機器學習的五大類別及其主要算法綜述
2019-10-11 11:24:36李旭然丁曉紅
軟件導刊 2019年7期
關鍵詞:機器學習
李旭然 丁曉紅

摘 要:機器學習作為一門源于人工智能和統計學的學科,是當前數據分析領域重點研究方向之一。首先通過追溯機器學習起源和介紹不同算法在求解策略上的啟發性思路,討論五類機器學習的發展及其主要算法在評價方法和優化方式上的實現,進一步總結歸納各算法適用領域和算法優劣,最后指出各算法克服自身缺陷的最新進展和未來實現多算法融合的研究方向。
關鍵詞:機器學習;學習算法;集成方法;增強理論;元學習
DOI:10. 11907/rjdk. 182932 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP3-0文獻標識碼:A 文章編號:1672-7800(2019)007-0004-06
Survey on Five Tribes of Machine Learning and the Main Algorithms
LI Xu-ran,DING Xiao-hong
(School of Mechanical Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
Abstract: Machine learning is a discipline derived from artificial intelligence and statistics, and it has been one of the key research directions in the field of data analysis. This paper introduces the inspiring ideas of different machine learning algorithms in the strategy through their origins, and the realization of five tribes of machine learning and the main algorithms including evaluation function and optimization method. Then applicable fields of each algorithm and both advantages and disadvantages of the algorithm are summarized. Finally this paper points out the latest progresses of each algorithm to overcome its own defects and the future research direction of multi-algorithm fusion.
Key Words: machine learning; learning algorithm; ensemble method; reinforcement learning; meta learning
作者簡介:李旭然(1994-),男,上海理工大學機械工程學院碩士研究生,研究方向為智能設計;丁曉紅(1965-),女,博士,上海理工大學機械工程學院教授、博士生導師,研究方向為機械結構多學科綜合優化設計、智能化創新設計方法。
