人工智能在骨質疏松癥中的應用研究綜述
2019-09-09 03:38:38尹梓名孫大運胡曉暉孔祥勇黃正行
小型微型計算機系統 2019年9期
尹梓名,孫大運,胡曉暉,孔祥勇,黃正行
1(上海理工大學 醫療器械與食品學院,上海 200093)2(上海市浦東新區浦南醫院 脊柱外科,上海 200125)3(浙江大學 生物醫學工程與儀器科學學院,杭州 310007) E-mail:weisskopf@hotmail.com
1 引 言
在世界衛生組織(World Health Organization,WHO)的定義中,骨質疏松癥是一種以骨量減少、骨組織微結構破壞、骨骼脆性增加和易發生骨折的全身性疾病[1,2].考慮到骨質疏松性骨折和骨強度密切相關,美國國立衛生研究院(National Institutes of Health,NIH)將骨質疏松定義為一種以骨強度降低致使肌體患骨折危險性增加為特征的疾病[3].其表現為骨密度降低和骨蛋白濃度的變化.骨質疏松癥會影響全身骨骼,導致骨折風險增加,且沒有明顯的預兆.隨著年齡的增加,骨密度降低,骨折風險增加,若不及時發現和治療,導致病情加重和死亡率增加.
常見的骨質疏松性骨折發生在髖部、脊椎、腕部等部位,且年齡是判斷骨質疏松癥的重要因素之一,在50歲以后,骨質疏松癥的發病率顯著增加[4].骨質疏松癥可根據其病因分為原發性和繼發性.原發性骨質疏松癥多發病于絕經后婦女群體,繼發性骨質疏松癥是由于疾病或藥物等原因所致[5],臨床上以內分泌代謝疾病、結締組織疾病、腎臟疾病、消化道疾病等為主,可能發生在任何群體身上.骨質疏松癥的發病率高,前期沒有明顯的癥狀和警示信號,第一個明顯癥狀往往是骨折.正因為這些原因,人們意識到自己患有骨質疏松時,往往已經是晚期,所以骨質疏松癥又被稱為“無聲的流行病”,及時的預測骨質疏松癥顯得尤為重要.
在骨質疏松癥的診斷中,X射線可以觀察到骨骼的輪廓和內部結構,但其識別能力較低,只有當骨量丟失30%才能發現;從單光子骨礦物質密度(Bone Mineral Density,BMD)測定儀、雙光子BMD測定儀、定量CT檢查,到目前通用的雙能X線BMD測試儀(Dual Energy X-ray Absorptiometry,DXA)等方法也可以測量骨量[2].DXA被認為是黃金標準,但即使在大多數發達國家,使用這種設備的機會仍然不足[6].所以,對骨質疏松的診斷還較為困難.同時,骨質疏松癥的治療成本較高,造成了重大的經濟損失.根據世界范圍的預測,目前髖部骨折的費用中,男性為36億美元,女性為190億美元,到2050年,預計男性為140億美元,女性為730億美元[7].
2017年7月,國務院印發的《新一代人工智能發展規劃》中提到,應深化人工智能在智能醫療領域的應用,推廣應用人工智能診療新模式、新手段,建立快速精準的智能醫療體系.隨著醫療信息化的快速發展,電子病歷和健康檔案的實行,產生了大量的數據信息.通過人工智能技術與醫療大數據的結合,可以提升醫療衛生服務能力,解決醫療資源緊缺等問題.例如:人工智能技術通過對海量的醫學文獻、病例數據和診斷方案進行快速學習,可以分析出數據之間的隱含關系;通過對醫學影像的智能分析,能夠準確的進行特征提取,定位病灶,從而輔助醫生進行預測、診斷[8].
本文旨在對人工智能在骨質疏松癥中的應用進行綜述,通過對相關研究所涉及的技術、方法等進行系統討論,使讀者了解人工智能相關技術在骨質疏松領域的應用現狀和存在問題.本文結構如下:首先對常用醫學人工智能技術進行了介紹,包括基于啟發式知識的方法和常用的基于機器學習的方法;然后從骨質疏松癥的危險因素分析、風險預測和識別診斷三方面,對人工智能技術在骨質疏松癥中應用的相關研究做了回顧總結;最后,對其現存的局限性做了總結并對未來發展進行了展望.
2 常用醫學人工智能技術簡介
將人工智能技術應用在醫學領域,主要有兩種方式:基于啟發式知識的方法和基于機器學習的方法.
2.1 基于啟發式知識的方法
基于啟發式知識的方法主要應用于構建醫學專家系統,依賴于存儲在知識庫中的專家知識和 推理引擎中的推理技術,像專家一樣對病情進行診斷.主要包含規則推理、框架推理和基于臨床指南模型的推理等方法.
2.1.1 規則推理
規則是一種特定領域的知識表達,它封裝了用于決策的邏輯流程.在基于產生式規則的系統中,每一個知識單元是一個單獨的IF-THEN邏輯語句,推理引擎評估可用的數據和語句,選擇下一個執行的語句.產生式規則的格式是IF-THEN語句:
IF(condition) THEN (action)
(condition)代表一條邏輯語句,如果為真,就執行(action).Condition部分也稱作語句的左手邊(left-hand side,LHS),Action部分被稱為右手邊(right-hand side,RHS).Condition 可以是一個簡單的、與單個可用數據值的比較,也可以是一個復雜的布爾邏輯語句,如:IF 紅斑AND 化膿AND NOT 腺病,THEN 結論“病毒性咽炎”.基于產生式規則的推理由匹配、選擇和執行組成一個不斷重復的環.
2.1.2 框架推理
框架是把某一特殊時間或對象的所有知識存儲在一起的一種復雜的數據結構.框架通常由描述事物的各個方面的槽組成,每個槽描述對象的某一方面的特性.槽由槽名和槽值組成,同一個槽有多種類型的槽值,每種類型成為槽值的一個側面.每個槽可以擁有若干個側面,而每個側面可以包含若干個值.框架如何設計取決于具體問題.一般來說,在實際應用中,使用一個框架是不夠的,必須同時使用多個框架,并組成框架系統.框架是一種通用的知識表達形式,目前關于如何建立框架還沒有統一的方法論,通常是根據具體問題具體分析.基于框架的系統的優點是具有良好的繼承性、結構化和自然性,以及推理靈活多變.它的不足之處主要在于它不善于表達過程性知識,而臨床診斷恰恰是具有創造性的思維過程,所以基于框架的系統在實際中應用的例子并不多.
