結合R-DAD和KCF的行人目標跟蹤改進算法
2019-09-12 10:41:42許喜斌
智能計算機與應用 2019年4期
許喜斌

摘 要:行人目標跟蹤技術在現實生活中具有較強應用性,但存在抗遮擋性弱等問題。本文利用Jetson TK1平臺的便捷性結合R-DAD(Region Decomposition and Assembly Detector)思想改進了KCF(Kernelized Correlation Filters)跟蹤算法,實現對行人目標跟蹤。實驗結果表明,改進的行人目標跟蹤算法運算量少、性能高、速度快,具有良好的抗遮擋性和精確性。
關鍵詞:Jetson TK1平臺;R-DAD;KCF;目標跟蹤;抗遮擋性
文章編號:2095-2163(2019)04-0263-05 中圖分類號:TP391 文獻標志碼:A
0 引 言
隨著人工智能的快速發展,圖像檢測識別和目標跟蹤技術在多個領域被廣泛使用,例如商業、小區安全、軍事保密和法律取證等方面的智能視頻監控;基于5G網絡的智能醫療診斷;解決交通道路擁堵的智能交通監管系統及自動駕駛系統。
目標檢測算法主要有基于背景建模、基于輪廓模板、基于光流法和基于底層特征等4類。基于背景建模算法是先建立當前前景的背景模型,再與背景圖像模型做差分,提取運動前景,建立臨時塊模型,結合更新的行人檢測的背景模型實現行人檢測[1],該算法對動態變化背景較為敏感,不適用復雜的動態場景。基于輪廓模板的方法是通過構建圖像目標物體的邊緣輪廓、灰度、紋理等信息模板,再匹配模板的方法來檢測目標[2],該方法簡單易行,但需要構建大量的模板才能取得較好的效果。基于光流法是賦予圖像各個像素點一個速度矢量形成圖像運動場,再根據像素點的速度矢量特征進行圖像分析,獲取物體在圖像中的運動位置,實現目標檢測[3],該方法適合分析多目標的運動,可以解決運動目標檢測中的遮擋、重合等問題,但存在實時性差、魯棒性弱、計算方法復雜等不足。基于底層特征的算法是利用積分圖技術進行快速計算,但對行人目標的表達能力不足,判別力較差。
行人檢測技術主要有基于特征提取和深度學習(Deep Learning)2種。其中對于特征提取的方法,為了更好地獲取行人圖像特征,Dalal N等人[4]采用梯度方向直方圖(HOG)特征描述子結合線性分類器支持向量機(SVM)的方法,在行人檢測方面取得了巨大的突破,但在處理遮擋問題的時候,HOG特征并不能很有效地解決遮擋問題。基于深度學習方面,隨著近年來的理論和相關技術的高速發展,深度學習的行人檢測算法取得很大的突破[5-8],其檢測精度也有較大地提高,深度學習具備的自我學習特點可以避免復雜的特征提取和數據建模過程,很好地描述檢測目標特性。本文基于KCF算法,結合區域分解集成的思想,改進KCF算法提高目標跟蹤的抗遮擋性,在NVIDIA Jetson TK1 平臺上具有良好的抗遮擋性和實時性。
1 Jetson TK1平臺
NVIDIA Jetson TK1平臺是NVIDIA針對快速開發和部署面向機器人技術、計算機視覺、醫療等領域的計算密集型系統。該平臺以NVIDIA Tegra K1 SoC 為基礎構建,包含 NVIDIA KeplerTM 計算核心,且具有192 個 CUDA 核心,非常適合算法的并行運算,具體參數見表1。
Jetson TK1平臺使得計算機視覺、深度學習的計算更加高性能、低能耗,是嵌入式系統設計的理想平臺,如圖1所示。
2 跟蹤算法
2.1 KCF算法
KCF(Kernelized Correlation Filters),即核相關濾波器方法。首先,采用循環偏移圖像矩陣,構建出分類器的訓練樣本,其中中間部分為正樣本,其它周邊為負樣本,使數據矩陣轉換成循環矩陣,然后,簡化循環矩陣計算,進而求解基于循環矩陣特性的問題。該方法建立在相關濾波跟蹤算法的框架上,將FFT快速傅里葉變換轉換到頻域,從而避免矩陣求逆過程,極大地降低算法復雜度和提高跟蹤精度[9]。下面給出KCF算法的具體過程:
2.1.1 訓練分類器
2.1.2 目標檢測
目標檢測的計算響應公式為:
KCF算法目標跟蹤流程如圖2所示。
2.2 R-DAD思想
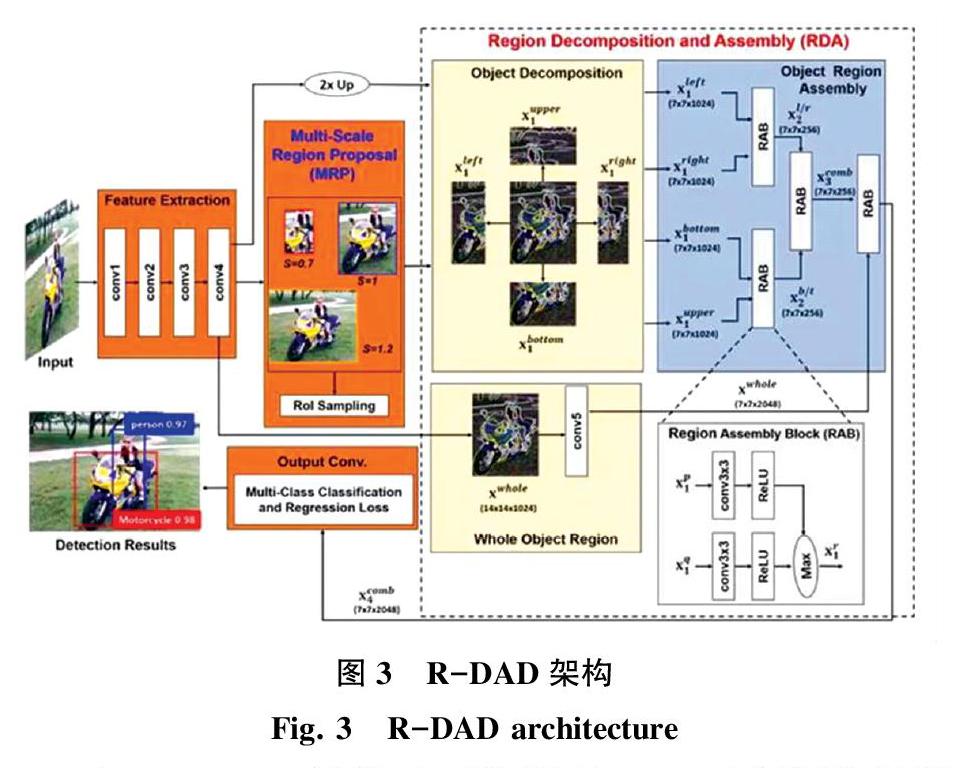
目前主流的目標檢測算法中以Faster-RCNN 為代表,由RPN(Region Proposals Network)生成感興趣區域RoI(Region of Interests),該算法會因目標被遮擋或不精確的候選區域(Region Proposals)導致目標檢測不準確,因此,Seung-Hwan Bae 提出R-DAD(Region Decomposition and Assembly Detector),即區域分解組裝檢測器,來改善生成的候選區域[12]。圖3示出了R-DAD架構。
