氣象文本推薦研究
2019-08-16 01:18:06王慕華王闊音
計算機應用與軟件 2019年8期
梅 鈺 唐 衛 王慕華 王闊音
(中國氣象局公共氣象服務中心 北京 100081)
0 引 言
氣象服務作為普通大眾最常接觸的公共服務,要求具備實時、準確、精細的特點。現有的氣象產品一般是通過氣象數據獲取、數值模型計算得到預測結果,最后將預測結果轉換為文字(輔以圖形及表格)向公眾發布。其中,后臺的數值預測通過預測算法不間斷運行得到預測結果,而前臺的預報文本則需要通過人工編寫校對生成。雖然人工參與可以保證預報的準確性以及權威性,但人工生成效率有限,且人無法像機器一樣連續工作,從而導致一些預報不能實時發布,制約了氣象服務質量的提升。目前,氣象文本自動生成的主要應用場景是給定數值數據,直接生成氣象文本[1],即全自動生成;主流方法是基于模板的方法,即針對不同氣象信息構造文本模板,后續通過“填空”的方式生成預報內容,該方法的最大問題是模板有限,只能表達固定信息,且有時信息不夠準確,生成的文本內容在靈活性和豐富性上也較差。因此,本文提出了一種半自動生成方案,給定部分氣象文本,生成擴展的預報文本的方法,即根據人工輸入推薦候選內容,相當于以人機結合的方式進行文本生成。這樣既可以提升人工進行文本生成效率問題,也可以保證預警信息的準確性,擴充預報思路,具有良好的實用性。
進行氣象文本推薦,一種簡單的實現思路可以采用基于搜索的方法,即收集歷史氣象文本,針對每對句子(前半句和后半句),構建從前半句到后半句的映射字典,在推薦時通過檢索前半句給出后半句集合。這種方法存在兩個問題:一是同樣輸入,對應的候選句集合太大,來自不同地區、不同單位的文本內容存在差異,所含的氣象數值不同;二是對于未出現的用戶輸入句,無法給出推薦結果。
從自然語言處理角度來看,氣象預警文本推薦可以看作是一個典型的文本生成問題(NLG)[2-4]:利用文本的上下句的語義邏輯關系進行預測。本文所提方法分為兩步:第一步是對原始文本中的氣象要素(如時間、地點、溫度、風速等級)進行實體抽取、數值替換,得到模板文本。模板文本相當于只保留了預警內容的描述框架。第二步基于模板文本構建文本生成模型,用于文本推薦。其中,生成模型采用基于神經網絡的Seq2Seq模型,該模型可以有效解決上述基于搜索方法的不足,既可以對候選文本進行排序減少推薦量,也可以對用戶的新輸入進行推薦。
