基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法
2019-10-21 09:11:14安明慧沈忱林李壽山李逸薇
中文信息學(xué)報(bào) 2019年10期
安明慧,沈忱林,李壽山,李逸薇
(1. 蘇州大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,江蘇 蘇州 215006;2. 香港理工大學(xué) 人文學(xué)院中文及雙語(yǔ)系,香港 999077)
0 引言
隨著互聯(lián)網(wǎng)技術(shù)的飛速發(fā)展,網(wǎng)絡(luò)購(gòu)物成為了廣大消費(fèi)者的首選購(gòu)物方式,國(guó)內(nèi)電子商務(wù)平臺(tái)也隨之迎來(lái)了爆發(fā)式的增加。2018年“雙十一”期間天貓銷售額達(dá)到了2 135億元,京東銷售額達(dá)到了1 598億元,蘇寧的訂單量也同比增長(zhǎng)了132%。電商平臺(tái)的飛速發(fā)展使得平臺(tái)上的評(píng)價(jià)信息也隨之飛速增加。對(duì)電商平臺(tái)而言,如何有效利用這些評(píng)價(jià)信息[1],特別是問(wèn)答型評(píng)論,來(lái)進(jìn)行平臺(tái)輿情分析、商品質(zhì)量檢測(cè)和客服質(zhì)檢[2]等應(yīng)用的開發(fā),是維護(hù)平臺(tái)公平性和保證用戶購(gòu)物體驗(yàn)的重中之重。情感分析技術(shù)在這些領(lǐng)域中扮演著極其重要的角色。
目前,針對(duì)電商評(píng)論的情感分類方法大多為基于全監(jiān)督的機(jī)器學(xué)習(xí)方法,這類方法往往需要大規(guī)模的標(biāo)注語(yǔ)料[3]。然而面向問(wèn)答型評(píng)論的情感分類語(yǔ)料集十分匱乏,額外標(biāo)注大規(guī)模問(wèn)答型評(píng)論的成本又十分昂貴,基于此本文探索一種基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法。例1為問(wèn)答型評(píng)論實(shí)例,例2為普通評(píng)論實(shí)例,我們可以發(fā)現(xiàn)問(wèn)答型評(píng)論和普通評(píng)論具有十分相似的情感描述信息,因此,我們可以使用大量自然標(biāo)注普通評(píng)論通過(guò)聯(lián)合學(xué)習(xí)的方式,輔助提升問(wèn)答型情感分類任務(wù)的性能。
例1問(wèn)題:手機(jī)是不是很耗電啊?
答案:不會(huì)呀。
情感: 正面
例2評(píng)論:手機(jī)電池很持久,待機(jī)耗電很低,用兩天沒問(wèn)題,很不錯(cuò)。
情感: 正面

