小波特征提取和隨機森林模型解析色譜重疊峰
2019-09-20 00:55:10
測控技術 2019年5期
(東南大學 儀器科學與工程學院,江蘇 南京 210096)
在復雜物質的色譜法解析過程中,經常會有色譜峰重疊[1]的情況發生。目前,用于重疊峰分解的方法有以下幾種:傳統的傅里葉變換和導數等方法對噪聲敏感,降低了信噪比而不利于定性定量分析;垂線法和切線法的原理簡單、計算速度較快,但是對一些重疊峰分解的精度可能會出現較大誤差;曲線擬合法[2]實現過程和運算都比較復雜,難以實現色譜曲線實時處理,在實際的應用中有一定的局限性;小波變換方法雖然運用廣泛[3-4],但容易引起變換后曲線重構的信號不準確;神經網絡法利用了其較強的非線性映射能力計算子峰面積比,但其數學模型較為復雜,網絡結構選擇不一,只能憑借經驗選取,并且它的計算量大,網絡的收斂速度也較慢。
隨機森林模型是一種基于決策樹的算法,被歸類為機器學習中的一種方法[5]。它具有模型簡單、訓練速度快、預測精度高、泛化能力強等突出優點。本文結合了神經網絡法的思想,對隨機森林模型在色譜重疊峰分解領域的應用進行了研究。首先利用gaus1小波分解系數來模擬導數,利用小波分解計算過程中自動消除噪聲的特點,直接從原始的信號中提取相應的導數特征點;然后并以特征點作為模型輸入、重疊峰子峰面積比作為模型輸出,使用交叉驗證的方式確定模型參數,對隨機森林模型進行有監督的訓練;最后使用訓練好的模型擬合待測色譜重疊峰信號的各子峰面積比,實現重疊峰的解析。
1 重疊峰解析基本原理
