荷蘭開放大學的大數據多模態學習分析研究新進展
2019-08-13 09:09:31張楠
中國信息技術教育 2019年14期
張楠
● 引言
人們今天已經熟知大數據具有4V屬性,其中一個屬性就是數據的半結構化和非結構化,因此解決這一領域問題的多模態數據分析研究越來越受到人們的關注。荷蘭開放大學維爾滕學院的丹尼爾·迪米特里博士一直致力于研究學習分析和人工智能。維爾滕學院是荷蘭開放大學的學習、教學和技術研究中心,該研究中心以科學的、高質量的、實踐性的教育研究為核心,以提高教育質量為目標(該目標有助于彌合理論與實踐之間的鴻溝),成為(高等)教育的合作伙伴,成為(國際)國家級高質量研究機構。丹尼爾·迪米特里博士及其他幾名相關研究人員利用多模態數據對實驗進行了文獻調查,構建了多模態學習分析這一新興研究領域,介紹了用于多模態學習分析領域文獻調查的分類框架、有關學習的多模態數據的分類,以及多模態學習分析模型。
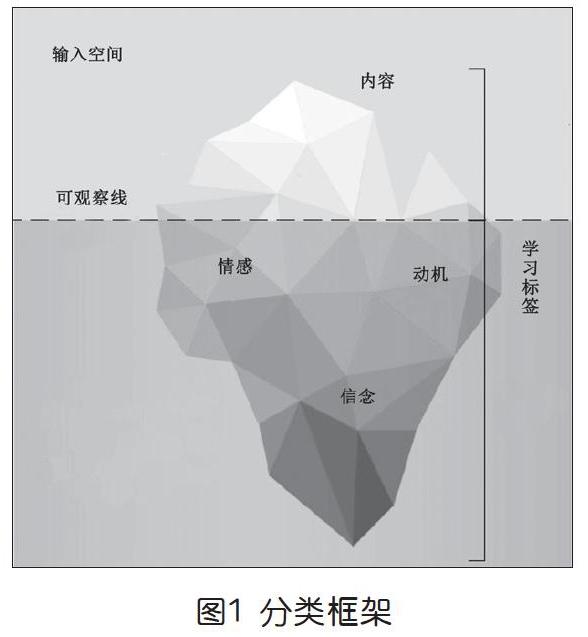
● 多模態學習分類框架
在學習過程中,學習者的行為屬性等是能夠通過傳感器直接觀察和測量的,但學習者的認知、情緒這些潛在的屬性,無法直接由傳感器測量,只能對其推斷,一些文獻調查將這些方面命名為輸入空間和假設空間(如圖1)。在人類學習中,輸入空間包括學習者的行為和學習情境,這方面的數據雖然可以被傳感器自動捕獲,但傳感器無法對這些數據作出解釋或賦予其意義。假設空間包含了一系列可能的解釋,即傳感器雖然不能直接觀察到屬性,但也可以利用數據顯示。假設空間包括對多模態數據的語義解釋,而這些數據是基于心理和學習相關的結構,如情緒、信念、動機、認知或學習結果,其屬性屬于學習者的意義形成過程,在課堂活動中,教育者和研究人員是看不到這一過程的。
輸入空間和假設空間在概念上由可觀察線分隔開,從一個通用傳感器的角度來看,“水線以上”的部分是顯而易見的,“水線以下”的屬性需要多層次解釋,同時還取決于屬性與可觀察線的距離有多深。另外,可觀察與不可觀察之間的區別是概念性的,在實踐中可能會有所不同。
● 用于學習的多模態數據的分類
多模態學習數據分類是組織可觀測模態(輸入空間)復雜性的第一種方法,可由傳感器監測,并在調查研究中被提及。這種分類并不是對學習模式的詳盡分類,也不是對不同傳感器類型的技術審查。對于后者,我們參考Schneider等人的綜述,該綜述提供了可應用于教育領域的傳感器的廣泛列表。