2.1.3 基于臨床指南模型的推理
在臨床實踐中,臨床指南作為一系列診斷標準的集合可用于指導臨床診斷.從20世紀90年代中后期一直到21世紀初,隨著臨床指南研究的發展,出現了許多以臨床指南為建模對象的模型和方法,稱為計算機可解釋的指南(computer-interpretable guideline,CIG),比較著名的有Asbru[9],PROforma[10],EON[11],GLIF[12],SAGE[13]等,并涌現出一大批根據這些模型開發的專家系統,如ATHENA[14],PRODIGY[15]等.這些指南模型各有偏重,GLIF方法關注指南的標準化,PROforma關注于執行方面,Asbru關注于復雜時間計劃的表達和可視化,EON關注于支持指南開發和執行的架構的開發.這種基于臨床指南模型構建專家系統的方法本質上也是構建專家系統的方法.與傳統專家系統相比,它只是在構建思路上稍有不同.它不將診斷視為一個單獨的事件,而是將其視為一個持續的、從收集體征數據,檢查檢驗,重新評估數據,直到足夠確信度的結論并采取治療措施的過程.它在知識的表達方式上并不用基于符號的方法,而是將其抽象成一個個的流程圖.在診斷的過程中,基于CIG的專家系統提示醫生收集各種信息,然后將形式化的指南知識和最新的病人臨床數據進行匹配,最后提供基于特定病人的建議,影響醫生的臨床行為.
上述幾類專家系統在各自的應用場景下取得了一定的效果,但是有相當一部分系統只是停留在評估階段,并未在臨床上獲得廣泛的接受.拋開系統應用設計層面的問題,最主要的原因就是專家系統中的知識相對于醫療的復雜性來說還是過于簡單.醫學是一個相當復雜的體系,存有大量科學無法論證的不確定性,很難進行完全的醫學知識表達,并且傳統推理技術還無法模擬醫生診斷和治療的決策過程.比如在臨床信息缺失的情況下,臨床醫生可以憑借豐富的醫學經驗,依據不完整、不夠精確的臨床信息進行推理,確定臨床診斷并提出治療方案,但上述專家系統卻在這方面無法與醫生相比,在不確定的情況下難以進行準確的分析和推理.另外一種常見的情況是,由于疾病的復雜性和人的個體差異,很多疾病會出現非典型癥狀,依據啟發式方法構建的專家系統很難處理這部分情況,從而判斷錯誤.
2.2 基于機器學習的方法
常用在骨質疏松領域的機器學習方法,包括Logistics回歸、決策樹、隨機森林,人工神經網絡、支持向量機、集成學習以及最新的深度學習技術.
2.2.1 Logistics回歸
Logistic回歸(Logistics Regression,LR)[16]是一種機器學習技術,常用于數據挖掘、醫療診斷等領域.例如分析疾病的危險因素,并根據危險因素預測疾病發生的概率.LR是分析二進制醫學數據的黃金標準方法,因為它不僅提供預測結果,而且產生附加信息,例如診斷比值比.在流行病學研究中,Logistics回歸模型有兩個基本用途,篩選與應變量有聯系的自變量和控制混雜因素.公式(1)是簡單的Logistics回歸方程,其中g(x)=w0+w1x1+…+wnxn,wn是變量xn的權值.圖1是簡單的邏輯回歸模型.
(1)

圖1 邏輯回歸模型Fig.1 Logistic regression model
2.2.2 決策樹
決策樹(Decision Tree,DT)[17]是一種歸納學習算法,其利用一組無規則、無次序的實例推理出有效的分類規則,從而對數據進行分類.決策樹先通過訓練集進行學習,得到一個測試函數,然后根據不同的權值建立樹的分支,即葉子節點,在每個葉子節點下又建立層次節點和分支,藉此生成決策樹.決策樹以樹狀圖的形式表示預測結果,比較直觀.常用的決策樹算法包括ID3和C4.5等.ID3算法根據信息理論,采用劃分后樣本集的不確定性作為衡量劃分好壞的標準,在每個分葉
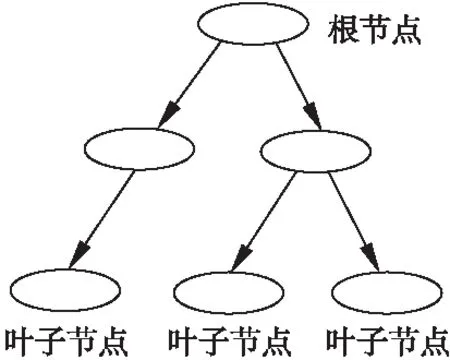
圖2 決策樹模型Fig.2 Decision tree model
節點選取時,選擇信息增益最大的屬性作為測試屬性.C4.5是對ID3算法的改進和擴展,其用信息增益率來選擇屬性,克服了ID3在選擇屬性時偏向選擇取值多的屬性的不足,當屬性值空缺時,通過使用不同的修剪技術以避免樹的過擬合[18].圖2是簡單的決策樹模型.
2.2.3 隨機森林
隨機森林(Random Forest,RF)[19]通過自助法重采樣技術,從訓練集中重復隨機抽取k個分類樹組成隨機森林.新數據的分類結果按分類樹投票多少形成的分數而定.其實質是對決策樹算法的一種改進,將多個決策樹合并在一起,每棵樹的建立依賴于一個獨立抽取的樣品.隨機森林中的每棵樹具有相同的分布,分類誤差取決于每一顆樹的分類能力和他們之間的相關性.特征選擇采取隨機的方法去分裂每一個節點,然后比較不同情況下產生的誤差.能夠檢測到的內在估計誤差、分類能力和相關性決定選擇特征的數目.單棵樹的分類能力可能很小,但在隨機產生大量的決策樹后,一個測試樣品可以通過每一棵樹的分類結果經統計后選擇最可能的分類[20].
