基于時空域深度神經網絡的野火視頻煙霧檢測
2019-09-13 03:38:32高聯欣宋巖貝李佳欣
計算機應用與軟件 2019年9期
張 斌 魏 維 高聯欣 宋巖貝 李佳欣
(成都信息工程大學計算機學院 四川 成都 610225)
0 引 言
在現實生活中,火災突發性難以控制,特別是野外森林火災的發生不僅會使自然生態系統遭到嚴重破壞,而且還會對人類生命財產構成了嚴重威脅。由于煙霧的出現早于火焰之前,因此開發一種有效的早期森林火災煙霧的檢測方法具有重大的理論和現實意義。目前,研究者們在文獻中提出的基于視頻的火災煙霧檢測算法大多集中在顏色和形狀等特征上,他們通常構建一個多維特征向量,然后作為SVM、神經網絡、Adaboost等分類算法的輸入。
文獻[1]提出一種基于圖像處理技術的特征提取算法和基于計算智能策略的分類器來檢測煙霧的方法。該方法在檢測過程著重于提取煙霧的顏色特征、邊緣特征和運動區域檢測等,然后使用兩層前饋神經網絡來判別不同幀中的煙霧的區域,但是該算法對于野外復雜場景下的煙霧檢測適用范圍有限。文獻[2]提出了一種基于時空特征袋(BOF)模型的特征提取方法,他們從當前幀塊中提取HOG作為空間特征,并且基于由熱對流而使煙霧擴散方向向上的事實,提取HOOF作為時間特征。通過結合靜態和動態特征,最后通過隨機森林分類器進行分類,該方法檢測效果良好。文獻[3]通過連接局部二值模式(LBP)和基于局部二值模式方差(LBPV)金字塔的直方圖序列提取了一個有效的特征向量,并采用BP神經網絡進行煙霧檢測識別,但是該算法對于稀薄煙霧的檢測效果較差。文獻[4]通過高斯混合模型(GMM)進行背景建模后提取疑似煙霧區域,并通過NR-LBP(非冗余局部二進制模式)特征描述煙霧紋理,然后通過支持向量機進行分類,但是在檢測野外火災煙霧下會出現誤判。文獻[5]首先使用背景差分法找出運動目標區域,然后設置一個采樣緩沖區進行運動區域檢測,接著利用自定義閾值函數進行煙霧的顏色、面積增長率和運動方向的分析,最后根據這些特征進行分類識別,但是該方法對于野外遠距離煙霧檢測效果較差。
