基于ATT-IndRNN-CNN的維吾爾語名詞指代消解
2019-10-21 02:01:50祁青山田生偉艾山吾買爾
中文信息學報 2019年9期
祁青山,田生偉,禹 龍,艾山·吾買爾
(1. 新疆大學 軟件學院,新疆 烏魯木齊 830091;2. 新疆大學 信息科學與工程學院,新疆 烏魯木齊 830046)
0 引言
指代(anaphora)是在自然語言中常見的一種語言現象,在篇章中通常利用一個抽象的詞語代替前面的某個具體的詞語。語言學中將抽象的語言單位稱為照應語(anaphor),而具體的實體稱為先行語(antecedent)。確定某個照應語的先行語的過程稱為指代消解[1]。指代消解對于自然語言處理(natural language processing,NLP)研究中的機器翻譯(machine translation)、信息抽取(information extraction)、自動文摘(automatic abstracting)以及自動問答(question answering)等自然語言應用系統都具有非常重要的支撐作用[2]。指代消解分為指代(anaphora)和共指(coreference),回指也稱為指示性指代,是當前的詞語與上文中出現的具體的詞語具有密切聯系;共指也稱為同指,是兩個具體的詞語對應于現實世界中共同參照物的指代[3]。
指代消解發展的幾十年來,已經從基本的基于規則的研究方法逐漸過渡到機器學習的研究方法中。McCarthy[4]等首先提出將指代消解改成二分類問題,在候選先行語中判斷與照應語是否具有緊密的聯系,進而判斷是否具有指代關系。Soon[5]等在此基礎上提出使用機器學習進行指代消解的研究框架并給出了可用的系統。他們在語料中提取12種特征作為分類的標準,再利用支持向量機對其進行訓練得到分類模型。這一思想影響了后期大多數學者的研究。Ng[6]等在Soon的基礎上將特征擴充成53種;Yang[7]等提出了一種雙候選模型,可以更好地確定照應語對應的先行語;Kong[8]等把中心理論應用到語義層,提高了指代消解的性能。在中文指代消解中,郭志立[9]提出了利用人稱代詞本身的語義信息等進行人稱代詞先行語的分析;馬彥華[10]等采用了一種 “主題人物法”的方法來解決中文的人稱代詞消解問題;許敏[11]等利用上下文中的語義信息進行指代分類;王厚峰[12-14]等對漢語的指代消解有較多的研究。但是對于像維吾爾語這種小語種的研究較少,主要有李冬白[15]等提出了一種基于DBN深度神經網絡學習模型的方法對維吾爾語的人稱代詞進行消解;李敏[16]等提出了一種基于棧式自編碼深度學習的維吾爾語名詞消解方法。
隨著研究不斷深入,研究者們發現對于特征給予不同的關注程度可以更好地進行分類,并且在篇章中上下文信息對于指代消解也具有極其重要的作用。此外,目前的研究大多都集中于中文和英文,針對維吾爾語這種語料資源匱乏的小語種的研究非常少,并且將深度學習用到維吾爾語的名詞指代消解中的研究也很少。基于上述問題,本文提出一種基于注意力機制、獨立循環神經網絡和卷積神經網絡相組合的方法,用于維吾爾語的名詞指代消解。在該方法中先利用注意力機制作為模型特征的選擇組件計算特征的權重,使得特征與消解結果的聯系更加緊密。再利用獨立循環網絡和卷積神經網絡分別得到全局特征和局部特征,并將這兩種特征進行融合,在得到上下文信息的同時又不丟失局部信息,可以得到更好的分類結果,提升維吾爾語名詞指代消解的性能。
1 相關知識
1.1 指代消解
指代消解是自然語言中的一個語言單位用于確定其指向之前出現的語言單位的過程。其中用于指向的語言單位,稱為照應語(anaphors),被指向的語言單位稱為先行語(antecedent)。根據消息理解會議(Message Understanding Conference,MUC)對指代的定義,認為指代關系不僅僅存在于代詞與名詞(名詞短語)之間,還存在于名詞(名詞短語)與名詞(名詞短語)之間。例如,
例1

(最終有一天,我收到了母親一封奇怪的信,這封信是寄給姐姐阿依努爾的。為了讀母親給她寫的這一封完整的信,就需要我必須跟姐姐見一次面)