綜述從通用傳感器的角度給出了分類方法(如圖2),其基本思想是傳感器可以監視一個(或多個)模態。在這里,我們將情態作為一種可測量的屬性,屬于身體或上下文的特定部分。模態通過信號通道進行通信,信號通道連續采樣導致一個(或多個)模態的縱向收集。例如,麥克風(傳感器)可以采樣語音(通道)來檢測語音(模態),或者攝像機可以同時跟蹤語音、動作和面部特征,從而提供語音、全身運動(GBMs)和面部表情。為了概述所提出的分類,我們分析了兩個主要的分支:行為運動模態和行為生理學模態。
運動模態可分為與“身體”或“頭”有關的模態,其中身體包括軀干、腿、手臂和手。來自攝像機的軀干的運動可以提供GBM,而腿的運動可以通過步數來跟蹤,并為身體活動提供良好的指標,手臂和手則是更有意義的身體部位,其運動也可以被攝像機檢測到,在這種情況下,一種流行的選擇是Microsoft Kinect用于手勢和身體姿勢的識別,尤其是那些注重表達技巧的研究選擇了這種解決方案。另一種選擇是可以用肌電圖傳感器(EMG)跟蹤手臂運動和手勢。最后,手作為身體的一部分,可以提供對學習者活動的最好的洞察。
頭部運動模式包括面部表情分析、眼球運動和語言分析。在情感計算研究中,面部表情在情感識別學習中被高度研究,也在多模態人機交互實驗中得到了廣泛應用。眼動跟蹤通常被用作學習者注意力的指標,也被用于多模態數據集。而語音的分析的范圍是從副語言分析(如說話時間、發音關鍵字或韻律特征)到學生與教師互動等對話環境中口語單詞的實際識別。
生理形態也可分為相應的身體部位,心臟、大腦和皮膚是獲得生理信息的主要器官。目前,較為流行的檢測大腦活動的方法是腦電圖(EEG),它可以測量大腦內部電位的差異。Prietoetal將EEG與眼動跟蹤相結合,進而從教師分析的角度預測互動的社會層面和具體的教學活動。心臟活動的測量則可以采用不同的技術來計算,如心率和HRV——心電圖(ECG)或光容積描記術。皮膚電反應(GSR),也稱為皮膚電活動(EDA),用來測量皮膚電導率。另外,如果身體受到生理上的刺激,皮膚電導就會增加。
● 假設空間分類表
下頁表總結了在選擇的使用多模態數據的研究中發現的學習理論。該表根據所選擇的理論結構、假設空間規范、數據表示類型和標注方法對研究進行分類,為研究提供參考。
使用多模態數據的最先進的研究側重于預測情緒。情緒被認為是身體生理變化的表現,隨著對特定刺激的反應而變化。根據體細胞標記假說,生理變化發生在身體中,當它們被解釋為情緒時,會傳遞給大腦,進而人們通過自主神經系統反應來適應環境和情感刺激。因此,情緒被認為在學習中具有重要的作用,學習過程中典型的情緒是困惑、無聊、投入、好奇、興趣、驚喜、喜悅、焦慮和挫折。