為了研究氣象文本推薦,我們選取預警文本作為實驗數據,主要原因是預警文本數量大且獲取容易。預警文本是國家氣象部門針對可能帶來災害性后果的天氣情況作出的提前告警,圖1給出了一篇完整的氣象預警文本。圖2給出了氣象預警文本推薦的應用示例:左側是氣象預報員編寫的預警內容,右側是系統推薦的下一句預警文本。對于第一個樣本,用戶輸入“受冷空氣影響”,系統會推薦可能性較高的下一句預警文本,這里給出了top-3的結果。其中,空格表示用戶可以輸入時間、地點、溫度、風速等具體氣象要素,這些要素對于特定的預警事件,取值不同。用戶基于推薦文本進行修改后,生成最終預警文本。預警文本推薦一方面可以減少用戶輸入,另一方面也可以對預報生成進行提示,從而幫助提升預警文本攥寫的準確性。

圖1 預警文本示例

用戶輸入系統推薦結果樣例1:受冷空氣影響1. 預計風力逐漸加大至級2. 起將有雷陣雨3. 預計最低氣溫在℃左右樣例2:密切關注天氣盡量減少戶外活動
圖2 預警文本推薦示例
文本到文本的生成是目前自然語言處理的熱門研究方向,具體可以分為文本摘要[5-7]、文本復述[8-10]等細分方向。文本生成的傳統方法有規則式的生成方法、抽取式的生成方法。近年來,隨著深度學習的發展,尤其是神經機器翻譯技術的成熟,相關工作使用序列到序列的模型[11]來解決文本生成任務,如詩歌生成[12-13]、對話機器人[14-16]。此外,工業界也推出實際的寫作程序,應用于新聞寫稿[17]、氣象預報生成[18]等領域。現有氣象文本生成工作集中在將數值轉換為文本,而我們研究的氣象預警文本推薦側重于對用戶已輸入文本進行擴展。
本文的主要貢獻如下:
(1) 首次提出了氣象文本推薦問題,構建了研究數據集。通過對天氣網的預警內容進行數據采集,構建了預警文本數據集。
(2) 探索了對氣象文本進行氣象要素抽取的方法。首次定義了氣象要素抽取任務,評估了CRF模型[19]在要素抽取任務上的效果。