2.2.4 神經網絡
人工神經網絡(Artificial Neural Network,ANN)是一種非線性映射方法,屬于隱式數學處理方法,不需要建立數學模型,是由網絡訓練的數據概括出的知識,以多組權值及閥值的方式存儲與各個神經元中,從而構建網絡知識,利用該知識來評估或預測相關因素的結果[21].在神經網絡應用于骨質疏松癥的診斷中,需要建立診斷分類的神經網絡模型,利用神經網絡對已有的數據集進行訓練,并用測試集對其進行仿真測試,再對未知的病情進行診斷分析,以得到較為準確的分類結果.
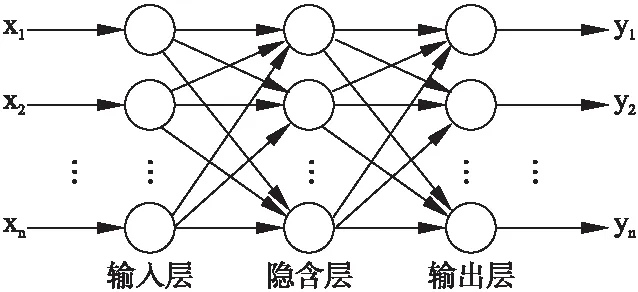
圖3 人工神經網絡結構Fig.3 Artificial neural network model
在人工神經網絡模型的訓練過程中,無需人為確定權重,可以減少診斷過程的人為因素,從而提高診斷的靠靠性,使診斷結果更有效、更客觀,有助于有效的降低骨質疏松診斷的誤診率和漏診率[22].圖3是簡單的人工神經網絡模型.
2.2.5 支持向量機
支持向量機(Support Vector Machine,SVM)基于核函數的分類方法,聯合多個參數值,在非線性空間利用支持向量機分類算法,能夠實現有效的數據分類,得到非線性分類邊界[23].神經網絡根據經驗風險最小化原則(Empirical risk minimization,ERM)來訓練學習,而支持向量機則根據結構風險最小化原則(Structural Risk Minimization,SRM)提高學習的泛化能力,避免了神經網絡存在的“過學習”問題[24].支持向量機在圖像處理、文本分類等領域應用廣泛.但是,對于輸入變量較多、樣本集較大的情況下,支持向量機的計算復雜性和空間復雜性會急劇增加,導致訓練時間長、耗用內存資源大.通常可從兩個方面來解決,一種是訓練算法的改進,如SMO、CSVM等;另一種是通過簡化訓練數據集來降低計算復雜性[25].圖4是簡單的支持向量機模型示意圖.
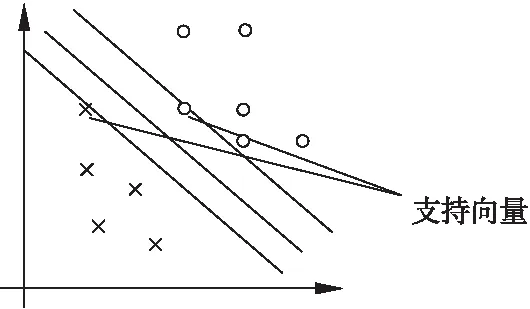
圖4 支持向量機模型示意圖Fig.4 Support vector machine model
2.2.6 集成學習
集成學習(Ensemble Learning,EL)是當下機器學習的熱門研究方向之一.通過構建并結合多個學習器來完成學習任務,以取得比單個分類器更好的效果,有時也被稱為多分類器系統(multi-classifier system)、基于委員會的學習(committee-based learning)等[26].一般來說,單一的算法在某方面存在缺陷,當處理復雜問題時,這些缺陷變得特別明顯和關鍵,例如其數據通常具有高度復雜性、不完整性的問題.在單個算法無法滿足實際診斷的需求的時候,多種不同算法的組合可以實
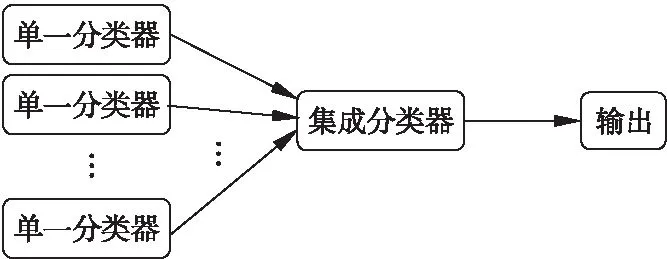
圖5 集成學習模型示意圖Fig.5 Ensemble learning model
現缺陷的互相彌補,保證機器學習的質量和效率,有效的降低骨質疏松預測、診斷的誤診率和漏診率.通常通過模型的可靠性、多樣性、準確性等來判斷集成模型的優劣.圖5是簡單的集成模型示意圖.
2.2.7 深度學習
深度學習(Deep Learning)是機器學習的新領域,旨在通過構建多隱含層的模型和大量的訓練集數據來學習更有效的特征,從而提高分類或預測的準確性[27].與傳統的淺層學習相比,深度學習具有以下特點:一是特征學習,其可以根據不同的應用自動從海量的數據中學習到所需的高級特征表示,更能表達數據的內在信息;二是深層結構,深度學習模型結構深,通常具有5層甚至更多層的隱含層節點,包含更多的非線性變換,使得擬合復雜模型的能力大大提高;三是無監督學習,模型通過數據內在的一些特征和聯系將數據自動分類[28].通過在訓練過程中加入無監督學習作為預訓練,使得深度學習模型相比人工神經網絡具有更好的分類能力.
3 人工智能在骨質疏松癥中的應用
人工智能在骨質疏松中的應用,根據其在骨質疏松癥中的作用目的,可以分別從骨質疏松癥的危險因素分析、風險預測、識別和診斷等方面分析.
3.1 骨質疏松癥的危險因素分析
研究表明,影響骨質疏松的危險因素復雜多樣.例如,肥胖[29]、體重指數(BMI)[30]、脂質分布[31-34]等都有可能是影響骨質疏松癥的危險因素.確定骨質疏松癥的危險因素,可以制定更有效的、有針對性的預防方案,以及根據危險因素對骨質疏松進行預測或診斷.這些都有待于利用人工智能技術進行精確分析和預測.
