協(xié)同KPCANet模型在人臉識(shí)別中的應(yīng)用
2019-10-18 02:57:59楊翠萍魏赟
軟件導(dǎo)刊 2019年9期
楊翠萍 魏赟


摘 要:為解決手工提取圖像特征過(guò)程繁復(fù)和參數(shù)復(fù)雜問(wèn)題,提出一種基于深度學(xué)習(xí)的協(xié)同KPCANet模型。該算法能夠?qū)ΜF(xiàn)場(chǎng)采集到的人臉數(shù)據(jù)和特征進(jìn)行提取和分類,通過(guò)提取分塊直方圖特征進(jìn)行編碼協(xié)同表示,將測(cè)試樣本歸于殘差最小的類中對(duì)人臉數(shù)據(jù)進(jìn)行識(shí)別和運(yùn)算。實(shí)驗(yàn)結(jié)果表明,協(xié)同KPCANet模型在濾波器數(shù)量L1=10時(shí)一層卷積層與L2=15時(shí)二層卷積層的正確率分別達(dá)到99.17%和99.44%。協(xié)同KPCANet模型不僅能使運(yùn)算過(guò)程簡(jiǎn)潔,還能提高識(shí)別結(jié)果準(zhǔn)確度,提升識(shí)別效率。
關(guān)鍵詞:特征提取;深度學(xué)習(xí);KPCANet;人臉識(shí)別
DOI:10. 11907/rjdk. 191123 開(kāi)放科學(xué)(資源服務(wù))標(biāo)識(shí)碼(OSID):
中圖分類號(hào):TP301文獻(xiàn)標(biāo)識(shí)碼:A 文章編號(hào):1672-7800(2019)009-0022-04
Application of Cooperative KPCANet Model in Face Recognition
YANG CUI-ping, WEI Yun
(School of Optoelectronic Information and Computer Engineering,
University of Shanghai for Science and Technology, Shanghai 200093, China)
Abstract: In order to solve the complex process and parameters of extracting features manually from image features at this stage, a collaborative KPCANet model based on deep learning is proposed, which can extract and classify face data and features collected on the spot. This algorithm recognizes and calculates the face data by extracting the block histogram features and co-representation coding, kernel principal component analysis network, binary hash coding, calculating the coding residuals, and classifying the test samples into the classes with the smallest residuals. The experimental results show that the correctness of the cooperative KPCANet model in the number of filters L1 = 10 layer convolution layer and L2 = 15 layer convolution layer reaches 99.17% and 99.44%, respectively. Collaborative KPCANet model can not only simplify the operation process, but also improve the accuracy and efficiency of recognition results.
Key Words: feature extraction; deep learning; KPCANet; face recognition
0 引言