色譜峰信號一般使用高斯函數來擬合,表達式為:
(1)
式中,t為信號采樣時間;h(t)為信號在時間t時的強度;H為色譜峰信號的最大值;T為峰的保留時間;σ為峰拐點距離峰保留時間的距離。如果色譜峰不對稱,則:t
對于一個由兩個色譜峰疊加而形成的重疊峰,即可以用H1、T1、σ1a、σ1b、H2、T2、σ2a、σ2b八個參數來唯一決定。并且對于化學色譜峰,可以假設兩個子峰的不對稱度相同,即有σ1a/σ1b=σ2a/σ2b,這樣參數的數量就減少到5個。此時可定義此重疊峰的子峰面積比Q如下,其中S1、S2分別為兩子峰面積。
Q=S1/S2
(2)
(3)
色譜重疊峰的分離度RS定義為
(4)
式中,Wi為峰1、峰2的峰底寬度。RS的值越小,則兩峰重疊的越厲害。當RS較小時,兩峰已不能用肉眼識別;當RS接近1.5時,兩峰已基本分離。本文研究的重疊峰分離度RS范圍為0.5~1.4。
色譜重疊峰信號的特征點有起點、拐點、谷點、頂點、終點等,它們是色譜信號中的突變點或是奇偶點,包含了較為重要的信息。由于重疊峰具有前肩峰、后肩峰等不同的形狀,所含有的特征點種類和數量都不相同。只有拐點是所有形式重疊峰都具有的特征點,這些點的橫縱坐標與子峰面積比之間一定存在著某種聯系,但無法用簡單的函數關系式表示出來。考慮到隨機森林模型具有對任意函數進行擬合的能力,并且具有訓練速度快,擬合精度高等優點,因此本文選取其對上述關系進行擬合。
2 連續小波變換計算色譜曲線拐點
