面向非均衡數(shù)據(jù)類的樸素貝葉斯改進算法
2019-09-02 03:28:44譚志侯濤文
現(xiàn)代電子技術 2019年9期
關鍵詞:數(shù)據(jù)挖掘
譚志 侯濤文


摘 ?要: 針對樸素貝葉斯分類器存在對非均衡樣本分類時,易將少數(shù)類樣本分到多數(shù)類的問題,利用感受性曲線的性質和深度特征加權的思想,提出一種面向非均衡數(shù)據(jù)類的樸素貝葉斯加權算法(DA?WNB)。為了驗證該算法對不平衡數(shù)據(jù)分類的有效性,實驗結果以AUC、真正類率、整體精度為指標,仿真結果表明,該算法能提高少數(shù)類分類準確率(最高達60%),且能保持較高的整體精度。
關鍵詞: 樸素貝葉斯; 監(jiān)督學習; 感受性曲線; 非均衡樣本; 深度特征加權; 數(shù)據(jù)挖掘
中圖分類號: TN911.1?34; TP3 ? ? ? ? ? ? ? ? ? ?文獻標識碼: A ? ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2019)09?0118?05
An improved naive Bayesian algorithm for unbalanced data classes
TAN Zhi, HOU Taowen
(Beijing University of Civil Engineering and Architecture, Beijing 100044, China)
Abstract: Naive Bayesian classifier is easy to divide minority?class samples into majority class samples while classifying unbalanced samples. In view of this phenomenon, an deep AUC (area under curve) weighted naive Bayesian (DA?WNB) algorithm for unbalanced data classes is proposed, which is based on property of receiver operating characteristic curve and thought of deep feature weighting. In order to verify the effectiveness of the algorithm for unbalanced data classification, the AUC, true positive rate (TPR) and overall accuracy are taken as the indicators for experiments. The simulation results show that the algorithm can improve the minority?class classification accuracy highest to 60%, and can maintain the high overall accuracy.
Keywords: naive Bayesian; supervised learning; receiver operating characteristic curve; unbalanced sample; deep feature weighting; data mining
0 ?引 ?言
樸素貝葉斯(Naive Bayesian,NB)是現(xiàn)今最普遍的監(jiān)督學習分類算法,以計算成本低、運行效率高著稱,被廣泛用到文本分類、信息檢索、醫(yī)療診斷等領域。NB基于一個強獨立性假設,具體指各特征向量相互獨立且同等重要,這導致分類時損失大量有益信息。
研究者為了削弱獨立性假設造成的不良影響,提出不同形式加權貝葉斯算法。加權算法的關鍵是利用指標衡量各個特征重要性,然后將指標轉化為權值形式。文獻[1]提出用相對熵計算每個屬性在分類中的重要程度。文獻[2]提出用差分進化算法搜索出最佳權值。文獻[3]通過多元線性回歸模型分析各特征之間的聯(lián)系,再將相關度轉化為權值系數(shù)。Kim T于2016年提出NB加權算法是為了最大化整體分類精度,沒有考慮非均衡樣本分類問題。