圖1 聯(lián)合學(xué)習(xí)示意圖
眾所周知,基于聯(lián)合學(xué)習(xí)的方法在自然語(yǔ)言處理領(lǐng)域表現(xiàn)得非常出色,聯(lián)合學(xué)習(xí)的模型框架如圖1所示,一般由主任務(wù)和輔助任務(wù)構(gòu)成,整個(gè)模型針對(duì)主任務(wù)的損失函數(shù)和輔助任務(wù)的損失函數(shù)同時(shí)進(jìn)行優(yōu)化。Chen等[4]通過(guò)對(duì)情緒分類任務(wù)和情緒原因識(shí)別任務(wù)進(jìn)行聯(lián)合學(xué)習(xí),有效結(jié)合了二者的情緒特征并大幅提升了這兩個(gè)任務(wù)的性能。Ma等[5]設(shè)計(jì)了一個(gè)基于神經(jīng)網(wǎng)絡(luò)的聯(lián)合學(xué)習(xí)模型,可以同時(shí)進(jìn)行屬性的預(yù)測(cè)和屬性級(jí)情感類別的預(yù)測(cè)。該聯(lián)合模型能有效結(jié)合預(yù)測(cè)的屬性標(biāo)簽信息來(lái)提升屬性級(jí)情感分類任務(wù)的性能。基于以上工作的啟發(fā),本文提出了一種基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法,通過(guò)大量易獲得的普通評(píng)論,輔助問(wèn)答情感分類任務(wù)。具體而言,我們先通過(guò)主任務(wù)模型單獨(dú)學(xué)習(xí)問(wèn)答型評(píng)論的情感信息,再使用問(wèn)答型評(píng)論和普通評(píng)論共同訓(xùn)練輔助任務(wù)模型以獲取問(wèn)答型評(píng)論的輔助情感信息,再通過(guò)聯(lián)合學(xué)習(xí)同步更新主任務(wù)模型和輔助任務(wù)模型參數(shù)。實(shí)驗(yàn)結(jié)果表明,本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法能較好地融合問(wèn)答型評(píng)論和普通評(píng)論的情感信息,在性能上明顯優(yōu)于其他基線方法。
1 相關(guān)工作
1.1 問(wèn)答情感分類
面向問(wèn)答型評(píng)論文本的情感分類是一項(xiàng)新穎且富有挑戰(zhàn)性的任務(wù),該任務(wù)由Shen等[6]首次提出,同時(shí)Shen等提出了一種基于層次匹配網(wǎng)絡(luò)的問(wèn)答情感分類方法,該方法通過(guò)切分句子并構(gòu)建句子級(jí)的二元組,再通過(guò)層次匹配機(jī)制能有效挖掘問(wèn)答型評(píng)論深層次的情感信息。
1.2 聯(lián)合學(xué)習(xí)
近年來(lái),聯(lián)合學(xué)習(xí)在自然語(yǔ)言處理領(lǐng)域的諸多任務(wù)上被證明是十分有效的。嚴(yán)倩等[7]通過(guò)聯(lián)合學(xué)習(xí)的方法利用豐富的英文事件語(yǔ)料庫(kù)來(lái)幫助中文事件抽取任務(wù),提高了跨語(yǔ)言事件識(shí)別的性能。邱盈盈等[8]通過(guò)聯(lián)合深度學(xué)習(xí)和主動(dòng)學(xué)習(xí)的事件抽取方法,在主動(dòng)學(xué)習(xí)過(guò)程中提高語(yǔ)料標(biāo)注效率從而提升了事件抽取的性能。Wang等[9]在用戶畫像識(shí)別任務(wù)中,通過(guò)聯(lián)合學(xué)習(xí)使得年齡預(yù)測(cè)、性別預(yù)測(cè)和職業(yè)預(yù)測(cè)3個(gè)任務(wù)的特征互相影響,從而提升了用戶畫像識(shí)別的性能。Li等[10]在事件抽取任務(wù)中,提出了一種基于結(jié)構(gòu)化感知機(jī)的聯(lián)合學(xué)習(xí)模型,通過(guò)同時(shí)抽取事件觸發(fā)詞和論元的方法提高了句子級(jí)別的事件抽取任務(wù)的性能。Tu等[11]在跨領(lǐng)域情感分類任務(wù)中,將完形填空任務(wù)網(wǎng)絡(luò)作為輔助任務(wù),卷積層次注意力網(wǎng)絡(luò)作為情感分類任務(wù)進(jìn)行聯(lián)合學(xué)習(xí),提高了跨領(lǐng)域情感分類的性能。Cong等[12]提出了一個(gè)基于層次網(wǎng)絡(luò)的聯(lián)合學(xué)習(xí)模型,可以同時(shí)進(jìn)行層面級(jí)的情感分類和單詞級(jí)別的觀點(diǎn)抽取,提高了觀點(diǎn)詞抽取任務(wù)的性能。
基于上述工作的啟發(fā),為了解決問(wèn)答型評(píng)論數(shù)據(jù)集匱乏的問(wèn)題,本文提出了一種基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法,通過(guò)大量易獲得的普通評(píng)論輔助提升問(wèn)答情感分類任務(wù)的性能。
2 方法
本節(jié)詳細(xì)介紹本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法,整體框架如圖2所示。該方法由主任務(wù)和輔助任務(wù)構(gòu)成,主任務(wù)模型為基于雙向門控注意力機(jī)制的神經(jīng)網(wǎng)絡(luò),輔助任務(wù)模型為基于雙向LSTM和注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)。

