除了提高基學習器的準確性以外,提高基學習器之間的差異性(Diversity)也是關鍵因素之一[21]。
集成學習的過程主要由兩步組成:一是訓練生成基學習器,二是將這些基學習器進行集成組合。按照基學習器的不同生成方法,可將集成學習分為四類[22]:一是通過重采樣或復制等方法改變訓練數(shù)據(jù),如Bagging、Boosting;二是通過選取特征值(Feature)對訓練數(shù)據(jù)進行變化,如隨機子空間(Random Subspace,RS)、隨機森林(Random Forest,RF);三是對基學習器的配置參數(shù)進行變化,如K近鄰(K Nearest Neighbors,KNN)算法分類器中的核函數(shù)、神經網(wǎng)絡調的撲結構;四是對基學習器的算法類型進行多樣化,即對不同類型的基學習器進行集成。
按照基學習器組合的不同方式,集成學習又可以被分為線性集成、非線性集成,以及統(tǒng)計集成(或智能集成)三類。其中線性集成指通過加和或者取平均的方式得到最終結果,非線性集成則指通過多數(shù)投票、加權計算等方式獲得最終結果,而統(tǒng)計集成(或智能集成)方式則是采取回歸預測、貝葉斯算法、神經網(wǎng)絡等方法計算最終結果[23]。
2?貸款違約預測的集成學習訓練方法
2.1?總體研究框架
本文的總體研究框架主要包括四部分:1)訓練基學習器。2)選擇基學習器進入集成過程。3)對基學習器進行集成,根據(jù)集成方法不同可分為兩類操作:一類是針對線性集成、非線性集成方法,對基學習器結果的組合參數(shù)進行調整和優(yōu)化;另一類則對應統(tǒng)計集成方法,在基學習器之上進行多層模型學習。4)對生成的集成學習器進行測試檢驗,并根據(jù)結果決定是否繼續(xù)進行集成。
2.2?基學習器篩選
集成學習通過找到準確且互補的基分類器,并對其進行集成來提高學習器的泛化能力,從而獲得更優(yōu)的學習效果。故需要找到合適的指標,對基學習器的準確性和多樣性進行度量,從而篩選出預測準確性高,且有較強的多樣性和互補性的基學習器。
2.2.1?基學習器的預測準確性度量
ROC(Receiver Operating Characteristic)曲線和AUC(Area Under Curve)值常被用來評價一個二值分類器(Binary Classifier)的優(yōu)劣。ROC曲線最早運用在軍事上,后來逐漸運用到醫(yī)學領域,再被運用到統(tǒng)計分析研究中,可準確反映某分析方法特異性和敏感性的關系[24]。
ROC曲線以下部分的面積即為AUC,AUC值越高表示模型預測效果越好,它可以被解釋為任取一對(正、負)樣本,正樣本的預測值大于負樣本預測值的概率[25]。AUC值具有一致性和穩(wěn)定性的特點,不受判斷閾值選擇的影響,而且即使測試數(shù)據(jù)集正負樣本分布不平衡也能保持穩(wěn)定,故本文使用預測AUC值作為各學習器準確性的度量指標。
2.2.2?基學習器之間的多樣性度量
基學習器之間的多樣性(Diversity)與其相互之間的互補性緊密相關,多樣性越強的基學習器,集成以后模型的泛化能力越強,目前越來越多的研究已經把注意力放到了如何更準確地對分類器之間的多樣性進行度量[21]。
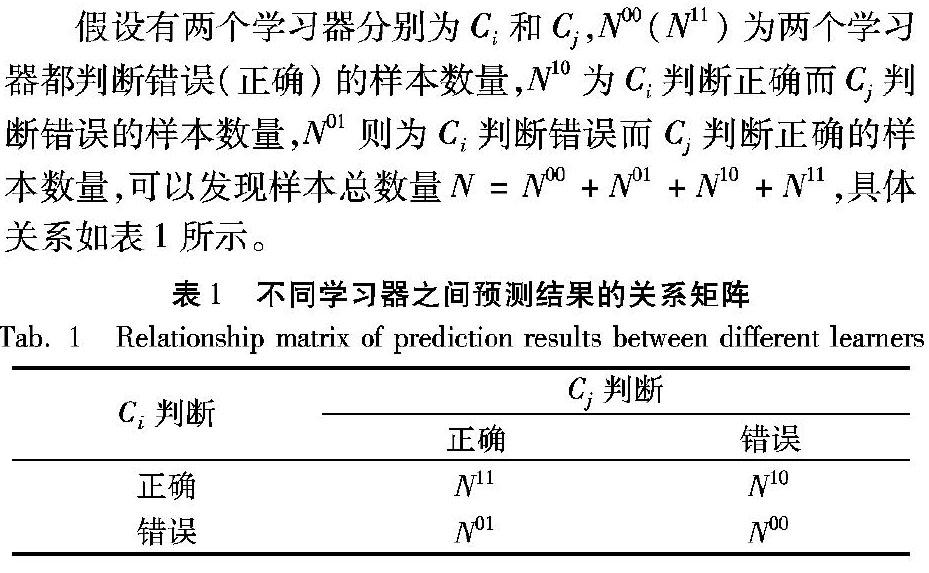
假設有兩個學習器分別為Ci和Cj,N00(N11)為兩個學習器都判斷錯誤(正確)的樣本數(shù)量,N10為Ci判斷正確而Cj判斷錯誤的樣本數(shù)量,N01則為Ci判斷錯誤而Cj判斷正確的樣本數(shù)量,可以發(fā)現(xiàn)樣本總數(shù)量N=N00+N01+N10+N11,具體關系如表1所示。
