超超分辨率卷積神經網絡算法在高速攝影圖像優化中的應用
2019-08-29 01:51:30高林
載人航天 2019年4期
高 林
(西安航天動力試驗技術研究所,西安710100)
1 引言
分布式環繞高速攝影系統不僅可用來研究液體火箭發動機試驗中關鍵部位圖像的細節信息,且可通過放大局部圖像研究跌落試驗中結構件的形變程度。但受CMOS處理器尺寸的物理極限與成本的限制,圖像經多次甚至2次放大后會變得模糊不清,影響圖像數據的分析。高精度光學儀器設備通常需要接近35 mm模擬膠片的分辨率水平,從而在放大一個圖像時不會有可見的瑕疵[1]。然而,隨著像素尺寸的減少,光通量也隨之減少,產生的散粒噪聲使圖像質量嚴重惡化。不受散粒噪聲的影響而減少像素的尺寸有一個極限,即對于0.35 μm的CMOS處理器,像素的理想極限尺寸大約是40 μm[2]。當前液體火箭發動機試驗使用德國PCO.dimax系列高速攝影機采集發動機關鍵部位的高速攝影圖像,通過后處理軟件Visart實時放大查看圖像時便存在圖像失真與模糊的現象,影響圖像數據的細化分析。
超分辨率(Super-Resolution)算法從空間分辨率上解決了圖像放大時的失真問題,克服了傳感器和光學制造技術的限制。該算法通過量化后的低分辨率圖像與高分辨率之間的對應關系,將低分辨率圖像恢復成具有生動紋理與顆粒細節的高分辨率圖像[3]。該技術可以在不改變硬件條件的情況下,在已有的低分辨率圖像基礎上,利用圖像的先驗信息重建出高分辨率的圖像[4]。
超分辨率算法自上世紀70年代提出以來,主流的算法主要為傳統的基于插值的圖像超分辨率算法和基于深度學習的圖像超分辨率算法[5]。基于插值的算法利用臨近像素的灰度值來產生待插值像素點的灰度值,較為經典的插值算法有雙線性插值算法和雙三次插值算法,但這些算法的應用環境較為局限[6]。為克服傳統插值算法的不足,研究者提出了許多改進的插值方法。Chang等2001年提出的基于最小二乘法的邊緣指導內插值算法,獲得了更好的圖像效果[7]。陶洪久等[8]提出的小波域的雙線性插值算法雖滿足實時性要求,但是很難在超分辨圖像中得到較好的銳化效果。
當前深度學習理論與算法在圖像超分辨率方面的發展非常迅速,優化算法層出不窮,基本已經取代了傳統的插值算法,如目前較新的算法有SRCNN、ESPCN 和 SRGAN等[9]。SRCNN(超分辨率卷積神經網絡,Super-Resolution Convolutional Neural Network)算法基于稀疏編碼的單幀超分辨重建算法,何凱明[10]在此基礎上設計了一個3層的卷積神經網絡,以逐像素損失為代價函數,取得了令人震撼的效果。但是針對不同問題,對3層卷積網絡中每層不同濾波器個數的選擇會得到不同的平均峰值信噪比和圖像清晰度。因此對高速攝影問題,使用SRCNN須對濾波器個數進行調優。
本文將基于深度學習的超分辨率算法SRCNN應用到高速攝影領域進行濾波器參數調優,針對單幀高速攝影圖像,采用Matlab 2016a對圖像超分辨率SRCNN算法進行仿真,對第2層卷積網絡參數f2進行了調優,并對比原來的SRCNN算法和雙三次插值算法的圖像平均峰值信噪比和圖像清晰度,以求在保證圖像具有較高的平均峰值信噪比和圖像清晰度的同時,取得較為滿意的收斂速度。
2 問題描述