(3) 提出使用基于神經網絡的序列到序列的模型(Seq2Seq)來解決預警文本生成。實驗表明基于Seq2Seq模型的預測效果在BLEU值上可以達到12.21,具有一定的實用性。
1 問題定義
1.1 問題描述
氣象文本推薦的目標可以認為是構建一個推薦系統,該系統接收用戶的句子輸入S,輸出關聯句子T。推薦系統處理的數據形式為句對(類似于機器翻譯中的對齊文本[11])。具體地,我們對S和T的限定如下:(1)S和T是進行了氣象要素替換后的模板文本。之所以使用模板文本,是因為用戶在編輯具體內容時需要根據氣象預測情況填入實際的氣象數據。(2)S和T為逗號隔開的子句,且S和T要出現在氣象文本的同一句話中(句號隔開)。
根據第(1)條,推薦系統處理的文本為模板文本,即需要將文本中的氣象要素進行替換。氣象要素是指描述氣象信息的必要內容,比如時間、地點、類別等。實際上,這里的氣象要素對應的是自然語言處理中的實體。另外,氣象文本也會涉及量的描述,如“降水量在50毫米以上”,類似“50”的數值也需要替換。具體地,文本要抽取的氣象要素以及氣象數值示例如表1所示。
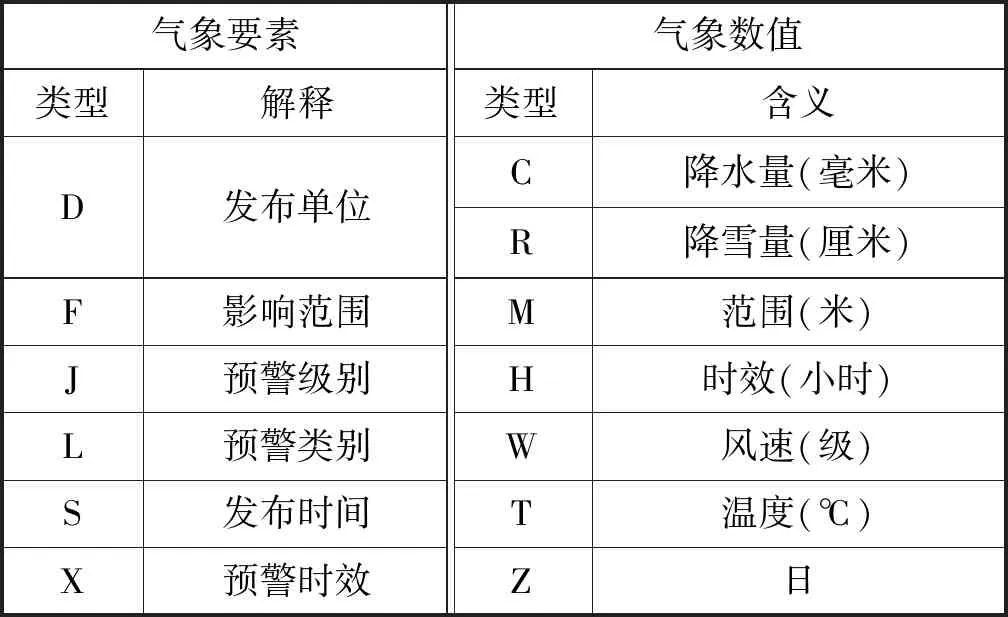
表1 氣象要素、氣象數值類型示例
表2給出了原始文本經過抽取替換得到的模板文本。其中,“密云氣象臺”是一個發布單位的實體,在模板文本中,使用實體類型“D”來替換。

表2 原始文本VS模板文本示例
根據第(2)條,句對的構建通過抽取文本中所有相鄰的子句來完成。以圖1中的預警文本為例,基于該預警文本生成的句對如表3所示。
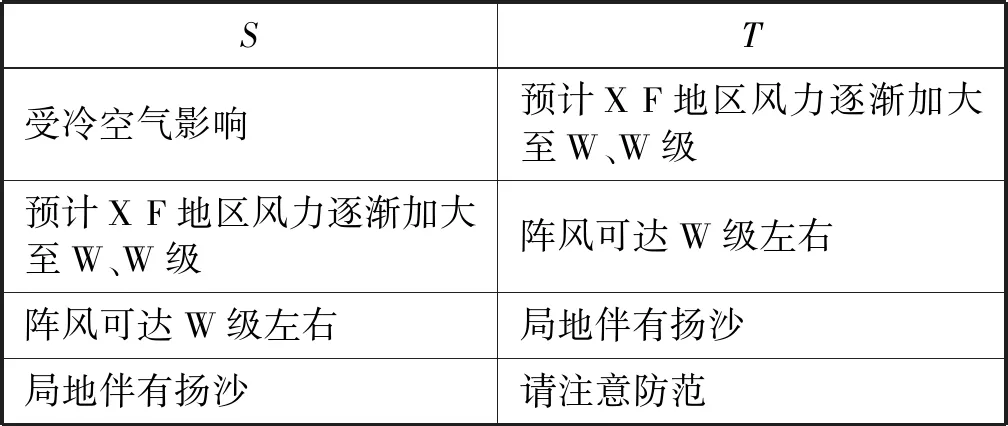
表3 基于圖1預警文本生成句對
1.2 數據集構建
為了開展文本推薦研究,需要構建對應的數據集。具體地,我們爬取了天氣網下氣象預警欄目的內容。下載過程分為2步:(1) 通過構建翻頁下載鏈接,即“https://www.tianqi.com/alarm-news/”+頁數,下載得到預警導航頁面;(2) 對導航頁面中的鏈接進行抽取,選擇“發布類型”的鏈接進行二次采集,獲取預警文本。圖3給出了數據下載的示例。