利用人工智能技術可以有效地分析影響骨質疏松癥的危險因素,為此,很多學者進行了大量的工作.2005年,Akkus Z 等基于多元二元回歸,來確定骨質疏松的危險因素,并評估骨質疏松的風險變量.這項研究表明,低水平的膳食鈣攝入、體育活動、教育和更年期延長是我們人群低骨密度風險的獨立預測因子,適量的膳食鈣攝入,結合日常體育鍛煉,提高教育水平,降低產次,延長母乳喂養時間,有助于骨骼健康[35].G Huang等基于多元回歸,分析危險因素與骨質疏松之間的關系.結果顯示,骨質疏松的主要危險因素,男性是年齡,女性是絕經后的持續時間[36].2006年,Chiu JS等基于人工神經網絡對骨質疏松癥的危險因素做了研究,認為影響骨質疏松癥的主要危險因素包括:人口學特征、人體測量和臨床資料(性別、年齡、體重、身高、體重指數、絕經后狀況、咖啡消費)[37].陳湘定等基于人工神經網絡,對影響骨密度的12個因素進行分析,結果表明,性別影響因素最大,身高、體重、年齡的作用均比基因的作用強,在基因中雌激素受體α基因作用很強,而骨鈣素(BGP)基因的作用最弱[38].2009年,C.Ordó?ez等基于支持向量機模型,研究影響骨質疏松癥的危險因素,研究顯示飲食生活習慣身高、體重、體重指數(BMI)、暴露于陽光下、鈣的攝入量、蛋白質的攝入量、懷孕次數、膽固醇水平、碳水化合物的攝入量、脂肪、維生素D、鉀、鈉等的因素,影響絕經后婦女的骨質疏松癥[39].2012年,X Ma等基于Logistics回歸,分析動物性食物與骨質疏松的關系.單因素回歸分析顯示與骨質疏松相關的因素有年齡、出生數、肥胖、受過高等教育、高收入、蔬菜和牛肉;多因素Logistic回歸分析顯示,雞蛋可增加骨質疏松癥的風險,牛肉和蔬菜可降低骨質疏松癥的風險[40].2013年,Anastassopoulos等采用人工神經網絡和遺傳算法的混合算法對骨質疏松癥的危險因素進行分析.結果表明更年期、年齡、酒精攝入量是重要的危險因素[41].2015年,Quan Liu等在老年髖骨骨折的危險性預測研究中,基于人工神經網絡分析其危險因素,同時證明男性模型比女性模型的危險因素少,具有更好的分類性能[42].2016年,李茂蓉等基于Logistics回歸,分析絕經后非糖尿病婦女骨質疏松癥影響因素,單因素Logistics回歸分析顯示,年齡、文化程度、產次、體質指數(BMI)、血清堿性磷酸酶(ALP)是骨質疏松的可能影響因素,多因素Logistics回歸顯示高齡、高ALP是中老年絕經后婦女骨質疏松發病的可能影響因素[43].表1是有關骨質疏松癥的危險因素分析的相關研究總結.
表1 有關骨質疏松癥危險因素分析的相關研究總結
Table 1 Summary of related studies on risk factors of osteoporosis

時間作者工具目的2005Akkus Z 等Logistics回歸危險因素分析2005G Huang等Logistics回歸危險因素分析2006Chiu JS等ANN識別、危險因素分析2006陳湘定等ANN危險因素分析2009C.Ordó?ez等SVM預測BMD、危險因素分析2012X Ma等Logistics回歸危險因素分析2013Anastassopoulos等ANN+GA危險因素分析2015Quan Liu等ANNS預測、危險因素分析2016李茂蓉等Logistics回歸危險因素分析
注釋:ANN(人工神經網絡)、ANNS(集成人工神經網絡)、SVM(支持向量機)、GA(遺傳算法)
從以上的研究中可以看出,在對骨質疏松的危險因素進行分析的過程中,Logistics回歸是最常用的機器學習算法.影響骨質疏松的最常見的危險因素包括性別、年齡、體重、教育程度、產次等臨床參數.同時可以發現,在骨質疏松癥的危險因素分析中,男性和女性存在差異性,對于男性來說,最重要的影響因素是年齡,而女性的絕經時間影響力較大.
3.2 骨質疏松癥的風險預測
在骨質疏松癥的風險預測中,我們從對骨質疏松癥的預測和對骨密度的預測兩方面進行研究.
3.2.1 對骨質疏松癥的預測
骨質疏松癥早期的癥狀不明顯,不易被發現,嚴重時容易導致骨質疏松性骨折,這常常對患者的生活質量產生顯著地負面影響,造成較大的經濟損失,甚至威脅生命.因此骨質疏松癥的早期診斷和預防是社會的重要醫學問題[44].如果可以對骨質疏松癥進行預測,就可以根據預測結果判斷,是否需要進一步診斷,也避免了額外的花費和影像輻射危險.世界衛生組織骨折風險評估工具(FRAX)[45]和Garvan骨折風險計算器[46],都被用來評估髖骨骨折的風險.也有很多研究從人工智能方向入手,對骨質疏松癥進行預測.2005年,Wang等基于人工神經網絡和決策樹的混合集成模型,對女性骨質疏松癥進行預測.結果顯示,集成模型相比單一模型具有較高的多樣性,有效的提高了預測的精度.然而,由于訓練后的神經網絡和決策樹模型之間的差異性不夠高,無法顯著提高集成模型的性能,需進一步提高其多樣性[6].同年,2005年,Sadatsafavi等采用人工神經網絡對伊朗絕經后婦女骨質疏松癥進行預測.結果表明,人工神經網絡模型預測性能高于傳統的回歸方法和目前公認的決策規則[47].2008年,Chin-Ming Hong等基于模糊神經網絡,對骨質疏松癥進行預測.結果顯示,采用骨質疏松危險因素問卷而不是其他侵入性方法或實驗室測量來預測骨質疏松癥,不僅可以顯著降低大規模篩查的成本,而且可以加快篩查過程[48].2010年,Mantzaris等基于概率神經網絡(PNN)和學習向量量化(LVQ)神經網絡來評估骨質疏松癥的風險,研究結果表明,PNN的正確率為96.58%,優于LVQ的96.03%[49].2010年,G Anastassopoulos等基于概率神經網絡(PNNS),評估骨質疏松癥的風險[50].2012年,支英杰等基于決策樹、人工神經網絡、Logistic回歸模型,對絕經后婦女的嚴重骨質疏松癥預測進行研究.