協同過濾推薦算法研究?
2019-10-08 07:12:04李曉瑜
計算機與數字工程 2019年9期
關鍵詞:用戶
李曉瑜
(安康學院電子與信息工程學院 安康 725000)
1 引言
協同過濾也稱為社會過濾由Terry等于1992年提出[1],它計算用戶間偏好的相似性,在相似用戶的基礎上自動的為目標用戶進行過濾和篩選,其基本思想為具有相同或相似的價值觀、思想觀、知識水平和興趣偏好的用戶,其對信息的需求也是相似的[2]。協同過濾推薦技術是推薦系統中最為常用并且有效的方法,主要有兩種類型一種是基于用戶的協同過濾,另一種是基于項目的協同過濾。基于用戶的算法是將和目標用戶有共同興趣愛好的用戶所喜歡的物品且目標用戶沒有購買的物品推薦給目標用戶,基于項目的算法通過目標項目的相似項目集合預測用戶對相似項目的的喜歡程度。協同過濾推薦算法的推薦步驟為建立用戶評分表,尋找相似用戶,推薦物品。協同過濾推薦技術是目前應用廣泛的一種推薦技術,但仍然面臨很多問題,其中主要有:
1)冷啟動問題(Cold-start)[3]
推薦系統需要根據系統中用戶的歷史評價數據來預測用戶未來的興趣,當一個新的戶或一個新項目進入系統時,系統中沒有關于該用戶或項目的評價數據,就沒有辦法找到其近鄰,從而無法對其進行推薦,這就是協同過濾推薦系統中的冷啟動問題。
2)稀疏性問題(Sparsity)
協同過濾推薦需要根據用戶對某些項目的共同評分或相同行為,來進行推薦。由于網絡中項目量非常大,用戶間共同評分的項目可能非常少,這樣就會影響到協同過濾推薦的準確度。對于新加入的項目,系統中沒有用戶關于該項目的評分記錄,我們就無法使用協同過濾推薦技術對其進行推薦。在推薦系統中,數據的稀疏性可以定義為[4]
3)推薦精度問題(Recommendation accuracy)
由于協同過濾推薦技術存在數據稀疏性問題和冷啟動問題,影響到了推薦結果的正確性和精確性。目前主要的研究方向是在解決系統數據稀疏性問題和冷啟動問題的同時,如何保證系統推薦的精度。
本文主要對協同過濾推薦算法中存在的主要問題以及其主要的解決方法進行了總結,同時還對協同過濾推薦過程中計算相似度的方法進行概括和總結。
2 相似度計算方法比較
2.1 傳統相似度計算方法
傳統的相似度度量方法主要有修正的余弦相似性、杰卡德相似、相關相似,具體如表1所示。
2.2 融合用戶活躍度和項目流行度的相似度計算方法[7]
融合用戶活躍度和項目流行度的計算方法是在傳統的皮爾遜(Pearson)相似性計算方法上進行的改進。皮爾遜(Pearson)相似性計算方法需要用戶對項目共同評分,由于數據的稀疏性會導致結果誤差較大,燕山大學的王斌在他的碩士論文中提出了一種融合用戶活躍度和項目流行度的相似度計算方法,通過引入了相關性懲罰權重來降低誤差。項目i和項目j的評分相似性可表示為式(1)。

表1 傳統的相似性度量方法[5~6]

其中Ui和Uj分別表示對項目i和對項目j評分用戶的集合。Ui∩Uj表示對項目i和對項目j共同評分用戶的集合。ru,i和ru,j分別表示用戶u對項目i和項目j的評分。和分別代表用戶對項目i和項目j的平均評分。表示相關性懲罰權重,其計算方法如下:

Iu表示用戶u評價過項目的數量,I表示所有項目的數量。項目i流行度的計算方法如下:

Ui表示評價過項目i的用戶的數量,U表示所有用戶的數量。項目i和項目j流行度的差值計算方式為

當項目i和項目j間的流行度差值大于某個閾值時,就可以不考慮項目流行度對項目相似性計算的影響。
2.3 融合興趣和評分的相似度計算方法[8]
融合興趣和評分的相似度計算方法,考慮到影響項目評分的因素除了評分還有用戶的興趣。將用戶的評分信息映射為興趣向量,先計算用戶的興趣相似性,然后計算項目的評分相似性,最后將用戶興趣相似性和評分相似性進行兩次融合。任意兩個用戶,用戶u和用戶v興趣相似性可表示為