導數在信號處理領域發揮著著十分重要的作用,但在實際的色譜分析過程中,信號往往含有較大的噪聲。如果使用點到點微分的方法,求導結果曲線中往往也含有大量噪聲。此時使用二階導數法求取色譜重疊峰拐點,就可能因為噪聲而難以計算出準確的結果。
小波變換為色譜信號求導提供了新的思路,小波變化的小波分解系數可以用來模擬求導[6]。根據小波分解的性質,如果選取的小波滿足小波容許條件,在進行變換的過程中能夠自動地對噪聲進行消除,提高信噪比,得到的結果可以用來模擬導數,彌補了導數法的不足,適用于對色譜重疊峰信號的拐點提取。
本文使用小波模擬一階導數的極值點來檢測原色譜曲線拐點,而不是模擬二階導數的過零點。有以下幾點原因:① 若使用尺度較小的小波在對低信噪比的色譜信號進行分析,小波計算的模擬導數由于仍然存在噪聲,可能會在零點附近波動;② 選取較大的分解尺度時,色譜峰會變得銳化,從而有利于極值點的提取。由于高斯函數的各階導數正好可以滿足小波容許條件,本文選取了gaus1函數作為母小波對原色譜信號進行連續小波變換來模擬一階導數。gaus1函數表達式如下所示,其中C為調整因子。
gaus1(x)=C·e-x2
(5)
圖1為模擬的色譜重疊峰并使用gaus1小波分別在3,10,15,25尺度下進行分解得到的細節系數。從圖中可以看出,隨著分解尺度的增加,小波細節系數也逐漸增大,并且存在4個極值點A、B、C、D。上述小波模擬導數可以代替實際導數計算的理論基礎是特征點位置在小波變換前后沒有發生變換。實際上在選取不同的分解尺度時,可能會造成特征點不同程度的偏移。下面以某后肩峰為例使用gaus1小波,選取不同尺度進行分解并對其拐點進行計算,得到的結果如表1所示,其中模擬信號的范圍為-2000~3000,單位為毫秒(ms),拐點位置為模擬信號的橫坐標值,相對誤差定義為位置誤差與子峰寬度之間的比值。