當前研究中對不同學習器之間差異性的度量方法主要有四種,分別為Q統(tǒng)計、相關系數(shù)ρ、不一致度量(disagreement measure, dis)、雙次失敗度量(Double-Fault measure, DF)。
1)Q統(tǒng)計值(Q statistics)。
Q統(tǒng)計值源自統(tǒng)計學領域,計算方法如式(1)所示,其值為-1~1。如果兩個分類器總是同時正確或錯誤分類,則Qi, j=1,此時兩個學習器完全相同,相互之間的差異性最小。反之,如果兩個分類器在每個樣例上分類結果都相反,則Qi, j=-1,這種情況兩個學習器之間差異性最高。
2)相關系數(shù)ρ。
兩個學習器Ci和Cj之間相關系數(shù)ρ計算方法見式(2), ρ與Q統(tǒng)計值具有相同的符號,代表的意義也類似,即值越小則學習器之間的差異性越大。
3)不一致度量dis。
不一致度量dis計算方法如式(3),其關注分類器Ci和Cj分類結果差異的樣本比例,這個比例越高,兩個分類器之間差異性越高;反之則差異性越低。
4)雙次失敗度量DF。
雙次失敗度量DF的計算方法見式(4),其值為兩個學習器Ci和Cj在相同的樣例上判別錯誤的比例,可以認為這個比例越高,兩個學習器越容易犯同樣的錯誤,其集成以后泛化性也越低。
總體看來,Q統(tǒng)計指標的意義更加清晰明確,且計算過程相比相關系數(shù)ρ更為簡便,故本文使用Q統(tǒng)計值作為各學習器之間差異性的度量指標。
2.3?集成學習訓練
當前集成學習的訓練方法主要可分為線性集成、非線性集成、統(tǒng)計集成三種。前兩種方法都是對基學習器的預測結果進行直接組合,區(qū)別只是在于對各個基學習器結果的權重因子計算方法不同;第三種方法則是基于各基學習器的輸出結果之上,使用其他模型進行多次學習,并生成獲得新的學習器。
2.3.1?線性集成及非線性集成
由于貸款違約預測的結果是一個連續(xù)性的概率值,故本文的線性集成采取平均值法(AVerage, AV),即通過計算各基學習器所預測貸款違約概率的算術平均值得到集成后的違約概率 pAV,具體如式(5)所示:
其中:m為參與集成的基學習器數(shù); pi為基學習器Ci預測的貸款違約概率。
而非線性集成方法需要為各基學習器的輸出結果設置不同的權重因子(Weight Factor, WF),各基學習器權重因子與其預測準確性相關[26]。由于AUC值具有一致性和穩(wěn)定性特點,本文使用基學習器的預測結果AUC值代表其預測準確性,并以此計算其權重因子,集成后的違約概率pWF如式(6)所示:
2.3.2?統(tǒng)計學習集成
二層學習(Double-level Learning,DL)集成是統(tǒng)計集成的一種,是指以基學習器結果作為輸入,通過第二層模型學習訓練獲得集成學習器的方法。本文選擇使用邏輯回歸(LR)作為二層學習集成的模型。二層學習集成方法的貸款違約概率 pDL計算方法如式(7)所示:
2.4?集成學習器的預測效果檢驗
對于訓練獲得的集成學習器,將從預測準確性和錯誤情況兩方面進行檢驗,其中準確性使用預測結果的AUC值進行度量。
學習器在預測時出現(xiàn)的錯誤可分為一類錯誤和二類錯誤。前者是指將實際違約貸款判別為正常,后者則是將未違約貸款判別為違約。一類錯誤可能造成對違約貸款的投資失誤,對資金安全影響更大。本文使用一類錯誤數(shù)量作為度量學習器犯錯情況的指標,該數(shù)值越高,則學習器預測失誤越嚴重。
2.5?算法實現(xiàn)
按照總體研究框架,本文構建了基于AUC和Q統(tǒng)計值的集成學習訓練算法(Training Algorithm Based on AUC and Q statistics, TABAQ),覆蓋集成學習從構造、篩選、訓練、檢驗和持續(xù)優(yōu)化的全過程。