其中當vui和vvi為集合時,其元素允許重復。得到任意用戶u和用戶v之間的興趣相似性sim(u,v)interest,并應用傳統計算相似性方法計算項目評分相似性sim(u,v)rate,則用戶u和用戶v的綜合相似性sim(u,v)計算方式如下:
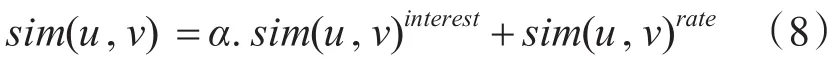
其中α和β是平衡參數,用來控制用戶興趣相似性和用戶評分相似性在用戶綜合相似性中所占的權重,并且α+β=1。
該計算方法可以對傳統相似性度量僅僅依靠用戶評分進行相似性計算引起的誤差進行修正。并在計算用戶評分相似性的時候引入專家信任度,通過引入專家信任度的概念對用戶未評分項目進行評分預測填充,可以降低由于數據稀疏性引起的評分相似性計算誤差。
2.4 基于項目聚類的用戶最近鄰全局相似性[9]
基于項目聚類的用戶最近鄰全局相似性,先計算局部最近鄰用戶相似性。局部最近鄰用戶相似性是在k個項目聚類的基礎上,引入重疊度因子,并將其融合到計算用戶局部相似度的公式中。用戶u和用戶v在聚類Cj上的局部最近鄰用戶相似性可表示為
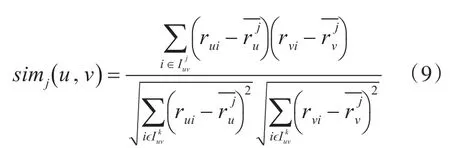

其中,|Iu∩Iv∩Cj|指用戶u和用戶v在聚類Cj上共同評分的項目數,設置參數γ,當用戶共同評分的項目數小于γ,即數據相對稀疏時,共同評價的項目數越多,因子值越大,從而保證只有共同評分項目較多且評分相似的用戶才有可能成為鄰居用戶。
全局最近鄰用戶相似性可以表示為

基于項目聚類的用戶最近鄰全局相似性協同過濾算法,根據用戶共同評分的項目數量,引入重疊度因子,并將其融合到計算用戶局部相似度的公式中,來進一步加強相似度的準確性。同時汕頭大學的李巧雨在她的碩士論文里還提出了混合的相關相似性度量方法和混合的余弦相似性度量方法,來解決傳統相似性度量方法中存在的問題[10]。
3 冷啟動問題解決方法
李歡提出的基于項目相似度學習的協同過濾推薦算法(ISL-CF),通過實驗結果驗證,該算法可以很好地緩解冷啟動問題[11]。劉群、陳陽等提出的融合信任度和相似度的推薦算法,利用用戶間的信任信息,將源用戶的信任鄰居對項目的評分作為該用戶的個人喜好,同時根據基于物質擴散的協同過濾算法找出源用戶的相似鄰居,利用信任鄰居和相似鄰居為該用戶產生推薦,實驗結果表明該算法能有效的解決冷啟動問題[12]。喬雨、李玲娟等提出的融合用戶相似度與評分信息的協同過濾算法,算法先找出用戶基本信息之間的相似度,再根據最速下降法對用戶評分矩陣進行更新,從而產生對目標用戶的推薦,實驗表明,該算法在保證推薦準確率的同時,解決了冷啟動問題[13]。劉坤提出了兩種新的推薦模型:基于偏好的推薦模型NPBM和基于人口統計學的推薦模型NDBM分別用于解決非純冷啟動問題和純冷啟動問題,NPBM算法結合結合機器學習方法,根據用戶的產品評價信息準確地找到冷用戶的最近鄰,然后將這些最近鄰用戶喜歡的產品推薦給冷用戶。NDBM模型利用用戶的人口統計學特征信息準確地找到冷用戶的相似用戶,然后將相似用戶喜歡的產品推薦給冷用戶。實驗結果顯示NPBM和NDBM模型面對冷啟動問題仍然具有較高的推薦準確率,它們能有效地緩解冷啟動問題帶來的影響[14]。
4 稀疏性問題解決方法
安徽大學的李歡提出了一種基于項目相似度學習的協同過濾推薦算法,實驗證明該算法即可以很好地解決數據稀疏性問題也可以緩解冷啟動問題[11]。山東大學的黃山山提出的結合Linked Data的協同過濾推薦算法,利用Linked Data中關于項目的顯式結構化屬性信息定義項目之間的相似度,提出了兩種項目相似度敏感的矩陣分解推薦算法,實驗證明該算法可以很好地解決數據稀疏性問題[4]。李聰、梁昌勇、馬麗等提出基于領域最近鄰的協同過濾推薦算法,以用戶評分項并集作為用戶相似性計算基礎,將并集中的非目標用戶區分為無推薦能力和有推薦能力兩種類型,實驗結果表明該算法可以很好地解決數據稀疏性問題[15]。張俊、劉滿等提出的融合興趣和評分的協同過濾推薦算法,將用戶的評分項目信息映射為興趣向量,計算用戶的興趣相似性,并使用用戶興趣相似性和評分相似性進行兩次融合,從而對傳統相似性度量僅僅依靠用戶評分進行相似性計算引起的誤差進行修正。在計算相似性過程中,通過引入專家信任度的概念對用戶未評分項目進行評分預測填充,從而降低由于數據稀疏性引起的評分相似性計算誤差[8]。假設rui表示用戶u對項目i的評分,定義函數如下:

如果用戶u評論過項目的數量大于某個閾值時,則將用戶u加入到專家集合E中,閾值?的計算方式如下:
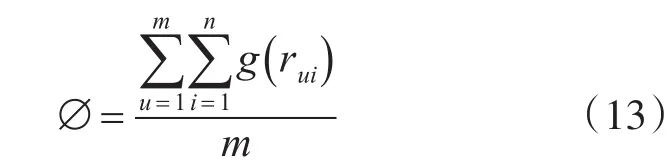
其中m為選取用戶的數量,n為選取項目的數量,rui是用戶u對項目i的評分。則任一專家e對于項目i的信任度計算如下:

其中,C(e)和C(n)分別表示專家e和專家n評論過項目的數量。rui是用戶u對項目i的評分,rni是用戶n對項目i的評分。E表示專家集合,專家對未評分項目的預測評分計算如下:

其中tni代表專家n對項目i的信任度,rni是用戶n對項目i的評分。目標用戶u對未評分項目i的預測評分為:情況[13]。
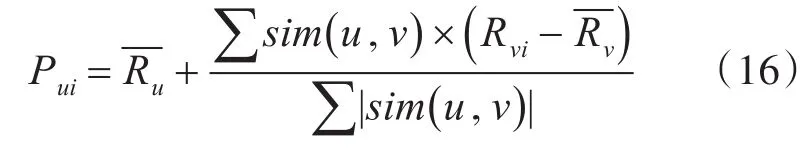
輸入:用戶-項目評分矩陣、項目信息、目標用戶u、目標項目i
輸出:目標用戶u對未評分目標項目i的預測評分。
1)根據用戶-項目評分矩陣和項目信息,計算用戶的興趣向量;
2)由使用式(6)計算用戶之間的興趣相似性,得到用戶興趣相似性矩陣;
3)在原始用戶-項目評分矩陣上找出專家集合E;
4)應用專家集合E,計算任意專家n對項目i的信任度tni,然后應用式(15)計算專家對于未評分項目i的預測評分;
5)根據Pei的結果對用戶-項目評分矩陣進行填充;
6)依據填充后用戶-項目評分矩陣,利用相關相似性度量方法計算用戶之間的評分相似性形成用戶評分相似性矩陣;
7)根據融合興趣和評分的相似度計算方法,計算用戶的相似性,得到用戶綜合相似性矩陣;
8)根據用戶綜合相似性矩陣,獲得目標用戶u的鄰居集Nu;
9)根據式(16),計算目標用戶u對目標項目i的預測評分Pui。
5 推薦精度問題解決方法
賈冬艷、張付志等提出的基于雙重鄰居選取策略的協同過濾推薦算法,動態選取目標用戶的興趣相似用戶集,利用雙重鄰居選擇策略。實驗結果表明該算法不僅提高了系統推薦精度,而且具有較強的抗攻擊能力[16]。孫光福、吳樂等提出的基于時序行為的協同過濾推薦算法,根據用戶間的時序行為進行建模,找到對目標用戶影響最大的鄰居集合,并將最近鄰集合融合到基于概率矩陣分解的協同過濾推薦算法中,實驗證明該算法不僅能夠有效地預測用戶實際評分,還可以有效地提高推薦精度[17]。李巧雨提出的優化的基于用戶聚類的協同過濾算法OUKCF,通過在算法中加入聚類,應用混合相似性計算方法計算用戶相似性,實驗結果證明該算法不僅可以解決數據稀疏性問題和可擴展性問題,同時可以保證推薦的精度。黃山山提出的基于用戶組的二部圖推薦算法,將聚類技術應用到用戶聚類中,利用奇異值分解(SVD)將打分信息進行降維獲得用戶的特征空間,實驗結果表明該算法在提高可擴展性的同時保證了推薦的準確度[10]。蘇芳芳提出的相似度最優加權協同過濾推薦算法,利用PSO優化算法進行模型求解的過程中,使用相關加權的結果作為粒子的初值,極大地加快了收斂速度,實驗結果表明該算法可以很好地改善推薦效果[18]。
6 結語
本文主要介紹了協同過濾算法的推薦流程,存在的主要問題,推薦過程中常用的相似性度量方法,歸納了國內外研究者已經提出的用來解決數據稀疏性,冷啟動和推薦精度等問題的解決方法。與其他學科和領域的融合是協同過濾未來發展的趨勢。隨著互聯網上信息的急劇增長,協同過濾推薦系統常需要處理海量的數據,如何存儲以及如何依據大量的數據計算出推薦結果,是協同過濾推薦面臨的一個挑戰,可以將協同過濾技術與云計算技術相結合,這樣可以使協同過濾推薦系統具有更高的容錯能力,實時推薦能力和更強的并行計算能力。為向用戶提供個性化的商品或服務,協同過濾系統需了解用戶的個人信息,這就涉及到用戶的隱私保護問題。對協同過濾推薦的隱私保護問題的研究還比較少,還需進一步深化。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