高速攝影實時采集的圖像或者事后得到的圖像經多次甚至2次放大后,圖像已變得較為模糊。超分辨率求解任務如圖1所示,首先將輸入的低分辨率圖像放大至目標尺寸,然后利用某種算法去擬合低分辨率圖像與高分辨率圖像間的映射關系,最后求解得到高分辨率圖像[10]。其中LR表示低分辨率,HR表示高分辨率。
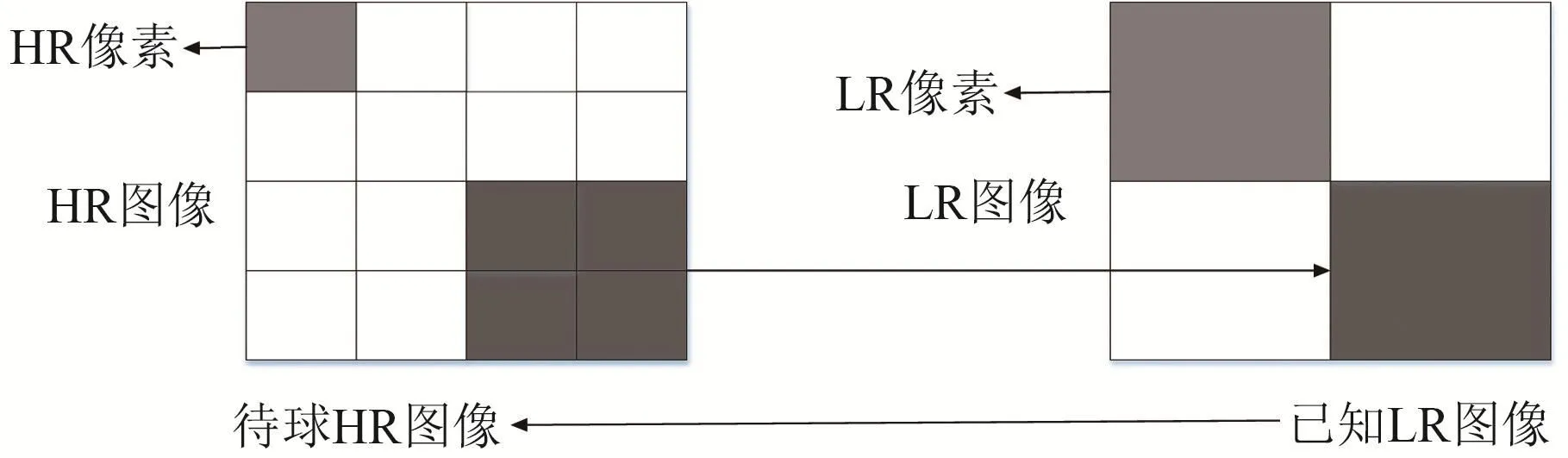
圖1 超分辨率求解任務[10]Fig.1 Super-resolution solving task[10]
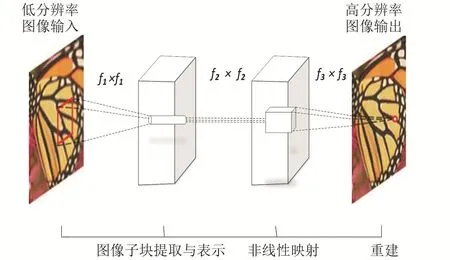
圖2 SRCNN算法超分辨率重建原理[10]Fig.2 Super-resolution reconstruction principle of SRCNN algorithm[10]
3 SRCNN算法調優
3.1 深度學習SRCNN算法流程
經典的SRCNN算法超分辨率重建原理如圖2所示[10],包含3個卷積層,其在概念上分為3個步驟:
1)圖像子塊的提取和表示:此操作從輸入的低分辨率圖像中提取圖像子塊并將每個子塊表示為1個高維度的向量。這些向量包含了1組數量與向量維數相等的特征映射。圖像復原中流行的一種策略是密集地提取圖像子塊,然后通過一組預先訓練的基來表示,例如PCA、DCT和Haar等。這相當于用1組濾波器對圖像進行卷積,其中的每個濾波器都是1個基。形式上,第1層可表示為1個操作F1:F1(Y)=Max(O,W1*Y+B1),其中W1和B1分別代表的濾波器和偏置,*表示卷積操作,W1相當于c×f1×f1×n1的濾波器,其中c是輸入圖像的通道數目,f1是濾波器的空間大小。直觀地說,W1對圖像應用n1個濾波器卷積,卷積核大小為c×f1×f1。輸出由n1個特征映射組成,B1是1個n1維向量,其每個元素與1個濾波器相關聯[10]。
2)非線性映射:此操作將每個高維度向量非線性映射到另一個高維度向量。第1層為每個圖像子塊提取1個n1維特征。在第2層中,我們將每個n1維向量映射到1個n2維向量中。這相當于應用了n2個卷積核大小為1×1濾波器,而且很容易推廣到更大的過濾器,如3×3或5×5濾波器,并非線性映射到3×3或5×5的圖像子塊上。第2層可表示為 1 個操作F2:F2(Y)=Max(O,W2*Y+B2),W2包含大小為n2×f1×f1的濾波器,B2是n2維的。每個輸出的n2維矢量在概念上是一個重建后的高分辨率圖像子塊的特征表達[10]。
3)重建:此操作將第2步中的高分辨率圖像子塊來生成最終的高分辨率圖像。第3層操作表示為F3:F3(Y)=Max(O,W3*Y+B3),W3包含大小為n3×f1×f1的濾波器,B3是n3維的。如果高分辨率圖像子塊的表示是在圖像域,濾波器表現的和均值濾波器一樣;如果高分辨率圖像子塊的表示是在一些其他域(例如,基于一些基的系數),W3先將系數投影到圖像域,然后平均產生最終的完整圖像。無論哪種方式中,W3是一套線性濾波器[11]。
上述3個步驟組合形成一個超分辨率卷積神經網絡,利用較少的卷積層獲得圖像分辨率質的提升。
3.2 算法調優
本文對液體火箭發動機圖像深度學習訓練采用ILSVRC 2014 ImageNet訓練集。ImageNet訓練集是一個用于視覺對象識別軟件研究的大型可視化數據庫,其約有超過1400萬的圖像URL被ImageNet手動注釋,以指示圖片中的對象,并包含2萬多個圖像類別。類似的訓練集91 images樣本數較ImageNet訓練集樣本數很小。但訓練集樣本數越大不代表可以獲得的圖像質量越高,訓練集樣本數越大只是學習的細節信息越多,算法收斂速度越快,訓練出模型的時間越短。在SRCNN上使用不同濾波器數目可以改善最終獲得的圖像的平均峰值信噪比PSNR,Set5 images數據集訓練結果如表1所示[12],前者采用更多的濾波器數目取得了更加優越的性能。