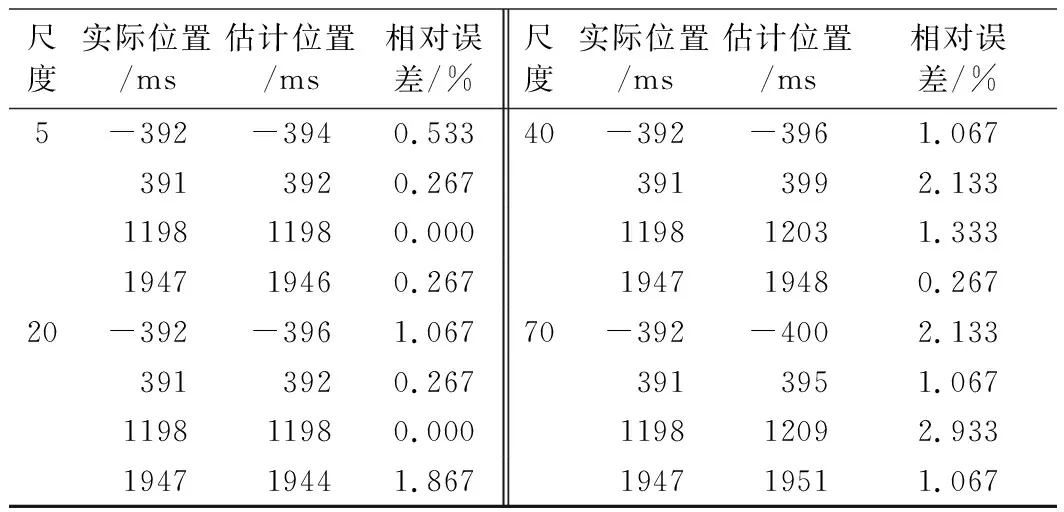
表1 不同分解尺度下拐點位置計算結果
可以看出,使用gaus1小波進行變換之后的模擬導數的4個極值點,相較于原色譜信號的拐點,位置誤差較小。因此,小波變換的方法具有可行性。
下面在重疊峰信號中加入一定量級的白噪聲,對小波模擬導數檢測拐點的抗噪性進行分析。圖2分別是在色譜信號中加入信噪比為20 dB的噪聲后,進行小波變換模擬的一階導數曲線,以及先進行滑動窗口濾波,然后使用數值微分方法求取的一階導數曲線。可以看出,雖然原色譜信號被噪聲污染嚴重,但經過小波計算模擬的一階導數比較光滑,峰形清晰,分辨率較高,明顯優于數值微分方法求取的結果。
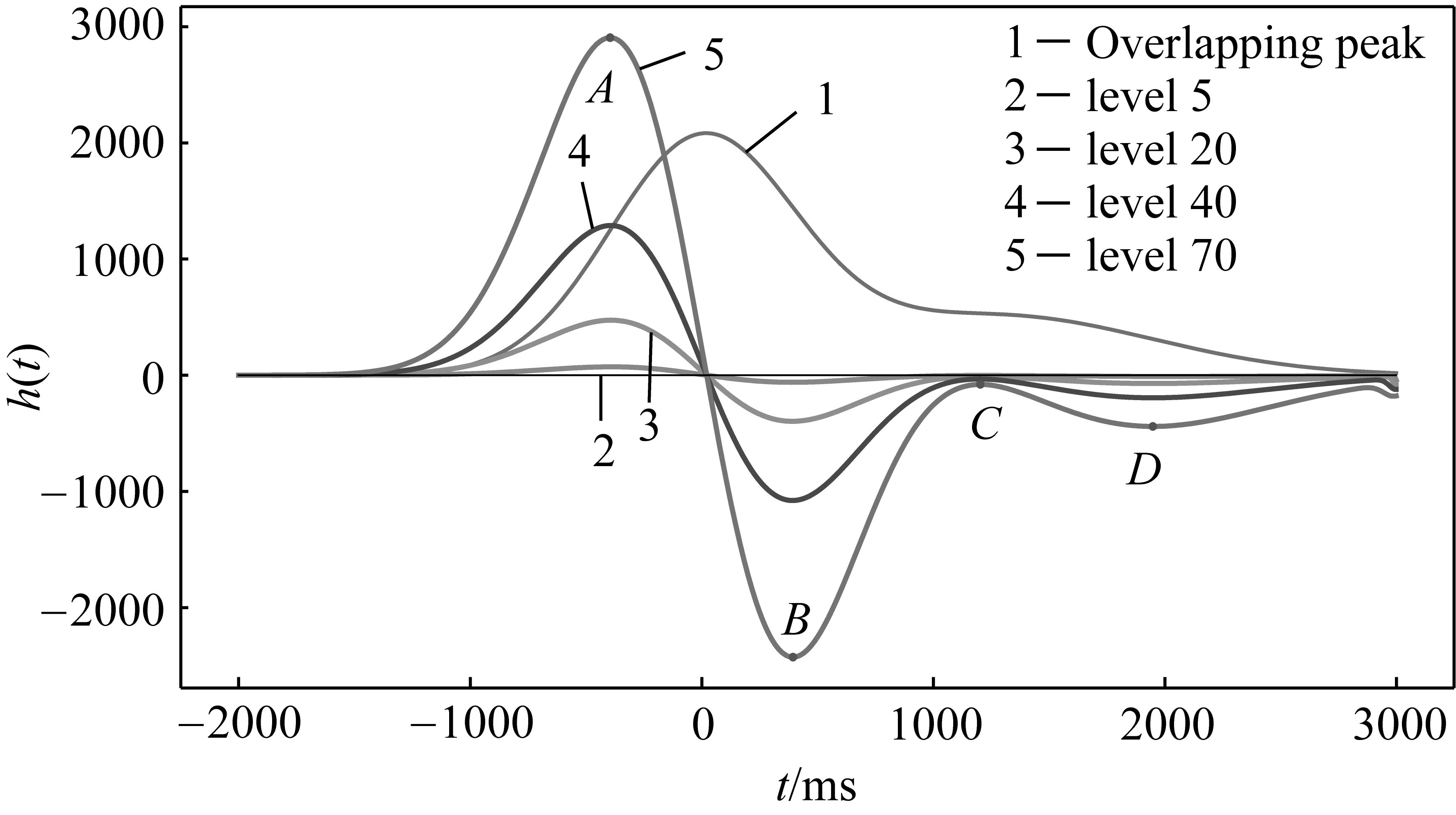
圖1 不同尺度的分解結果
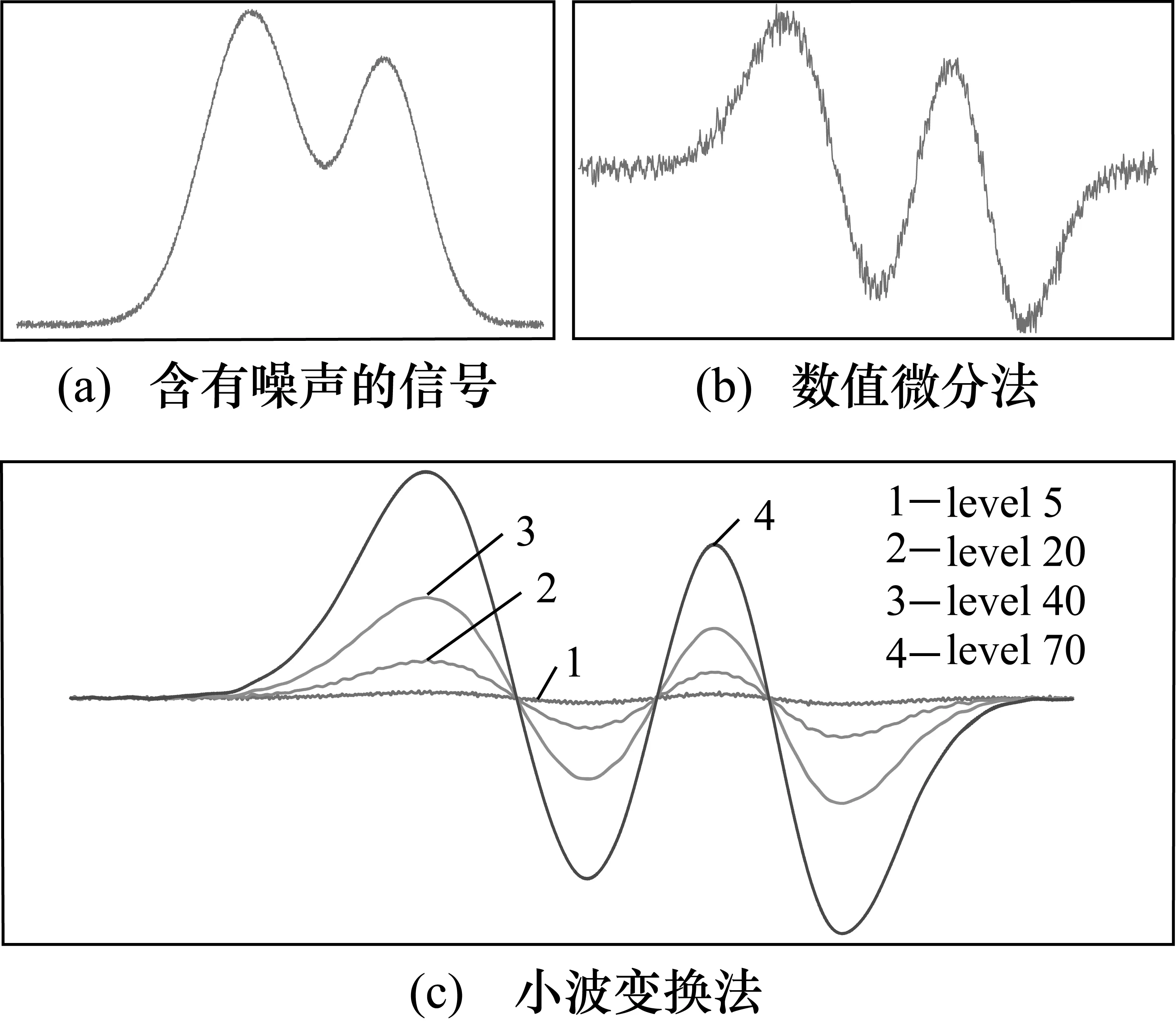
圖2 一階導數曲線
可以看出,隨著分解尺度的增大,模擬的導數曲線越來越光滑,有利于求取其極值點。但由于尺度的增大,其極值點位置也會發生偏移,因此需要合理選擇小波分解尺度。信噪比不同,分解的尺度也應不相同,最優分解尺度應通過觀察小波模擬導數的曲線來確定,當模擬導數的譜峰分辨率有了很大提高,并且導數曲線較為光滑時,即認為是合適的尺度。選取了合適的尺度之后,模擬一階導數曲線也可能存在噪聲的殘留,但相較于原信號已有非常大的改善,優于使用數值微分方法得到的結果。