圖2 基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法框架圖
2.1 主任務(wù)
主任務(wù)模型由基于雙向門控注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)構(gòu)成, 它用來(lái)挖掘問(wèn)答型評(píng)論的深層次情感匹配信息,其模型結(jié)構(gòu)如圖3所示。

為了更好地捕捉問(wèn)題文本和答案文本之間的情感匹配信息,我們提出了一種雙向門控制注意力機(jī)制,這是傳統(tǒng)注意力機(jī)制的一種變體,能夠很好地捕捉問(wèn)題文本和答案文本中詞語(yǔ)之間的情感匹配關(guān)系,該方法包含問(wèn)題—答案門控注意力機(jī)制以及答案—問(wèn)題門控注意力機(jī)制,具體如下:


圖3 基于雙向門控注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)示意圖
其中,ct是注意力機(jī)制學(xué)習(xí)到的問(wèn)題文本的表示。然后,我們通過(guò)門控機(jī)制學(xué)習(xí)答案文本的語(yǔ)義序列表示,如式(6)~式(8)所示。

最后,我們通過(guò)一層LSTM來(lái)獲取答案文本的最終表示向量,如式(9)、式(10)所示。

(9)
hA=LSTM(VA)
(10)
其中,hA為答案文本最終的表示向量。
答案—問(wèn)題門控注意力機(jī)制: 同樣地,我們可以通過(guò)注意力機(jī)制獲得由答案信息增強(qiáng)后的問(wèn)題文本表示,如式(11)~式(13)所示。
其中,ct是注意力機(jī)制學(xué)習(xí)到的答案文本表示。其次,我們通過(guò)門控機(jī)制學(xué)習(xí)問(wèn)題文本的語(yǔ)義序列表示,如式(14)~式(16)所示。

最后,我們通過(guò)一層LSTM獲取問(wèn)題文本的最終表示向量,如式(17)、式(18)所示。
其中,hQ為問(wèn)題文本的情感表示向量。
最終,我們通過(guò)向量拼接的方式得到問(wèn)答型評(píng)論的語(yǔ)義表示向量hmain,如式(19)所示。
2.2 輔助任務(wù)
輔助任務(wù)模型由共享的雙向LSTM和注意力機(jī)制構(gòu)成,該模型由問(wèn)答型評(píng)論和普通評(píng)論共同訓(xùn)練獲得。其模型結(jié)構(gòu)如圖4所示。為了簡(jiǎn)便起見,我們同時(shí)將問(wèn)答型評(píng)論中問(wèn)題文本和答案文本進(jìn)行拼接,類似于看成一條普通評(píng)論來(lái)處理。

圖4 基于雙向門控制注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)示意圖
其中,ut為詞語(yǔ)et的隱藏層輸出。然后,我們通過(guò)注意力機(jī)制獲取輔助模型最終的向量表示,如式(21)~式(24)所示。
其中,α為注意力權(quán)重,Wc和bc為權(quán)重矩陣和偏置。h為輔助模型的最終輸出的向量表示,我們還規(guī)定haux為問(wèn)答型評(píng)論學(xué)習(xí)到的向量表示,hr為普通評(píng)論學(xué)習(xí)到的向量表示。
2.3 聯(lián)合學(xué)習(xí)
最后,我們通過(guò)聯(lián)合學(xué)習(xí)同時(shí)學(xué)習(xí)和更新主任務(wù)模型和輔助任務(wù)模型的參數(shù)。分類包含主任務(wù)模型分類和輔助任務(wù)模型分類。
主任務(wù)分類: 問(wèn)答型評(píng)論文本的表示最終由兩部分組成,一部分是由主任務(wù)學(xué)習(xí)到的語(yǔ)義表示向量hmain,另一部分為輔助任務(wù)學(xué)習(xí)到的向量表示haux,我們將兩個(gè)向量進(jìn)行拼接,得到問(wèn)答型評(píng)論的最終向量表示hqa,如式(25)所示。
其中,⊕表示向量的拼接操作。
面向問(wèn)答型評(píng)論文本的情感分類任務(wù)共包含四種情感類別,因此,我們通過(guò)softmax層獲得最終的類別表示,如式(26)所示。
其中,pqa為問(wèn)答型評(píng)論的情感類別輸出概率。Wqa和bqa為softmax層的權(quán)重和偏置。
主任務(wù)模型的目標(biāo)函數(shù)為交叉熵?fù)p失函數(shù),定義如式(27)所示。