圖3 預警導航頁面
通過對200個導航頁進行輪詢下載,最終獲得了3 760條預警文本,我們稱對應的數據集為ALERT數據集。
2 方法設計
構建氣象文本推薦系統分為兩步:一是進行文本轉換,即將原始文本轉換為模板文本;二是基于模板文本構建推薦模型。以預警文本推薦為例,整個處理框架如圖4所示。
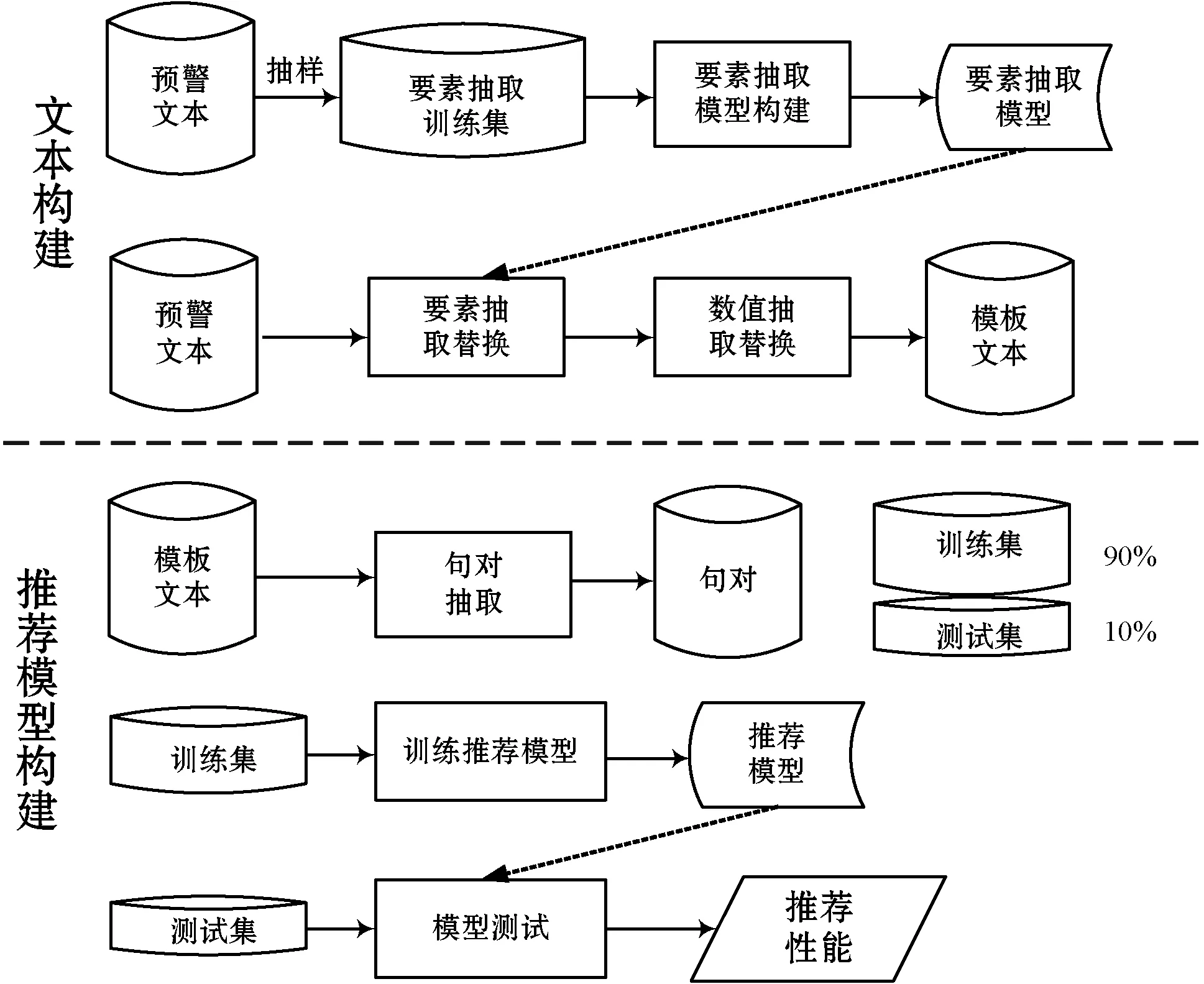
圖4 氣象文本推薦研究框架
2.1 文本轉換
2.1.1要素抽取模型構建
氣象要素抽取可以認為是一個命名實體識別問題。目前主流命名實體識別方法是基于統計的CRF模型。因為是統計模型,所以該模型在訓練時需要標注數據。由于包含氣象要素的預警文本相似度很高,所以要素抽取可能不需要太多的標注。為此,我們從ALERT數據中抽取了1 500條進行人工標注,選取其中的1 200條用于模型訓練,300條用于效果評估,對應的數據集分別為ALERT-Train和ALERT-Test。
具體地,我們采用字符級別的標注方法。圖5給出了標注示例,“12-14日”為預警時效實體類型,所以相關字符的標簽為“X”。

圖5 要素抽取的人工標注樣例
訓練使用目前主流的Stanford-NER工具。該工具提供了基于CRF的實體抽取模型。我們使用前面提到的ALERT-Train訓練模型,使用ALERT-Test測試效果,得到的性能測試結果如表4所示。
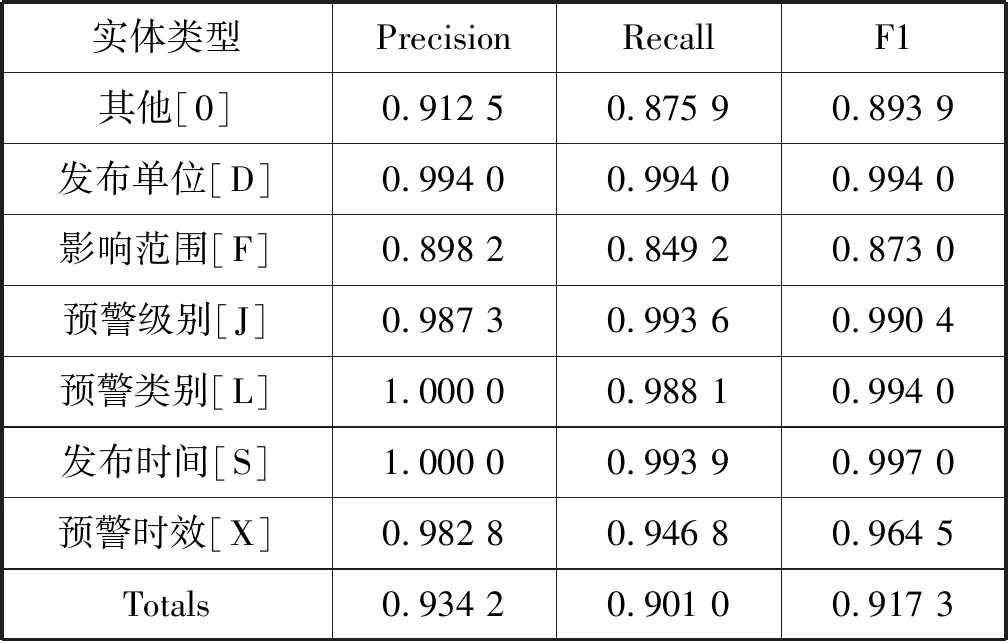
表4 氣象要素抽取的測試性能
從測試結果來看,發布單位[D]、預警級別[J]、預警類別[L]、發布時間[S]的F1值都超過了0.99,說明這些要素在內容表達上相對固定,而影響范圍[F]的準確率相對較低(0.87),說明地點表達相對多樣。
2.1.2要素抽取替換
我們使用2.1.1節訓練得到的要素抽取模型來處理ALERT中的所有預警文本。將抽取出的氣象要素替換為類型符號,比如將“發布單位”實體替換為“D”、“影響范圍”實體替換為“F”,替換示例如表2(左側)所示。值得注意的是,要素替換只會替換氣象要素實體。
2.1.3數值抽取替換