3 重疊峰解析的隨機森林模型
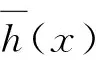
(6)
為了克服單一決策樹模型容易出現過擬合、預測精度不高的缺點,隨機森林模型引入了套袋(bagging)[9]和隨機子空間的思想[10]。可以證明,這兩種方法的運用,不僅可以保證每棵子樹節點之間的特征子集都不同,還可以使得隨機森林模型中的各回歸子樹建立更加隨機化,保證了相互之間的獨立性,從而有效地解決了過擬合的問題,提高了回歸分析結果的精度。子樹的數量和選取的自變量個數會影響到隨機模型的性能,因此本文將使用交叉驗證的方式為模型選取合適的參數。除此之外,在構建回歸決策樹的時候,使用的是CART算法,由于各子樹的構建是相互獨立的,因此可使用多線程的方式并行實現隨機森林模型。
基于隨機森林模型進行重疊峰解析的整體思想如圖3所示。先按照一定的方式模擬不同情況下的色譜重疊峰,使用上文所述小波變換的方法檢測其拐點,為了加快模型收斂,本文由原始的拐點數據生成了5個無因次比值,生成訓練和測試使用的數據集;然后基于網格搜索的方式不斷調整參數的最優組合,使用10折交叉驗證的方式選擇最優的隨機森林模型參數;最后利用最優參數和CART算法構建并訓練模型,使用測試數據集驗證模型的結果。
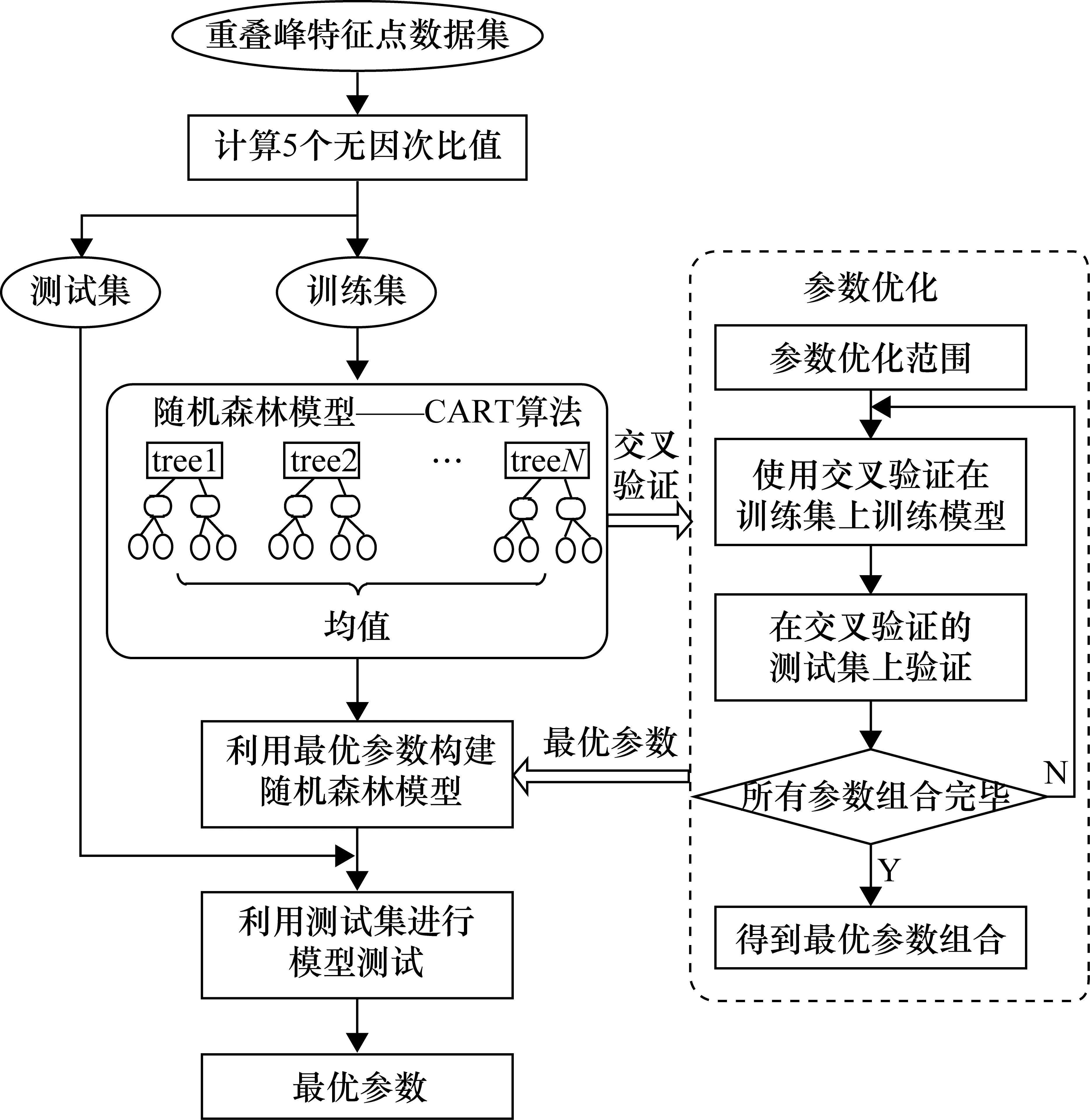
圖3 模型訓練流程
4 模型的配置和訓練