輔助任務(wù)分類: 面向普通評(píng)論的情感分類任務(wù)共包含兩種情感類別。因此,我們通過(guò)sigmoid層獲得最終的類別表示,如式(28)所示。
其中,pr為普通評(píng)論的類別輸出概率。
輔助任務(wù)模型的目標(biāo)函數(shù)同樣為交叉熵?fù)p失函數(shù),如式(29)所示。
聯(lián)合學(xué)習(xí): 整個(gè)模型通過(guò)聯(lián)合學(xué)習(xí)同時(shí)更新參數(shù)。因此,整個(gè)模型的目標(biāo)函數(shù),如式(30)所示。
3 實(shí)驗(yàn)設(shè)計(jì)與分析
本節(jié)系統(tǒng)評(píng)估本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法的性能,同時(shí)對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行分析。
3.1 實(shí)驗(yàn)設(shè)置
數(shù)據(jù)設(shè)置: 實(shí)驗(yàn)數(shù)據(jù)來(lái)自Shen等[6]公開的問(wèn)答型評(píng)論語(yǔ)料(1)https://github.com/clshenNLP/QASC/,該語(yǔ)料包含美妝,鞋類和數(shù)碼3個(gè)領(lǐng)域,具體類別分布如表1所示。在本實(shí)驗(yàn)中,我們將每個(gè)領(lǐng)域隨機(jī)分為訓(xùn)練集(每個(gè)類別的70%樣本)、驗(yàn)證集(每個(gè)類別的10%樣本)以及測(cè)試集(每個(gè)類別的20%樣本)。另外,本實(shí)驗(yàn)所使用的普通評(píng)論從淘寶(2)http://www.taobao.com/爬取,每條評(píng)論自帶用戶的打分(打分范圍為1—5分)。我們將大于3分的認(rèn)為是包含正面情感的評(píng)論,評(píng)分低于3分的認(rèn)為是包含負(fù)面情感的評(píng)論。通過(guò)這種方式在美妝、鞋類和數(shù)碼3個(gè)領(lǐng)域中,每個(gè)領(lǐng)域選擇5 000條包含正面情感的評(píng)論以及5 000條包含負(fù)面負(fù)面情感的評(píng)論。

表1 問(wèn)答情感分類語(yǔ)料集的類別分布
分詞和詞向量: 我們采用FudanNLP(3)https://github.com/FudanNLP/fnlp/進(jìn)行中文分詞。通過(guò)word2vec(4)https://code.google.com/archive/p/word2vec/訓(xùn)練詞向量,詞向量維度設(shè)置為100。
參數(shù)設(shè)置: 在本實(shí)驗(yàn)中,所有的未登錄詞(out-of-vocabulary, OOV)均通過(guò)均勻分布U(-0.01,0.01)進(jìn)行初始化。LSTM神經(jīng)網(wǎng)絡(luò)的一些重要參數(shù)如表2所示。模型的優(yōu)化函數(shù)為Adam[14],為了防止神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練過(guò)程中過(guò)擬合的現(xiàn)象,模型均采用了Dropout機(jī)制[15]。其余的參數(shù)通過(guò)驗(yàn)證集調(diào)試確定。
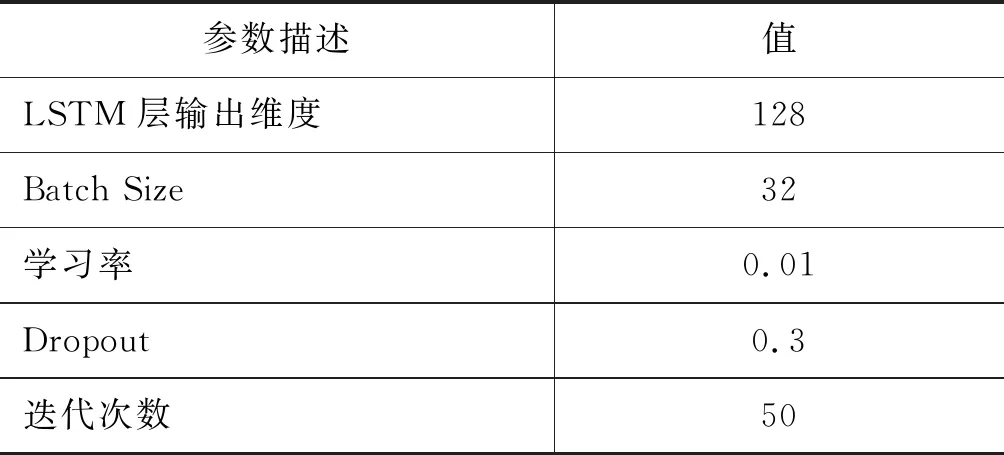
表2 LSTM神經(jīng)網(wǎng)絡(luò)的參數(shù)設(shè)置