0 引言
機器學習源于人工智能和統計學[1],在依次經歷了兩個10年的活躍與平靜期后,1980年舉辦的首屆機器學習國際論壇,標志著機器學習全面復蘇。機器學習開始影響文明社會的各行各業,如消費領域自動駕駛、制造業異常檢測、金融業統計分析和零售業在線推薦等。
定義學習機理作為機器學習的關鍵[2-4],在發展史上先后出現了3種類型的論述方式。第一類論述的代表人物為Simon[5],他指出學習是外部行為的變化,即系統通過學習作出自我改變,并在隨后處理相近任務時變得高效;第二類論述的代表人物為Michalski[6],他強調學習的內部過程,即學習是對經驗事物表征的重構;而最后一類論述來自專家系統開發領域,其主要觀點為獲取知識即是學習[7]。
1 機器學習類別
按照學習態度和不同的靈感來源,可將機器學習大致分為5個具有不同思想的類別[8],包括符號主義(Symbolists)、聯結主義(Connectionists)、進化主義(Evolutionaries)、貝葉斯主義(Bayesians)和類推主義(Analogizer)。每個類別圍繞各自的基本思想,有重點研究領域及相應算法。
符號主義認為,所有信息均可簡化為操作符號,符號學者使用符號、規則和邏輯表征知識與進化邏輯進行推理,其主算法是逆向演繹,包括規則學習和決策樹等;聯結主義認為學習是大腦所做的事情,因此聯結學者使用概率矩陣和加權神經元動態地識別和歸納模式,從而對大腦進行逆向演繹,其主算法是反向傳播學習算法,如神經網絡;進化主義從對自然選擇的解釋中發現了學習本質,它通過生成變化,再根據特定目標獲取最優者,在計算機中實現對自然的模仿,其主算法是基因編程,如遺傳算法;不確定性是貝葉斯主義關注的中心,其認為從知識獲取過程到一切既定知識均具備不確定性。貝葉斯學者利用事件發生的概率大小進行計算,其主算法是貝葉斯定理,如樸素貝葉斯和馬爾可夫鏈;類推主義從關系間的相似性著手,推導出其它關系。類推學者根據約束條件優化函數,通過找出需被記憶的經歷并弄清之間的結合關系,實現新場景預測,其主算法是支持向量機。
表1 機器學習類別
在探尋新問題解的過程中,是否可讓計算機記憶足夠大量數據,然后從中尋找出解?答案是否定的。假設將被解答的新問題存儲于數據庫中,而現有數據庫又非常龐大,則該問題出現的概率極低。記憶不能被當作學習算法。符號主義代表人物之一Tom Mitchell[6]察覺到必須在機器學習中預設觀念,即引入附加假設,才可歸納出能力范圍內最具普遍性的規則。另一個質問是如何在概括已知甚至未知的知識時,合理且準確?各類機器學習算法都在設法解答這一歸納性難點。符號主義創始人之一Ryszard Michalski[9]借鑒心理學中的“合取概念”對任意影響結果的因素進行組合,他設想在機器學習到任意一個規則后,用下一個規則盡可能多地包含剩余解,直到得到解對應的規則全集。但多數算法開始掌握的知識有限,這種“分而治之”的歸納算法很容易引起過擬合問題。對此,Stephen Muggleton等[10]借鑒“歸納是逆向演繹”的思路,于1988年設計出第一個歸納邏輯的程序。在面對海量數據時,符號學者提出決策樹歸納,通過對規則的排序或讓其選擇解決多概念規則對應一個實例的問題,保證實例和規則一一對應,使決策樹精度高且易于理解,Ross Quinlan[11]的研究使其成為分類問題的佼佼者。符號主義在1980年代迅速占據了機器學習的主導地位,并在專家系統的應用中大獲成功,但又因為復雜的規則編碼逐漸消失。隨著人工智能技術的提升,上述先驅人物工作之間產生了新的聯系,符號主義機器學習重新活躍起來[12-13]。