在R-DAD架構中,重新對MRP網絡進行調整,對目標進行縮放形成多個不同尺度的候選區域,再對其分解成幾個部分,如上、下、左、右,其中,設計了一個帶有3*3的卷積濾波器區域組裝塊,讓分解的部分兩兩進行卷積和使用ReLU函數,比較得出最大單元模塊,再繼續使用RAB(Region Assembly Block),接著對分解部分的強響應進行結合,然后再學習整個對象和基于部件的特征之間的語義關系,R-DAD 網絡架構主要分成MRP 和RDA 2個模塊。
2.2.1 MRP(Multi-Scale Region Proposal)模塊
MRP模塊主要是改善RPN生成的候選區域的準確率。是生成多尺度的候選區域,首先用傳統的RPN生成一些建議框,然后用不同的縮放因子對生成出的候選區域進行不同比例的縮小放大,從而提高候選區域的多樣性。如圖4所示,框內分別對應S=0.7,1,1.2的候選區域,不同尺度的區域,會導致部分局部大于目標本身,也使得候選區域數量過多,導致無法完全利用,因此需要添加RoI的采樣層,對分數低和跟ground truth 重疊率低的進行篩選。因此,MRP 網絡生成的各種候選區域,可以進一步適應目標之間因為空間變化所導致的特征變化,進而提高結構的魯棒性。
2.2.2 RDA(Region Decomposition and Assembly)模塊
RDA模塊同時描述物體的全局及局部外觀,將目標物體分為目標區域集成和目標分解2部分,其中,目標分解如圖5所示,將目標分為上、下、左、右4個部分,其中圖左邊為不同尺度的候選區域,圖右邊為物體目標的分解區域。
對目標進行分解時,先用線性插值2倍以上采樣之后再分解,會達到更好的效果。因為左右剛好是特征圖的左右一半,上下也是一樣,然后再送入RAB模塊,其中RAB模塊如圖6所示。
RDA模塊主要由以下2個函數表示:
R-DAD可以描述全局特征和局部特征的語義信息,在較為復雜的場景下,若目標對象被遮擋,通過左、右、上、下模板篩選出來的特征會更加符合真實場景,使得候選區域更加可信,增強目標跟蹤的抗遮擋性。
2.3 改進KCF算法
KCF算法在各種場景的應用中,在跟蹤效果和跟蹤速度上都表現的比較優秀。但是,該算法存在無法較好解決跟蹤過程中目標被遮擋的問題,一旦跟蹤目標發生遮擋就容易導致跟蹤失敗。
本文結合R-DAD的思想,對行人目標區域進行全局和局部特征提取,并進行訓練,獲得行人目標的局部特征,再對局部區域使用KCF跟蹤器進行初始化并輸出響應值,利用響應值定位目標局部區域的關聯響應,進而將部分區域響應值組合形成整體的行人目標響應值。局部特征提取如圖7所示。
基于R-DAD思想的KCF目標跟蹤改進算法描述如下:
步驟1 先將行人目標整體檢測出來,然后對行人整體目標進行劃分,例如,假設整體行人目標為X,將其等分為上、下、左、右4部分:Xl、Xr、Xu、Xd;
步驟2 對每部分都進行特征提取,并形成相對應的特征值:El、Er、Eu、Ed;
步驟3 將整體目標跟蹤化為局部跟蹤,先跟蹤局部部分,即先跟蹤El,以El特征為目標Xl作為行人目標所在的跟蹤對象進行跟蹤;
步驟4 當局部目標Xl被遮擋時,跟蹤另一個局部目標局部塊Xr,使用Er作為目標跟蹤特征進行跟蹤,重復步驟3;
步驟5 當局部目標特征失效或整體目標被完全遮擋,則跟蹤失敗;
步驟6 算法結束。
3 實驗結果
為了提高識別的速度,提升實驗效果,本文在JetsonTK1平臺上調用GPU進行行人識別運算,對同一段行人跟蹤視頻分別用KCF算法及改進的KCF算法進行目標跟蹤,對比兩者的召回率和準確率,分析兩者之間的性能區別,見表2。
3.1 召回率
其中,R為召回率;TP為目標跟蹤正確的圖像幀總數;TN為含有目標的圖像幀及跟蹤失敗的總數。召回率可以評估目標跟蹤算法的全面性衡量及跟蹤質量,進而反映出算法在所有目標出現的圖像中的成功跟蹤目標的能力。
3.2 準確率
其中,P為準確率; TP為目標跟蹤正確的圖像幀總數; FP為目標跟蹤錯誤及未出現目標的圖像幀總數。準確率可以衡量目標跟蹤的準確性。
見表2,KCF目標跟蹤算法的準確率為???28.55%,改進后的KCF目標跟蹤算法的準確率為48.69%,改進后的KCF算法準確率提升20.14%。KCF算法召回率為28.11%,改進后的KCF算法召回率為46.67%,改進后的KCF算法召回率率提升18.56%。實驗結果表明,基于R-DAD思想改進的KCF目標跟蹤算法的跟蹤性能更佳、抗遮擋性更強、跟蹤效果更好。
