云環境下基于群智能算法的大數據聚類挖掘技術
2019-09-02 03:28:44劉云恒
現代電子技術 2019年9期
劉云恒


摘 ?要: 云計算從分布式存儲和分布式計算兩個方面為大數據處理提供了強力的支持,并逐漸成為大數據挖掘的主流平臺。但是在處理云平臺中的大規模數據集時典型聚類挖掘算法存在一定不足,因此,提出一種基于群智能算法的大數據K?means聚類挖掘算法。首先對云計算Hadoop框架的存儲數據能力和采用的Map Reduce計算模型進行分析,然后采用群智能算法對傳統數據挖掘K?means聚類算法進行改進,解決其容易陷入局部最優問題。實驗結果表明,相比加權K?means聚類算法,提出的改進算法表現出更好的聚類精度和運行速度,可以適用于大規模數據的聚類挖掘。
關鍵詞: 大數據聚類挖掘; 云計算模型分析; 聚類分析; 聚類算法設計; 算法優化; 聚類算法改進
中圖分類號: TN911.1?34; TP393 ? ? ? ? ? ? ? ? ? 文獻標識碼: A ? ? ? ? ? ? ? ? ? 文章編號: 1004?373X(2019)09?0065?03
Cloud environment big data clustering mining technology
based on swarm intelligence algorithm
LIU Yunheng
(Nanjing Forest Police College, Nanjing 210023, China)
Abstract: Cloud computing provides strong support for big data processing in the aspects of distributed storage and distributed computing, and gradually becomes the mainstream platform of big data mining. However, the typical clustering mining algorithm has some shortcomings while dealing with the large?scale datasets in cloud platform. Therefore, a mining algorithm based on swarm intelligence algorithm is proposed for big data K?means clustering. The data storage capability of the cloud computing Hadoop framework and Map Reduce computing model are analyzed. The swarm intelligence algorithm is used to improve the traditional data mining K?means clustering algorithm to solve the problem that the algorithm is easy to fall into the local optimum. The experimental results show that, in comparison with the traditional weighing K?means clustering algorithm, the improved algorithm has higher clustering accuracy and faster running speed, and is suitable for clustering mining of large?scale data.
Keywords: big data clustering mining; cloud computing model analysis; clustering analysis; clustering algorithm design; algorithm optimization; clustering algorithm improvement
0 ?引 ?言
云計算(Cloud Computing)是大型計算機到客戶端?服務器的大轉變之后的又一種巨變,并被社會各界所認可。由于出眾的計算性能,云計算得到了計算機領域的廣泛認同,其接受程度和應用范圍不斷擴大[1?2]。近幾年來,云計算已經對許多行業產生了巨大的革命性影響,并會完全改變IT產業的模型和運行機制。隨著成本的不斷降低,低功耗和高性價比的云計算將逐漸替代眾多的傳統服務器硬件市場。具有高計算性能機、高存儲速度和大存儲空間的云計算數據中心將迅速大規模普及[3]。不久的將來,大部分應用軟件將以服務的形式展現在人們面前,甚至大型的3D游戲也會在遠程的云服務器中運行。