算法說明:在所有備選基學習器中,選擇分類準確性最高,且差異性最大的基學習器作為初始集成學習器,然后循環(huán)篩選剩余的基學習器進入集成學習過程,直到集成后學習器的準確性不再提升,或者所有基學習器都被集成后為止。
3?P2P貸款數(shù)據(jù)實證分析
基于實際P2P貸款數(shù)據(jù),使用本文算法TABAQ來訓練并生成集成學習器,并基于此對單一數(shù)據(jù)源與融合數(shù)據(jù)源、單學習器與集成學習器的預測結果分別進行了實證對比分析。
實證分析主要分為三部分:1)訓練基學習器,設置實驗對比基準,并對不同基學習器之間差異性進行對比分析;2)使用TABAQ訓練生成集成學習器,并對不同集成方法、集成參數(shù)對集成學習效果的影響進行對比分析;3)對單信息源與多信息源、單學習器與集成學習器的預測結果進行對比分析。
實驗使用到的基學習器共5類,覆蓋了基于借款人端信息和投資人端信息的兩類預測模型,前者包括邏輯回歸(LR)、支持向量機(SVM)、決策樹(DT),后者包括投資人穩(wěn)定性(LS)和投資人效用(LU2)。集成學習方法則選擇平均值法(AV)、權重因子(WF)和二層學習(DL)三種。
3.1?實驗數(shù)據(jù)說明
實證數(shù)據(jù)來自P2P借貸平臺Prosper,使用的樣本屬性在借款人端包括借款人信用評級分、借款人預期損失率、借款利率、借款人每月還款金額、借款人借款收入比、借款人是否擁有住房等,投資人端則包括投資總金額、歷史投資違約情況、貸款出價利率、貸款出資額等。
實證數(shù)據(jù)分別被劃分為訓練數(shù)據(jù)集(Train Dataset)、驗證數(shù)據(jù)集(Verification Dataset)和測試數(shù)據(jù)集(Test Dataset)。其中:測試數(shù)據(jù)集用于訓練基學習器;驗證數(shù)據(jù)集用于計算基學習器的AUC值、一類錯誤數(shù)量、相互間的差異性Q統(tǒng)計值等數(shù)值,以訓練獲得集成學習的參數(shù);測試數(shù)據(jù)集則用于對各種基學習器和集成學習器的預測效果進行檢測和對比。
各數(shù)據(jù)集通過放回取樣的方式從貸款數(shù)據(jù)中隨機選取,每個數(shù)據(jù)集包含的貸款數(shù)量都為1000筆,共抽取10個數(shù)據(jù)集,各數(shù)據(jù)集輪流用于訓練、驗證和測試。進行10次實驗,將各輪次實驗結果取平均值用作對比分析。
3.2?實驗結果分析
3.2.1?基學習器之間多樣性分析
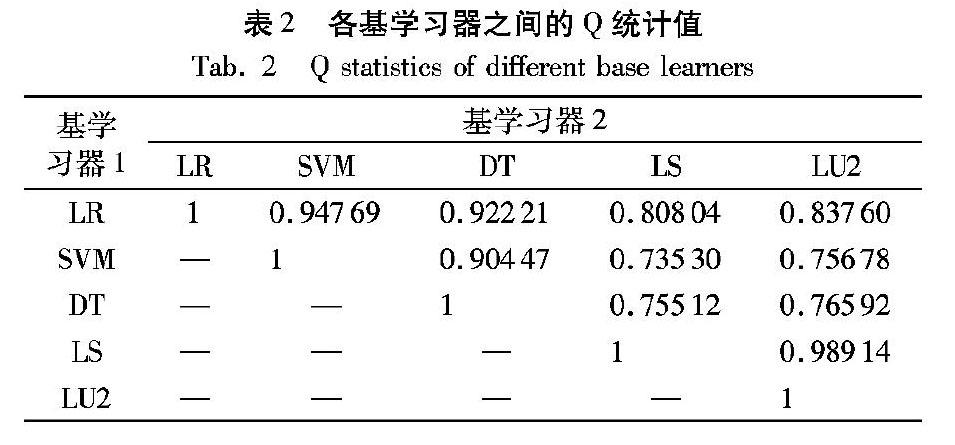
表2為各基學習器間的差異性Q統(tǒng)計值,可以發(fā)現(xiàn):基于不同信息源的學習器之間Q統(tǒng)計值較低,如基于借款人端信息的LR、SVM、DT學習器,與基于投資人端信息的LS和LU2學習器之間,說明這些基學習器之間存在較強互補性。而基于相同信息源的模型之間Q統(tǒng)計值則都較高,表示較低的多樣性。
3.2.2?不同集成方法的比較
三種集成方法訓練獲得的學習器的預測結果見表3,其中,Error-I為預測結果中的一類錯誤數(shù)量。可以看到屬于統(tǒng)計集成的二層學習方法(DL)表現(xiàn)更好,取得了更高的AUC值以及更低的一類錯誤數(shù)量,而平均值方法(AV)和權重因子方法(WF)則表現(xiàn)欠佳,訓練獲得的集成學習器預測效果甚至低于單個基學習器。