傳統的視頻火災煙霧檢測方法通過依靠專業知識來手工設計的相關特征,然后創建基于規則的模型和判別特征。但這樣的研究方法不能很好地適用于各種情況。近年來,基于深度學習的卷積神經網絡(Convolutional neural network,CNN)模型在圖像分類[6]和物體檢測[7]等多個計算機視覺應用領域中,與傳統機器學習方法相比具有更強大的特征學習和特征表達能力。Xu等[8]在視頻圖像序列上利用AlexNet網絡結構檢測人造的煙霧圖像,準確率最高達到了94.7%。Frizzi等[9]構建了自己的CNN,類似于著名的LeNet-5網絡結構,增加了卷積層中的特征圖數量。作者在真實的煙霧場景進行測試,達到了97.9%的精確度,這比傳統的機器學習方法的性能更高。陳俊周等[10]提出了一種級聯的卷積神經網絡煙霧識別框架,他們將CNN引入到煙霧的靜態紋理和動態紋理中以進行特征提取,該方法有效降低了非煙霧區域的誤檢率。
CNN直接在原始RGB幀上運行,而不需要特征提取階段。雖然目前很多文章中使用更深層次的CNN網絡結構來提取特征,但它們并沒有利用上時域中的特征。煙霧具有動態性,它會隨著時間的變化而改變形狀,循環神經網絡(RNN)則可以累積一組連續幀之間的運動信息。因此,本文提出使用CNN和RNN的組合來進行視頻煙霧的檢測,詳細的煙霧檢測框架如圖1所示。
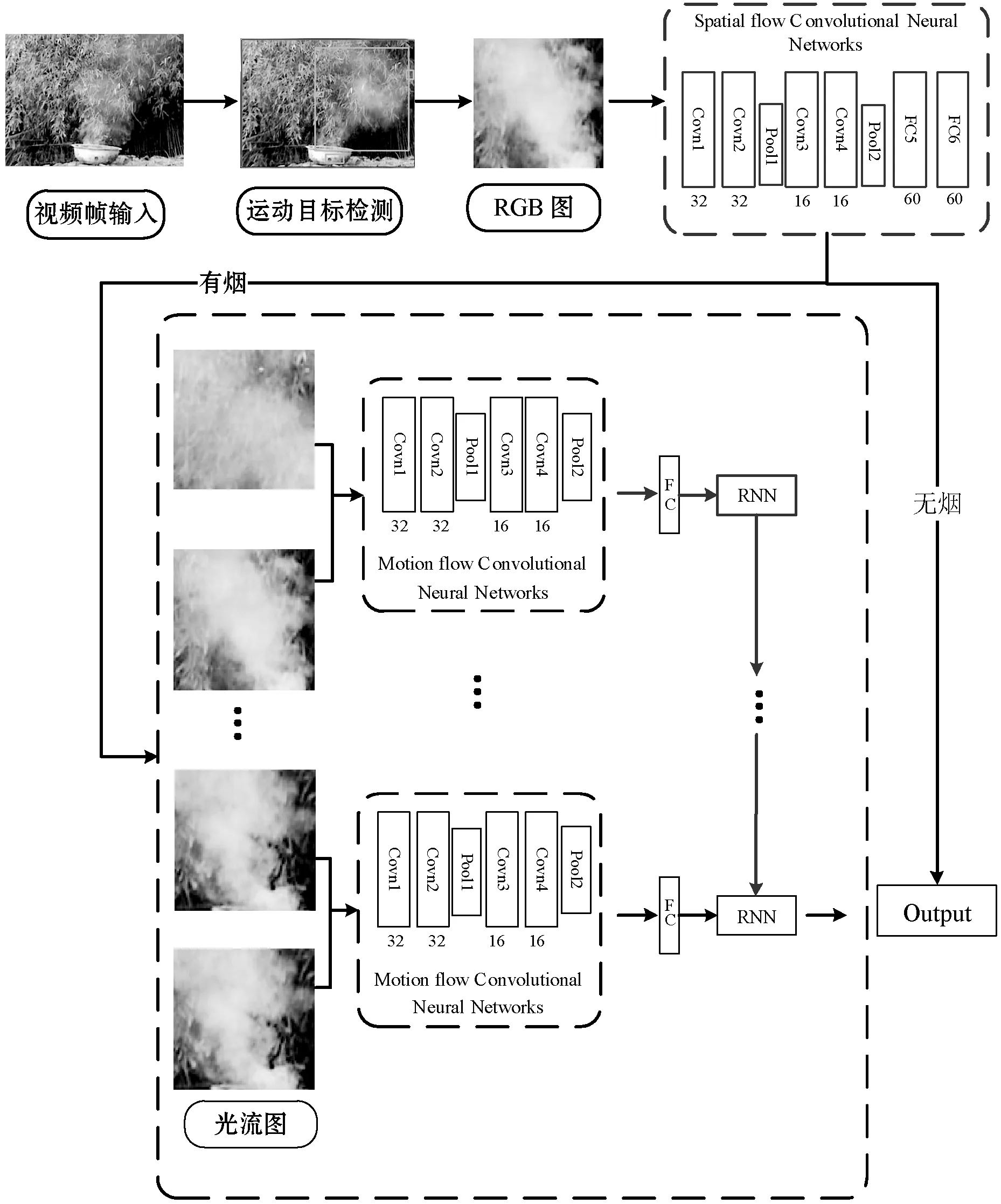
圖1 基于時空域深度神經網絡的野火視頻煙霧檢測框架
算法首先通過使用在文獻[11]中提出的煙霧運動目標檢測方法來檢測出視頻幀中的運動區域;然后,將這些候選運動區域作為空間流網絡的輸入以提取空域特征;為了充分利用視頻中煙霧的運動信息,當候選運動區域被空間流網絡CNN識別為有煙時,則取出該區域左右相鄰兩幀圖像的相對應區域,并對連續兩幀圖像通過時間流網絡進行處理,以獲取相鄰幀中對應區域之間的運動信息,最后輸入給RNN進行時間上的運動特征累積,以進一步降低誤檢。現有的只利用空域特征的深層次CNN以及本文方法(去掉時間流網絡和RNN部分)進行了對比實驗,結果表明,本文所提出的網絡模型實驗結果表現出了較高的分類檢測準確率,最后在多個真實視頻場景中進行了測試,實驗結果表明本文算法具有良好的準確性和實時性。
