基于綜合相似度的旅游景點推薦?
2019-10-08 07:12:04麻風梅
計算機與數字工程 2019年9期
麻風梅
(安康學院電子與信息工程學院 安康 725000)
1 引言
隨著大數據時代的到來,人們已從缺乏信息的時代進入了信息過載時代,網絡上的海量信息讓人們眼花繚亂,無所適從[1]。旅游業作為國民經濟的支柱產業之一,近年來仍在不斷升溫,旅游網站不斷興起,旅游推薦算法成了該領域的研究熱點[2]。針對個性化旅游推薦問題,學者們進行了深入研究,雖然取得了一定進展,然而它依然面臨著諸多挑戰[3]。譬如,當前的推薦系統建模技術并不能準確全面地描述游客偏好,沒有充分利用含有豐富用戶信息的用戶特征數據,缺乏對用戶興趣的綜合考慮等[4]。
針對上述問題,本文提出一種基于綜合相似度的旅游推薦算法,將用戶特征與綜合興趣合理結合。該算法使得系統的推薦效率、可擴展性進一步提高,提高了推薦的準確率。
2 基于綜合相似度的旅游景點推薦算法
基于綜合相似度的旅游景點推薦算法步驟如下。
1)計算用戶特征和用戶興趣相似度,作為綜合相似度。2)根據綜合相似度找到相似用戶群。3)對目標用戶的興趣景點進行預測,做出top-N推薦。
2.1 用戶特征
用戶特征即指人的年齡、性別、工作、學歷、居住地和國籍等,即一般情況下用戶注冊時需要填寫的信息[5]。而這些特征對預測用戶興趣有很重要的作用。中國旅游權威在線分析艾瑞咨詢給出了一組數據,2017年中國旅游景區用戶性別分布中,男、女各占62.9%和37.1%,其中25~40歲的中青年用戶占到75.9%;地理分布上,廣東、上海領跑,旅游用戶最多;職業分布上,旅游景區用戶多為家庭、事業穩定型群體,企業員工、公務員、事業單位人員所占比例最多。該網站的另一組數據分析也指出,在旅游過程中,年輕人更喜歡冒險項目,而老年人更喜歡休閑觀光項目,女性更喜歡購物,而男性更喜歡度假。旅游用戶的行為與其用戶特征有著較大的關系。利用用戶特征推薦相對隨機推薦能夠獲得更好的推薦效果。
本文只對用戶的年齡、性別、居住地和職業等用戶特征進行用戶相似度度量[6]。由于用戶信息大多不是數值型,因此要對用戶特征進行量化或轉化為數值型,以方便計算。通過對數據集中用戶的用戶特征進行量化,形成了用戶-特征矩陣,如表1所示。
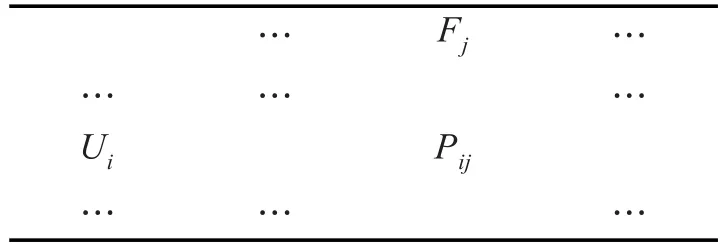
表1 用戶-特征矩陣
其中Ui為第i個用戶,Fj為第 j個用戶特征。Pij表示第i個用戶的第 j個用戶特征值。用戶特征相似度計算方法公式如下:
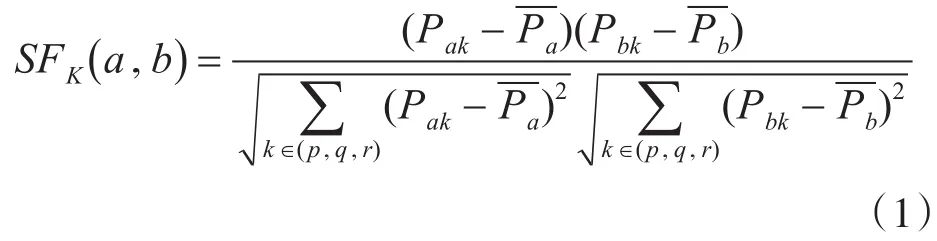
因為不同用戶特征對用戶興趣的影響程度不同,所以本文賦予特征相似度不同權值。公式如下:
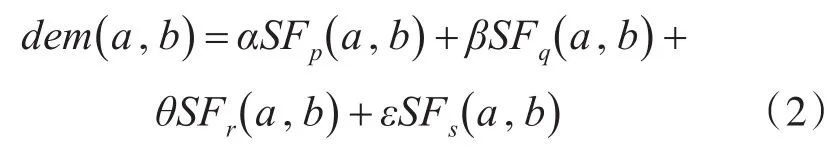