非均衡分類問題始于二分類任務中數(shù)據(jù)存在偏態(tài)的問題[4],即在二分類任務中,一類的樣本數(shù)目遠遠大于另一類的樣本數(shù)目。傳統(tǒng)監(jiān)督學習分類算法都假設類的樣本數(shù)量大致相同,在對非均衡樣本分類時,往往易將少數(shù)類樣本分到多數(shù)類,導致分類器性能大大降低。其原因是分類器訓練是為了最大化整體精度,當多數(shù)類樣本準確識別時,錯分少數(shù)類樣本不影響訓練效果。現(xiàn)實中,數(shù)據(jù)類經常表現(xiàn)出非均衡的狀態(tài)[5],比如垃圾郵件多于正常郵件,謠言多于真相等。為了精準識別少數(shù)類樣本,眾多研究者提出了各種改進方法,主要分為重采樣和代價敏感學習算法兩類。文獻[6]提出從不平衡數(shù)據(jù)特征研究非均衡數(shù)據(jù),并討論非均衡數(shù)據(jù)分類器的評價指標,文獻[7]通過集成算法解決不平衡問題,Kim S基于NB提出在計算似然概率時,用泊松分布代替多項式分布,同時考慮樣本大小標準化對分類結果的影響。Rennie等提出3種規(guī)范數(shù)據(jù)集的方法,并通過實驗確定了三種方法的實用性順序。代價敏感學習被結合到各種經典分類器,比如決策樹[8]、支持向量機[9]。樸素貝葉斯加權算法在不平衡數(shù)據(jù)分類領域的應用仍未被挖掘。
Kim T于2016年提出了一種高效且針對非均衡數(shù)據(jù)集的貝葉斯加權算法[10]。文獻[11]利用感受性曲線對偏態(tài)數(shù)據(jù)集不敏感的性質,實現(xiàn)了樣本重要特征選取和特征加權。本文在Kim T提出的算法基礎上結合深度特征加權的思想[12],使算法原理更貼近實際,進一步減弱獨立性假設對非均衡樣本分類的影響。
1 ?研究背景
1.1 ?樸素貝葉斯
樸素貝葉斯是一個簡單高效的分類模型,分類原理是將測試樣本[x]轉化為數(shù)據(jù)特征向量[a1,a2,…,am],然后通過最大似然估計實現(xiàn)分類,如下:
式中:[cx]為NB分類器預測的類別;[Pc]稱為先驗概率,為[c]類別樣本個數(shù)占所有類別樣本個數(shù)的百分比;[Pa1,a2,…,amc]稱為似然概率,指在[c]類中各個特征同時出現(xiàn)的概率。先驗概率和似然概率通過訓練樣本得到。樸素貝葉斯分類器假設各個特征相互獨立且同等重要,得出:
式中[Paic]在數(shù)據(jù)離散時采取多項式分布形式計算,在數(shù)據(jù)連續(xù)時采用高斯分布模擬。雖然獨立性假設不切實際,但提出NB多數(shù)情況下能準確分類的原因是分類判別式只作為區(qū)別函數(shù),不代表實際發(fā)生概率。
1.2 ?深度特征加權樸素貝葉斯(D?WNB)
加權貝葉斯分類器是基于不同特征重要性有差異的事實,通過訓練樣本,得到不同特征對應的權值,代入式(3)實現(xiàn)分類。
文獻[12]提出深度特征加權貝葉斯分類器,指出在對離散型數(shù)據(jù)分類時,大多數(shù)改進形式都只對條件概率的公式進行了加權,沒有將訓練得到的權值加入到條件概率的計算當中,為更好利用權值中所含信息,形式變換為:
式中:[naic]指第[c]類中[ai]的個數(shù);[nc]指[c]類別中所有樣本的個數(shù);[ni]指第[i]個特征向量不同特征值的個數(shù),它與分子中“1”是為了避免零概率問題。其中,[Wi]通過特征抽取得到,選取的特征[Wi=2],其他特征[Wi=1],這加強了重要特征在預測中的作用,降低了樸素貝葉斯假設的影響。
1.3 ?AUC加權樸素貝葉斯
真陽性率(TPR)和假陽性率(FPR)是描述感受性曲線(Receiver Operating Characteristic Curve,ROC)和AUC(Area Under Curve)的重要指標。
True Positive(TP),指樣本正確類別為正類,分類器預測類別為正類,TPR指TP的個數(shù)占正類總數(shù)的比例;False Positive(FP),指樣本正確類別為負類,但分類器預測類別為正類的樣本,F(xiàn)PR指FP的個數(shù)占負類總數(shù)的比例。在不同閾值(區(qū)別正樣本、負樣本的得分臨界值)的情況下,得到不同的TPR和FPR,再以TPR為縱坐標,F(xiàn)PR為橫坐標,得到一個經過(0,0),(1,1)的曲線,即為ROC,AUC指ROC曲線下的面積。二者常被用來評價二值分類器的優(yōu)劣。
ROC曲線具有三大優(yōu)點[11]:
1) ROC曲線下面積越大,即AUC越大,其分類能力越強;
2) ROC曲線下的面積可以轉化為標量AUC,能夠體現(xiàn)ROC曲線的分類能力;
3) 當測試樣本中正類和負類樣本數(shù)比變化時,測試結果ROC曲線基本保持不變,能體現(xiàn)AUC作為非均衡樣本分類器性能指標的穩(wěn)定性。
根據(jù)以上性質,Kim T等提出AUC加權樸素貝葉斯(AUC Wighted Naive Bayesian,A?WNB),該算法將單個特征作為整個訓練樣本,用NB訓練出每個特征對應的[AUCi],然后通過式(6)或式(7)計算似然概率,代入式(1)實現(xiàn)分類。
對離散型數(shù)據(jù)集:
2 ?提出的DA?WNB算法