1 運動目標檢測
常用的提取運動目標檢測的方法有:光流法、幀間差法和背景減除法等。本文的視頻煙霧檢測過程由運動區域提取和對運動區域進行特征提取并分類識別這兩大部分組成,具體的視頻煙霧檢測框架如圖1所示。
在圖像處理中,幀差法是一種通過對視頻圖像序列中相鄰兩幀作差分運算來獲得運動目標輪廓的方法[12]。當監控場景中出現物體運動時,通過差分圖像可以快速獲得運動區域,但當移動目標快速運動時就會出現“重影”和“孔洞”現象,但對于運動較緩慢的煙霧,其檢測效果不理想。因此,根據幀差法的原理,本文使用在文獻[11]中提出的基于混合高斯模型和改進的四幀差法相結合的算法來檢測運動目標。具體算法描述如下:
(1) 通過改進的四幀差法的算法和混合高斯模型分別對視頻圖像進行運動目標檢測及背景建模以獲取前景圖像。
(2) 將它們得到的圖像進行邏輯“或”運算并進行形態學處理,目的是為了去除圖像中的噪聲以及空洞現象等,最終提取出比較完整的運動目標區域。文獻[11]運動目標區域檢測的算法流程圖如圖2所示,算法最終對視頻的檢測結果如圖3所示。
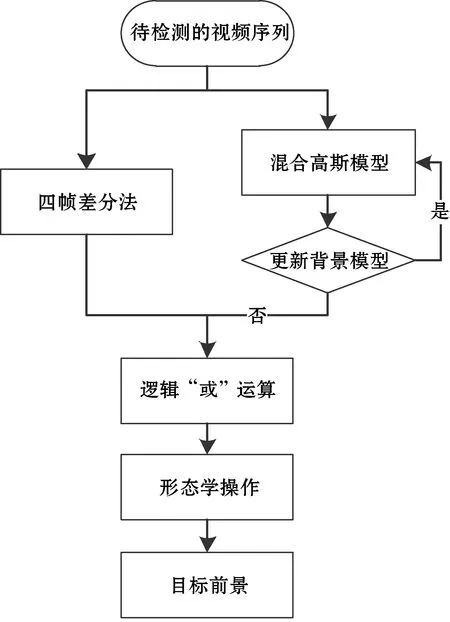
圖2 運動目標區域檢測流程圖

圖3 運動目標檢測效果示例圖
2 候選運動區域縮放
首先通過在文獻[11]中提出的算法從視頻幀中提取出疑似煙霧運動區域,再通過空間流網絡來初步計算這些候選運動區域是否含有煙霧的特征。因為空間流網絡結構對輸入圖片的大小是固定的,所以必須將這些疑似煙霧運動區域的圖像數據轉換到固定的大小。因此我們采用插值縮放[13]的方法(這種方法很簡單,就是不管圖片的長寬比例,不管它是否扭曲,全部縮放成CNN輸入的大小),然后將這些縮放后的候選運動區域輸入到CNN以提取用于初步確定該區域是煙霧域還是非煙霧域的特征。