伴隨著Internet網絡的飛速進步及不斷普及,如今社會正以十分驚人的速度生成大量的數據。移動通信、網頁瀏覽、辦公自動化、在線購物等,極度便利的網絡社交和商業活動持續不斷地生成各類數據,意味著世界已經邁入了一個嶄新的時代,即爆炸性擴張的大數據時代。數據挖掘(Data Mining)技術按照眾多事件的相關性,發掘解釋數據的一般規則集合,并利用訓練和自學習,抽取隱含在數據中的新關系。上述數據的一般規則或相互關系能夠為數據管理、信息查詢、決策判斷和優化控制等應用提供技術支撐。這些數據對于企業來說具有巨大的經濟價值,可以視為一個信息金庫[4?5]。云環境上的大數據分析已經逐漸成為一個全新的商業模式。但是要實現云環境下的數據挖掘,首先要在云計算環境中實現傳統數據挖掘算法,其次需要解決現有傳統的數據挖掘算法無法適應大規模數據的問題。文獻[6]對基于粒子群算法的智能搜索引擎進行研究,將粒子群算法引入智能搜索引擎中,以實現公安大數據的關聯搜索。文獻[7]采用的群體協同智能聚類方法在粒子群算法中融入多種群協同進化的方案,避免出現局部最優解問題,提高了數據聚類的效率和精度,最終增強了大數據存儲性能,但是仍存在一定的局限性且不能較好地適用于云計算模型。
因此,為了進一步提高云環境下聚類算法的準確率,本文提出一種基于群智能算法的大數據K?means聚類挖掘算法。實驗結果表明,相比加權K?means聚類算法,本文提出的改進算法表現出更好的聚類效果。
1 ?云計算模型分析
1.1 ?云平臺體系
目前,云計算平臺主要具有基礎設施Server、平臺Server和軟件Server三種服務內容[8]。云平臺典型體系如圖1所示。
圖1 ?云平臺典型體系
1.2 ?HDFS架構及Map Reduce計算模型
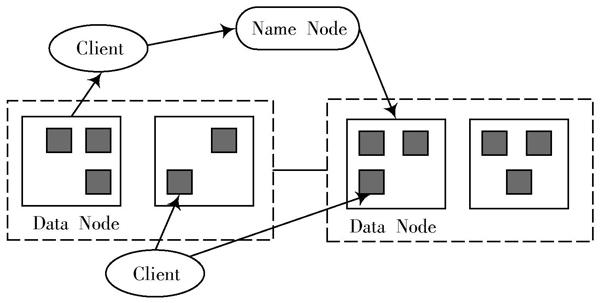
作為Apache中的一個開源項目,Hadoop分布式框架HDFS是現階段最流行的云計算服務架構。HDFS主要由一個主從結構構成,完整的集群包含唯一的Name Node和2個以上的Data Node,如圖2所示[8]。
Hadoop分布式框架HDFS采用Map Reduce計算模型進行Map階段和Reduce階段的執行,從而把大數據集劃分成若干個小數據集。完整的Map Reduce作業步驟分為作業提交、作業初始化、任務分配、任務執行和作業完成五個階段。
圖2 ?HDFS架構
2 ?基于群智能的聚類算法設計
2.1 ?聚類分析基本模型
作為一種基于距離的劃分聚類算法,K?means聚類算法具有算法結構簡單、運行效率高且適用范圍廣等優點[9]。基于K?means聚類算法的聚類分析過程如圖3所示。
圖3 ?聚類分析示意模型
可以看出,式(1)所示的目標函數是一個誤差平方和計算過程。其中:E為聚類準則函數;K為聚類的總數;[Cj,j=1,2,…,K]為聚類中的簇;[x]為簇[Cj]中的一個聚類目標;[mj]為簇[Cj]的平均大小。K?means聚類算法的輸入參數為數值K和數據集X中聚類目標的數量n,輸出為使聚類準則函數E達到最小的K個聚類。
2.2 ?狼群算法優化設計
面對大數據環境下的復雜優化問題,傳統K?means聚類算法在處理大規模數據時存在尋找全局最優解較為困難的難題:在處理大規模數據集的挖掘任務時,K?means算法的聚類效果對初始中心敏感,常常出現陷入局部最優的問題。
因此,基于混合聚類的思路,本文引入智能群體算法中的狼群算法,輔以魯棒性更強的K?means算法優化混合聚類方法的聚集效果。設狼群中狼的總數為N,待尋優的變量數為[D]。探狼在第d維空間中的位置更新方式如下[10]:
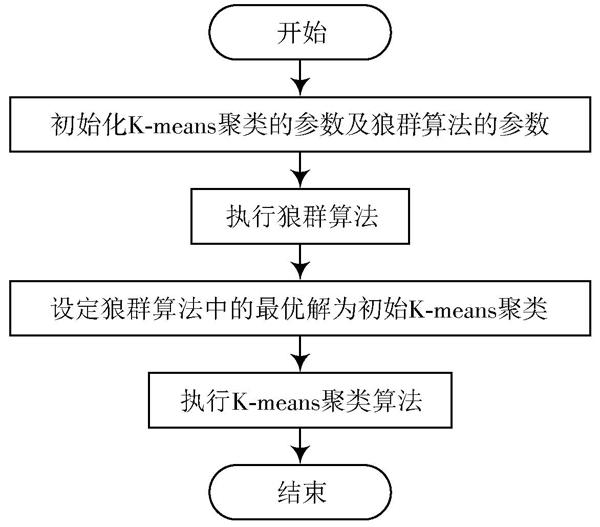
圖4 ?群智優化的K?means聚類算法流程
3 ?實驗結果與分析
3.1 ?實驗環境配置
為了驗證所提算法的性能,本文搭建Hadoop云計算平臺,在Linux操作系統上進行測試與分析。Hadoop集群所用軟件版本信息如表1所示。3個Hadoop集群實驗根據不同IP分配設立3個主機節點,各節點配置信息如表2所示。在HDFS分布式文件系統中,集群包含唯一的Name Node和2個Data Node,其中Name Node實現數據管理功能,Data Node實現數據存儲功能。
使用一組人工數據集Dataset1對加權K?means聚類算法[9]和提出的群智優化K?means聚類算法進行仿真實驗。該數據集Dataset1包含200個樣本,類別數為3。實驗中狼群算法誤差目標值為0.000 1,人工狼的數目為50,最大進化次數為100,更新比例因子為4。
表1 ?Hadoop集群所用軟件版本

表2 ?Hadoop集群中各節點配置信息


3.2 ?聚類效果比較
采用聚類正確率和聚類錯誤率兩個指標對不同算法的聚類效果進行量化評估,計算公式如下:
加權K?means聚類算法和本文提出的群智優化K?means聚類算法的聚類精度比較結果如表3所示。從表3中可以看出,群智優化K?means聚類算法具有較好的全局優化穩定性,聚類劃分更明確,獲得了更好的聚類效果。
表3 ?聚類精度比較
4 ?結 ?語
本文提出一種基于群智能算法的大數據K?means聚類挖掘算法。在云計算環境下采用群智能算法中的狼群算法對傳統數據挖掘K?means聚類算法進行改進。得出如下結論:本文提出的混合聚類算法解決了傳統聚類算法對初始中心敏感、容易出現陷入局部最優的問題,獲得了較好的全局最優解;相比加權K?means聚類算法,提出的改進算法表現出更好的聚類效果,但是算法的迭代時間還有待改善和研究。
參考文獻
[1] BERA S, MISRA S, RODRIGUES J J P C. Cloud computing applications for smart grid: a survey [J]. IEEE transactions on parallel & distributed systems, 2015, 26(5): 1477?1494.
[2] WHAIDUZZAMAN M, SOOKHAK M, GANI A, et al. A survey on vehicular cloud computing [J]. Journal of network & computer applications, 2014, 40(1): 325?344.
[3] JULA A, SUNDARARAJAN E, OTHMAN Z. Cloud computing service composition: a systematic literature review [J]. Expert systems with applications, 2014, 41(8): 3809?3824.
[4] LU H, SETIONO R, LIU H. Effective data mining using neural networks [J]. IEEE transactions on knowledge & data engineering, 2016, 8(6): 957?961.
[5] LINDEN A, YARNOLD P R. Using data mining techniques to characterize participation in observational studies [J]. Journal of evaluation in clinical practice, 2016, 22(6): 835?843.
[6] 胡存剛,程瑩.基于粒子群算法的大數據智能搜索引擎的研究[J].計算機技術與發展,2015,25(12):14?17.
HU Cungang, CHENG Ying. Research on big data intelligent search engine based on particle swarm optimization algorithm [J]. Computer technology and development, 2015, 25(12): 14?17.
[7] 劉先花.基于群體協同智能聚類的大數據存儲系統設計[J].現代電子技術,2017,40(23):138?141.
LIU Xianhua. Design of big data storage system based on group collaborative intelligent clustering [J]. Modern electronics technique, 2017, 40(23): 138?141.
[8] KHAN M, JIN Y, LI M, et al. Hadoop performance modeling for job estimation and resource provisioning [J]. IEEE transactions on parallel & distributed systems, 2016, 27(2): 441?454.
[9] AMORIM R C D, MAKARENKOV V. Applying subclustering and Lp distance in weighted K?means with distributed centroids [J]. Neurocomputing, 2016, 173(3): 700?707.
[10] YI T, LI H, WANG C. Multiaxial sensor placement optimization in structural health monitoring using distributed wolf algorithm [J]. Structural control & health monitoring, 2016, 23(4): 719?734.