預警文本也會涉及氣象數值,這些數值對不同預警事件來講,參考性不大,也需要替換。如“降水量在50毫米以上”,需要將其中的“50”進行替換,替換之后的句子為“降水量在C毫米以上”。
具體地,我們使用正則表達式進行抽取,上述例子應用的正則表達式為“(d+)毫米”。同樣地,我們使用數值類型符號進行替換,替換的示例如表2(右側)所示。
2.2 推薦模型構建
2.2.1句對抽取
輸入的預警文本往往包含多個句子(句號隔開)。根據1.1關于問題的定義,預警文本推薦任務只處理相鄰子句。所以句對生成的過程如下:(1) 按照句號分割預警文本;(2) 對(1)中每句話,按逗號分割句子;(3) 對于(2)中的句子,如果句子由括號結尾,把括號中的內容獨立為一個新子句;(4) 對于(1)-(3)產生的所有子句,將返回相鄰的子句文本作為句對。句對抽取的示例如表3所示。
2.2.2推薦模型
推薦模型針對輸入句S,返回擴展句T。從輸入輸出來看,預警文本推薦可以看作是機器翻譯問題,相關的機器翻譯方法都可以拿來進行嘗試。采用目前基于神經網絡的序列到序列(Seq2Seq)翻譯模型來構建推薦模型[20-21]。Seq2Seq模型由兩部分構成,一是編碼階段的“Encoder”,二是解碼階段的“Decoder”。Encoder、Decoder一般使用基于RNN的神經網絡。RNN網絡可以將變長輸入序列轉換為固定維度的向量,也可以從固定維度的向量輸出變長序列。
1) RNN網絡。一個RNN網絡[22]按照順序對輸入序列x={xi}進行處理,不斷更新內部的隱藏狀態。對每個位置的輸入xi,RNN會更新計算隱藏狀態hi。在每個位置,基于隱狀態hi,RNN可以產生關于輸出yi的條件概率。這里輸入到RNN單元的xi、hi是固定維度的向量,yi是詞匯表中的特定詞。具體地,RNN網絡包括2個重要函數:狀態更新函數f(·)以及輸出函數g(·)。常見形式如下:
hi=f(hi-1,xi)=δ(Uxi+Whi-1+b)
(1)
g(yi|hi)=O(Vhi+c)
(2)
式中:δ(·)為激活函數tanh,O(·)為概率輸出函數softmax。由于原始RNN不能很好地解決長時依賴問題,神經網絡研究領域提出了多個針對RNN的改進版本,比如LSTM以及GRU[22]。