計(jì)算機(jī)視覺(jué)技術(shù)中的基本問(wèn)題是圖像識(shí)別技術(shù),成熟的圖像識(shí)別技術(shù)可以追蹤檢測(cè)物體狀態(tài),對(duì)數(shù)據(jù)進(jìn)行有效分析。人工智能技術(shù)使現(xiàn)有產(chǎn)業(yè)能夠?qū)崿F(xiàn)無(wú)人運(yùn)作,人臉識(shí)別作為智能設(shè)備的重要組成部分在科技進(jìn)步和社會(huì)發(fā)展中占有重要地位。人臉識(shí)別技術(shù)研究中的圖像特征提取成為重要研究課題[1]。采用人臉識(shí)別技術(shù)建立自動(dòng)人臉識(shí)別系統(tǒng),配合計(jì)算機(jī)實(shí)現(xiàn)對(duì)人臉圖像的自動(dòng)識(shí)別具有良好的應(yīng)用前景。圖像特征提取的主要困難是相當(dāng)大的類內(nèi)變異性,由不同的照明、剛性變形、非剛性變形和遮擋引起,對(duì)圖像識(shí)別影響很大。因此,人臉識(shí)別準(zhǔn)確率一直很難達(dá)到一個(gè)比較高的水平[2]。深度學(xué)習(xí)方法成為關(guān)注的焦點(diǎn),該方法模擬人類大腦的深度組成結(jié)構(gòu),通過(guò)組合低層特征從而獲取更為抽象、有效的高層語(yǔ)義信息,具有學(xué)習(xí)不變特征能力[3]。在不斷試驗(yàn)的基礎(chǔ)上,人工智能學(xué)者提出了基于多種架構(gòu)的深度學(xué)習(xí)算法。文獻(xiàn)[4-6]提出卷積深度置信網(wǎng)絡(luò)(Convolutional Deep Belief Networks,CDBN),能提取原始圖像中的微表情等高級(jí)別視覺(jué)元素;深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Networks,DNNs)具有更好的提取圖像幾何信息能力,并能對(duì)這些信息整合和分類,但存在運(yùn)算量大和過(guò)擬合等缺點(diǎn);卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNNs)具有訓(xùn)練簡(jiǎn)易和網(wǎng)絡(luò)參數(shù)較少的優(yōu)點(diǎn)。Bruna等[7]建立了一個(gè)散射網(wǎng)絡(luò)(ScatNet),它對(duì)剛性和非剛性變形都是不變的。吳等[8]提出了核主成分分析網(wǎng)絡(luò)(KPCANet),級(jí)聯(lián)兩個(gè)KPCA階段和一個(gè)匯集階段,當(dāng)核函數(shù)為線性時(shí),所提出的KPCANet退化為PCANet。另外文獻(xiàn)[8-12]證明了KPCANet對(duì)光照是不變的,并且對(duì)輕微的非剛性變形是穩(wěn)定的,在人臉識(shí)別和物體識(shí)別任務(wù)上都優(yōu)于PCANet。PCANet深度網(wǎng)絡(luò)融合了卷積神經(jīng)網(wǎng)絡(luò)與哈希直方圖的優(yōu)勢(shì)。在使用智能設(shè)備識(shí)別人臉過(guò)程中,各個(gè)樣本數(shù)據(jù)之間的相互合作和相對(duì)距離都有助于設(shè)備正確識(shí)別。在這個(gè)基礎(chǔ)上,張等[13]研制出了高效率的人臉識(shí)別設(shè)備,但卻無(wú)法識(shí)別那些被遮擋的面部表情。為解決這類設(shè)備缺陷,本文提出一種基于深度學(xué)習(xí)框架的協(xié)同KPCANet模型,能夠?qū)Σ杉母鞣N人臉數(shù)據(jù)進(jìn)行特征提取和分類。該算法利用深度學(xué)習(xí)圖像特征提取框架提取靜止?fàn)顟B(tài)下的人臉圖像特征,并利用協(xié)同表示分類器進(jìn)行分類,從而獲得較高的識(shí)別準(zhǔn)確率。
協(xié)同KPCANet應(yīng)用步驟如下:通過(guò)核主成分分析網(wǎng)絡(luò)、二值哈希編碼、提取分塊直方圖特征后進(jìn)行協(xié)同表示編碼,計(jì)算編碼殘差,在殘差最小的一類中放入測(cè)試樣本。實(shí)驗(yàn)結(jié)果表明:協(xié)同KPCANet模型在濾波器數(shù)量L1=10時(shí)一層卷積層與L2=15時(shí)二層卷積層的正確率分別達(dá)到了99.17%和99.44%。
1 算法設(shè)計(jì)
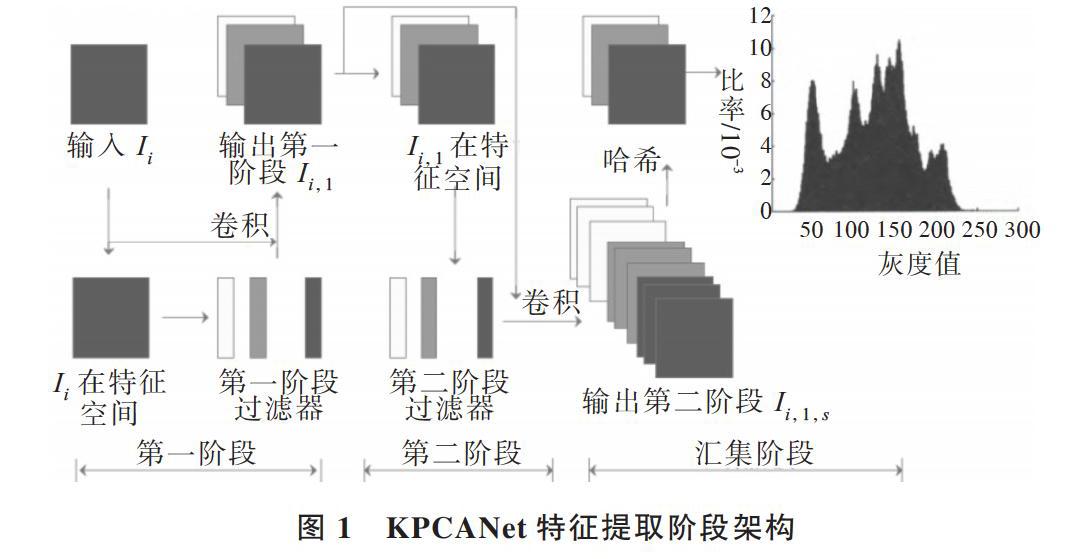