通過比較三者的ROC曲線,發現,神經網絡和Logistics回歸的擬合度較好,說明在嚴重骨質疏松癥的預測研究中,可以考慮人工神經網絡和Logistics回歸[51].同年,孫鳳等基于多變量Logistics回歸模型,對骨質疏松癥進行預測[52].2013年,Tae Keun Yoo等基于流行的機器學習模型,對骨質疏松癥進行預測,并將其與四種傳統的臨床決策工具:骨質疏松自評工具(OST)、骨質疏松風險評估工具(ORAI)、簡單計算骨質疏松風險評估(SCORE)和骨質疏松風險指數(OSIRIS)進行比較.結果顯示,在將年齡、身高、體重、體重指數、絕經時間、母乳喂養時間、雌激素治療、高脂血癥、高血壓、骨關節炎和糖尿病等作為變量輸入的情況下,支持向量機模型優于其他模型[53].2014年,李超等基于神經網絡和支持向量機的集成模型,對原發性骨質疏松癥進行識別.結果顯示,集成模型充分利用神經網絡非線性映射、自適應、泛化能力和容錯能力強,以及支持向量機分類可靠度高,推廣性強的優點,其識別誤差小于單一模型[54].同年,方驍然等基于支持向量機模型,通過常規的體檢參數,對骨質疏松癥進行預測[55].2015年,Quan Liu等基于BP神經網絡,通過74個輸入變量,對老年髖骨骨折的危險性進行預測.結果表明,人工神經網絡在處理多輸入變量的復雜醫學模型方面是有效的.同時證明,男性模型比女性模型具有更好的性能,因為男性病例的復雜度低[42].同年,YC Juan等建立基于遺傳算法的集成分類器,采用健康檢查資料,預測骨質疏松癥[56].2016年,E Tejaswini等基于人工神經網絡,利用年齡、性別、身高、體重、受傷或手術史、藥物史、運動和相關的醫學問題,對骨質疏松癥進行預測[57].2017年,TP Ho-Le等基于人工神經網絡,通過年齡、骨密度、臨床因素和生活方式因素,對絕經后骨質疏松癥患者,患髖部骨折進行預測.研究表明,當BMD和非BMD因子結合訓練的模型,預測準確度為87%,ROC曲線下面積(AUC)為0.94,該模型比單獨使用BMD或非BMD因子訓練的模型分類效果好[58].
3.2.2 對骨密度的預測
目前骨質疏松的主要識別特征——低骨密度(BMD),主要通過雙能X射線吸收法(DEXA)、定量超聲(QUS)、定量計算機斷層攝影(QCT)等方法進行測量.這些方法所用的儀器設備非常昂貴,難以在貧窮國家廣泛推廣;且存在諸如X射線之類的輻射,影響人體健康.所以如果可以對骨密度值進行預測,則可以避免不必要的花費和健康人群的輻射影響.2003年,E.I.Mohamed等基于人工神經網絡,將人體測量數據(性別、年齡、體重、身高、體重指數、腰臀比和四個皮褶厚度之和)作為獨立輸入變量輸入人工神經網絡,可用于預測和估計特定部位的BMD值[59].2009年,C.Ordó?ez等基于支持向量機,研究骨密度和飲食及生活習慣的關系,并對骨密度值進行預測.同時結果表明,額外的鈣攝入,適當的暴露于陽光下,體重控制,有規律的體育活動和足夠的熱量攝入是減少絕經后婦女骨量損失的主要因素[39].2011年,FJDC Juez等基于人工神經網絡,通過營養習慣和生活方式,對骨密度進行預測.同時為了減少輸入變量的數量,使用遺傳算法處理原始變量,通過僅考慮重要變量的神經網絡模型,預測絕經后婦女的骨密度[60].2017年,M Shioji等基于人工神經網絡,通過年齡、體重、身高、絕經年齡、月經初潮年齡、絕經后持續時間、BMI、體脂百分比、脂肪質量、瘦體重、腰椎(L2-L4)或股骨BMD值,對絕經后婦女骨密度值及骨丟失率進行預測[61].
從以上相關研究可以看出,在骨質疏松癥或者骨密度的預測中,一般使用臨床問診、常規體檢參數等不需要花費過多金錢和過多儀器檢測得來的數據,對骨密度或者骨質疏松癥進行預測,從而判斷受試者是否需要進一步全面的診斷,降低醫療費用和患者被輻射的風險.表2是有關骨質疏松癥預測的相關研究總結.
3.3 骨質疏松癥的識別與診斷
骨質疏松癥的特征是骨礦物質含量的異常丟失,從而導致非創傷性骨折或骨結構變形的趨勢.因此,準確估計骨密度已成為確定骨質疏松癥狀態和在骨質疏松癥治療中患者隨訪研究的最重要的診斷方法.但是許多研究表明骨密度不足以預測骨質疏松性骨折的可能性,其他因素,如骨小梁的微觀結構和載荷分布對骨質疏松性骨折有顯著影響.以下,我們通過研究者分析所用數據源的不同類型來對相關研究進行回顧.
3.3.1 以問題量表為數據源
在不接受醫學影像檢查的情況下,通過問題量表、常規體檢參數等,可以對骨質疏松癥進行識別.
如:2006年,Chiu JS等基于人工神經網絡,通過人口學特征、人體測量和臨床資料(性別、年齡、體重、身高、體重指數、絕經后狀況、咖啡消費),對老年骨質疏松癥進行識別[37].2011年,程若珠等基于BP神經網絡,通過性別、身高、體重、臨床癥狀問診、胸腰椎及股骨頸骨密度,對骨質疏松癥進行識別[22].2013年,Sung Kean Kim等基于支持向量機模型,通過年齡、身高、體重、體重指數、絕經時間、母乳喂養時間、雌激素治療、高血壓、高脂血癥、糖尿病和骨關節炎等,對絕經后婦女骨質疏松癥進行識別,并與傳統的臨床決策工具——骨質疏松癥自我評估工具(OST)進行了對比.通過對比建立的SVM模型能更準確的區分骨質疏松癥婦女和對照婦女,年齡和體重與骨質疏松的發展密切相關[62].2016年,Pedrassani等基于J48決策樹模型,通過年齡段、先前骨折、先前骨折數目、先前股骨頸骨折、先前脊柱骨折、先前前臂骨折、先前t肋骨,藥物使用,更年期,鈣的使用,激素替代療法,甲狀腺藥物的使用,子宮切除術,卵巢切除術,診斷,體重指數(BMI),體重和三度肥胖等,對骨質疏松癥進行識別[63].