本文參考了神經網絡法分解重疊峰中的數據集產生方法和無因次比值計算方法[11],生成了5400組重疊峰,并按照5:1的比例隨機劃分成訓練集和測試集。然后對訓練集和測試集的每一個重疊峰,使用guas1小波進行小波變換模擬其導數,按圖4所示求其4個拐點A、B、C、D。參考神經網絡方法計算5個無因次比值作為輸入,Q1為需要擬合的因變量,使用第3節的方法訓練隨機森林模型,即可得到自變量和因變量之間的映射關系。
5 實驗驗證
經過模型的網格搜索和交叉驗證,可得到這兩個特征在不同取值時的系數曲線。綜合考慮性能和模型復雜度,得到最優的參數組合為:特征數量3,回歸子樹數量為150。
得到最優參數組合之后,本文使用最優參數建立隨機森林模型,并使用訓練數據集對模型進行訓練。最后使用測試集驗證模型的精準度。采用均方根誤差(RMSE)、最大絕對誤差(MAE)、R2決定系數等參數作為評價的依據,定義如下:
(7)
(8)
(9)
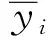
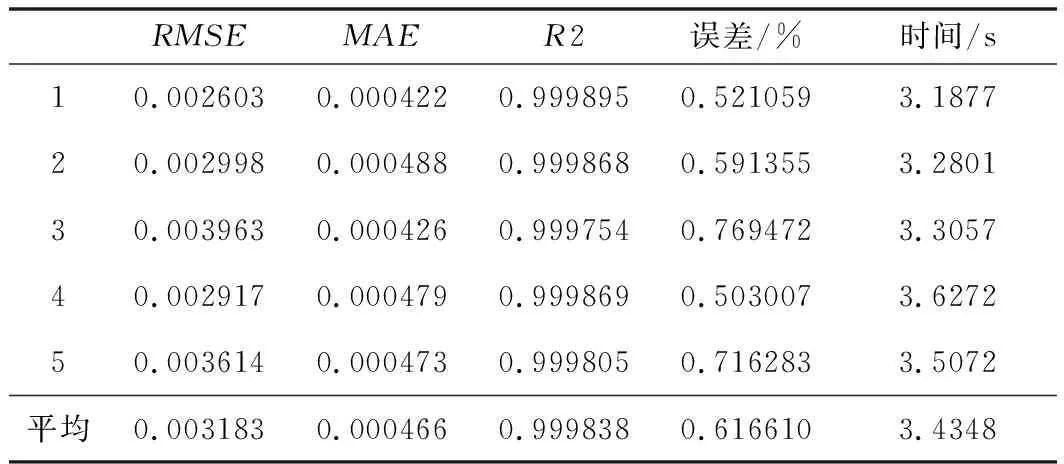
表2 模型性能分析
可以看出,隨機森林模型對輸入輸出的擬合能力很強,平均誤差不到1%,R2決定性系數達到99%以上,說明了本模型具有較強的學習能力和泛化能力。圖4為模型在訓練時的學習曲線,訓練集和測試集收斂于同一條線,說明沒有過擬合的發生。
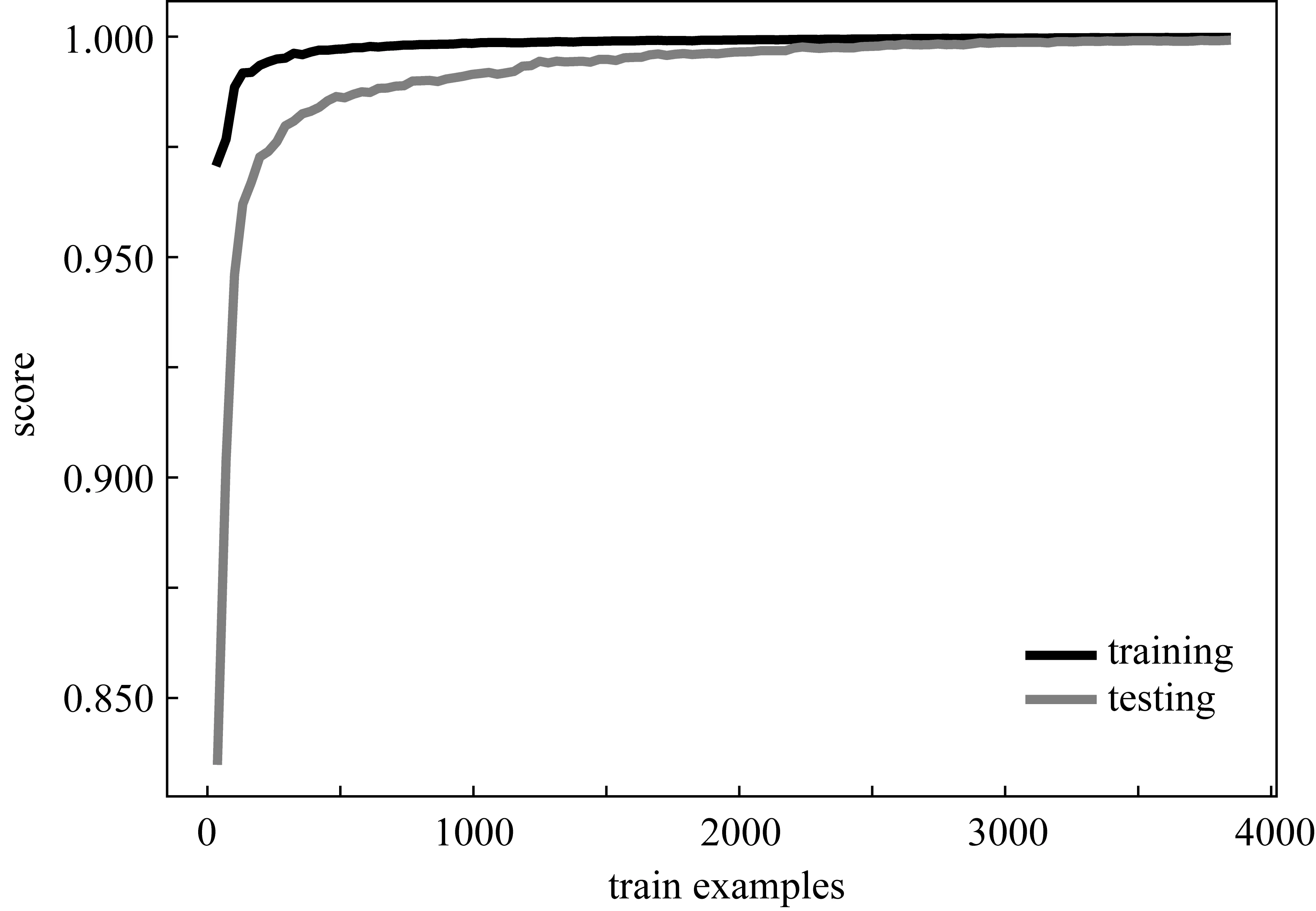
圖4 模型學習曲線
