基于BP神經網絡的合金收得率預測模型
2019-09-21 03:10:50李廷剛馬仲群孫建鵬
山西冶金 2019年3期
關鍵詞:模型
李廷剛, 陳 勇, 鄭 偉, 馬仲群, 孫建鵬, 毛 勇
(五礦營口中板有限責任公司, 遼寧 營口 115000)
脫氧合金化作為轉爐五大制度之一其操作精度的好壞直接影響著板坯的質量及噸鋼成本。現階段大多數鋼廠對合金收得率的預測都是通過經驗判斷,對各鋼種的收得率進行統一估值,忽略了現場其他條件對合金元素收得率的影響,鋼廠應用的轉爐冶煉操作模型大多未設計合金收得率預測模型。開發合金收得率預測模型,可起到提高合金配加精度的作用。
1 BP神經網絡
BP神經網絡是一種按誤差逆傳播算法訓練的多層前饋網絡,是目前應用最廣泛的神經網絡模型之一。BP網絡能學習和存貯大量的輸入-輸出模式映射關系,而無需事前揭示描述這種映射關系的數學方程[1]。它的學習規則是使用最速下降法,通過反向傳播來不斷調整網絡的權值和閾值,使網絡的誤差平方和最小。BP神經網絡模型拓撲結構包括輸入層、隱層和輸出層,如圖1所示。本文應用神經網絡的函數逼近功能,以影響收得率的各項參數為輸入向量,以相應爐次的合金收得率為輸出向量,訓練數值仿真函數對合金收得率進行預測。
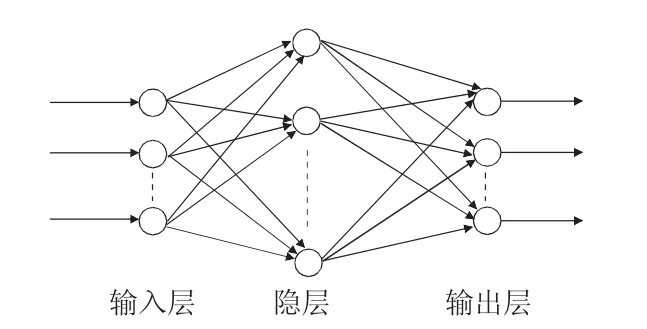
圖1 神經網絡模型拓撲結構
2 模型的建立與驗證
合金進入鋼液后部分溶于鋼液,部分被鋼中氧所氧化并溶于渣中。根據專家的經驗以及對合金配加過程進行分析可得,合金收得率主要由終點C含量、Si含量、氧含量、終點出鋼溫度等因素決定[2]。因此本文以這4個參數作為合金收得率預測模型的變量,輸出變量為合金收得率。合金收得率與輸入變量的關系為:

式中:X1為終點C含量,X2為終點Si含量,X3為終點氧含量,X4為終點出鋼溫度。
2.1 樣本的選取
在訓練模型的過程中應選用合適的樣本容量及個體,若樣本容量過大時,個體數目過多,個體之間的相關性較強,會影響模型整體的穩定性,神經網絡產生震蕩不利于函數收斂。本文對某鋼廠轉爐車間4號LD轉爐的實際生產數據進行篩選,選擇具有代表性的數據對函數進行訓練。
2.2 數據預處理
一般對輸入數據采取歸一化的處理方法,將數據變換到[0,1]區間,變換公式如下:樣本的歸一化與學習的收斂速度有很密切的關系,應盡量用歸一化后的樣本進行學習。網絡的輸出經過反歸一化后就可還原為真實的數據。經驗證明,數據的歸一化能明顯提高學習的速度和精度。對網絡的輸出進行相應的反歸一化,公式為:
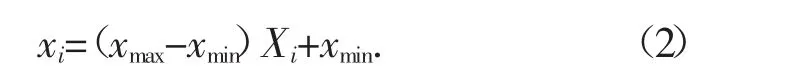
2.3 預測模型的結果與分析
本文選用了三層網絡,輸入神經元數為4,輸出單元數為1,隱含層單元數通過網絡訓練獲得,函數誤差E=1×10-2。從某鋼廠轉爐車間采集了400爐數據,剔除異常數據后,得到319爐生產記錄。選取220爐記錄作為訓練集,99爐記錄作為測試數據并利用MATLAB進行仿真。
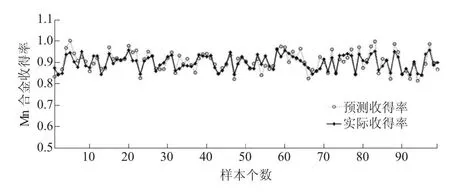
圖2 錳合金收得率預測結果與實際值
圖2為錳合金收得率預測結果與實際值,從圖2中可以看出神經網絡對終點的預報達到了較好的結果。預測結果表明:終點收得率預測平均誤差為0.02,誤差小于0.03的命中率為85.5%,小于0.06的命中率為96%。最大預測誤差小于0.08。本文所建立的模型精確度與現場估算精度相比有了很大提高,能夠在冶煉過程中起到指導作用。
3 結論
1)通過分析影響合金收得率的機理以及對生產數據進行分析,最終確定輸入參數為終點C含量、終點Si含量、終點氧含量、終點出鋼溫度。
2)對所建立的模型的性能進行了研究,對模型預測結果進行了測試,證實模型運行準確可靠。
3)從預測結果看,本文所建立的模型精度較高,能夠為生產冶煉作出指導。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