表2 有關骨質疏松癥風險預測的相關研究總結
Table 2 Summary of related research on prediction of osteoporosis

時間作者工具目的2003E.I.Mohamed等ANN預測BMD2005M.Sadatsafavi等ANN預測2005Wenjia Wang等ANN+DT預測2008Chin-Ming Hong等FNN預測2009C.Ordó?ez等SVM預測BMD、危險因素分析2010G Anastassopoulos等PNNS預測2010Mantzaris等PNN、LVQ預測2011FJDC Juez等ANN預測BMD2012支英杰等ANN、DT、Lo-gistics回歸預測2012孫鳳等Logistics回歸預測2013Tae Keun Yoo等SVM、RF、ANN、Logistics回歸預測2014方驍然等SVM預測2014Theodors Lliou等ANN、SVM、RF等預測2014李超等ANN+SVM預測2015YC Juan等GA預測2015Quan Liu等ANNS預測、危險因素分析2016E Tejaswini等ANN預測2017M Shioji等ANN預測BMD和骨丟失率2017TP Ho-Le等ANN預測髖骨骨折
注釋:ANN(人工神經網絡)、SVM(支持向量機)、DT(決策樹)、FNN(模糊神經網絡)、PNNS(集成概率神經網絡)、GA(遺傳算法)、RF(隨機森林)、LVQ(學習矢量量化)等
3.3.2 以醫學影像為數據源
醫學影像是醫學檢測中的常用手段,在骨質疏松癥的診斷中,我們可以通過特定部位(髖關節、腕關節、椎體等)的醫學影像,觀察其紋理、結構等,來進行識別.2005年,AM Badawi等基于模糊邏輯和神經網絡,對骨質疏松癥進行識別.結果顯示,該模型的診斷效率為97%,可以很好地識別骨質疏松癥[64].2007年,Chen等基于人工神經網絡,選取以下參數作為輸入:三個骨密度參數(股骨頸、全身、L2L4脊柱)、三個分形參數(最小、平均、最大)和年齡,對骨質疏松患者進行判別,達到81.66%的正確分類,相比之下,傳統的分類方法只能達到72%的正確分類[65].2008年,Moua Meneses等基于多層感知神經網絡,應用于顯微斷層圖像、X射線成像、骨識別中,對骨質疏松癥進行識別[66].第二年,作者基于人工神經網絡對圖像像素進行分類,對人骨小梁結構進行定量分析.結果表明,盡管骨小梁結構復雜,但人工神經網絡在圖像像素的識別和定量分析以及圖像的特征相容性方面是成功的[67].2010年,R.Jennane等基于遺傳算法,通過髖關節顯微CT圖像,對骨質疏松癥進行識別[68].同年,Zhi Gao等基于C4.5決策樹模型,對骨小梁顯微CT影像中提取的特征進行分類,以識別骨質疏松癥[69].2012年,Harrar K等基于多層感知(MLP)神經網絡,通過骨結構的五個特征:年齡、骨礦物質含量(BMC)、骨礦物質密度(BMD)、分形赫斯特指數(H.)和共流紋理特征(CoEn),來對骨質疏松癥進行早期診斷.研究結果顯示,MLP可以達到97%的正確估計,優于貝葉斯網絡的86%,Logistics回歸的96%[70].同年,Istanbullu,M等基于人工神經網絡和支持向量機,通過計算機斷層掃描圖片,來識別骨質疏松癥,ANN的準確率為70%,SVM的準確率為86%[71].2013年,Yan Xu等基于支持向量機和k-近鄰(KNN),通過顯微CT圖像進行骨質疏松診斷.研究選擇的圖像特征,包括骨體積/總容積(BV/TV)、骨表面/骨體積(BS/BV)、骨小梁數目(Tb.N)和體積拓撲分析(VTA)的其他四個特征.結果顯示SVM模型的分類效果優于KNN模型,同時除了選擇的特征外,圖像紋理特征也有助于骨質疏松的識別[72].同年,Sapthagirivasan等基于支持向量機模型,從髖關節的影像信息中提取骨小梁特征,以識別低骨密度的受試者[73].D.S.Li等基于支持向量機,通過體積拓撲分析從顯微CT圖像中獲得骨密度(BMD)以及與骨小梁(TB)結構相關的四個參數,識別骨質疏松癥[4].2014年,周珂等基于度量學習和支持向量機的集成模型,通過對骨質疏松紋理進行分析,來識別骨質疏松癥.結果顯示,基于度量的SVM模型比單獨使用度量學習和SVM 的識別率高,而且分類結果穩定,在臨床影像中應用可以盡快對患者進行確診和盡早治療[74].2015年,Tafraouti等基于支持向量機模型,對從X射線影像中提取的特征進行分類,來識別骨質疏松癥[75].2016年,劉健基于支持向量機,對顯微CT影響進行自動分類,診斷骨質疏松疾病[76].同年,2016年,N Kilic等基于隨機子空間方法和隨機森林(RSM-RF)集成模型,對骨質疏松癥進行識別[77].2017年,蔡潔等將從骨小梁圖像中提取出的紋理特征和形狀特征相結合,用支持向量機、K-最近鄰分類算法和線性判別分析方法,對骨質疏松癥進行識別.結果表明,紋理參數和性狀特征結合是,模型分類準確性比用一種參數的分類準確性高[78].同年,Muatapha Aouache等基于模糊決策樹(FDT)模型,通過對頸椎影像識別,對骨質疏松癥進行識別[79].Reshmalakshmi C等基于模糊專家系統和常規X射線圖像處理技術的集成模型,通過臨床影像,對骨質疏松癥進行識別.結果顯示,該集成模型有助于診斷骨質疏松和骨量減少[80].Yassine Nasser等提出了一種基于深度學習的骨質疏松癥診斷新方法[81].