3 基于時空域深度神經網絡的煙霧識別模型設計
由于煙霧沒有固定的輪廓和顏色,在傳統的火災煙霧圖像識別研究中,研究者們需要根據一定的專業和先驗知識來手工設計和處理特征。然而基于手工設計和處理特征的傳統煙霧檢測算法難以描述煙霧的本質屬性,從而影響煙霧檢測的準確性。但是卷積神經網絡不需要將特征提取和分類訓練兩個過程分開,它在訓練的時候就自動提取最有效的特征,具有強大的特征提取能力。同時CNN訓練的模型對縮放、平移、旋轉等畸變具有不變性,有著很強的泛化性。因此,我們將縮放后的這些候選運動區域作為空間網絡的輸入以提取空域特征,并在有煙的基礎上進一步利用RNN進行時間上的運動特征累積,最后使用Softmax損失函數進行分類識別。
3.1 時間流網絡結構
空間流CNN架構包括1個輸入層、4個卷積層、2個子采樣層、3個全連接層,我們利用Softmax回歸模型對最后1個全連接層進行分類,以初步判斷該候選區域是否含有煙霧。具體設計的網絡結構如圖4所示。

圖4 空間流網絡結構
空間流網絡的輸入大小為64×64的RGB彩色圖像,然后依次經過兩次卷積運算,取卷積核大小為5×5,步長為1,濾波數為32對輸入圖像進行卷積。第三層為池化層,作用是對激活函數的結果再進行池化操作,即降采樣。我們使用最大池化方法,保留最顯著的特征,并提升模型的畸變容忍能力。池化層使用池化的核大小為3×3,步長為2。第四和第五兩個卷積層的卷積核大小為3×3,步長為1。最后兩個全連接層每層有60個神經元,輸出層有2個神經元,分別與最后的分類結果(有煙霧與無煙霧)相對應。為避免在全連接層上出現過擬合的現象,在全連接層中,網絡采用Dropout[14]方法避免過擬合情況的發生。在每一個卷積層后用一個修正線性單元(Rectified Linear Unit,ReLU)激活函數,目的是將前面卷積核的濾波輸出結果,進行非線性的激活函數處理。ReLU激活函數[15]的公式如下:
f(x)=max(0,x)
(1)
當輸入特征值x<0時,輸出為0,訓練完成后為0的神經元越多,稀疏性越大,提取出來的特征就越具有代表性,泛化能力越強;當輸入特征值x>0時,輸出等于輸入,無梯度耗散問題,收斂快。