其中SFp(a ,b)為用戶a與用戶b的性別特征相似度,SFq(a ,b)為用戶a與用戶b的年齡特征相似度,SFr(a ,b)為用戶a與用戶b的居住地特征相似度,SFs(a ,b)為用戶a與用戶b的職業特征相似度 。 其 中 , α∈[0 , 1],β∈[0 , 1],θ∈[0 , 1] ,ε∈[0 , 1],且α+β+θ+ε=1。
2.2 用戶興趣相似度
人的興趣是由主觀的表述與客觀的描述兩部分組成。在推薦系統中,我們把用戶在興趣調查中主動提供的本人興趣傾向理解為主觀的興趣表述,這種表述相對固定,屬于顯性興趣;而用戶的種種搜索歷史和訪問行為反映了用戶的實際需要,這種需要的不斷變動往往表示原有興趣的調整,這是用戶興趣的客觀描述,屬于隱性興趣[7]。本文以會話的方式在線獲取用戶的偏好和需求,然后結合對用戶瀏覽行為的分析得到綜合興趣。根據綜合興趣,分析用戶之間興趣的相似程度[8]。
為了更好地解決數據稀疏問題,本文在描述用戶興趣時,首先,利用從旅游游記中提取的信息構建景點本身的特征信息,為景點建立標簽;然后,用景點標簽來描述用戶興趣。在目前的旅游網站上,存在著海量的旅游游記。通過對游記的分析,我們發現用戶在計劃旅游選取景點時,最普遍考慮的因素是景點的所屬區域、當季是否為最佳旅游時間、旅游的主題和景點的類型。所以,我們為景點設置的標簽與這4個因素相關:區域、時間、主題、類型[9]。例如:在計劃旅游時,不同的用戶會偏好不同的主題,一些用戶會偏好符合“徒步”主題的景點,而另一些用戶可能會偏好符合“親子”主題的景點。關于類型,是景點本身的特性。有的景點的類型是“古鎮”,如鳳凰古鎮、束河古鎮;而香港和上海則可以歸到“城市”類型中。關于主題中的“親子”、“情侶”這樣的詞匯,我們稱之為景點主題標簽。同樣地,“城市”、“古鎮”則稱為景點類型標簽[10]。
2.2.1 顯性興趣
顯性興趣是用戶對景點信息認同程度的一種有意識地表達,其特征主要來源于用戶對特定問題的答案分布。本系統采用在線問答的交流方式,各個問題的答案都以選項形式出現,指導用戶在線回答,逐漸啟發用戶的偏好和需求[11]。通常用戶在表達他們的需求時,描述都是模糊的,如“交通便利的”、“設施安全的”、“環境優美的”。為了快速準確識別出用戶的需求目的,本文用景點標簽描述用戶的興趣特征,使用戶感興趣的活動與一個或多個景點標簽相對應,每個答案選項都標有對應的景點標簽。例如,詢問用戶喜歡的運動類型時,提供的答案選項有:徒步、單車等。根據當前的會話情況,將用戶的所有答案映射到不同景點標簽。旅游資源的特性包含有用戶的偏好越多則代表用戶對其的興趣越高[12~13]。
2.2.2 隱性興趣