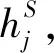
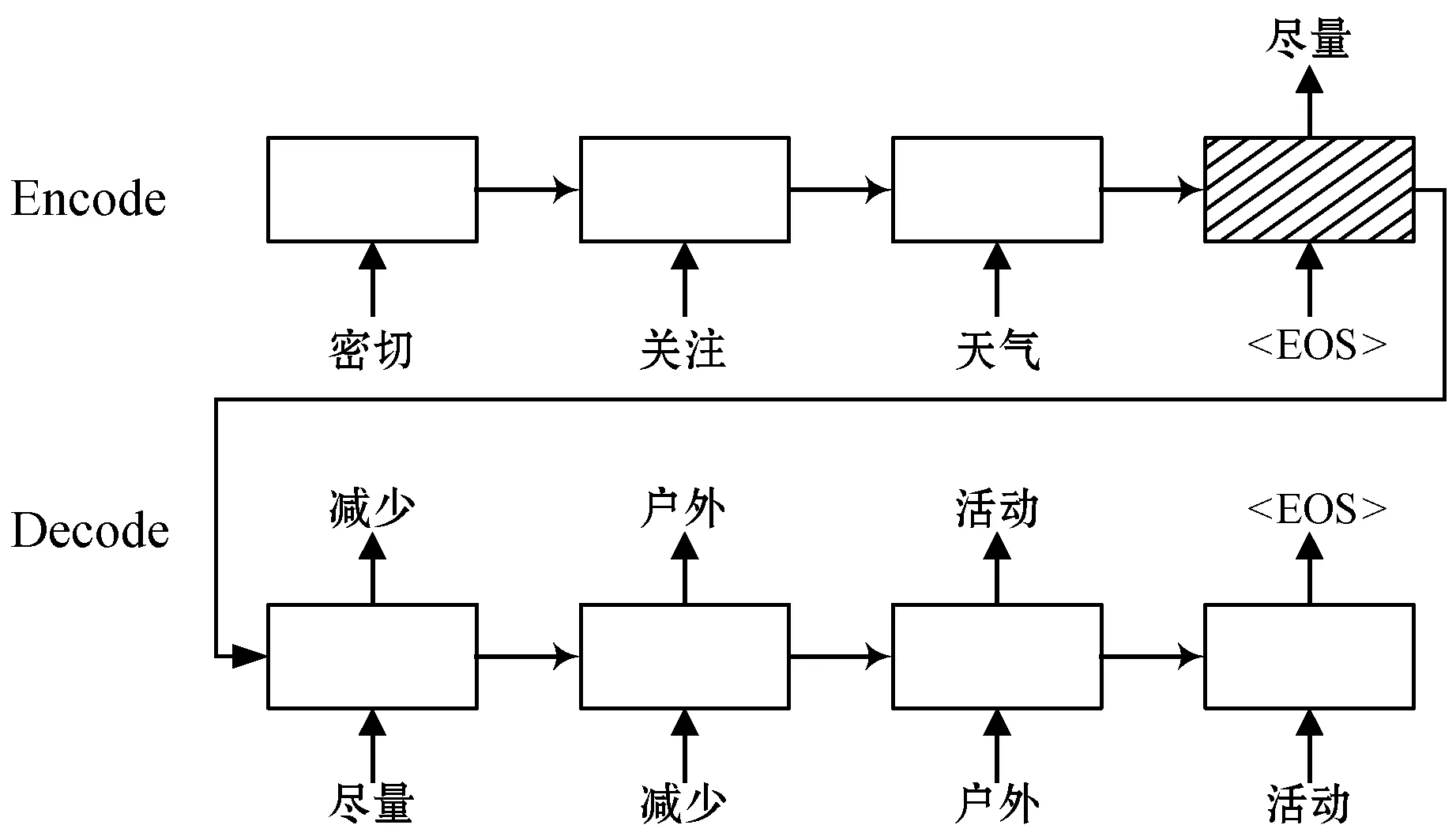
圖6 預警推薦算法的示意圖
從概率角度來看,Seq2Seq模型可以看作是用于估計條件概率P(T|S),S和T的長度可以不同。P(T|S)的計算如下:
式中:函數gDecoder(·)是解碼器的輸出函數(softmax函數),該函數能計算輸出詞Tj的概率。函數fEncoder(·)、fDecoder(·)是編碼器和解碼器的狀態更新函數。
Seq2Seq模型的參數學習通過最大化如下目標函數來實現:
式中:θ是模型參數,每一組
3) Seq2Seq模型實現細節。Seq2Seq作為基礎框架,其具體編解碼過程有多種選擇,在機器翻譯領域也有很多變種。針對氣象預警文本的推薦,我們的實現方案包括:
(1) 使用GRU作為RNN的實現。
(2) 不使用attention機制。主要原因包括3點:① 在預警文本推薦中,句子的長度較短,基于attention來解決解碼時長范圍依賴的需求不大;② 預警文本推薦的2句話在整體上存在邏輯表達關系,但在單個詞上的對齊關系較弱,attention作用有限;③ 引入attention也會引入額外參數,增大過擬合的風險。
(3) 對輸入句子進行反轉。主要原因是為了縮短輸入句S前面的詞到輸出句T前面詞的平均距離。在機器翻譯中,該方法可以有效提升翻譯質量。
具體的算法流程同文獻[21]一致。
3 實驗及分析
3.1 實驗設置
本文使用google-seq2seq的工具進行實驗。具體地,對ALERT數據集進行句對抽取,共獲得14 593個句子對。隨機選取其中的90%作為訓練集來學習參數,10%作為測試集進行結果驗證。句子長度的統計信息如表5所示。

表5 S、T句子長度統計信息
選擇機器翻譯常用的BLEU和ROUGE作為評價指標,通過比對模型生成句以及標準答案句的差異,對推薦句的效果進行評價。
句子使用Jieba進行分詞,詞的表示(embedding)也作為參數進行學習,訓練集中S的詞表大小為827,T的詞表大小為696;輸入句S和輸出句T使用獨立的詞表以及獨立的embedding矩陣。