在KPCANet框架中,卷積層的濾波器主要采用基本的KPCA濾波器,運(yùn)用二值哈希編碼對(duì)重采樣層和非線性層進(jìn)行加工,使用重采樣層輸出特征提取結(jié)果,最終用提取到的協(xié)同表示整個(gè)KPCANet網(wǎng)絡(luò)最終的分類器。
圖1為本文提出的KPCANet整體結(jié)構(gòu),它由兩個(gè)KPCA階段和一個(gè)匯集階段組成,假設(shè)所有階段的補(bǔ)丁大小都是k1×k2,并且所有輸入圖像大小都是m×n。
1.1 KPCANet第一階段
輸入屬于C類的N個(gè)圖像[Ii(i=1,2,?,N)],并在圖像[Ii]的[j-th (j=1,2,?,mn)]像素中以一個(gè)補(bǔ)丁[Pi,j∈][Rk1*k2]為中心,將該貼片矢量化為[xi,j∈Rk1k2]。收集[Ii]的所有矢量化[xi,j(j=1,2,?,mn)],得到矩陣[Xi=[xi,1,xi,2,?,][xi,mn]∈Rk1k2×mn]。為所有輸入圖像構(gòu)造相同的矩陣并將它們放在一起,得到[X=[X1,X2,?,XN]∈Rk1k2×Nmn]。為方便起見(jiàn),X的第p列表示為[x'p(p=1,2,?,Nmn)],然后將輸入空間[Rk1k2*k1k2]的X映射到特征空間F:
為簡(jiǎn)化C對(duì)角化,可以替換為K對(duì)角化,其中[Kpq=][(T~(x'p)?T~(x'p))pq,T~(x'p)]表示集中[T(x'p)],符號(hào)“[?]”表示點(diǎn)積。由于F的維數(shù)是任意大甚至無(wú)窮大,所以直接計(jì)算點(diǎn)積[(T~(x'p)?T~(x'p))]很難。用核函數(shù)K代替點(diǎn)積,得到[Kpq=][(k(x'p,x'q))pq]。K集中[K=K-1NmnK-K1Nmn+1NmnK1Nmn,][K]對(duì)角化,得到主特征向量[WIll=1,2,?,L1],這是第一階段的KPCA濾波器,其中[(1Nmn)ij=1Nmn]。
零填充[Ii]的邊界并與[WIl]卷積,得到第一級(jí)[Ii]的l-th濾波器輸出,[Ii,l=Ii*WIl∈Rm×n(i=1,2,?,N;l=1,2,?,L1)],其中“*”表示2D卷積,L1表示第一階段中的濾波器數(shù)量。
1.2 KPCANet第二階段
通過(guò)重復(fù)與第一階段[Ii,l(i=1,2,?,N;l=1,2,?,L1)]相同的過(guò)程,得到第二階段的[L2]核PCA濾子[W2s(s=1,][2,?,L2)]。卷積[Ii.l]與[W2s],得到第二階段[Ii,l,s=Ii,l*W2s][(i=1,2,?,N;l=1,2,?,L1;s=1,2,?,L2)]的輸出。
1.3 KPCANet匯集階段
由于深度體系結(jié)構(gòu)是由多個(gè)非線性操作組成的,例如在復(fù)雜的命題公式中使用許多子公式[14],所以KPCANet的前兩個(gè)階段設(shè)置為相同,也可重新使用第一階段的整個(gè)結(jié)構(gòu)。
1.4 協(xié)同表示分類器
壓縮感知理論[15-16]和稀疏表示[17]在人臉識(shí)別技術(shù)提高過(guò)程中效果不錯(cuò),一般在稀疏性討論中都會(huì)默認(rèn)人臉數(shù)據(jù)庫(kù)中的每個(gè)訓(xùn)練樣本[Ai]均為過(guò)完備,但實(shí)際上人臉數(shù)據(jù)庫(kù)中的數(shù)據(jù)并不是過(guò)完備而是欠完備的。把人臉數(shù)據(jù)庫(kù)中其它類的人臉圖像都當(dāng)作測(cè)試樣本使用以解決樣本數(shù)據(jù)不足的問(wèn)題。因此,用所有的類的人臉圖像[A=[A1,A2,][?,Ak]]在一定的l1-范數(shù)約束條件下協(xié)同表示測(cè)試樣本y,協(xié)同性則會(huì)起到關(guān)鍵作用。
2 協(xié)同KPCANet模型
本文提出的基于協(xié)同的KPCANet模型,主要是在協(xié)同表示分類算法的基礎(chǔ)上引入KPCANet程序,用它提取人在靜止?fàn)顟B(tài)下的面部特征,并利用協(xié)同表示分類器進(jìn)行分類,從而獲得較高的識(shí)別準(zhǔn)確率。