聯結主義認為,符號主義僅通過邏輯規則定義概念的方式不足以掌握全部實例。聯結主義信奉“同時被激活的神經元會被聯系在一起”的赫布理論,反過來分析人類大腦的運轉方式[14-15]。1960年前后Frank Rosenblatt[16]通過給McCulloch-Pitts神經元之間的連接賦予不同的權重設計感知器。感知器結構簡單,僅借助例子訓練即可區分圖像聲音。但如果遇到正負實例之間不能被超平面分離的情況,即典型的排斥-或功能(exclusive-OR function, XOR),感知機則不能進行學習。直到1985年同時具有感官和隱藏神經元的玻爾茲曼機器的誕生,將聯結主義的復興帶到頂峰。雖然玻爾茲曼機器有效解決了贊譽分布問題,但在實踐過程中學習行為開展得異常緩慢和艱難。此后不久,Yann LeCun[17]發現了一個既能學習XOR,又能高效處理贊譽分布問題的反向傳播算法,并與Yoshua Bengio等[17-18]對其不斷優化。深度學習算法諸如疊加自動編碼器、卷積神經網絡的誕生讓聯結主義一度成為機器學習的主導思想。
進化主義和聯結主義一樣,都試圖效仿自然進行學習的方法。John Holland[19-20]最早研究的是神經網絡,但隨著關于進化的數學理論體系逐漸成熟,其關注點轉變為一種從達爾文自然選擇理論轉化的算法。遺傳算法類似選擇育種,它通過模擬點突變和染色體交叉過程生成變化,然后引入適應度函數給程序和目標的契合度打分。在解決垃圾郵件過濾的應用過程中,他提出分類器系統的規則集,并利用桶隊算法處理其面臨的贊譽分布問題。盡管如此,與分層感知器相比,分類器系統可適用的領域十分有限。1987年John Koza[21]發現了基因編程方法,即對成熟的計算機程序自身進行進化。這種對程序樹而非字符串進行交叉的方法,使學習活動變得更為靈活。目前聯結主義最引人關注的應用是具有自我意識和創造力進化的機器人研發。反觀進化主義和聯結主義主算法的不同側重點,前者注重結構學習,而后者則通過權值學習解決大部分工作。借助遺傳算法尋找神經網絡最優結構將成為兩種思想的融合點。
與效仿自然的方法截然不同,貝葉斯主義和符號主義都試圖從基本原理中探尋算法學習方式。貝葉斯主義基于貝葉斯定理,發明了樸素貝葉斯分類器,由于它可以獲取輸入輸出間的兩兩相關關系而被廣泛應用,最成功的案例之一是David Heckerman[22]的垃圾郵件過濾器。不論是樸素貝葉斯法還是馬爾可夫鏈,均為貝葉斯網絡特例,后者是由Judea Pearl[23-24]在20世紀80年代創建的一個關系圖譜,包含任意的結構特征,且特征之間允許出現干涉。隨之而來的是使變量呈指數性增大的推理問題,Pearl & Jordan[24-26]分別提出了“環路信念傳播”思想和優化易于處理的分配內參數的方法進行近似推理。