其中PSNR是圖像的平均峰值信噪比,計算方法如式(1)~(2)[13]:
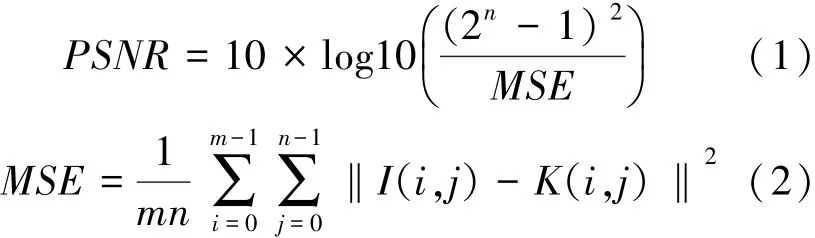
對比尺度因子為2的雙三次插值算法,本文采用增大SRCNN算法第2層卷積非線性映射中濾波器大小來獲得圖像的平均峰值信噪比PSNR的提升,這樣收集了圖像更加豐富的結構信息,從而得到更好的圖像質量。在初始的試驗中嘗試采用ImageNet數據集中9-1-5網絡結構的x3.mat核文件輸出結果,但是圖像的質量模糊不佳。在SRCNN算法流程第2步非線性映射中采用更大的5×5的濾波器訓練出x2.mat核文件,采用訓練出的9-5-5的x2.mat核文件重新測試,本文算法流程圖如圖3所示。

圖3 本文算法流程圖Fig.3 Flow chart of algorithm proposed in this paper
4 仿真校驗
為了驗證深度學習SRCNN調優算法在高速攝影圖像優化過程中的有效性,將第3節基于SRCNN算法采用 Matlab語言編程實現,并將PCO.dimax高速攝影后處理軟件Visart處理后的視頻數據拆分為單幀圖像。
系統的仿真硬件平臺配置:處理器為Intel(R)Core(TM)i5-6200U CPU@2.40 GHZ,內存 4.00 GB;軟件開發平臺配置:Windows10操作系統(64 bit)、MATLAB R2016a。
訓練數據集:采用樣本數為127萬的ILSVRC 2014 ImageNet訓練集訓練網絡模型,由于該訓練集樣本數過于龐大,于是每間隔3張圖片取一張,直到取到120萬時終止,從而得到了30萬張樣本圖像,并將取到的圖像統一壓縮為256×256大小的圖像進行保存,再從256×256的圖像的隨機位置取96×96大小的小塊,得到本文的HR標簽。對96×96大小的小塊再采用高斯濾波和AREA下采樣2倍和4倍得到LR標簽,以此組成了24/48和24/96的LR/HR圖像對。
校驗步驟為:首先截取發動機噴管附近區域202×202大小的jpg格式單幀高速攝影圖像作為輸入的原始圖像,然后分別使用雙三次插值算法、SCRNN算法、調優后的SCRNN算法對輸入的原始圖像進行處理,最后統計處理后圖像的PSNR值和算法運行時間進行比對,如圖4所示。
從圖4可以看出,(b)中雙三次插值算法得到的圖像紋理細節模糊不清,這主要是因為插值模型的低通濾波效應,使得圖像缺少了高頻信息,對細節還原能力不夠。與雙三次插值算法對比,(d)中調優后的SRCNN算法具有更高的圖像重建精度PSNR值為39.293 dB且主觀上圖像更加清晰銳利,算法運行時間和(c)中SRCNN算法用時接近。從軟件算法層面提供了一種解決當前試驗系統中高速攝影圖像多次放大后圖像清晰度受物理硬件精度限制問題的有效思路。
5 結論
仿真實驗表明,對深度學習SRCNN算法第2層卷積網絡層進行調優后的比原來的SRCNN算法和雙三次插值算法的圖像平均峰值信噪比表現更好,圖像清晰度滿足實驗要求,可以應用在液體火箭發動機試驗高速攝影圖像優化以及大數據量的發動機圖像壓縮存儲和復原。下一步研究重點是進一步優化發動機訓練集,提高算法收斂速度。
