基于爬蟲大數據的網絡負載異常監測方法
2019-09-10 07:22:44楊毅
河南科技 2019年34期
楊毅

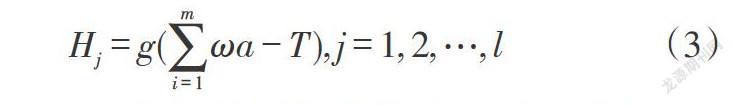
摘 要:針對傳統網絡負載異常監測方法中精準度較差、有效性較低等問題,本文提出一種基于爬蟲大數據的網絡負載異常監測方法。為了驗證該方法的有效性,將其與傳統監測方法進行對比實驗。實驗結果表明,該方法實用性和精準度更高,更適用于對網絡負載異常的監測。
關鍵詞:爬蟲大數據;網絡負載;異常監測
中圖分類號:TP393.08;TN915.02 文獻標識碼:A 文章編號:1003-5168(2019)34-0033-03
Network Load Anomaly Monitoring Method Based on Crawler Big Data
YANG Yi
(School of Information Engineering, Henan University of Animal Husbandry and Economy,Zhengzhou Henan 450018)
Abstract: Aiming at the problems of poor accuracy and low effectiveness in traditional network load anomaly monitoring methods, this paper proposed a network load anomaly monitoring method based on crawler big data. In order to verify the effectiveness of this method, it was compared with the traditional monitoring method. Experimental results show that this method is more practical and accurate, and more suitable for monitoring network load anomalies.
Keywords: crawler big data;network load;abnormal monitoring
隨著網絡信息技術的快速發展,網絡中接入的負載量成倍增長,而這些網絡負載產生的數據信息成為目前網絡環境中數據分析的來源[1]。因此,負載數據成為網絡信息中最重要的、最具價值的數據源。理論上,網絡負載越多,對采集到的數據樣本分析越有價值,但實際上,大量的負載連接到網絡中,會嚴重影響整個網絡環境的穩定性和功能性。在實際網絡環境中,在線負載量會受大數據平臺中接入網絡的負載總量、計算能力、相應時間及數據所能承載的上限限制,因此網絡負載與大數據平臺進行數據交換時必須與其建立起相應的有效連接[2]。為了避免因未進行有效通信的負載而占用通道的問題產生,提出一種網絡負載異常監測方法,提高網絡資源的利用效率。傳統監測方法是以服務器與負載是否產生通信為判定標準,但這種方法存在一定的局限性,需要占用較多的資源。本文提出一種基于爬蟲大數據的網絡負載異常監測方法,以判斷網絡負載的連接情況。
1 基于爬蟲大數據的網絡負載異常監測方法
1.1 網絡負載異常監測流程設計