上述4個類別的一個共同缺點在于,它們學習研究的顯式模型在數據不充足的情況下無法繼續有效。但類推主義卻可以僅從小數據中進行學習,包括高效的最近鄰算法和準確的支持向量機。Peter Hart等[27]創建的最近鄰算法也被算作懶惰學習算法之一,它將每個數據點變成微型分類器,每次僅構建局部模型,其優點為學習過程簡單、快速,但是也使其受“維數災難”的影響比所有其它學習算法大。直到20世紀90年代,Vladimir Vapnik等[28-29]開發出的支持向量機成為類推主義新代表,支持向量機與加權k最近鄰算法很像,但前者能夠提供平緩的邊界且不產生過擬合。Douglas Hofstadter[30]對類比推理學習評價頗高。
2 機器學習主算法
2.1 決策樹
符號主義的主算法是決策樹(Decision Tree)。作為一類模仿人腦在日常生活中處理決策問題的方法,決策樹具有如面對“是否”、“好壞”等二分類任務的二叉樹結構[30-32]。在得到問題結論即最終決策的過程中,所有對數據[(x,y)]中各特征[a]子決策判斷的累積,使求解范圍不斷縮小。通常而言,一棵完整的決策樹由一個包含數據和特征全集的根節點、若干代表特征判定的過程節點以及相應代表決策結果的葉節點組成。從根節點到葉節點的過程參照“分而治之”的機制展開,如圖1所示。
圖1 決策樹學習策略
其中,決策樹學習的核心問題之一是特征劃分。3種經典劃分方法形成了決策樹的3種代表性算法:ID3、C4.5和CART(見表2)。
表2 決策樹算法
剪枝是決策樹學習的第二個核心問題,按照決策樹生成與否分為先、后兩種剪枝方式,以解決數據過擬合帶來的后果,見表3。
表3 避免過擬合策略
2.2 人工神經網絡
聯結主義主算法是人工神經網絡(Artificial Neural Networks,ANN)。以神經網絡中的最小單元,即經典M-P神經元模型為例[33-34],當前神經元收到來自前方神經元輸出信號[X]加上權值[ω]后的信號,借助響應函數[f]如Sigmoid函數產生最終輸出信號[Y],與閾值[θ]對比的結果如圖2所示。
圖2 經典神經元模型
在神經網絡發展過程中出現了前饋神經網絡和遞歸神經網絡[8]兩種結構。后者打破了前者關于輸入和輸出相互獨立的假設,通過網絡建立的環形結構使某些輸出信號反饋成為輸入信息,見表4。
表4 神經網絡類別
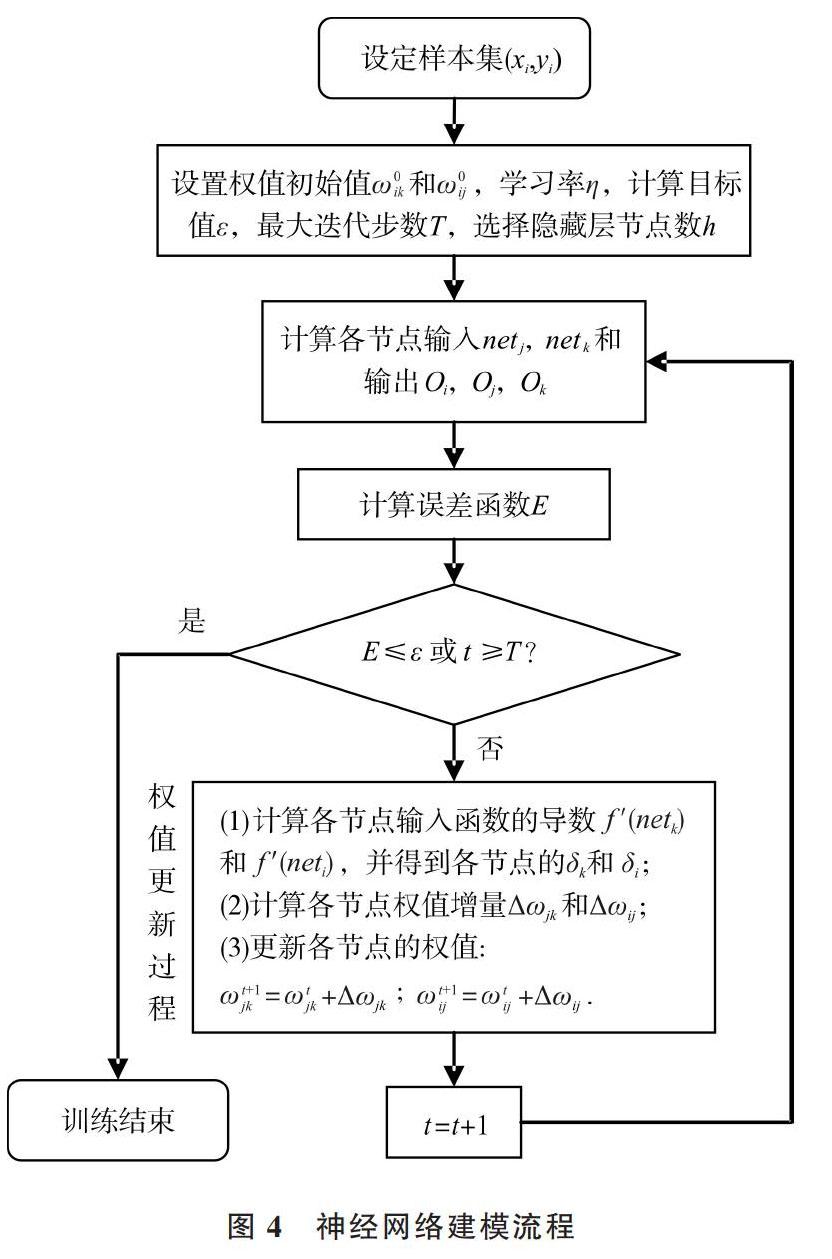
同時,誤差反向傳播(Error Back Propagation,BP)算法[9]既可以用在前饋神經網絡,又可以用于遞歸神經網絡訓練,并得到最廣泛的使用。以BP算法訓練的m輸入n并輸出單隱層前饋神經網絡為例,其拓撲結構見圖3。
圖3 單隱層BP神經網絡拓撲結構
其中,[ωij]為輸入層節點[i]和隱含層節點[j]之間的權值,[ωjk]為節點[j]和輸出層節點[k]之間的權值。記[Oi]為節點[i]的輸出(數值上等于[Xi]),[Netj]為節點[j]的輸入,[h]為隱含層節點數,得到神經網絡輸出為:
記網絡輸出[Yk]與期望輸出[Yk]的均方誤差為[Ek],學習率[η],基于梯度下降法,有隱藏層節點[j]和輸出層節點[k]之間的權值增量計算公式為:
其中[δk=(Yk-Yk)f(Netk)],同理得到輸入層節點[i]和隱含層節點[j]的權值增量[△ωij]和[δj],從而BP神經網絡建模流程如圖4所示。
圖4 神經網絡建模流程
2.3 遺傳算法
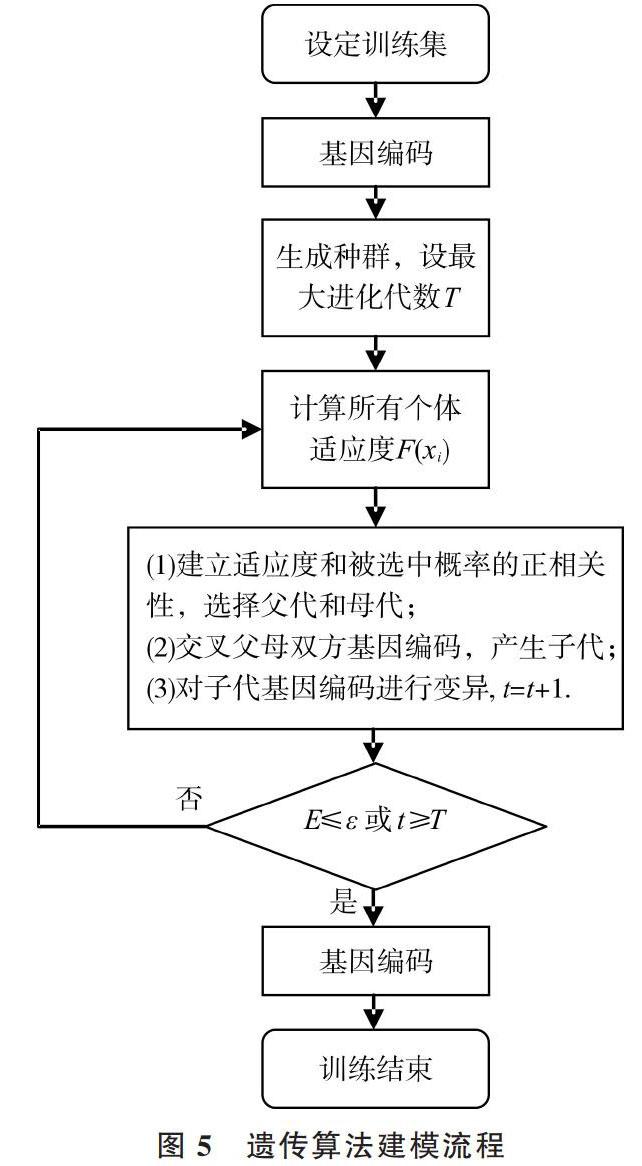
進化主義主算法是遺傳算法。遺傳算法努力避開問題的局部解,并嘗試獲得全局最優解,其基本思想來自達爾文物競天擇觀和遺傳學三大定律[35]。具體做法包括設計對問題解的編碼規則,利用適應度函數和選擇函數剔除次優解,再借助“交叉重組”及“變異”方法生成新的解,直到群體適應度不再上升,見圖5。