表3 各方法在所有領(lǐng)域的性能結(jié)果

表4 我們的方法與其他方法在所有領(lǐng)域上的性能結(jié)果

續(xù)表
評(píng)價(jià)準(zhǔn)則: 本文采用正確率(Accuracy)和Macro-F1值作為衡量情感分類性能的指標(biāo),與Shen等[6]論文中保持一致。
3.2 實(shí)驗(yàn)結(jié)果
為了驗(yàn)證基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法的有效性,我們實(shí)現(xiàn)了以下幾種情感分類方法與之進(jìn)行比較,具體如下:
LSTM: 將問(wèn)題文本和答案文本拼接作為一個(gè)序列,使用詞向量作為特征,LSTM[16]作為分類器。
Bi-LSTM: 將問(wèn)題文本和答案文本拼接作為一個(gè)序列,使用詞向量作為特征,雙向LSTM[17]作為分類器。
Bi-LSTM-ATT: 本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法中的輔助任務(wù)模型,由雙向LSTM和注意力機(jī)制構(gòu)成。
Uni-Gated Q: 本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法中的主任務(wù)模型,由單向門控注意力機(jī)制構(gòu)成,即答案—問(wèn)題門控注意力機(jī)制。
Uni-Gated A: 本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法中的主任務(wù)模型,由單向門控注意力機(jī)制構(gòu)成,即問(wèn)題—答案門控注意力機(jī)制。
Bi-Gated: 本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法中的主任務(wù)模型,由雙向門控注意力機(jī)制構(gòu)成。
Joint Model: 本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法,由主任務(wù)模型和輔助任務(wù)模型聯(lián)合構(gòu)成。
表3為各方法在所有三個(gè)領(lǐng)域上的實(shí)驗(yàn)結(jié)果。從中我們可以發(fā)現(xiàn),基于雙向LSTM和注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)方法(Bi-LSTM-ATT)相較于LSTM和Bi-LSTM有一定的提升。這表明加入注意力機(jī)制后,能更好獲得問(wèn)答文本中的特定詞和句子的重要程度,以便于更好地挖掘問(wèn)答型評(píng)論的情感信息。
其次,基于雙向門控注意力機(jī)制的方法(Bi-Gated),在性能上明顯優(yōu)于基于單向門控注意力機(jī)制的方法(Uni-Gated A、Uni-Gated Q)。這表明在問(wèn)答型評(píng)論中,問(wèn)題文本和答案文本均包含了重要的情感信息。
最后,本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法(Joint Model)在性能上表現(xiàn)最強(qiáng)勢(shì)。在3個(gè)領(lǐng)域上,都取得了最好的分類性能。與Bi-Gated方法相比,在美妝、鞋類和數(shù)碼3個(gè)領(lǐng)域數(shù)據(jù)集上準(zhǔn)確率分別提升了4.2%、2.8%和3.6%,Macro-F1值分別提升了6.7%、5.7%和4.3%。這表明該方法不僅能有效地挖掘問(wèn)答型評(píng)論的情感信息,同時(shí)也能較好地融合問(wèn)答型評(píng)論和普通評(píng)論的情感表述信息。
為了更全面地說(shuō)明本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法的性能,我們將與其他方法作更深層次的比較:
CNN-Tensor: 本方法由Lei等[18]提出,在句子級(jí)情感分類任務(wù)上達(dá)到了目前最好的性能。
ATT-LSTM: 本方法由Wang等[13]提出,在屬性級(jí)情感分類任務(wù)上達(dá)到了目前最好的性能。在本實(shí)驗(yàn)中,我們忽略了屬性信息,直接通過(guò)LSTM的隱藏層輸出得到注意力權(quán)重。