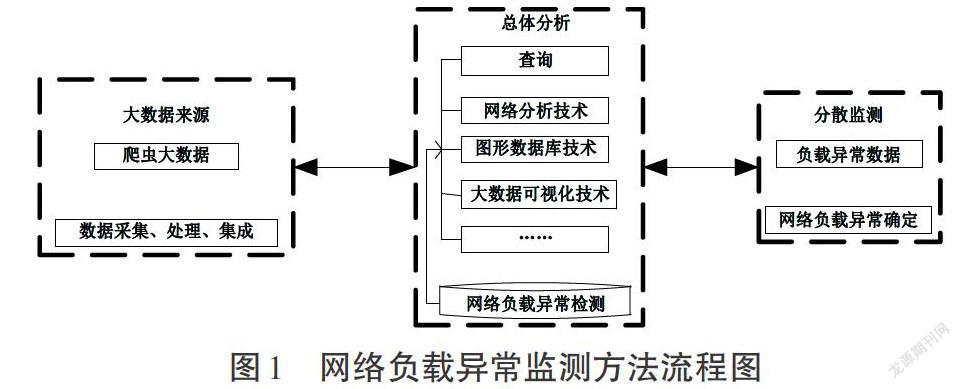
網絡爬蟲,又被稱為網頁蜘蛛、網絡機器人,是一種按照一定的規則,自動地抓取萬維網信息的程序或者腳本[3]。對網絡負載異常進行監測需要各類相關數據,而爬蟲大數據對獲取負載異常監測的相關數據具有一定程度的幫助。圖1為基于爬蟲大數據的網絡負載異常監測方法的監測流程設計。
基于爬蟲大數據的網絡負載異常監測方法是利用被監測的網絡負載數據,將采集到的數據信息與未出現異常的數據信息進行比較分析,找出負載異常情況。與傳統監測方法相比,該監測方法更能有效找出網絡負載異常的線索[4]。該方法的具體流程如下。
第一步:確定網絡負載異常目標。在對數據進行監測前,要確定需要被監測的具體網絡環境及其中的相關數據。
第二步:分析負載異常整體結構。為了獲取上述數據信息,需要對相應的網絡負載進行分析。
第三步:實現爬蟲大數據,采集所需異常數據。利用爬蟲大數據實現對上述數據信息的獲取。
第四步:對采集到的負載異常數據進行計算和分析。針對上述采集到的數據信息,在對大數據集成及預處理的基礎上,根據集中分析和分散核查的監測思路,利用大數據可視化的相應工具對數據進行分析,通過可視化的分析結果進行觀測,并快速從大數據信息中找出異常數據,獲取負載異常線索[5]。監測人員對負載異常進行監測的過程中,需要對異常數據進行細化處理,并全面分析被監測數據。在可視化分析結果的基礎上,監測人員可借助相應的查詢方法或監測軟件對被監測的數據信息進行建模或分析,從而進一步獲取相關異常證據。在此基礎上,通過對數據信息進行異常確定,獲取到最終的網絡負載異常結果。
1.2 基于爬蟲大數據的異常數據采集
網絡負載異常數據的采集是獲取相應網絡負載數據的重要環節。網絡負載異常數據采集主要分為四部分:Web爬蟲、數據處理、爬取隊列及數據庫。四個部分的主要功能分別為:從網絡中獲取相應的負載數據信息,并從中抽取需要的屬性數據信息;對爬蟲獲取的數據信息進行處理;為爬蟲提供需要獲取異常數據的隊列;數據庫中主要包括需要獲取的異常數據信息、從網絡中抽出的數據及經過處理后的數據。
Web爬蟲獲取數據的過程為:網絡→鏈接獲取→異常鏈接過濾→內容獲取→異常內容過濾→爬取隊列→異常數據采集。具體過程為:在網絡中獲取相應的鏈接;從內容中抽取相應的正文內容和鏈接;進一步判斷鏈接地址時已經是被獲取過的;從中提取所需利用價值的數據;為爬蟲提供所需異常數據的隊列;最后將所有數據信息存儲在數據庫當中。
利用爬蟲抓取網絡中負載數據的方法可分為三種。第一種方法是以廣度優先,由根節點開始,對當前被監測的負載進行搜索,再對下一層進行搜索,以此類推,逐層搜索,從而完成對負載數據的獲取[6]。第二種方法是以深度優先,從根節點出發,找出其葉子節點,以此類推。在一個網絡環境當中,選擇一個鏈接,被鏈接的網頁將指向深度優先的搜索策略,以此形成單獨存在的一條搜索鏈,當搜索到沒有其他鏈接存在時,完成對網絡負載數據的獲取。第三種方法是最佳優先,通過計算得出預測模型與實際網絡的相似程度或相關性,根據事先設定的閾值進行選擇,從而完成對網絡負載數據的獲取。可根據實際要求,選擇不同的爬蟲大數據獲取方法。