圖5 遺傳算法建模流程
其中,迭代終止條件是群體適應度最大值與平均值相差E小于容差[ε]或迭代次數[t]超過最大進化代數[T],表達個體適應度[F]和其被選中概率[P]的常用公式為:
值得注意的是,基因編碼方式的合理選擇對遺傳算法效果影響顯著,常見編碼方式及特點見表5。
表5 遺傳算法編碼方式及特點
2.4 樸素貝葉斯
貝葉斯主義主算法是樸素貝葉斯算法[36-37]。源于統計學的貝葉斯定理可以表示為:
P(原因|結果)=P(原因)×P(結果|原因)/P(結果)
面對多分類問題,用訓練數據[X]代替上式“結果”,用離散的數據特征種類[C]代替“原因”。為方便得到條件概率[Pxc],忽略各特征間對分類作用的關聯,此時有:
[Pcx=PcPxcPx=PcPxi=1dPxic] (4)
使樣本按最低風險選擇特征種類的最優分類判定準則有:
[H(x)=argmaxc∈CP(c)i=1dPxic]? ? ? ? ? ?(5)
其中[C]為特征種類[c]的取值集合,數量為[d]個。
但由于實際應用中各特征很可能相互干涉,且訓練數據有缺失,于是又從中演化出其它算法,以增強泛化能力,見表6。
表6 貝葉斯算法及改進
2.5 支持向量機
類推主義的主算法是支持向量機。找到合理劃分數據的超平面是該算法基本思想[38](見圖6)。
圖6 超平面和間距
其中法向量[ω]和常量[b]通過分別定義超平面的方向與其到原點的距離,使該超平面被唯一確定。此時問題核心為兩“支持向量”的間距[γ]最大化。經處理后得到數學優化模型為:
其中訓練集[D]內[yi]的取值為[±1]。為了更高效地計算,通過例如Sequential Minimal Optimization (SMO)算法,求解由拉格朗日乘子法和Karush-Kuhn-Tucker (KKT)條件轉化得來的式(6)之對偶問題。
若去除上述討論中數據是線性可分的假設,則需引入核函數[κ(xi,xj)]將問題簡化。該技術采用升維思想,通過非線性映射[φ(?)],將原始數據如二維空間轉化成更高維的三維空間,即可在高維特征空間中使數據線性可分,并按相似步驟求解。值得注意的是,核函數的函數選取對能否接近問題的最優解有很大影響。依據經驗首先試用高斯核函數。
支持向量機的功能包括處理分類(Support Vector Classify,SVC)問題和回歸(Support Vector Regression, SVR)問題兩種。本文著重討論其分類功能,而兩者主要差異在于數學模型。對于回歸問題,此時訓練集[D]內[yi]屬于實數域。若訓練數據與回歸函數之間的偏差不超過[ε]即被算法采納,見圖7。
圖7 支持向量回歸原理
此時,回歸問題的數學模型可轉化為:
其中[C]為正則化因子,[ξi]和[ξi]為函數兩側松弛因子。
3 結語
機器學習各類別代表方法、評價及優化部分總結如表7所示。
符號主義主算法決策樹可以處理機器學習的分類任務和回歸任務,優點包括學習效率高、解釋性強,適用于具有不相關特征或特征缺失的場合,缺點包括無法考慮數據間的關聯,易受數據在某特征內數量多少的影響發生過擬合。對此,現在多采用集成方法,如隨機森林(Random Forest,RF)克服決策樹的缺點,提升學習準確度。
表7 各類別機器學習算法