3.2 運動流網絡結構
在實際應用中, 霧氣、云等都可能與火災煙霧具有相似的特征,但火災煙霧會隨著時間的變化而改變它的形狀。光流原理是利用圖像序列中像素在時間域上的變化以及相鄰幀之間的相關性來找到上一幀跟當前幀之間存在的對應關系,從而計算出相鄰幀之間物體的運動信息的一種方法[16]。因此,為進一步充分利用視頻中煙霧的運動信息,當候選運動區域被空間流網絡CNN識別為有煙后,提取該煙霧區域左右相鄰兩幀圖像的相對應區域,并對連續兩幀圖像通過時間流網絡進行處理,以獲取相鄰幀中對應區域之間的運動信息,最后輸入給RNN進行時間上的運動特征累積,以進一步降低誤檢。
時間流網絡包含了4個卷積層,在每個卷積層之后使用非線性函數Tanh函數。把該煙霧相對應區域左右相鄰兩幀圖像的連續兩幀作為輸入,輸入大小為64×64×4。每一層具體網絡參數設置如表1所示,網絡的最后一層是全連接層,輸出向量為60維。

表1 時間流網絡結構及參數設置
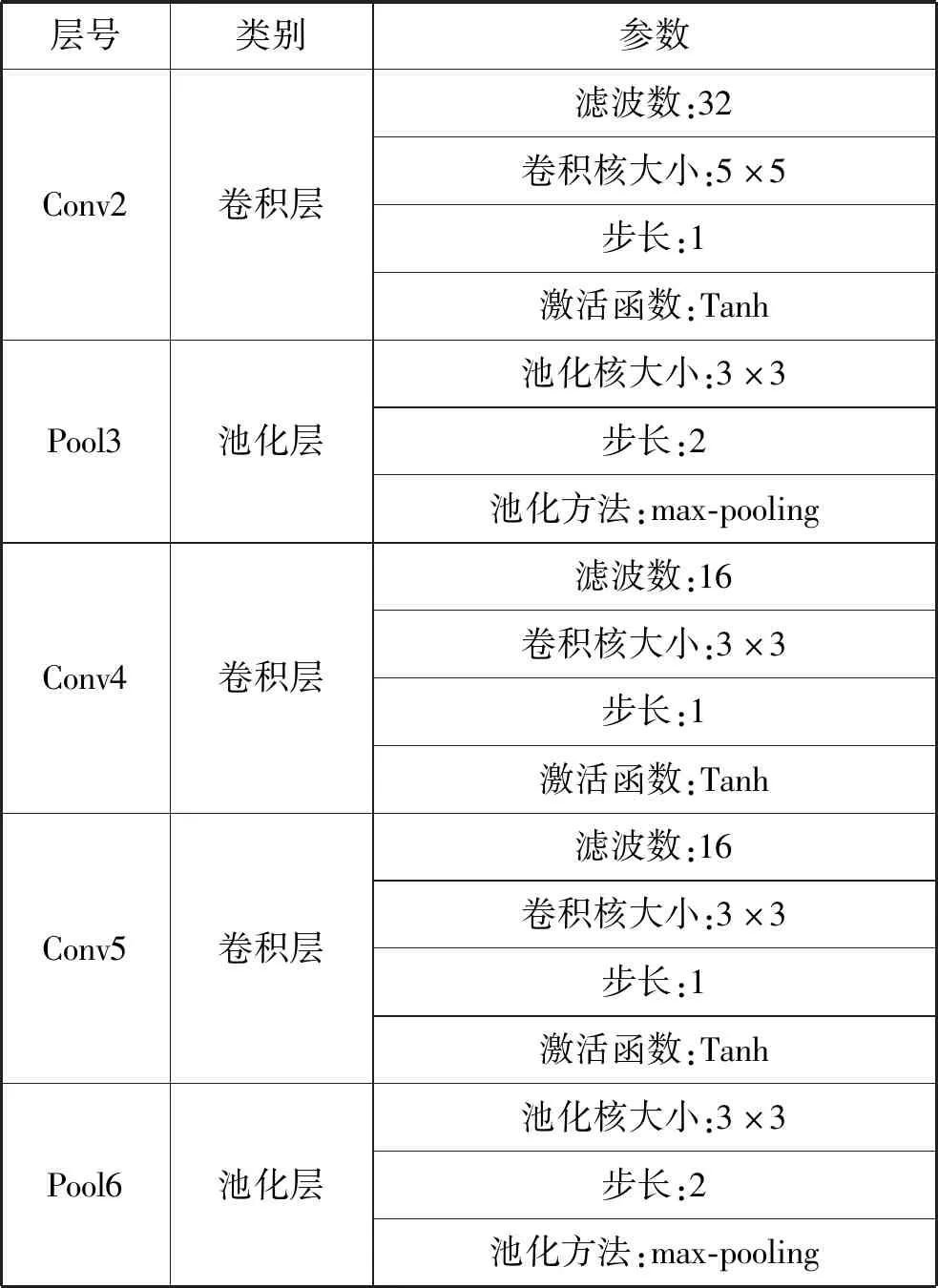
續表1
3.3 運動信息累積
在煙霧檢測問題中,累積的運動信息非常有用,為了更好地提取視頻序列中運動背景信息的運動特征,我們采用RNN網絡,該網絡可以處理任意長度的時間序列,從而可以通過該神經網絡解決聚合運動上下文信息的問題。尤其是RNN網絡具有前饋連接,其允許在一段時間內保存信息并基于當前幀和前一幀的信息產生輸出。一個標準的RNN結構圖如圖5所示,對于給定的RNN網絡,橫向連接用作存儲器單元,其允許在任何時間的信息流動。
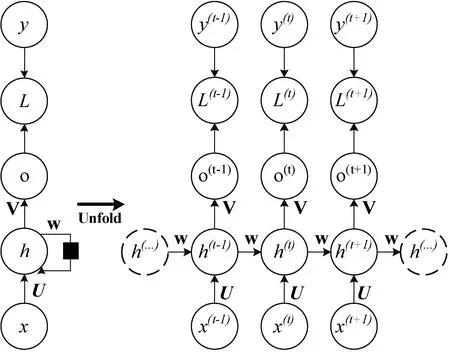
圖5 一個標準的RNN結構圖
圖5中,x、h和o分別表示輸入層、隱藏層和輸出層,L為損失函數,y為訓練集的標簽,t代表t時刻的狀態,V、W、U是權值。則RNN在t時刻的輸出以及最終模型的預測輸出如下所示:
o(t)=Vh(t)+c
(2)
(3)