在進行爬蟲大數據采集過程中,需要增加過濾設備,用于判斷獲取到的數據信息是否存在于未出現異常的數據集合中。過濾設備的基本思路為:當由爬蟲大數據獲取到的數據信息進入集合中,利用散列函數對每個數據元素映射成為一個位數組中的某一個點,并將其設置為0。在檢索過程中,只需要判斷該點是否為0即可得知該數據是否在未出現異常的數據集合中。若集合中出現任何不為0的子集,則表示集合中存在負載異常數據,將這一部分集合過濾出來;若集合中的數據均為0,則表示該集合中所有的數據均為未出現異常的負載數據[7]。由于過濾設備中的存儲空間及插入、查詢的時間均為常數,因此,對監測人員來說,監測復雜程度更低。加之散列函數相互之間不具有一定的關聯關系,因此更有利于硬件設施方面的并行實現。由于過濾設備不具有存儲數據信息的功能,因此,對某些保密性要求更高的數據信息而言,安全性更高。
1.3 網絡負載異常數據計算
假設網絡負載的數量為[m]個,在某一時間段[s]中,構建相應的負載監測模型,網絡負載的變化從時間軸上看是沒有規律可言的,因此分析接入大數據平臺的負載可以用時間序列對負載數量進行預判[8]。結合爬蟲大數據的采集,根據上一時間段中的負載實際數量和預測的負載數量建立當前時間段內的網絡負載異常預測模型,通過對數據進行不斷修正,使其無限逼近于真實的負載數量。
假設在某一時間段[s]中的負載數量的預測數值為[Fs],則[fs]表示在時間段[s]內的實際負載數量,則可得出相應的計算網絡負載數量預測值公式為:
[Fs+1=Fs+λ(fs-Fs)]? ? ? ? ? ? ? ? ? ? ?(1)
公式(1)中,[λ]表示為權重因子。
通過公式(1)可得出相鄰兩次負載數量的預測變化值為:
[ε=Fs-Fs-1]? ? ? ? ? ? ? ? ? ? ? ? ? ?(2)
公式(2)中,[ε]表示變化值。
為了使監測方法的準確性更高,對于每次在計算過程中產生的誤差,應采用對多次預測數值求取平均數[F]的方式提升監測方法的精準度。
根據[ε]和[F]相差的數值判斷出最終的網絡負載數量變化情況。若計算出的結構[ε]≥[F],則表示在當前時間段內,負載數量的變化情況明顯,此時可能出現了網絡負載異常現象,應采取相應的措施,對當前接入網絡中的負載進行重新監測,并判斷此時監測情況及負載的類別;[ε]<[F],則表示在當前時間段內,負載數量的變化情況不明顯,未出現網絡負載異常現象,因此保持原有監測方法和相關參數不變。
通常情況下,網絡負載還會出現偽在線負載的現象,造成網絡中的資源浪費。針對這一問題,還需要驗證負載是否在線。利用爬蟲大數據對在線的負載狀態進行判別,用于判斷在線用戶的真實情況。根據上述構建的預測模型計算出負載數量的輸入量,而網絡負載在當前監測時間段內的通信看作是網絡輸出。將公式(1)中獲取到的負載預測值作為研究對象,以網絡負載的實際個數作為輸出,假設[m]個負載的通信時間為[ai(i=1,2,…,m)],根據輸出量,判斷此時負載的連接情況及負載的通信情況。通過正向運算可得出:
[Hj=g(i=1mωa-T),j=1,2,…,l]? ? ? ? ? ? ? ? (3)
公式(3)中,[Hj]為正向運算的結果;[ω]表示為權重;[T]表示為閾值;[l]表示為負載數量;[g]表示為傳遞關系。通過(3)計算出的結果與實際結果進行比較可得出兩者之間存在的誤差值,再通過反向運算將權重與閾值更新,以此可以不斷減小負載異常監測的結果誤差,從而獲取實際負載數量的在線情況。若通過本文上述方法利用爬蟲大數據獲取到的數據信息在設定的數據量閾值范圍內,則表示此時網絡負載處于正常的連接狀態及正常的通信狀態;若數據信息不在設定范圍內,則表示此時網絡負載的連接為無效連接,負載處于異常狀態。