算法流程如下:①將N幅圖片寫成一個(gè)m×n維矩陣[A=a11?a1n???am1?amn],進(jìn)行k1*k2的塊采樣:[xi,j∈Rk1k2(i=1,2,][?,N; j=1,2,?,mn)],對(duì)采樣得到的塊進(jìn)行零均值化,并且對(duì)訓(xùn)練集中其它圖片也做同樣操作,得到訓(xùn)練后的樣本矩陣[X=[X1,X2,?,XN]∈Rk1k2×Nmn];②選擇核函數(shù)并設(shè)置參數(shù),計(jì)算輸入的核矩陣Kl=ConstrucKernelMatrix(X),并將K1中心化得到KC1;③第一層的L1個(gè)濾波器核和第二層的L2個(gè)濾波器核分別對(duì)應(yīng)上一層輸出的矩陣相應(yīng)產(chǎn)出L1個(gè)和L2個(gè)輸出特征,從而每張輸出圖片都會(huì)在兩層KPCANet產(chǎn)生L1*L2個(gè)輸出矩陣[Oli={Ili*W2l}L2l=1];④KL的特征值可以用Jacobi迭代方法計(jì)算,[λ1,?,λn]及對(duì)應(yīng)特征向量[V1,?,Vn],將特征值按降序排列得到[λ1?λn],并對(duì)特征向量進(jìn)行相應(yīng)調(diào)整;⑤采用現(xiàn)有人臉庫(kù)中各個(gè)類別的人臉圖像元素[A=[A1,A2,?,Ak]]在一定的l1-范數(shù)條件下進(jìn)行協(xié)同表示測(cè)試樣本y,再將測(cè)試樣本分到有最小殘差的類中:[Identity(y)=argmin{ri(y)}]。
3 實(shí)驗(yàn)結(jié)果與分析
分別運(yùn)用ORL人臉庫(kù)和Extended Yale B人臉庫(kù)進(jìn)行人臉識(shí)別實(shí)驗(yàn)。將40組不同性別、年齡及種族的人臉圖片存儲(chǔ)在ORL人臉數(shù)據(jù)庫(kù)中。其中,每個(gè)人有10張不同表情的人臉圖片,總共有400張人臉圖片。每張圖片都是黑色背景,尺寸是92×112,圖中每個(gè)人的照片面部表情都有細(xì)微變化,有睜著眼睛的、閉著眼睛的、戴眼鏡的、戴帽子的,有沮喪的、開(kāi)心的等等。在這些照片中,每個(gè)人的面部表情都十分明顯,人臉大小也有所變化。圖2所示為其中3個(gè)人的面部表情。在實(shí)驗(yàn)過(guò)程中,用每個(gè)人的前5張人臉圖像作為訓(xùn)練使用,后5張圖像作為測(cè)試使用。Extended Yale B人臉庫(kù)一共39人,每人64張灰度照片,圖像尺寸168×192,共2 496張人臉圖片。在不同的機(jī)位上拍攝一個(gè)人64張同一表情圖片,每個(gè)subset的人臉數(shù)目分別為7張、12張、14張、19張。圖3是Extended Yale B人臉數(shù)據(jù)庫(kù)中同一個(gè)人在不同光照強(qiáng)度情況下的20張正面人臉圖像。實(shí)驗(yàn)過(guò)程中隨機(jī)抽取每個(gè)人的10張人臉圖片進(jìn)行訓(xùn)練,有390個(gè)可以訓(xùn)練的實(shí)驗(yàn)樣本,2 106個(gè)測(cè)試樣本,結(jié)果為10次試驗(yàn)之后得到的平均值。
3.1 不同核函數(shù)性能比較
每個(gè)核函數(shù)在不同圖片數(shù)據(jù)集中的識(shí)別率都會(huì)不一樣。選擇Polynomial、PolyPlus、Gaussian核函數(shù),設(shè)置相同的KPCANet網(wǎng)絡(luò)參數(shù),檢測(cè)它們能否準(zhǔn)確識(shí)別Extended Yale B人臉庫(kù)中的人臉。
經(jīng)實(shí)驗(yàn)驗(yàn)證,KPCANet在Extended Yale B人臉庫(kù)中采用3種不同的核函數(shù)識(shí)別錯(cuò)誤率如表1所示。從表1可以看出,在識(shí)別人臉圖像的KPCANet框架中, Polynomial、PolyPlus、Gaussian這3種核函數(shù)各具特點(diǎn)和優(yōu)勢(shì),比如,Gaussian核函數(shù)的識(shí)別錯(cuò)誤率在3個(gè)當(dāng)中是最低的。但是當(dāng)d=1時(shí),如果從空間和時(shí)間的復(fù)雜度考慮,Polynomial核函數(shù)的算法是最簡(jiǎn)單的。
3.2 ORL人臉庫(kù)識(shí)別錯(cuò)誤率比較
使用ORL人臉庫(kù)中的Polynomial核函數(shù),將核函數(shù)參數(shù)設(shè)置為d=1,將卷積層設(shè)置為1層,L1=8,使用SIFT特征提取算法和KNN聚類方法對(duì)人臉面部表情進(jìn)行分類。如果訓(xùn)練集圖片數(shù)分別為5、6、7、8,對(duì)這兩種框架在ORL人臉庫(kù)圖片的識(shí)別率進(jìn)行對(duì)比,得到數(shù)據(jù)如圖4所示。參與訓(xùn)練的每類圖片有8張,用來(lái)測(cè)試的圖片有2張,圖片分類錯(cuò)誤較小。所以,基于深度學(xué)習(xí)算法的協(xié)同KPCANet模型比BoW模型能更準(zhǔn)確地識(shí)別人臉。