式中:σ為激活函數,一般使用Tanh函數。
4 實 驗
本文使用Keras[17]和Tensorflow[18]來構建和訓練所提出的CNN模型。為了便于比較,我們還使用Keras和Tensorflow實現了其他3個經典的卷積神經網絡架構以及一個具有深層次的網絡VGG-16。所有的實驗都是在配備Intel(R) Core i3-6100 CPU @ 3.70 GHz和NVIDIA Tesla M40 GPU的PC上運行的Ubuntu 16.04操作系統中進行的。實驗中還使用到OpenCV-3.1.0庫和Python 3.5。
4.1 數據集
空間流網絡的實驗數據集圖片來源于袁非牛教授實驗室。數據集分為4組,分別命名為Set1、Set2、Set3和Set4。Set1有1 383張圖像,Set2有1 505張圖像,Set3有10 712張圖像,Set4有10 617張圖像。我們將Set3和Set4合并作為一個訓練集,共計21 329張圖像;將Set1和Set2合并作為一個測試集,共計2 888張圖像。
如圖6所示,煙霧和非煙霧的內部和外部類別差異非常大。圖6展示了數據集中的一些示例圖像,所有圖像都來自生活中真實的場景。

(a) 煙霧圖像 (b) 非煙霧圖像圖6 部分圖像數據集示例
我們將來源于土耳其比爾肯大學信號處理小組、韓國啟明大學計算機視覺和模式識別實驗室、意大利薩萊諾大學機器智能實驗室、內華達大學雷諾分校的計算機視覺實驗室的野外火災煙霧數據集,以及從YouTube、Youku等視頻網站收集并截取出大量野外火災煙霧的視頻段,構建為一個新的共5 000個視頻段的時間流網絡數據集。其中有煙和無煙部分分別從有煙視頻與無煙視頻中截取,且均不與測試視頻重復。實驗中隨機選擇80%樣本作為訓練集,其余的作為測試集。

圖7 部分視頻集數據示例
4.2 網絡模型訓練