2 對比實驗
為了驗證本文提出的基于爬蟲大數據的網絡負載異常監測方法的有效性,將該方法與傳統監測方法進行對比,實驗設計如下。
2.1 實驗準備
首先構建實驗平臺,設置網絡負載的數據樣本為2 000個。將2 000個樣本建立成一個樣本集合,并將數據全部接入平臺中。設置本文提出的監測方法為實驗組,傳統監測方法為對照組。將樣本分為兩組,每組1 000個,對其負載分別進行60min的不間斷調整,加入人工手段,讓部分負載失去連接,分別利用兩組方法對其網絡負載異常進行監測,比較對照組和實驗組的監測性能。
2.2 實驗結果及分析
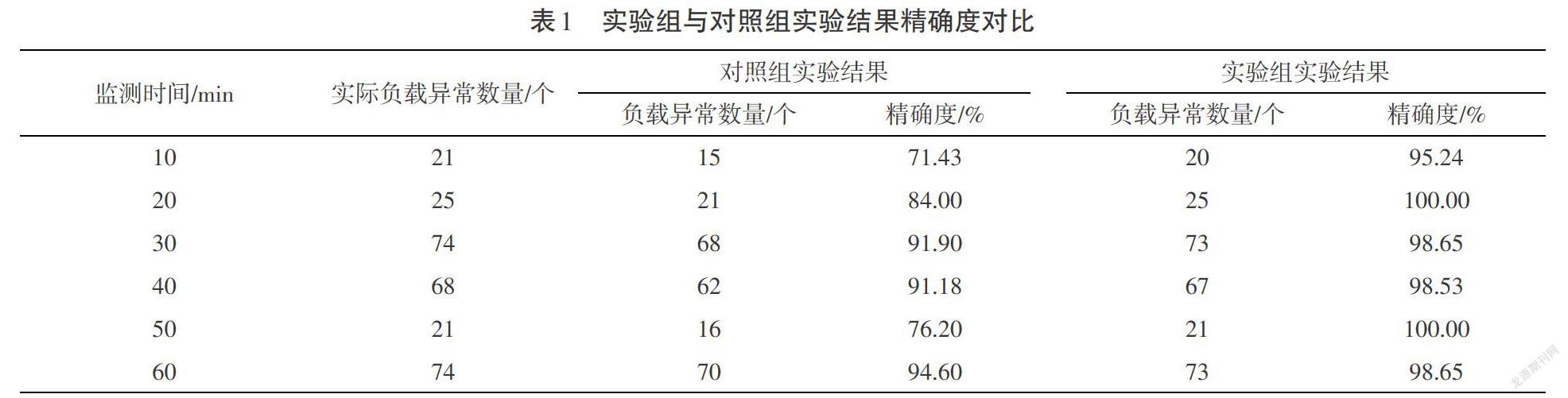
為了保證實驗的客觀性,在保證其他外界影響因素均相同的情況下,完成實驗。對實驗過程中的相關數據進行記錄,并通過計算得出兩組方法監測結果的精確度,如表1所示。
通過本文構建的實驗及表1可以得出,經過60min的監測與實際的負載異常數量相比,實驗組的監測精確度明顯高于對照組的監測精確度。雖然表1中對照組的監測精度能夠達到91%以上,但從整體實驗過程來看,監測精度的穩定性不強,精確度在70%~91%波動過大。這主要是因為,傳統監測方法是利用服務器定時對每個負載發送信號,再對發送信號的時間及接受反饋的相應參數進行記錄,根據時間差判斷負載的異常情況,這種方法浪費網絡資源,對大數據平臺的適用性較差。實驗組的監測方法在獲取網絡負載數據的過程中,避免了傳統方法運用過程中出現的問題,因此平均精確度可高達95%以上,且擬合性更高,精確度的誤差波動范圍較小。可見,本文提出的基于爬蟲大數據的網絡負載異常監測方法的監測精確度更高、適應性更強,更適用于對網絡負載進行異常監測。
3 結語
本文提出一種基于爬蟲大數據的網絡負載異常監測方法,在提高監測精確度的同時,提高了大數據平臺中資源的使用效率。實驗證明,本文設計的網絡負載異常監測方法具有更強的適用性。在后續的研究中還將針對爬蟲大數據采集進行更加深入的研究,找出最適用于網絡負載異常監測的網絡爬蟲類型,方便相關人員的監測,提高監測的運行效率及性能,為日后對結構更加復雜的網絡環境的負載異常監測提供理論基礎。
參考文獻:
[1]李星.基于小波神經網絡的大數據在線負載異常監測技術研究[J].現代電子技術,2019(11):95-97.
[2]章昭輝,崔君.大規模網絡服務系統行為異常的敏捷感知方法[J].計算機學報,2017(2):505-519.
[3]劉江,劉國璽,張雁,等.基于多線程和翻譯的網絡爬蟲鳥類音頻數據采集系統設計與實現[J].現代計算機(專業版),2018(30):85-92.
[4]高峰,劉震,高輝.結合有監督廣度優先搜索策略的通用垂直爬蟲方法[J].計算機工程,2018(11):289-299.
[5]石恩名,肖曉軍,盧宇.基于云平臺的分布式高性能網絡爬蟲的研究與設計[J].電信科學,2017(8):180-186.
[6]劉順程,岳思穎.大數據時代下基于Python的網絡信息爬取技術[J].電子技術與軟件工程,2017(21):160-161.
[7]郭二強,李博.大數據環境下基于Python的網絡爬蟲技術[J].計算機產品與流通,2017(12):82-83.
[8]曾健榮,張仰森,鄭佳,等.面向多數據源的網絡爬蟲實現技術及應用[J].計算機科學,2019(5):304-309.