關于詞的embedding學習,由于涉及參數較多,我們使用從中文wiki預訓練得到的embedding來初始化。具體地,中文wiki學習到的詞向量為300維,使用PCA將詞向量進行降維,該向量作為embedding的初始向量。對于未出現在wiki中的詞,使用隨機初始化。
在參數選擇上,需要盡可能地擬合訓練集,因為測試集和訓練集的數據分布差異較小。對于embedding.dim參數(PCA的輸出維度),我們嘗試了{4,8,16};對于Encoder、Decoder,我們嘗試了{num_layers:1,num_unit:8}以及{num_layers:2,num_unit:4}。最終使用的Seq2Seq模型的參數設置如表6所示。實驗在一臺GPU上運行,總共迭代了約15萬次。
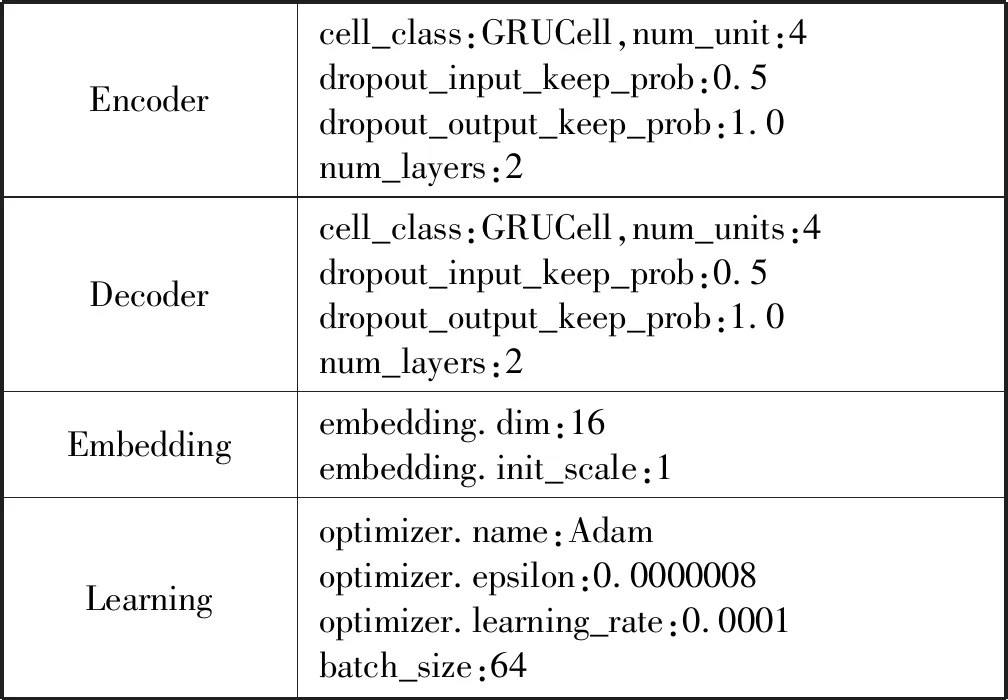
表6 Seq2Seq模型的參數設置
3.2 結果分析
最終的測試性能如表7所示。
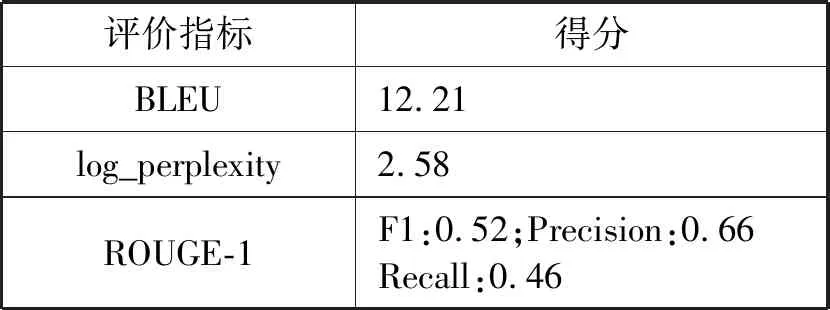
表7 Seq2Seq模型的性能指標
圖7-圖10給出了隨著迭代的進行,學習到的Seq2Seq模型在測試集上的性能得分(BLEU、ROUGE-1/F、ROUGE-1/Precision、ROUGE-1/Recall),步長為10 000。從圖中可以看到,模型已經收斂。

圖7 BLEU值
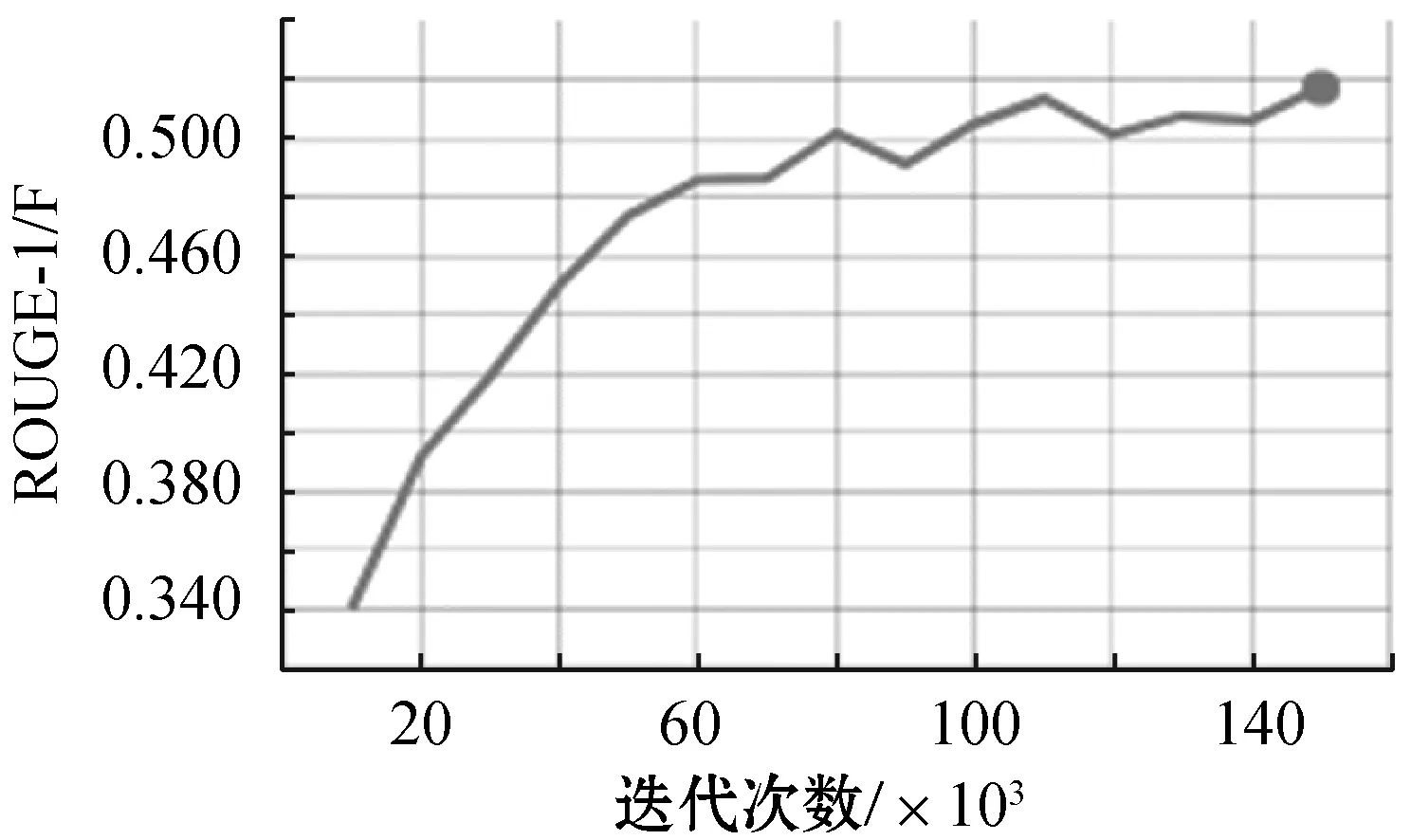
圖8 ROUGE-1/F值
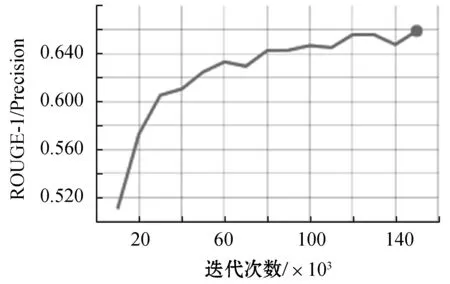
圖9 ROUGE-1/Precision值
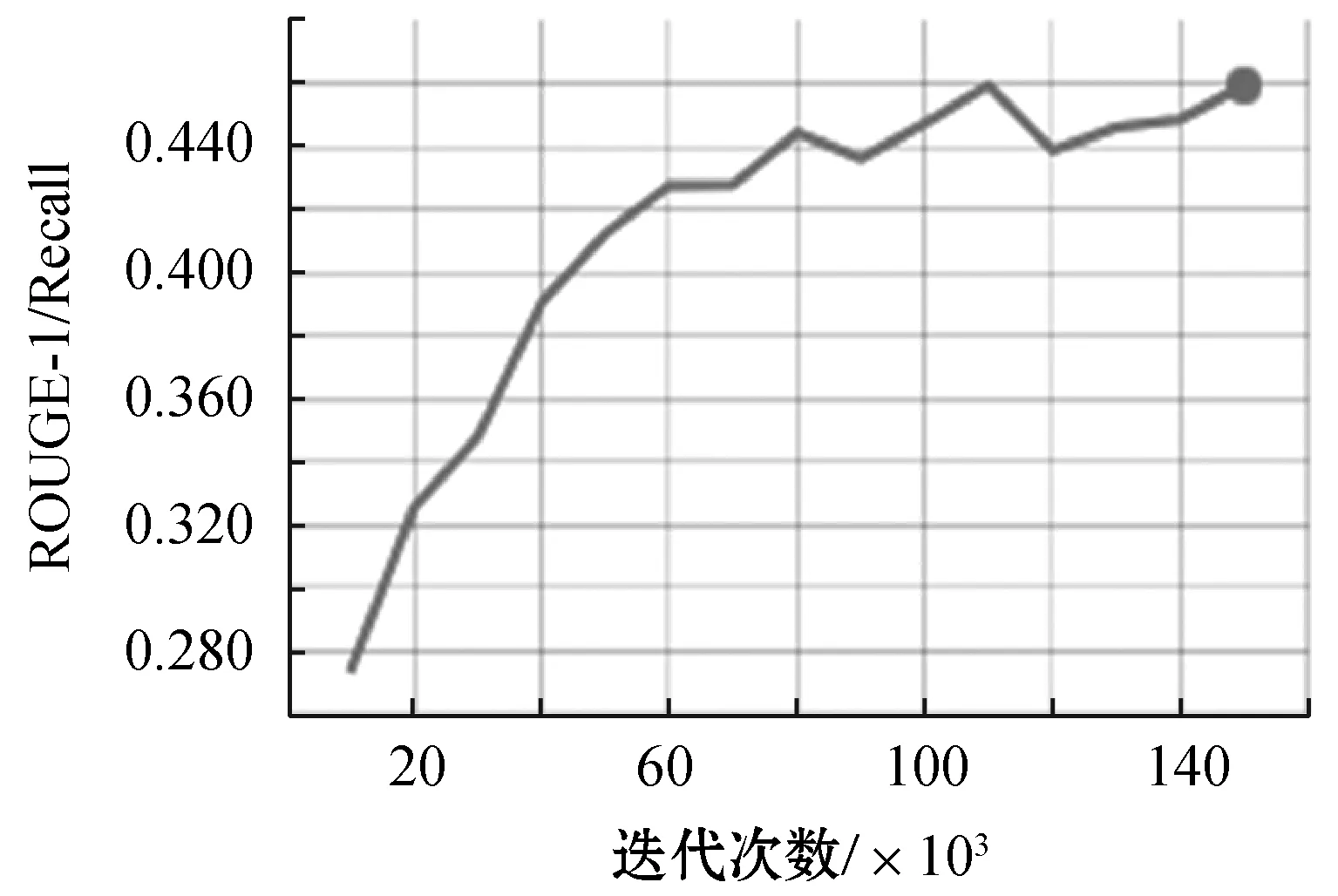
圖10 ROUGE-1/Recall值
表8給出了對于預警文本推薦,模型生成的得分最高的推薦結果與標準答案的樣例。從表中可以看到,對于編號1~3的樣本,模型生成句與原始參照句基本一致,說明Seq2Seq模型在句子生成上的優勢。對于編號為4的樣本,模型生成句雖然與標準答案不完全一致,但所含的內容詞也反映了答案的意思。