本文還在相同的環境下實驗測試了神經網絡法和垂線法進行了結果對比。其中,神經網絡方法采用的是含有10個隱節點的BP神經網絡,激活函數選用單極性sigmoid函數,學習率為0.01,分別設置了不同的迭代次數進行多次訓練,結果如表3所示。同時,模擬了不同參數(分離度RS、峰1面積比例Q1)下使用垂線法進行計算,其結果如表4所示。
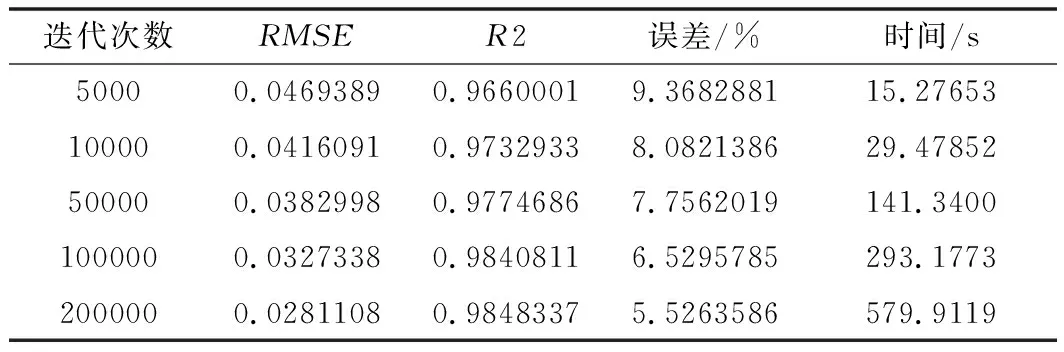
表3 神經網絡性能分析
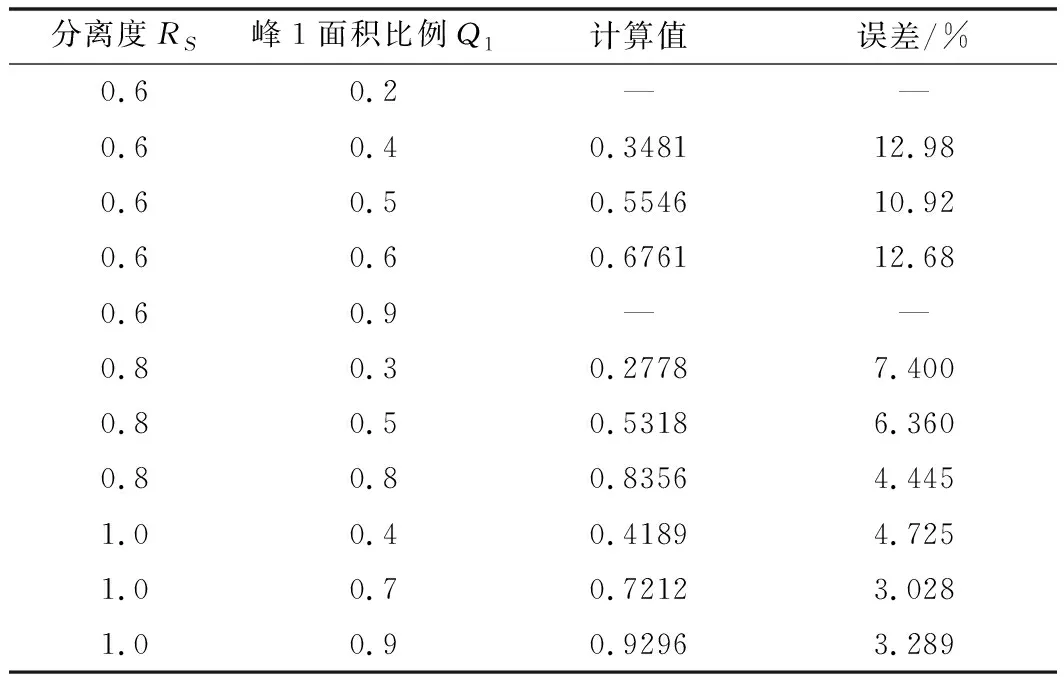
表4 垂線法結果(—代表出現肩峰)
測試的結果表明,雖然神經網絡法也能對輸入輸出進行擬合,但準確度不如本文的隨機森林模型。并且隨著網絡規模的擴大,若要達到相同誤差程度,需要進行成倍規模的計算,訓練時間也遠遠超出。雖然神經網絡也可以通過模型調優等方式使結果精度不斷提高,但不論是其參數選擇還是模型訓練的過程,相較于隨機森林模型而言都較為繁瑣,并且容易陷入過擬合或是局部最優的結果。而垂線法雖然原理簡單,計算速度很快,但是其精度會受到重疊峰的分離度和峰形的影響。一般重疊度越高,垂線法計算的誤差會越大。并且垂線法無法對肩峰進行分割計算,存在使用的局限性。綜合比較各方面而言,本文的模型有著更易理解、參數調節簡單、模型收斂速度快、準確率也較高等優點,具有一定的優勢。
最后,本文使用型號為NP7000C高壓色譜泵和NC3000C系列可見光檢測器,在實際中對本模型的結果進行驗證。設置色譜泵流速為2 ml/min,梯度程序時間為30 min,檢測器波長設為254 nm,流動相為85%的甲醇水溶劑。