在集成更多的基學習器后,并不能確保獲得更好的預測效果,在集成學習訓練過程中,需要考慮“更多并非更好”的原則,避免盲目增加基學習器對實際效果產生負面影響。
3.2.3?模型預測結果綜合對比分析
不同信息源、不同學習器預測結果的綜合對比見表4,其中BL列表示是單個基學習器(Base Learner),EL表示的是集成學習器(Ensemble Learner),總體上來看通過融合數(shù)據(jù)源和采取集成學習的方法,對提升預測效果都有幫助。從不同的數(shù)據(jù)源來看,基于投資人端信息的學習器獲得了比基于借款人端信息學習器更好的效果,即更高的預測AUC值及更低的一類錯誤數(shù)量,這說明由于不存在提供虛假信息的道德風險,投資人端的信息對于貸款違約預測更有幫助。在借款人端信息的基礎之上,通過融入投資人端的信息,預測AUC值獲得了較大提升,而預測的一類錯誤數(shù)量則更少,這證明引入投資人端的信息,對于降低信息不對稱性、提高預測準確性,特別是降低一類錯誤造成的投資失誤有幫助。
無論是基于借款人端的信息源,還是投資人端的信息源,集成學習方法總體上都取得了比單學習器更好的預測效果。
需要關注的一點是基于投資人端信息的基學習器經過集成學習以后,預測AUC值降低了0.00054,這應該與基學習器之間的多樣性不足有關。
從表2可以發(fā)現(xiàn)該類基學習器之間的差異性Q統(tǒng)計值非常高,說明基學習器之間的多樣性極低,這證明了基學習器的多樣性與集成學習效果之間的正相關性,集成學習過程中如果引入的基學習器過分相似,泛化性不足,最終的預測效果可能受到負面影響。
同時采取融合信息源和集成學習方法后,取得了最優(yōu)的預測效果,預測AUC值保持穩(wěn)步提升的同時,一類錯誤的數(shù)量更是進一步降低為86.3,相對于單學習器最優(yōu)的90.7進一步下降了4.85%。這說明TABAQ能夠有效地將多信息源融合與多學習器集成進行結合,同時發(fā)揮雙方面的優(yōu)勢作用,降低信息不對稱性,提升學習器的準確性,為提高貸款違約的預測效果、避免投資失誤、保障資金安全提供了有效支持。
4?結語
本文基于預測AUC值及差異性Q統(tǒng)計值,提出了一種集成學習的訓練算法TABAQ。使用P2P貸款數(shù)據(jù)進行實證分析發(fā)現(xiàn),使用統(tǒng)計集成的方法可以獲得比單個學習器更好的預測效果。集成學習的效果與基學習器的準確性和多樣性關系密切,但與被集成基學習器數(shù)量的相關性較低,集成了過多、過于相似的基學習器,可能會對集成學習的泛化性造成負面影響。通過融合投資人端的信息數(shù)據(jù),能夠有效地降低貸款違約預測中的信息不對稱性問題。TABAQ能結合多數(shù)據(jù)源融合和多學習器集成的雙方面優(yōu)勢,預測的準確性持續(xù)提升,同時一類錯誤的數(shù)量相對單模型、單數(shù)據(jù)源、融合數(shù)據(jù)源等都更低。后續(xù)可以考慮更加準確地量化和度量不同數(shù)據(jù)源信息對預測效果的影響程度,并基于此對優(yōu)化集成學習過程中的各類參數(shù)開展進一步研究。
參考文獻(References)
[1] ZHOU X. Ensemble Methods: Foundations and Algorithms [M]. Boca Racton: CRC Press, 2012: 15-17.
[2] DIMITRAS A I, ZANAKIS S H, ZOPOUNIDIS C. A survey of business failures with an emphasis on prediction methods and industrial applications[J]. European Journal of Operational Research, 1996, 90(3): 487-513.