在通過醫學影像骨質疏松的識別中,除了對特定部位的醫學影像進行研究,也可通過牙科醫學影像來判斷骨質疏松.據調查,絕經后婦女進行骨質疏松癥診斷的比例很低[82],但有很多機會去牙科所進行口腔護理和治療,每年拍攝大量的牙科全景影像(日本約1200萬,美國約1700萬)用于診斷和治療牙科疾病,如齲齒和牙周病,但沒有用于非牙科的診斷[83],從牙科全景影像中提取的平層寬度和形狀進行重新分類,對骨質疏松癥進行診斷,具有較好的敏感性和特異性.2007年,Arifin等基于模糊神經網絡(FNN),通過絕經后婦女的牙科全景影像,對骨質疏松癥進行識別.結果表明,FNN結合皮質寬度和形狀可用于牙科臨床骨質疏松癥患者的鑒別[84].2008年,Sooyeul Lee等基于支持向量機,使用X光影像,結合BMDS參數,區分骨質疏松骨折和非骨折組,并與僅適用BMDS的參數對比,檢測骨質疏松骨折的靈敏度和特異性顯著增加[67].2012年,M S Kavitha等基于支持向量機,通過牙科全景影像上關于下頜骨皮質寬度,對低骨密度的絕經后婦女進行識別[85].2013年,KM Subash等基于凝聚層級聚類(HAC)和支持向量機的集成模型,對牙齒的全景影像進行分類,對骨質疏松癥進行識別[86].2014年,Suprijanto 等基于支持向量機,通過牙齒全景影像,對骨質疏松癥進行識別[87].2016年,MS Kavitha等基于混合遺傳算法(GSF)模糊分類器,利用牙科數字影像,對骨質疏松癥進行識別,進一步將混合GSF分類器的性能與單個遺傳算法(GA)和粒子群優化(PSO)模糊分類器的性能進行了比較.結果顯示,使用混合GSF分類器對低骨密度和骨質疏松癥的識別性較好[88].2018年,D.Devikanniga等基于蝶形優化的人工神經網絡,通過數字牙科全景攝影的下頜皮質骨和小梁骨屬性,結合人口統計學屬性,來識別骨質疏松癥和正常人[89].
從以上的研究中可以看出,對于骨質疏松癥的識別,可以通過臨床問題量表、骨密度值、以及相關醫學影像等進行識別.單獨的骨密度值不足以對骨質疏松癥進行準確識別,醫學影像中提取骨骼的紋理特征、分形特征等參數,以及受試者的臨床問診、生活習慣等參數也對骨質疏松的識別有很大的幫助.所以,合理的將臨床問診、醫學影像等參數相結合,運用合適的人工智能算法可以提高分類模型的性能.表3是有關人工智能在骨質疏松癥識別診斷的相關研究總結.
4 討 論
4.1 人工智能在骨質疏松應用的制約因素
1)缺乏標準的公共數據集.因為骨質疏松領域沒有標準的公共數據集,所以每個研究者研究所用的數據都是自己收集的不同數據集.這些數據集具有地域、性別、人種等限制因素,使得訓練模型特異性、正確性等性能受到影響.同時,這也導致由不同研究者提出的人工智能算法間不能直接進行診斷性能的比較,無法評估相互之間算法的優劣.
2)研究所用的數據集規模較小.在已有的研究中,模型所使用的訓練集的規模都比較小(圖6是上述所列研究中采用不同訓練集容量的分布統計),可以看到0-100例數據占據了研究數目中的絕大多數,約有53%,3500-4000例數據的研究僅占4%,并且沒有4000例以上的研究.以這樣的數據規模生成的模型無法充分逼近疾病診斷的真實情況,存在局限性,也無法達到令臨床醫生滿意的診斷效果.骨質疏松領域缺乏高質量的大數據集.
表3 有關骨質疏松癥識別診斷的相關研究總結
Table 3 Summary of related research on identification of osteoporosis

時間作者工具目的2005AM Badawi等Logistics回歸+ANN識別2006Chiu JS等ANN識別、危險因素分析2007CL Benhamou等ANN識別2007Arifin等FNN識別2008Moua Meneses等ANN識別2008Sooyeul Lee等SVM識別2009Moua Meneses等ANN識別2010R.Jennane等GA識別2010Zhi Gao等C4.5識別2011程若珠等ANN識別2012Harrar K等MLP、貝葉斯、Logistics回歸識別2012Istanbullu,M等ANN、SVM識別2012M S Kavitha等SVM識別2013Yan Xu等SVM、KNN識別2013Sung Kean Kim等SVM識別2013Sapthagirivasan等SVM識別2013D.S.Li等SVM識別2013G Anastassopoulos等ANN+GA識別、危險因素分析2013KM Subash等HAC+SVM識別2014Suprijanto 等SVM識別2014周珂等度量學習+SVM識別2015Tafraouti等SVM識別2016Xinghu Yu等ANN識別2016MS Kavitha等GSF識別2016劉健SVM識別2016Pedrassani等J48識別2016N Kilic等RSM+RF識別2017蔡潔等SVM、KNN識別2017M.Aouache等FDT識別2017Yassine Nasser等深度學習識別2018D.Devikanniga等ANN識別
注釋:GSF(混合遺傳群模糊分類器)、RSM(隨機子空間)、FDT(模糊決策樹)、HAC(凝聚層級聚類)、MLP(多層感知器)
3)算法模型自身的局限性.一般來說,單一的算法在某方面存在缺陷,當處理復雜問題時,這些缺陷變得特別明顯和關鍵.在處理骨質疏松癥的問題時,危險因素復雜、多樣,單一的模型展現的性能受到限制,不能很好的滿足骨質疏松應用需求.例如,人工神經網絡作為一種非線性的映射方法,被廣泛應用的同時,其也存在缺陷.比如,所取的樣本的數量和質量很大程度上影響神經網絡模型的學習性能、網絡層數、與此同時,隱含層神經元的數量的選取也影響整個網絡的學習能力和效率等[90].傳統的BP算法隨應用廣泛,但存在易出現極值、收斂速度慢等問題.支持向量機(SVM)是一種新的機器學習技術,根據有限的樣本信息在模型的復雜性(即對特定訓練樣本的學習精度)和學習能力(即無錯誤的識別任意樣本的能力)之間尋求最佳折中,以獲得最好的推廣能力.但SVM存在核函數難求解,且需要大量存儲空間來計算函數的二次規劃的不足[91].所以將多種算法融合,揚長避短,形成新的算法來解決骨質疏松癥領域的問題是很多研究者采用的重要方法.