隱性興趣主要體現于用戶對景點的瀏覽行為信息,用戶對感興趣的景點往往會高頻度地搜索和瀏覽[14~15]。如果用戶訪問了某一景點,就可以認為其對該景點感興趣。用戶對景點的感興趣程度依賴于其對景點的訪問頻度。在某一時間段內訪問同一景點的次數越多,用戶興趣度越大。隱性興趣的獲取方法較為簡單,可從用戶的瀏覽歷史記錄庫中得到其感興趣的景點。再將這些歷史景點信息轉換為與區域、時間、主題、類型4種因素相關的多個標簽信息,并用這些標簽信息來描述用戶的隱性興趣。
通過上述的方法得到顯性興趣標簽和隱性興趣標簽后,將兩者結合,形成用戶的綜合興趣標簽,進而計算用戶間的綜合興趣相似度。
本文采用了John S.Breese提出的用戶興趣相似度計算公式,公式如下:
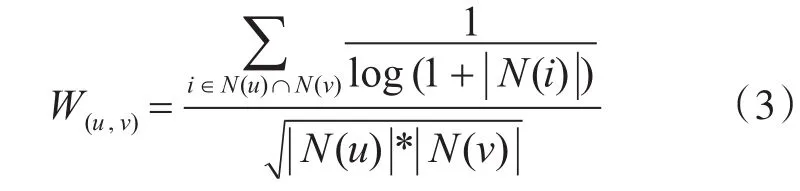
N(u)為用戶u的興趣標簽集,N(v)為用戶v的興趣標簽集,N(i)為用戶u和用戶v共同的興趣標簽集。
本文將用戶特征相似度與用戶興趣相似度相結合,得到綜合相似度,計算公式如下:
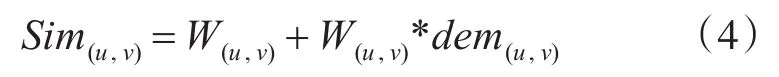
2.3 結合綜合相似度的協同推薦
基于綜合相似度的推薦算法主要包括兩個步驟:1)利用綜合相似度對用戶進行分類,找到相似用戶集合;2)依據相似用戶的旅游記錄為目標用戶推薦感興趣的景點[16]。具體地,對于每一個目標用戶,我們先找到和目標用戶相似度最高的k個用戶,然后對k個相似用戶去過的景點進行計數,選出最受相似用戶歡迎且目標用戶尚未去過的前N個景點作為推薦內容。我們用景點熱度表示景點的受歡迎程度,如式(5)所示。一個景點被參觀的頻次越多,則該景點的熱度越高。特別地,在為目標用戶推薦時,我們提到的某個景點熱度是在相似用戶群中該景點的熱度,而不是在所有用戶中該景點的熱度。
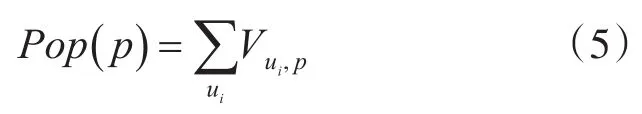
式中,p表示景點數量;ui表示用戶i;Vui,p表示用戶i參觀景點 p的頻次,如果沒有用戶去過景點p,則景點 p的熱度為0。最后,按照景點熱度值的高低來排序,選出前N個推薦給用戶。
3 結語
本文提出了基于綜合相似度的旅游景點推薦算法。該算法綜合考慮用戶特征數據、顯性興趣和隱性興趣向用戶推薦最適合的景點。同時,采用景點標簽來描述用戶興趣,能有效解決數據稀疏問題。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
今古傳奇·故事版(2016年24期)2017-02-07 04:29:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
數學大王·低年級(2014年7期)2014-08-11 16:36:44
河南科技(2014年23期)2014-02-27 14:19:15