[3] HAND D J, HENLEY W E. Statistical classification methods in consumer credit scoring: a review[J]. Journal of the Royal Statistical Society, 1997, 160(3): 523-541.
[4] MIN J H, LEE Y C. Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters[J]. Expert Systems with Applications, 2005, 28(4): 603-614.
[5] LI H, SUN J, WU J. Predicting business failure using classification and regression tree: an empirical comparison with popular classical statistical methods and top classification mining methods[J]. Expert Systems with Applications, 2010, 37(8): 5895-5904.
[6] CHARALAMBOUS C, CHARITOU A, KAOUROU F. Application of feature extractive algorithm to bankruptcy prediction[C]// Proceedings of the 2000 IEEE-Inns-Enns International Joint Conference on Neural Networks. Washington, DC: IEEE Computer Society, 2000: 5303.
[7] AMIN R K, INDWIARTI, SIBARONI Y. Implementation of decision tree using C4.5 algorithm in decision making of loan application by debtor (case study: bank pasar of Yogyakarta special region) [C]// Proceedings of the 2015 International Conference on Information and Communication Technology. Piscataway, NJ: IEEE, 2015: 75-80.
[8] GENG R, BOSE I, CHEN X. Prediction of financial distress: an empirical study of listed Chinese companies using data mining[J]. European Journal of Operational Research, 2015, 241(1): 236-247.
[9] VERIKAS A, KALSYTE Z, BACAUSKIENE M, et al. Hybrid and ensemble-based soft computing techniques in bankruptcy prediction: a survey[J]. Soft Computing, 2010, 14(9): 995-1010.