心流是一種運行的心理狀態,當個人沉浸在精力充沛的專注、享受和充分參與當前活動的狀態中時,就會體驗到這種狀態。它是由內在動機而不是外在獎勵來滿足,當任務的難度和個人對給定活動的準備程度達到平衡時,這種流動就會自然發生。
● 多模態學習分析模型
多模態數據分析模型(MLeAM)引入了第二個正交維——混合實線。混合現實被定義為物理世界和數字世界相遇的連續空間。我們相信物理世界和數字世界的分離有助于理解智能計算機代理和數字技術給學習過程帶來的好處。學習者的行為和反饋傳遞發生在物理世界,而模態的多模態數據表示及其處理和注釋發生在數字世界。綜述中,可觀測線和混合實線之間的交集創建了四個象限(如圖3)。這些象限之間的轉換由生成結果的過程“P”指導。模型從頂部中心開始按順時針方向迭代。
1.從傳感器采集到多模態數據
模型從(P1)傳感器捕獲開始,即自動采樣傳感器從幾個模式中獲得記錄數據,其選擇的模式與輸入空間的屬性有關,如學習者的身體位置、注視方向和面部表情,且這些數據可以從學習者的行為和活動或學習環境中提取,無論哪種情況,模式都存在于物質世界中。P1不斷地將不同的模態轉換為它們的數字表示,即(R1)多模態數據的多形式數據流。多模態數據流的截線對應于學習者在特定時間點的學習上下文中的數字快照。在設計P1實現時,有三個重要方面需要考慮:第一,使用的輸入空間的定義——模式的啟發式選擇及其數據表示;第二,確定最適當的傳感器,以便為具體的學習方案捕捉選定的模式;第三,傳感器體系結構的設計和實現,用于從多個傳感器收集和序列化數據流的硬件和軟件基礎設施。傳感器體系結構的設計必須考慮幾個技術方面,包括傳感器網絡工程、原始數據同步、融合技術和用于傳感器數據持久性的數據存儲邏輯。
2.從注釋到學習標簽
第二個過程是(P2)注釋,這是一個由專家或學習者人為驅動的重復過程。P2的目標是根據一些預定義的評估方案,用人類的判斷來豐富低語義多模態數據。該方案基于假設空間,即機器學習算法自動從多模態數據中推導出的不可觀測的解釋。P2可以被看作是一個學習任務與一些學習目標之間的評估,并通過三角剖分實現,即“法官”首先接觸到一些關于學習任務的人類可解釋的證據(如視頻或直接觀察),接著將一些(R2)學習標簽分配給多模態數據的時間段。這個過程P2允許為原始數據的某個時間間隔提供一些意義。與P1類似,P2需要定義所有可能的學習標簽,該任務對應于定義假設空間及其數據表示,同時,它還需要設計由報告工具和注釋過程組成的注釋策略。
3.從機器學習到預測
第三個過程是(P3)機器學習。監督機器學習的目的是從觀察到的(R1)多模態數據和手工標注的(R2)學習標簽中學習統計模型(函數);對未來未觀察到的數據進行歸納,生成類似結構的(R3)預測。核心的機器學習任務可以用數學形式表達,計算一個函數:y=f(X)+ε。