3.3 Extended Yale B人臉庫(kù)的識(shí)別錯(cuò)誤率比較
在Extended Yale B人臉庫(kù)中,選擇Polynomial核函數(shù),將核函數(shù)參數(shù)設(shè)置為d=1,卷積層設(shè)置為1層,BOR=0.5,比較兩個(gè)深度學(xué)習(xí)網(wǎng)絡(luò)KPCANet_CRC和PCANet_CRC。當(dāng)L1分別為2、4、6、8、10時(shí),計(jì)算Extended Yale B人臉庫(kù)識(shí)別人臉面部表情的準(zhǔn)確程度。表2為L(zhǎng)1不同的一層卷積層的KPCANet_CRC與PCANet_CRC在Extended Yale B人臉庫(kù)中的識(shí)別錯(cuò)誤率。由表2可以看出,在Extended Yale B人臉庫(kù)數(shù)據(jù)集中,1層卷積層的KPCANet_CRC算法識(shí)別錯(cuò)誤率更低。
在Extended Yale B人臉庫(kù)中,選擇Polynomial核函數(shù),將核函數(shù)參數(shù)設(shè)置為d=1,卷積層數(shù)設(shè)置為2層,BOR=0.5,比較兩個(gè)深度學(xué)習(xí)網(wǎng)絡(luò)KPCANet_CRC和PCANet_CRC。當(dāng)L1=8,第二層濾波器個(gè)數(shù)分別為8、10、15、20時(shí),計(jì)算在Extended Yale B人臉庫(kù)中的人臉識(shí)別錯(cuò)誤個(gè)數(shù)變化情況。從表3可以看出,在L2=15時(shí),KPCANet_CRC在Extended Yale B人臉庫(kù)中的識(shí)別錯(cuò)誤率最低。在Extended Yale B人臉庫(kù)中,KPCANet_CRC的識(shí)別錯(cuò)誤率略低于PCANet_ CRC。表3為L(zhǎng)2=8、10、15、20時(shí),KPCANet_CRC與PCANet_CRC在Extended Yale B人臉庫(kù)中的識(shí)別錯(cuò)誤率。
4 結(jié)語(yǔ)
在KPCANet_CRC框架中,設(shè)置確定的卷積層數(shù)、濾波器個(gè)數(shù)和BOR參數(shù),特征的提取會(huì)簡(jiǎn)單、高效、魯棒性強(qiáng),在需要較快較準(zhǔn)確地采集人臉圖像及在各類復(fù)雜場(chǎng)景中識(shí)別人臉場(chǎng)合非常適用。被訓(xùn)練的圖片數(shù)量越多,使用深度學(xué)習(xí)算法識(shí)別的人臉圖像就越準(zhǔn)確,該方法比中層特征提取法更實(shí)用、更準(zhǔn)確。如在ORL人臉庫(kù)中,基于深度學(xué)習(xí)的協(xié)同KPCANet模型分類準(zhǔn)確率高于BoW模型。同樣,在Extended Yale B人臉庫(kù)中,KPCANet_CRC的識(shí)別準(zhǔn)確率略優(yōu)于PCANet_CRC。綜上所述,在人臉識(shí)別、人臉檢測(cè)等領(lǐng)域,深度學(xué)習(xí)有著良好的發(fā)展前景。
參考文獻(xiàn):
[1] 王振,高茂庭. 基于卷積神經(jīng)網(wǎng)絡(luò)的圖像識(shí)別算法設(shè)計(jì)與實(shí)現(xiàn)[J]. 現(xiàn)代計(jì)算機(jī):專業(yè)版,2015(20):61-67
[2] 戴金波. 基于視覺(jué)信息的圖像特征提取算法研究[D]. 長(zhǎng)春:吉林大學(xué),2013.
[3] LECUN Y,KAVUKCUOGLU K,F(xiàn)ARABET C. Convolutional networks and applications in vision[C]. Proceedings of 2010 IEEE International Symposium on Circuits and Systems. Paris, France, 2010: 253-256.
[4] LEE H,GROSSE R.Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations[C]. ?International Conference on Machine Learning,2009:609-616.