4 結束語
本文基于JetsonTK1平臺,利用該平臺性能高、便捷、小巧的特點,設計了行人目標跟蹤算法,采用KCF跟蹤算法,并利用R-DAD思想對KCF算法進行改進,在保持KCF算法高正確率、高運算速度、少計算量的同時,提升了行人目標跟蹤算法的抗遮擋性和跟蹤精度。
參考文獻
[1]WREN C, AZARBAYEJANI A, DARRELL T, et al. Real-time tracking of the human Body[C]. IEEE Transactions on Pattern Analysis and Machine Intelligence,1997,19(7):781-785.
[2] 張春鳳,宋加濤,王萬良.行人檢測技術研究綜述[J]. 電視技術,2014,38(3):157-162.
[3] Yalin X, Steven A S. Moment and Hyper Geometric Filter for High Precision Computation of Focus,Stereo and Optical Flow[J]. International Journal of Computer Vision,1997,22(1):25-29.
[4] Dalal N,Triggs B. Histograms of oriented gradients for human detection[C]∥ 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,CVPR 2005,IEEE,2005:886-893.
[5] Tian Y,Luo P,Wang X,et al. Pedestrian detection aided by deeplearning semantic tasks[EB/OL]. ar Xiv preprint ar Xiv:1412. 0069,2014.
[6] Ouyang W,Wang X. Joint deep learning for pedestrian detection[C]. Computer Vision ( ICCV) ,2013 IEEE International Confe-rence on. IEEE,2013:2056-2063.
[7] Sermanet P,Kavukcuoglu K,Chintala S,et al. Pedestrian detectionwith unsupervised multi-stage feature learning[C]. Computer Visionand Pattern Recognition (CVPR) ,2013 IEEE Conference on.IEEE,2013:3626-3633.
[8] Luo P,Tian Y,Wang X,et al. Switchable deep network for pedes-trian detection [C]. Computer Vision and Pattern Recognition(CVPR) ,2014 IEEE Conference on. IEEE,2014:899-906.
[9] J.Henriques,R.Caseiro,P.Martins,et al.High-speed tracking with kernelized correlation filters[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3):583-596
[10]Li Y,Zhu J.A scale adaptive kernel correlation filter tracker with feature integration[C]//European Conference on Computer Vision,2014:254-265.
[11]何承源.循環矩陣的一些性質[J].數學的實踐與認識,2001,31(2):211-216.
[12]Seung-Hwan Bae.Object Detection based on Region Decomposition and Assembly[C]. Thirty-Third AAAI Conference on Artificial Intelligence (AAAI-19).2019.
