數據挖掘方法在工業企業故障診斷中的應用
2019-08-19 05:49:22
福建質量管理 2019年15期
(江南大學 江蘇 無錫 214122)
科技的發展為工業領域帶來了技術的變革,自動化和智能化的發展趨勢使得工業各個環節都在被信息技術影響,各種自動控制系統正在迅速應用。現代信息技術與工業的整合使每個鏈路的數據都得以完整記錄,這些數據正以驚人的速度擴張,工業已進入“大數據時代”。這些數據通過科學的手段便能“變廢為寶”,而數據挖掘技術就是幫助企業去挖掘寶藏的關鍵。數據挖掘技術可以分析行業生成的數據,發現隱藏的關系和規則。利用這些關系和規則來幫助工業在準備、制造、采購階段提高效率、優化質量和降低成本等。
在復雜的工業生產過程中,當某一環節發生故障時,會導致一系列的連鎖問題,使得整個生產系統受到影響,甚至可能會危及人身安全,因此故障預警是必不可少的。然而,生產線的復雜情況,即使是經驗豐富的老師傅也很難快速地反應過來,而數據挖掘卻不同,它通過數據的挖掘與分析,找出其中的關聯,能夠達到快速預測的效果。本文嘗試利用數據挖掘算法,對中科云谷公司混凝土泵車砼活塞進行故障診斷,以期更快、更有效地解決工業企業生產故障問題。
一、數據挖掘分類預測方法
活塞故障預測其本質就是預測該零件存在質量問題的傾向性,屬于二元分類預測模型,常用的有神經網絡、決策樹、邏輯回歸和支持向量機等算法[1-3]。
(一)決策樹算法。決策樹算法由構建決策樹和決策樹剪枝兩個基本步驟組成,利用數據中具有分類功能的屬性作為節點生成決策樹,然后利用測試數據集對分類規則進行剪枝,最終形成的決策樹可對數據進行分類。常見的構建決策樹的方法有CART算法、J48等。
(二)邏輯回歸。邏輯回歸用于描述范疇型響應變量與預測變量之間的關系,是在多響應線性回歸的基礎上,在一個經轉換的目標變量上建立的線性模型。
(三)支持向量機。支持向量機(SVM)是建立在VC維理論和結構風險最小原理等統計學理論基礎上的,它由于在解決小樣本、非線性、高維模式識別中具有特別的優勢而受到了廣泛的關注,并能夠推廣到函數擬合等其他機器學習的應用中。
二、實驗數據及數據預處理
本研究采用中科云谷科技有限公司公開提供的混凝土泵車砼活塞故障有關的數據,包括工作時間等多類工況數據,以及相應情況下,當混凝土泵送量完成時,活塞是否有故障的識別信息。
由于數據屬性較多,為提高結果準確度,需要進行數據預處理剔除冗余屬性,這里通過計算皮爾森系數來評估屬性重要程度的方法,選擇Ranker作為搜索方法,計算結果顯示,屬性反泵、低壓開關、攪拌超壓信號、高壓開關、正泵與預測結果關系為0,將它們移除,最終篩選出的屬性如表1所示。
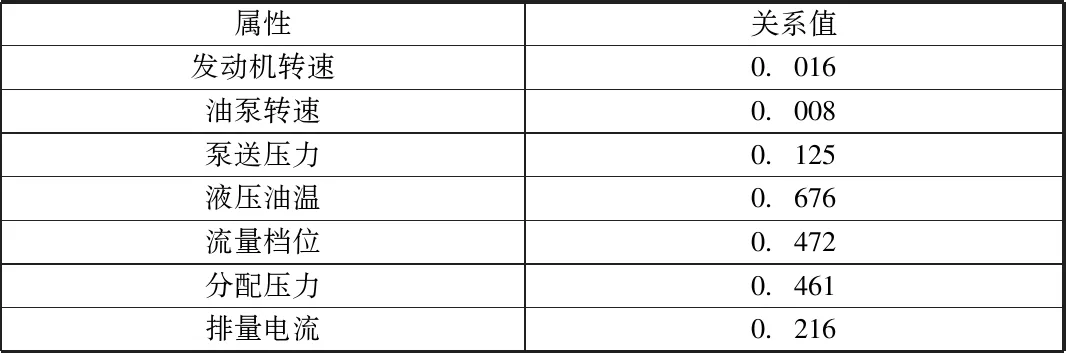
表1 屬性篩選結果
三、實驗結果
(一)對比實驗結果及評估
本章中活塞故障預測模型,輸入變量是連續型變量,輸出變量是分類變量,因此本文選擇邏輯回歸、決策樹、支持向量機3種分類算法進行建模,并對結果進行對比分析。
模型評估有多種指標,常用的有精確率、覆蓋率和兩類錯誤率。然而,某個類的精確率與覆蓋率不一定能同時高,對于故障預測問題,由于未能預測出故障造成的損失要比把不故障產品判斷成故障產品造成的損失高出許多,因此對故障識別能力要求較高,也就是對覆蓋率要求更高,具體需要比較兩類錯誤的不同代價,從而尋求平衡使得總代價最小。兩類錯誤率的概念來自統計學,將其放入本模型中,即原假設為活塞是故障的,那么把一個將故障的活塞預測為不會故障的錯誤就是第一類錯誤,把一個不會故障的活塞預測為會故障的活塞預測為會故障的錯誤是第二類錯誤。對比分析結果如表2所示:

表2 三種模型對比分析結果
從表2可以看出,決策樹J48算法不僅達到最高的精確率,覆蓋率,和F值,各類型錯誤率也是最低的。通過各類指標的比較,本文選取決策樹作為故障預測模型
(二)決策規則
決策樹應用于故障預測模型的優勢之一就是可以歸納出規則,便于工作人員操作,根據預測結果,本文可以歸納出以下幾條:
規則1:如果:流量檔位≥9.75;那么:故障傾向?不故障
規則2:如果:流量檔位>9.75 & 排流電量≤588.52;那么:故障傾向?不故障
根據這些規則,操作人員可以迅速定位有故障傾向的機器,然后進行整修。
四、結論
工業水平體現了一個國家的綜合國力,我國作為一個工業強國,工業領域的數據庫中有著大量的、模糊的、冗余的信息,工業生產過程所面臨的復雜的預測、優化問題,靠以往的人工經驗和簡單的統計分析方法已經不能解決,而數據挖掘為工業的優化帶來了新的方向。借助數據挖掘技術可以提高企業效率、優化產品質量,在工業領域中數據挖掘技術革新了企業的研發、生產、運營和管理方式,讓工業生產過程更加智能化和自動化。本文討論了在這個“數據爆炸”的時代,將數據挖掘技術應用于工業企業故障診斷的可行性。通過對中科云谷科技公司混凝土泵車砼活塞建立多個故障預警的模型,并進行對比分析,發現該公司砼活塞故障預警的最佳方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電力與能源(2017年6期)2017-05-14 06:19:37
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
信息通信技術(2015年6期)2015-12-26 01:16:46
汽車維修與保養(2015年6期)2015-04-17 03:31:50