[5] CHRISTIAN S,TOSHEV A,ERHAN D. Deep neural networks for object detection[C]. Advances in Neural Information Processing Systems,2013:2553-2561.
[6] CHRISTIAN S,LIU W,JIA Y Q. Going deeper with convolutions[C]. IEEE Conference on Computer Vision and Pattern Recognition,2015:1-9.
[7] BRUNA J,MALLAT S. Invariant scattering convolution networks[J]. ?IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8):1872-1886.
[8] WU D,WU J S,ZENG R, et al. Kernel principal component analysis network for image classification[J]. Journal of Southeast University(English Edition),2015,31(4):469-473.
[9] CHAN T H,JIA K,GAO S H,et al. Pcanet:a simple deep learning baseline for image classification[J]. TIP,2015,24(12):5017-5032.
[10] BRUNA J,MALLAT S. Invariant scattering convolution networks[J]. TPAMI,2013,35(8):1872-1886
[11] SIFRE L,MALLAT S. Rotation,scaling and deformation invariant scattering for texture discrimination[J]. CVPR,2013,9(4):1233-1240.
[12] ALEX K. ImageNet classification with deep convolutional neural networks[J]. Advances in Neural Information Processing Systems,2012,25(2):195-203.
[13] ZHANG L,YANG M,F(xiàn)ENG X. Sparse representation or collaborative representation: which helps face recognition[C]. ICCV. Washington,D C: IEEE Computer Society,2011.
[14] BENGIO Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning,2009,2(1):1-127.
[15] 平強(qiáng). 壓縮感知人臉識(shí)別算法研究[D]. 合肥:中國(guó)科學(xué)技術(shù)大學(xué),2011.
[16] 戴瓊海,付長(zhǎng)軍,季向陽(yáng). 壓縮感知研究[J]. 計(jì)算機(jī)學(xué)報(bào),2011,34(3):425-434.
[17] 楊榮根,任明武,楊靜宇. 基于稀疏表示的人臉識(shí)別方法[J]. 計(jì)算機(jī)科學(xué),2010,37(9):266-269.
(責(zé)任編輯:杜能鋼)
猜你喜歡
作文中學(xué)版(2022年1期)2022-04-14 08:00:34
學(xué)生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年15期)2019-08-27 01:12:00
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
新教育時(shí)代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(huì)(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
計(jì)算機(jī)工程(2015年8期)2015-07-03 12:19:07
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