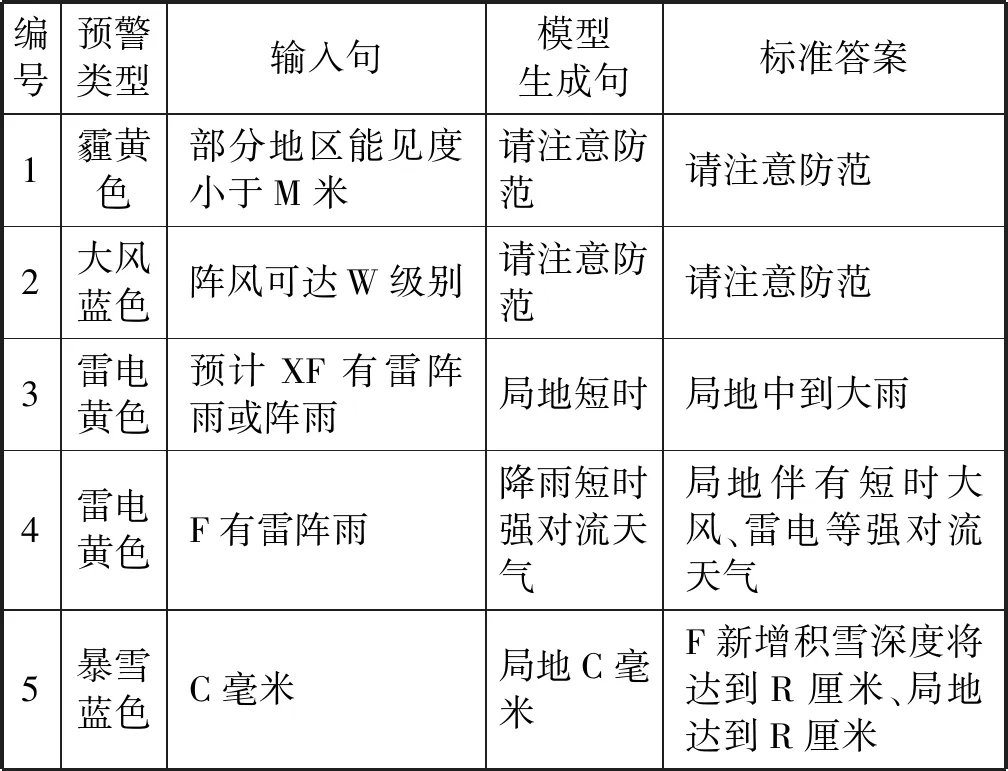
表8 輸入句、模型生成句與標準答案示例
一個有意思的樣本是樣本5,模型生成句為“局地有C毫米”,而標準答案是“F新增積雪深度將達到D厘米、局地達到D厘米”。顯然,模型生成句表達了降水,而標準答案表達為降雪。針對該預測錯誤進行分析,得到這兩句話所在的完整預警文本如表9所示,抽取的句對如表10所示。
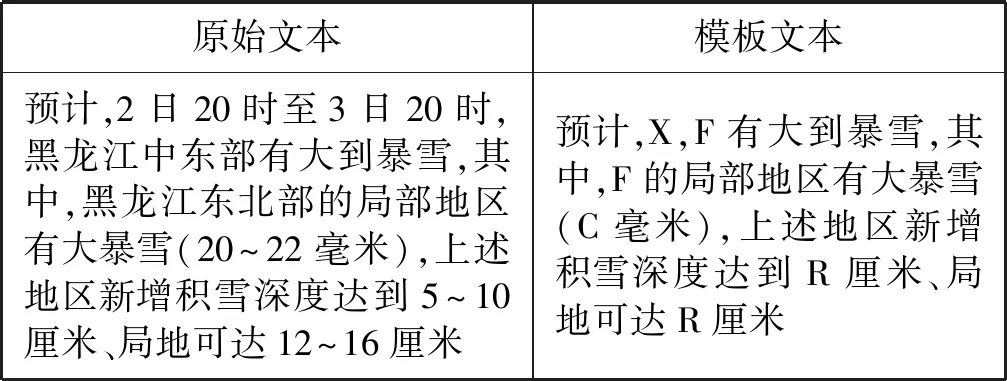
表9 樣本5所在的完整預警文本
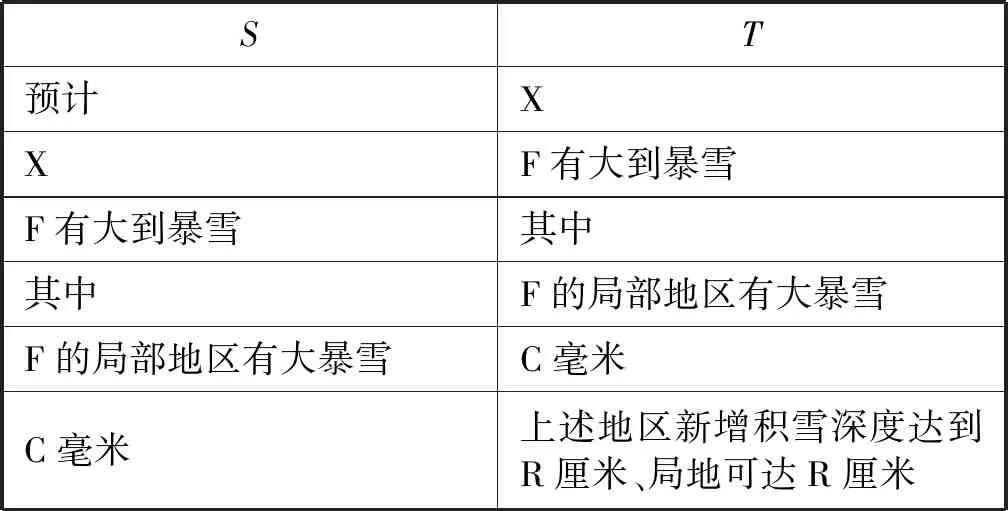
表10 樣本5抽取的句對
“C毫米”是從括號文本中抽取出來的單獨子句。因為對于降水預警文本,“C毫米”也是一個常見的短語,所以根據“C毫米”,模型會輸出和降水相關的下半句。
這個現象說明,目前使用基本Seq2Seq模型不考慮預警文本的背景信息(即“預警類型”、“預警級別”等),僅使用當前句子信息來預測下一個句子,會造成預測結果與實際結果的偏差。融合預警類型信息進行推薦還需要進一步研究。
4 結 語
本文對氣象文本推薦問題展開研究,在預警文本上實現了基于Seq2Seq模型的文本推薦系統。首先,進行氣象要素抽取,將歷史預警文本轉換為模板文本;然后,從模板文本中抽取句對;最后,基于句對構建推薦模型。其中氣象要素抽取使用基于CRF的抽取方法完成。測試結果表明,氣象要素抽取對“影響范圍[F]”類型的抽取精度(F值)相對較低,其他類型的抽取范圍精度較高。預警文本推薦使用基于神經網絡的Seq2Seq模型,并且針對氣象預警文本生成的特殊性,對Seq2Seq模型的組件進行了定制。實驗結果表明,本文方法進行文本推薦的BLEU值上可以達到12.21,具有一定實用性。此外,我們對其中一些預測錯誤的情況進行了分析。未來會把預警類型和預警級別作為上下文向量,引入到預警文本推薦中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