現(xiàn)實中存在離散型數(shù)據(jù)和連續(xù)型數(shù)據(jù),所以為提高數(shù)據(jù)模擬精度和算法實用性,本文從這兩方面提出DA?WNB。
2.1 ?離散型數(shù)據(jù)集
此時函數(shù)隨著自變量[Wi]的增加而增加,相當于[Wi]越大,函數(shù)值越接近[fai-],在計算[cx]時,越接近[fai-]的函數(shù)值所取的指數(shù)權值[Wi]越大。
綜上可得,深度特征加權樸素貝葉斯的本質是權值越大的特征,似然概率越接近該特征值發(fā)生的頻率,在判別式計算中起到的作用越大,即該特征對預測實際類別的重要性越大。所以在A?WNB的基礎上,將各個特征對應的[AUCi]形式作為權值加入到特征值條件概率計算之中,更能突出不同特征在分類中的不同重要性,使算法思想更符合實際。
2.2 ?連續(xù)型數(shù)據(jù)集
式(7)中標準差乘[1-AUCi]的原因如下:
1) AUC值越大,標準差越小,同一特征值[ai]計算得出的似然概率會增大,AUC值小則增長幅度較小,能突出AUC大的特征在判別式計算中的重要性;
2) 這種轉變能夠擴大判別式計算下同一特征值在不同類別中的似然概率差值[5]。若在式(7)基礎上加入指數(shù)權值,可繼續(xù)擴大該優(yōu)勢。
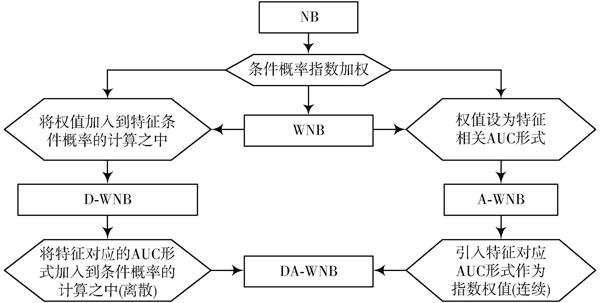
將深度特征加權思想應用于A?WNB中,提出兩種形式的DA?WNB(Deep AUC Weighting Naive Bayesian,深度特征AUC加權樸素貝葉斯)算法。具體形式見式(9)~式(12),所提出算法與其他四類算法的關系如圖1所示。
圖1 ?五種算法的關系
采取這兩種形式的原因如下:將權值擴大到1~2的范圍,更易區(qū)分重要特征和次要特征;兩種權值比較進行實驗,判斷權值變化程度大的DA1?WNB形式是否起到更好的效果。
3 ?實驗與分析
3.1 ?仿真實驗
非均衡數(shù)據(jù)大多為兩類,因此從UCI機器學習庫中選取13個數(shù)據(jù)集進行二分類實驗,規(guī)定正類為少數(shù)類。這些數(shù)據(jù)集來源于眾多領域,有圖像、醫(yī)療,郵件等,具體情況如表1所示。為簡化訓練復雜度,同時保證分類的精度,特征抽取時,舍去不利于分類的特征(對應AUC值低于50%)。實驗結果如表2所示,表中加粗數(shù)字為行中最大值。AUC,TPR,ACC(精度)通過文獻[11]中的方法計算。
表1 ?數(shù)據(jù)具體描述
3.2 ?結果分析
1) 從表2可看出,DA1?WNB和A?WNB的少數(shù)類分類準確率較NB有顯著提高,9個樣本TPR超過了NB,7個樣本AUC超過了NB。但其對樣本總數(shù)少的樣本分類時,如樣本3,結果不如預期。主要原因是,少量數(shù)據(jù)時主成分提取不準確,兩個加權算法擴大了次要特征的作用,導致了TPR降低。
2) TPR的增加伴隨著FPR的增加,這會導致分類器整體精度的降低,最佳結果是在TPR增長相同的情況下,F(xiàn)PR增加較少,精度降低較少。相對于NB,A?WNB對一些數(shù)據(jù)集分類時,極大降低了精度,比如第6和第9個樣本(最高損失14.3%),而DA?WNB 對13個樣本分類時都未表現(xiàn)出精度失衡(最高損失5.4%)。這說明DA?WNB穩(wěn)定性強于A?WNB。
表2 ?實驗結果
3) 較DA1?WNB,DA2?WNB在對第2和第9個樣本分類時TPR失常,其他表現(xiàn)持平。觀察發(fā)現(xiàn),兩樣本在NB分類下TPR較低。這說明主成分抽取準確,但其沒有起到突出主成分的作用。主要原因在于,兩樣本中只有個別重要特征對應的AUC較大,其他都接近50%。因此,權值變化程度大的DA1?WNB算法能避免損失主成分的重要信息,更貼近實際。
4 ?結 ?語
在實際應用中,數(shù)據(jù)分布往往是偏態(tài)的。樸素貝葉斯對偏態(tài)數(shù)據(jù)分類時,結果易傾向于多數(shù)類,導致少數(shù)類準確率降低。本文針對此問題,綜合AUC對偏態(tài)樣本集不敏感的性質和深度利用權值信息的思想,提出加權形式貝葉斯算法DA?WNB。結果顯示,DA?WNB有效地提高了少數(shù)類分類的準確率,且較A?WNB不易總體精度失常,同時證明了權值變化程度較大的DA1?WNB有利于保留主成分重要信息。算法不足在于未能準確提取小樣本集主要特征。今后將利用多項指標得出權值,并挖掘主要特征與權值之間的關系,這將更大程度減弱樸素貝葉斯獨立性假設的影響。
參考文獻
[1] LEE C H, GUTIERREZ F, DOU D. Calculating feature weights in naive Bayes with Kullback?Leibler measure [C]// 2011 IEEE International Conference on Data Mining. Vancouver: IEEE, 2011: 1146?1151.