聯結主義的主算法為人工神經網絡,可以處理機器學習回歸任務,優點包括學習能力強,魯棒性好;缺點包括需要做大量前期參數優化工作,學習效率低,學習過程不可知。但伴隨著深層神經網絡等深度學習算法的誕生,該方法在工程上得到了廣泛應用。
進化主義的主算法是遺傳算法,適用于解決最優化問題,相比傳統方法如爬山法,可更有效地與其它機器學習算法結合,在神經網絡中實現參數優化。其缺點是數學基礎薄弱,缺乏完整的收斂理論。
貝葉斯主義的主算法樸素貝葉斯模型,可處理機器學習分類任務,優點包括數學基礎堅實,學習能力強,適用于數據缺失的學習情景;缺點是要求數據量大,計算效率低。
類推主義主算法的支持向量機,可以處理機器學習分類任務和回歸任務,優點包括數據需求量小,計算精度高,適用于高維特征空間和多輸入多輸出問題。但核函數選取和具體問題相關,缺乏明確規則,導致對缺失的數據處理效果差。
綜上所述,各種類別的機器學習算法均有擅長的領域和難以克服的缺陷,其未來趨勢是進一步融合,如完善集成方法[39-40]和增強理論[41-42],或利用元學習(Meta Learning,ML)算法解決更深層次的學習“如何學習”的問題。
參考文獻:
[1] 王玨,周志華,周傲英. 機器學習及其應用[M]. 北京:清華大學出版社,2006.
[2] 閆友彪,陳元琰. 機器學習的主要策略綜述[J]. 計算機應用研究, 2004, 21(7):4-10.
[3] 李世軍. 非概率可靠性理論及相關算法研究[D]. 武漢:華中科技大學, 2013.
[4] 王光宏,蔣平. 數據挖掘綜述[J]. 同濟大學學報:自然科學版, 2004,32(2):246-252.
[5] KOTSIANTIS S B, ZAHARAKIS I D, PINTELAS P E. Machine learning: a review of classification and combining techniques[J]. Artificial Intelligence Review, 2006, 26(3):159-190.
[6] MITCHELL T M. Machine learning. [M]. 北京:中國機械出版社, 2003.
[7] ROBERT C. Machine learning, a probabilistic perspective[M]. Cambridge:MIT Press, 2012.
[8] DOMINGOS P. The master algorithm: how the quest for the ultimate learning machine will remake our world[M]. England:Reed Business Information Ltd., 2015.
[9] ANDERSON J R,MICHALSKI R S,MITCHELL T M. Machine learning, an artificial intelligence approach[M]. Berlin:Springer,1984.
[10] MUGGLETON S,BUNTINE W. Machine invention of first-order predicates by inverting resolution[M]. Machine Learning Proceedings, 1988:339-352.