通過對某一試劑連續進樣,控制其前后兩次進樣的體積比例,人為造成不同比例的重疊峰。對采集到的重疊峰信號進行連續小波變換檢測其拐點,并計算無因次比值作為本模型的輸入,多次實驗的結果如表5所示。
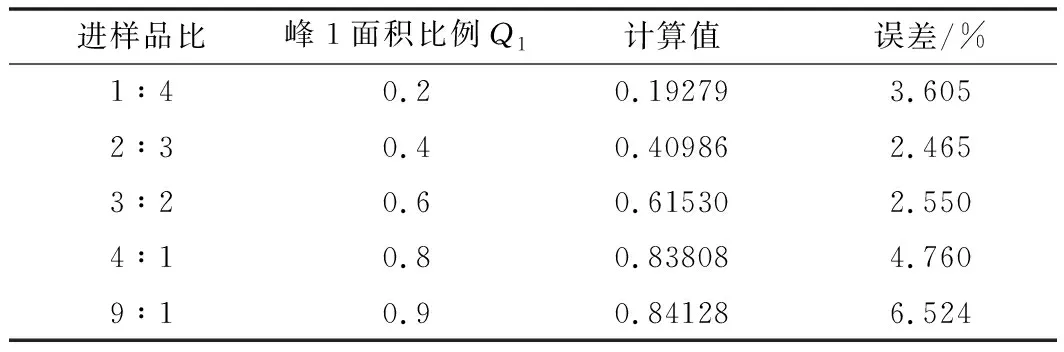
表5 模型實際使用效果
以上實驗結果表明本文提出的利用小波特征提取和隨機森林模型的重疊峰解析方法可以有效地對重疊峰中的子峰面積比值進行計算,結果優于傳統的垂線法和神經網絡法。隨機森林模型的兩大隨機特性可以有效地解決神經網絡模型中的過擬合問題,提高了回歸結果的精度。并且因為模型中各子樹之間的相互獨立性,可通過多線程構建的方式提升模型的訓練速度,從而在性能上具有一定的優勢,克服了傳統神經網絡法計算量大、學習效率低、網絡結構參數難以確定的缺點。從而提高了色譜分析效率,保證了分析結果的準確性。
6 結論
隨機森林作為一種高效的機器學習模型,已經在很多領域得到廣泛的運用,本文將其引入到色譜分析領域。采用本文所述的方法,利用小波變換和隨機森林模型分解色譜重疊峰,在精度上優于傳統的垂線法和神經網絡法。相較于神經網絡方法,它模型簡單、收斂更快、訓練時間更短,因此擁有更高的效率。通過仿真信號和實際色譜信號的實驗驗證表明,本方法得到的結果較為精準,確保了色譜分析結果的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
核科學與工程(2015年4期)2015-09-26 11:59:03