[2] WU J, CAI Z. Attribute weighting via differential evolution algorithm for attribute weighted naive Bayes (WNB) [J]. Journal of computational information systems, 2011, 7(5): 1672?1679.
[3] WANG X, SUN X. An improved weighted naive Bayesian classification algorithm based on multivariable linear regression model [C]// 2017 International Symposium on Computational Intelligence and Design. Hangzhou: IEEE, 2017: 219?222.
[4] KRAWCZYK B. Learning from imbalanced data: open challenges and future directions [J]. Progress in artificial intelligence, 2016, 5(4): 1?12.
[5] LEE J S, ZHU D. When costs are unequal and unknown: a subtree grafting approach for unbalanced data classification [J]. Decision sciences, 2011, 42(4): 803?829.
[6] PRATI R C, BATISTA G E A P A, SILVA D F. Class imba?lance revisited: a new experimental setup to assess the performance of treatment methods [J]. Knowledge & information systems, 2015, 45(1): 1?24.
[7] GALAR M, FERNANDEZ A, BARRENECHEA E, et al. A review on ensembles for the class imbalance problem: bagging, boosting, and hybrid?based approaches [J]. IEEE transactions on systems man & cybernetics Part C, 2012, 42(4): 463?484.
[8] KRAWCZYK B, WONIAK M, SCHAEFER G. Cost?sensitive decision tree ensembles for effective imbalanced classification [J]. Applied soft computing, 2014, 14(1): 554?562.
[9] YAN Q, XIA S, MENG F. Optimizing cost?sensitive SVM for imbalanced data: connecting cluster to classification [EB/OL]. [2017?11?05]. https://arxiv.org/pdf/1702.01504.pdf.
[10] KIM T, CHUNG B D, LEE J S. Incorporating receiver opera?ting characteristics into naive Bayes for unbalanced data classification [J]. Computing, 2016 (3): 1?16.
[11] KRUPINSKI E A. Receiver operating characteristic (ROC) analysis [J]. Frontline learning research, 2017, 5(3): 31?42.
[12] JIANG L, LI C, WANG S, et al. Deep feature weighting for naive Bayes and its application to text classification [J]. Engineering applications of artificial intelligence, 2016, 52(C): 26?39.
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