X為多模態觀測,輸入函數f。 X為n個屬性向量,由多種學習模式導出,X的所有可能的值組合構成了輸入空間,即f的定義域。
y是學習標簽(s),它將每個輸入的觀察結果定位到假設空間,即所有可能學習標簽的f的范圍。
函數f是一個泛化的關系,觀察X和y+學習標簽一些誤差項ε。
給出一種新的多通道觀測Xnew,預測計算學習任務對應的標簽(s)ynew=f(Xnew)+ε。
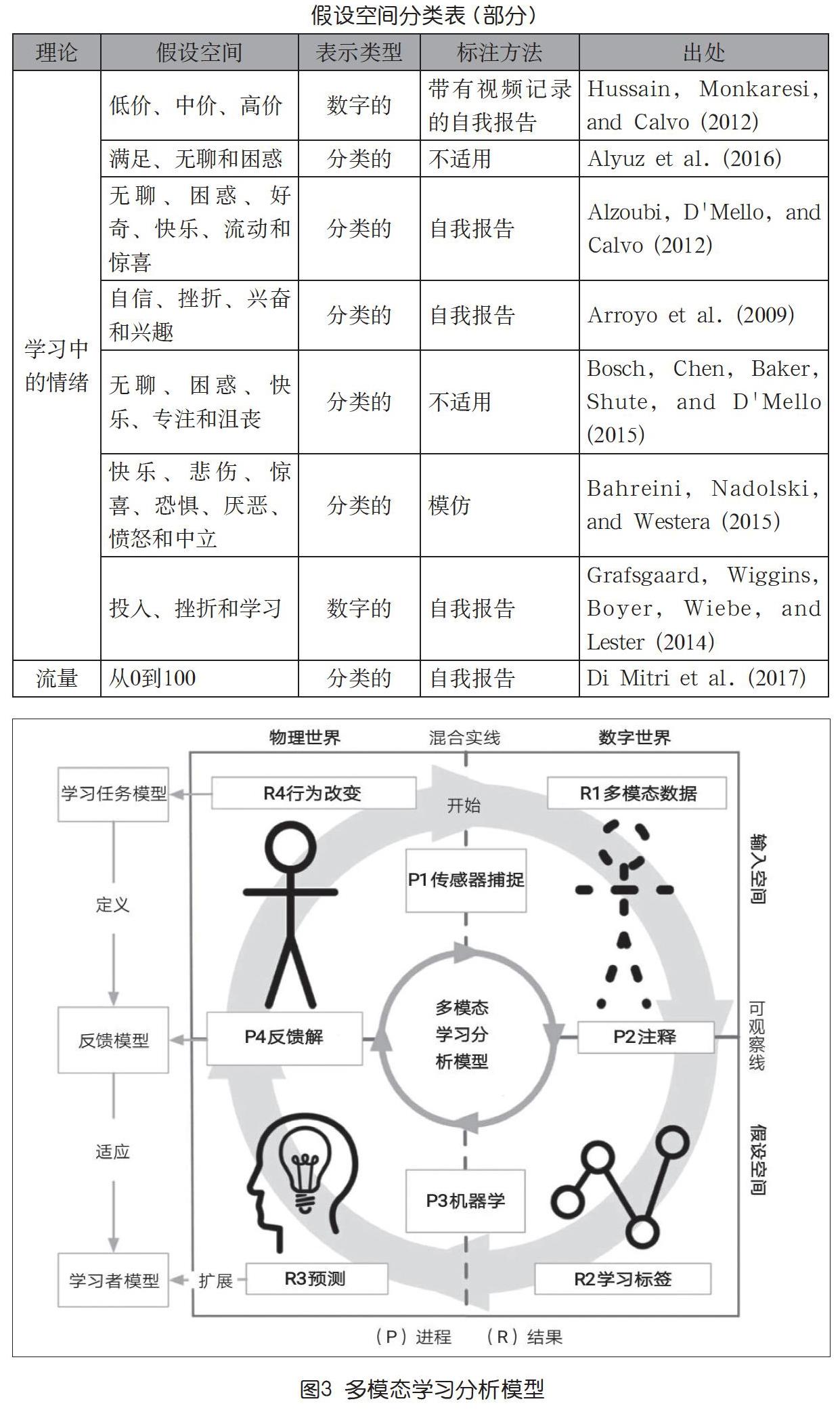
P3還包括以下迭代步驟:①預處理——重采樣,處理丟失的數據,使模型符合數據;②后期處理——選擇相關屬性,調整參數,驗證模型對新數據的通用性;③診斷——獲得相關性,以確定每個屬性在預測學習標簽方面的重要性。如果對所得到的模型進行合理的精度訓練,系統能夠在不可見的多模態數據中預測學習標簽。這個預測是一個機器輔助估計學習者在學習過程中的立場。P3使用機器將必須由人類驅動的注釋過程自動化。預測可以用來豐富學習者模型,為學習者提供更具適應性的反饋模型,并推動他們走向積極的行為改變。
4.從反饋解釋到行為改變
最后一個過程是(P4)反饋解釋,關閉返回給學習者的由機器驅動的反饋回路。P4的目的是利用對多模態數據的支持,并導致R4行為變化。P4需要預先設計好反饋模型,反饋模型高度依賴于學習活動,并由任務模型定義。MLeAM不處理任何反饋維度,也不提供依賴于學習活動的有效反饋策略。盡管如此,MLeAM可以與不同的反饋模型結合使用,并結合已經分析過的有關學習者行為和上下文的相關信息。另外,根據通過MLeAM得到的預測,學習者還可以得到不同形式的反饋,且反饋設計應能夠促進反饋解釋的過程,引導學習者產生新的學習行為。
本文受到東北師范大學教師教育研究基金重點課題“基于數據挖掘的教師專業發展成長軌跡研究”,吉林省教育廳“十三五”社會科學研究規劃項目重點課題“基于數據挖掘的卓越教師能力結構與培訓研究”及政府委托項目“長春市二道區集優化辦學UGS合作模式服務項目”資助。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
廣西科技大學學報(2016年1期)2016-06-22 13:10:37
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
航空學報(2015年4期)2015-05-07 06:43:35
上海電機學院學報(2015年4期)2015-02-28 14:30:00