[10] JADHAV S, HE H, JENKINS K W. An academic review: applications of data mining techniques in finance industry[J]. International Journal of Soft Computing and Artificial Intelligence 2016, 4(1): 79-95.
[11] ERGER S C, GLEISNER F. Emergence of financial intermediaries in electronic markets: the case of online P2P lending[J]. Business Research, 2010, 2(1): 39-65.
[12] JIN Y, ZHU Y. A data-driven approach to predict default risk of loan for online Peer-to-Peer (P2P) lending[C]// Proceedings of the Fifth International Conference on Communication Systems and Network Technologies. Piscataway, NJ: IEEE, 2015: 609-613.
[13] EMEKTER R, TU Y. Evaluating credit risk and loan performance in online Peer-to-Peer (P2P) lending[J]. Applied Economics, 2015, 47(1): 54-70.
[14] 談超, 孫本芝, 王冀寧. P2P網(wǎng)絡借貸平臺中的逾期行為研究[J]. 財會通訊, 2015(2): 49-51. (TAN C, SUN B Z, WANG J N. Research on overdue behavior in P2P lending platform[J]. Communication of Finance and Accounting, 2015(2): 49-51.)
[15] 鄧帆帆, 薛菁, 閆海鑫.商業(yè)銀行參與P2P網(wǎng)絡借貸的路徑分析及建議——基于貝葉斯網(wǎng)絡投資模型的測算結果[J]. 集美大學學報(哲學社會科學版), 2015, 18(2): 53-58. (DENG F F, XUE J, YAN H X. Analysis and suggestions of commercial banks participation in P2P lending — based on the measurement results of Bayesian network model[J]. Journal of Jimei University (Philosophy and Social Sciences), 2015, 18(2): 53-58.)
[16] WANG P, ZHENG H, CHEN D, et al. Exploring the critical factors influencing online lending intentions[J]. Financial Innovation, 2015, 1(1): 1-11.
[17] EVERETT C R. Information asymmetry in relationship versus transactional debt markets: evidence from peer-to-peer lending[D]. West Lafayette: Purdue University, 2011: 63-66.
[18] LUO C, XIONG H, ZHOU W, et al. Enhancing investment decisions in P2P lending: an investor composition perspective[C]// Proceedings of the 2011 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2011: 292-300.
[19] ZHAO H, WU L, LIU Q, et al. Investment recommendation in P2P lending: a portfolio perspective with risk management[C]// Proceedings of the 2014 IEEE International Conference on Data Mining. Piscataway, NJ: IEEE, 2014: 1109-1114.
[20] 章寧, 陳欽. 基于TF-IDF算法的P2P貸款違約預測模型[J]. 計算機應用, 2018, 38(10): 3042-3047. (ZHANG N, CHEN Q. P2P loan default prediction model based on TF-IDF algorithm[J]. Journal of Computer Applications, 2018, 38(10): 3042-3047.)
[21] KUNCHEVA L I, WHITAKER C J. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy[J]. Machine Learning, 2003, 51(2): 181-207.
[22] CHEN N, RIBEIRO B, AN C. A Financial credit risk assessment: a recent review[J]. Artificial Intelligence Review, 2016, 5(1): 1-23.
[23] CANUTO A M P, ABREU M C C, OLIVEIRA L D M, et al. Investigating the influence of the choice of the ensemble members in accuracy and diversity of selection-based and fusion-based methods for ensembles[J]. Pattern Recognition Letters, 2007, 28(4): 472-486.
[24] FAWCETT T. An introduction to ROC analysis[J]. Pattern Recognition Letters, 2006, 27(8): 861-874.
[25] MYERSON J, GREEN L, WARUSAWITHARANA M, et al. Area under the curve as a measure of discounting [J]. Journal of the Experimental Analysis of Behavior, 2001, 76(2): 235-243.
[26] MEYNET J, THIRAN J P. Information theoretic combination of classifiers with application to AdaBoost[C]// Proceedings of the 2007 International Conference on Multiple Classifier Systems. Berlin: Springer, 2007: 171-179.