BiMPM: 本方法由Wang等[19]提出,在問(wèn)答匹配任務(wù)上達(dá)到了目前最好的性能。在本實(shí)驗(yàn)中,我們將最后得到的問(wèn)答匹配向量直接通過(guò)softmax分類器進(jìn)行情感分類。
HMN: 基于層次匹配網(wǎng)絡(luò)的問(wèn)答情感分類方法本方法由Shen等[6]提出,在問(wèn)答情感分類任務(wù)上取得了目前為止的最佳性能。
Joint Model: 本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法,由主任務(wù)模型和輔助任務(wù)模型聯(lián)合構(gòu)成。
表4展示了各方法在所有領(lǐng)域上的性能結(jié)果。與處理傳統(tǒng)情感分類任務(wù)的方法相比,我們的方法Joint Model相較于CNN-Tensor和LSTM-ATT有極大的優(yōu)勢(shì),充分證明了我們的方法不僅能有效挖掘問(wèn)答型評(píng)論的情感信息,還能很好地結(jié)合普通評(píng)論中的情感表述信息。
其次,將問(wèn)題和答案看作兩個(gè)平行的單元采用雙向注意力機(jī)制的方法(BiMPM)相比于將問(wèn)題和答案進(jìn)行簡(jiǎn)單拼接的單序列輸入的方法(CNN-Tensor和ATT-LSTM),取得了更好的分類性能。這說(shuō)明將問(wèn)答文本看作兩個(gè)平行單元進(jìn)行建模的合理性。
最后,與問(wèn)答匹配方法 BiMPM、Bi-ATT以及HMN相比,本文提出的方法在性能上有極大的提升。與基線方法中表現(xiàn)最好的方法HMN相比,我們的方法在美妝、鞋類和數(shù)碼3個(gè)領(lǐng)域中正確率分別提升了2.6%、1.3%和 2.2%,F(xiàn)值提升了2.1%、1.8%和2.8%,這充分證明本方法能有效地捕捉問(wèn)題文本和答案文本之間的語(yǔ)義情感信息,更好地提升問(wèn)答情感的分類性能。
4 結(jié)語(yǔ)
本文針對(duì)問(wèn)答情感分類語(yǔ)料集匱乏的問(wèn)題,提出了一種基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法。通過(guò)大量易獲得的普通評(píng)論輔助問(wèn)答情感分類任務(wù),將問(wèn)答情感分類作為主任務(wù),將普通評(píng)論情感分類作為輔助任務(wù)。首先,通過(guò)主任務(wù)模型單獨(dú)學(xué)習(xí)問(wèn)答型評(píng)論的情感信息;其次,使用問(wèn)答型評(píng)論和普通評(píng)論共同訓(xùn)練輔助任務(wù)模型,以獲取問(wèn)答型評(píng)論的輔助情感信息;最后,通過(guò)聯(lián)合學(xué)習(xí)同時(shí)學(xué)習(xí)和更新主任務(wù)模型和輔助任務(wù)模型的參數(shù)。實(shí)驗(yàn)結(jié)果表明,本文提出的基于聯(lián)合學(xué)習(xí)的問(wèn)答情感分類方法能較好地融合問(wèn)答型評(píng)論和普通評(píng)論的情感信息,大幅提升問(wèn)答情感分類任務(wù)的性能。
在未來(lái)的工作中,我們將考慮探索其他半監(jiān)督機(jī)器學(xué)習(xí)方法和強(qiáng)化學(xué)習(xí)方法,通過(guò)選擇未標(biāo)注的問(wèn)答型評(píng)論文本來(lái)進(jìn)一步提升問(wèn)答情感分類的性能。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中國(guó)生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽(yáng)畫報(bào)(2019年10期)2019-11-04 02:57:59
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國(guó)生殖健康(2018年5期)2018-11-06 07:15:40
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