本文實驗是基于Keras[17]平臺實現的,且卷積網絡模型的訓練使用了GPU并行處理。CNN使用4.1節中的數據集進行訓練。在訓練過程中,我們選擇了Adam optimizer[19]來優化網絡損耗,Epoch設置為200,一次處理圖片的最小輸入的數量(BATCH_SIZE)為64,設置動量系數為0.9和權重衰減值為0.000 5,初始學習率為0.001,學習率在每10 epoch后縮小0.95倍。
4.3 評價指標
對于林火視頻煙霧檢測的性能測試,我們使用文獻[20]提出的評估方法,公式如下:
(4)
(5)
(6)
式中:ACC表示準確率,N為樣本總數;TPR表示被預測為煙霧的煙霧樣本結果數,即檢測率;TNR表示被預測為非煙霧的非煙霧樣本結果數,即誤檢率;TP表示煙霧總數中正確檢測到煙霧的數量;FN表示未被識別的實際煙霧區域的數;FP表示認定為煙霧的非煙霧數量;TN表示認定為非煙霧區域的非煙霧區域數量。
將本文方法與AlexNet[15]、Frizzi[9]、文獻[21]中提出的算法以及和本文方法(去掉時間流網絡)進行了對比,Frizzi[9]中使用的是一個具有8層結構的網絡,而文獻[21]中則采用的是較深層次的網絡。我們基本上使用了4.2節中描述的與訓練相關的超參數,并根據不同的網絡架構調整了輸入圖像的大小。為了公平比較,所有比較的算法都使用同一個訓練集,并且所有的網絡模型都是從零開始訓練。
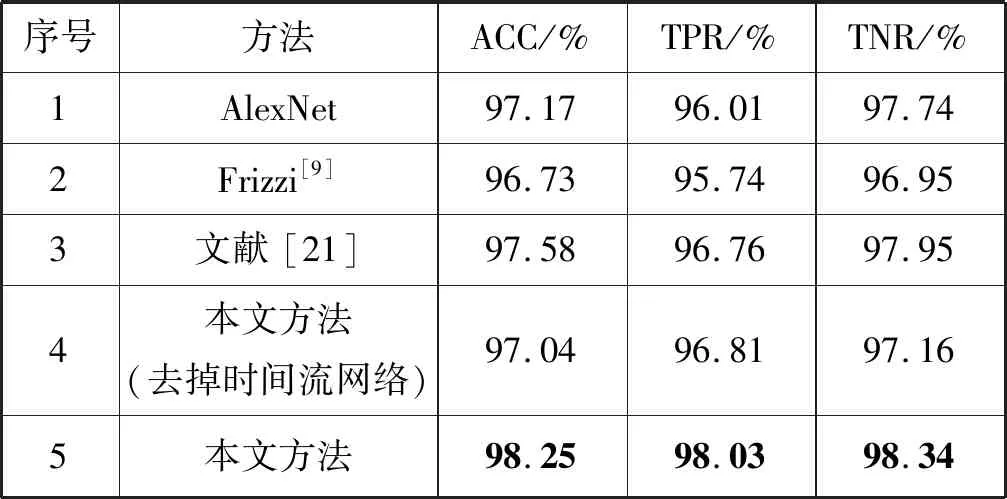
表2 與不同的方法比較結果
從表2的數據結果可以分析出,與AlexNet、Frizzi和文獻[21]中煙霧檢測方法相比較,我們的方法在煙霧檢測準確率和檢測率都有更好的表現。盡管AlexNet、Frizzi中和文獻[21]中的網絡在煙霧檢測方法檢測準確率較高,但是這三種網絡結構是無法累積一段視頻的上下文的運動信息的。相比較而言,本文中的網絡模型在去掉時間流網絡和RNN單元之后,煙霧檢測的準確率和檢測率都下降了至少1%,由此說明時間流網絡和RNN單元在本文的煙霧檢測框架中起著重要的作用,意味著RNN單元累積了有效的上下文運動信息,這種上下文信息不僅能夠很好地學習到圖像的特征,還具有較高的檢測正確率,有利于提高煙霧檢測的準確率。
4.4 本文算法用于視頻煙霧檢測結果