[11] QUINLAN J R. C4.5: programs for machine learning[M]. NewYork:Morgan Kaufmann Publishers Inc. 1992.
[12] DOMINGOS. Toward knowledge-rich data mining[J]. Data Mining & Knowledge Discovery, 2007, 15(1):21-28.
[13] SILVER N. The signal and the noise[M]. New York:Penguin Press, 2012.
[14] SEUNG S. Connectome: how the brain's wiring makes us who we are[M]. Boston:Houghton Mifflin Harcourt Trade, 2012.
[15] MCCLELLAND,JAMES L. Parallel distributed processing[M]. Cambridge:The MIT Press, 1986.
[16] ANDERSON J A,ROSENFELD E. Neurocomputing: foundations of research[J]. Artificial Intelligence, 1992, 53(2-3):355-359.
[17] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
[18] BENGIO, Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning, 2009, 2(1):1-127.
[19] WALDROP,MITCHELL M. Complexity: the emerging science at the edge of order and chaos[M]. New York:Simon & Schuster, 1992.
[20] HARIK G R. The compact genetic algorithm[J].? IEEE Transactions on Evolutionary Computation, 1999, 3(4):287-297.
[21] KOZA J R. Genetic programming: on the programming of computers by means of natural selection[M]. Cambridge:MIT Press,1992.
[22] HECKERMAN D. Bayesian networks for data mining[J]. Data Mining & Knowledge Discovery, 1997, 1(1):79-119.
[23] DUDA R O,HART P E. Pattern classification and scene analysis[M]. New Jersey: Wiley, 1973.
[24] DARWICHE A. Modeling and reasoning with bayesian networks[M]. Cambridge:Cambridge University Press,2009.
[25] HOFF P D. A first course in bayesian statistical methods[M]. New York:Springer, 2009.
[26] MCGRAYNE S B. The theory that would not die:how bayes' rule cracked the Enigma code, hunted down russian submarines, and emerged triumphant from two centuries of controversy[M]. New Haven:Yale University Press, 2011.
[27] COVER T,HART P. Nearest neighbor pattern classification[M]. NewYork:IEEE Press,1967.
[28] QUINLAN J R. Induction on decision tree[J]. Machine Learning, 1986, 1(1):81-106.
[29] CRISTIANINI N, SHAWE-TAYLOR J. An introduction to support vector machines[M]. Cambridge:Cambridge University Press,2000.
[30] HOFSTADTER D. The man who would teach machines to think[M]. Washington:The Atlantic, 2013.
[31] SURHONE L M, TENNOE M T, HENSSONOW S F, et al. Random forest[J]. Machine Learning, 2010, 45(1):5-32.
[32] HUANG L,CHEN H,WANG X,et al. A fast algorithm for mining association rules[J]. Journal of Computer Science and Technology, 2000, 15(6):619-624.
[33] DEMUTH H B,BEALE M H,JESS O D,et al. Neural network design[M]. 戴葵,李伯民,譯. 北京:中國機械出版社,2007.
[34] 李彥冬,郝宗波,雷航. 卷積神經網絡研究綜述[J]. 計算機應用,2016,36(9):2508-2515.
[35] 吉根林. 遺傳算法研究綜述[J]. 計算機應用與軟件,2004,21(2):69-73.
[36] HOFF P D. A first course in Bayesian statistical methods[J]. Journal of the Royal Statistical Society,2010,173(3):694-695.
[37] 王愛平,張功營,劉方. EM算法研究與應用[J]. 計算機技術與發展,2009,19(9):108-110.
[38] 婁鈺. 支持向量機算法研究[D]. 大連:大連理工大學, 2007.
[39] 董樂紅,耿國華,高原. Boosting算法綜述[J]. 計算機應用與軟件,2006,23(8):27-29.
[40] 于玲,吳鐵軍. 集成學習:Boosting算法綜述[J]. 模式識別與人工智能,2004,17(1):52-59.
[41] 孫志軍,薛磊,許陽明,等. 深度學習研究綜述[J]. 計算機應用研究,2012,29(8):2806-2810.
[42] LECUN Y,BENGIO Y,HINTON G. Deep learning.[J]. Nature, 2015, 521(7553):436-444.
(責任編輯:江 艷)
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