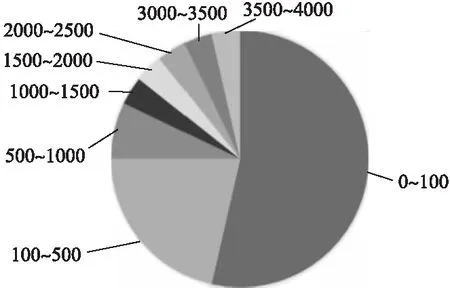
圖6 采用不同訓練集容量的研究分布圖Fig.6 Research distribution map with different training set capacity
4)缺少時間維度的分析.目前對于骨質疏松癥的預測和診斷的相關研究,僅針對單一病例某一個時間點進行判斷,缺少時間維度的數據.但實際在臨床中,不同時間點的癥狀對于預測疾病未來發展以及日后的治療方案的確定非常重要.如果能在積累臨床案例時,注意追蹤某個人一段時間內的數據,那么這樣的案例數目積累到一定程度,將更有利于患者的未來骨質疏松的預測.
4.2 未來發展方向
1)建立標準的公共數據庫.公共數據庫中的數據可供全球的骨質疏松研究者利用.公共數據庫中的數據應具備種類多樣、樣本量大等特點,還要充分考慮多地區間人種的差異.不同的地區的不同人群可以建立常模數據和異常數據.通過對其進行模型的訓練,可以更好的適應受試者多樣的特點.為建立標準數據庫,本文對相關研究中所用的骨質疏松癥相關危險因素進行了總結,如表4所示.
2)多種算法深層次結合.在單個算法無法滿足實際診斷的需求時,多種不同算法的組合可以實現算法缺陷的互相彌補,保證器學習的質量和效率,有效的降低骨質疏松癥預測、診斷的誤診率和漏診率.目前,集成模型以及多種算法融合的混合智能算法是一種研究趨勢,一些學者已經開展了相關的研究工作[88].
3)深度學習技術在骨質疏松上的應用.近年來,深度學習在圖像識別等領域取得了巨大的成功.在醫療領域,深度學習得到了很大的關注,例如對惡性腫瘤、肺部結節等疾病的學影像進行處理分析,來輔助醫生做診斷.骨質疏松癥的診斷也依賴醫學影像,所以深度學習與骨質疏松影像也會得到很好地結合,從而提高其診斷的準確性.
4)多模態數據分析.骨質疏松的預測非常復雜,需要醫生綜合多方面的臨床信息綜合判斷.如果研究僅以單一數據源進行分析,數據源所提供的信息往往有局限性,也不符合臨床實際.所以多模態數據的綜合分析是骨質疏松癥人工智能未來研究的一大趨勢.尤其是利用人工智能方法在臨床數據、量表數據、影像數據的基礎上再加入基因組學數據的分析,目前這方面的研究并不多,但已經有部分學者開始了這方面的研究[38].
表4 相關研究所用危險因素
Table 4 Risk factors used in relevant research

骨密度值圖像參數臨床因素1.股骨頸骨密度2.全身骨密度3.L2-L4脊柱的骨4.密度5.腰椎骨密度6.胸椎骨密度1.骨體積/總容積(BV/TV)2.骨表面/骨體積(BS/BV)3.骨小梁數目(Tb.N)4.分形參數5.紋理特征6.牙科全景照片上關于下頜骨皮質寬度1.種族2.教育3.職業4.婚姻5.月收入6.性別7.年齡8.體重9.身高10.體重指數11.腰臀比12.四個皮褶厚度之和13.絕經后狀態14.母乳喂養時間15.月經初潮年齡16.雌激素使用17.咖啡攝入量18.蛋白質攝入量19.酒精攝入量20.膽固醇水平21.碳水化合物的攝入量22.脂肪攝入量23.維生素D攝入量24.鉀、鈉的攝入量25.鈣的攝入量26.骨折歷史27.抗高血壓藥物使用28.更年期持續時間29.糖皮質激30.甲狀腺藥物的使用31.高血壓32.高血脂33.糖尿病34.骨關節炎35.心臟病史36.骨質疏松性肝病37.癌性白內障38.慢性呼吸道疾病39.便秘40.子宮切除術41.卵巢切除術42.骨痛43.足根痛44.腰膝酸軟45.下肢拘攣46.盜汗47.少氣懶言48.畏寒肢冷49.夜尿頻50手足心熱51.健忘52.握力53.飲食習慣54.生活習慣55.體育鍛煉56.懷孕次數57.出生或流產兒童數58.腰椎T值59.股骨T值60.大家族病史62.吸煙史
5 結 論
本文主要回顧了人工智能技術在骨質疏松癥中的應用.研究發現,人工智能技術在骨質疏松癥的預測、識別、以及危險因素分析中,相對于傳統方法,都有較好的性能.基于人工智能技術,在骨質疏松癥的預測中,通過臨床問卷和常規體檢參數,對骨密度或者骨質疏松性骨折進行預測,有助于受試者減少疾病花費和過多的輻射暴露;在骨質疏松癥的識別中,通過對問題量表或者醫學影像對其進行診斷,提高了模型的分類準確性;在骨質疏松癥的危險因素分析中,Logistics回歸被廣泛的應用.與此同時,人工智能技術在骨質疏松癥中的應用,依然存在很多的局限性,如:缺乏標準的公共數據庫、算法本身的局限性等.但隨著人工智能技術的不斷發展,如深度學習等技術的不斷深入研究,其在骨質疏松癥中的應用也會更加廣泛.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:36:04
今日農業(2021年17期)2021-11-26 23:38:44
食品安全導刊(2021年21期)2021-08-30 08:21:30
當代陜西(2021年12期)2021-08-05 07:45:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
冰雪運動(2016年4期)2016-04-16 05:54:56
核科學與工程(2015年4期)2015-09-26 11:59:03