本文算法在多個視頻場景中進行測試,鑒于篇幅有限,圖8僅列出9組視頻的檢測結果,其中視頻1至視頻5為含有煙霧的視頻,視頻6至視頻9為與無煙霧的干擾視頻,主要是自然景觀中的云霧,視頻圖像大小為320×240像素。可以看出本文算法在多種場景下都具有良好的檢測效果和一定的抗干擾能力。

圖8 9組測試視頻的檢測結果圖
實驗測試結果如表3、表4所示。從表3中可以看出,在視頻1中,文獻[21]的算法比本文方法提早檢測到煙霧,但本文算法在其他場景下的檢測性能都不錯。從表4中可以看出,在無煙霧的測試條件下,不同視頻場景中出現了與煙霧顏色相近的白霧、移動的烏云以及擺動的樹葉等干擾物,本文的算法在這些場景中都沒有出現誤檢的情況,這說明本文算法具有較強的抗干擾能力,但是其他四種算法相對來說有一定的誤檢。總而言之,實驗結果表明本文視頻煙霧檢測算法具有良好的準確性和實時性,并證明了時間流網絡和RNN單元在本文的煙霧檢測框架中起著重要的作用,在視頻煙霧檢測方面有更好的表現。
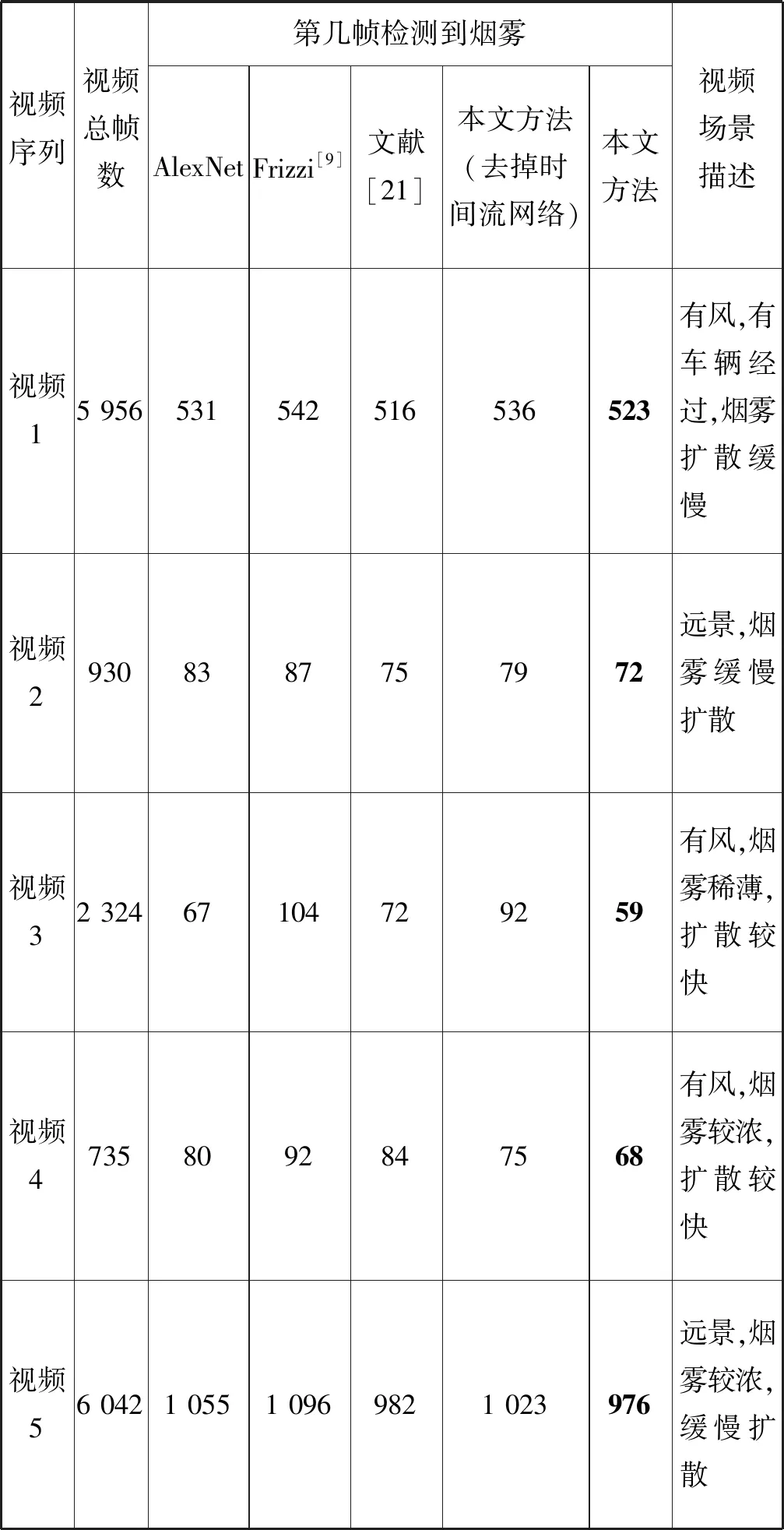
表3 有煙霧測試視頻的檢測結果
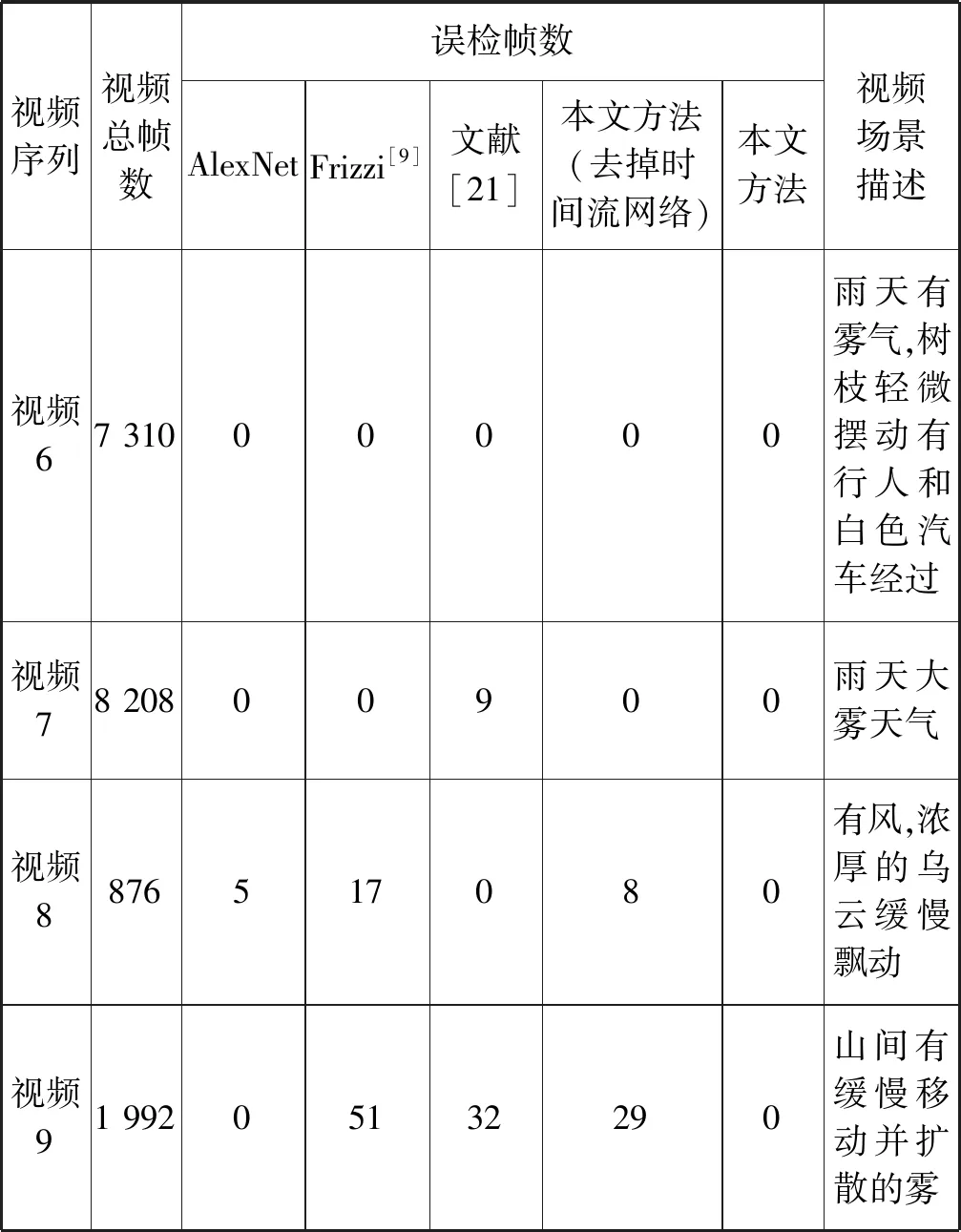
表4 無煙霧測試視頻的檢測結果
5 結 語
傳統的煙霧檢測方法是從輸入圖像中手動提取特征,然后使用分類器對煙霧進行分類和識別,這個過程通常比較復雜和繁瑣。本文提出一種基于時空域深度神經網絡特征提取與分類的林火視頻煙霧檢測算法。算法提取出候選運動區域的空域特征,當候選運動區域被空間流網絡CNN識別為有煙時,進一步充分利用視頻中相鄰幀中對應區域之間的運動信息,最后輸入給RNN進行時間上的運動特征累積,以進一步降低誤檢。與僅提取空域特征的煙霧檢測方法進行了對比,實驗結果表明,本文方法能夠在多個視頻場景下準確檢測煙霧區域,檢測性能得到改善,降低了檢測失敗率,并且具有一定的抗干擾能力。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