1.2 維吾爾語的特點
維吾爾語是一種帶格語法的黏著性語言,詞組與句子之間有嚴格的詞序,并且擁有“格”結構。這種“格”結構對于指代消解工作起到非常重要的作用,利用維吾爾語的格語法可以判斷詞語的詞性等重要內容。在維吾爾語中一般認為有6種格,具體如表1所示。

表1 維吾爾語的格

續表
維吾爾語中的名詞存在單復數變化,可以將名詞單復數作為一個非常重要的特征,判斷是否具有指代關系,排除不存在指代關系的樣本,這也為維吾爾語名詞的指代消解提供了較好的基礎。
2 模型介紹
針對維吾爾語名詞指代消解問題,本文利用Soon[5]等提出的框架,首先確定照應語的候選先行語,提取名詞短語的特征,再引入注意力機制(attention)賦予特征權重,將得到的帶權特征分別輸入到獨立循環神經網絡(IndRNN)模型和卷積神經網絡,得到包含上下文信息的全局特征和局部特征,最后將得到的全局特征和局部特征進行融合,放入Softmax中訓練分類,模型如圖1所示。

圖1 維吾爾語名詞短語消解框架
2.1 特征提取
在自然語言處理中特征提取是一項非常重要的工作,提取的特征是否具有代表性和通用性直接決定了最后實驗結果的好壞。而特征提取在指代消解中起到的作用更大,因此本文結合實驗組維吾爾語言學專家總結的具有指稱性的名詞短語以及前人的經驗選取以下特征進行指代消解。
2.1.1 規則特征
規則特征是根據語言內部結構規則進行提取的特征,主要體現先行語和照應語在文章內部的關系,本文主要提取了17種規則特征,具體如表2所示。

表2 規則特征

續表
2.1.2 語義特征
在指代消解工作中,提取規則特征雖然可以進行消解工作,但是缺少對整個句子語義的考慮。因此本文采用詞向量的方式將先行語和照應語在句中深層次的語義特征表現出來。為了避免維度災難,本文采取了Mikolov等[17]在2013年提出的Word2Vec工具進行詞向量的訓練。同時為了準確得到詞語在多維空間中的語義分布情況,對原有語料進行了擴充。利用爬蟲從人民網和天山網等網站的維吾爾語板塊爬取維吾爾語文本,并進行簡單降噪處理,得到8 000篇未標注的生語料文本,經過分詞處理后得到1 003 267個分詞數據,與實驗語料進行結合,訓練照應語和先行語的語義特征。
2.2 訓練和測試樣本構成
本文將語料文本進行預處理,再經過維吾爾語言學專家對語料庫進行詞性和相應的指代鏈標注。通過對進行標注的照應語在句子中出現的位置提取上下文的名詞構成候選先行語集合,再將其遍歷,判斷是否是該照應語的先行語,若是則形成正例樣本,否則形成負例樣本。具體算法為:
Step1提取單個文本中所有的名詞短語,根據標注判斷是否為照應語,若是,則存入集合{anaphors},否則存入集合{nouns}中。
Step2遍歷集合{anaphors},將每一個照應語anaphor與集合{nouns}中每個元素noun進行對比,若兩個元素屬于同一指代鏈,則將標簽標記為1,作為正例;否則將標簽標記為0,作為負例。同時根據2.1.1節中表2中所提到的特征,讀取文本中這兩個元素的信息,進行對比,構成樣本。
Step3重復step1、step2,直到將所有的語料遍歷一遍。
通過上述算法得到全部樣本,并且將其中的80%作為訓練數據集,20%作為測試數據集。
2.3 ATT-IndRNN-CNN
ATT-IndRNN-CNN模型結合注意力機制與兩種不同的神經網絡,可以有效地將全局特征與局部特征進行組合,該模型對數據處理主要分為3個階段: 首先利用注意力機制強化特征,然后將處理后的特征分別輸入IndRNN和CNN得到全局特征和局部特征,最后將全局特征和局部特征進行融合,形成新的特征,輸入Softmax進行分類訓練。模型總框架如圖2所示。
2.3.1 注意力機制(ATT)
注意力機制最早是在圖像處理中的被提出來的,Mnih[18]等將之用于圖像分類的同時Bahdanau[19]也將其用到了機器翻譯之中。本文中利用注意力機制主要是將不同的特征賦予不同的權重,以便更好地進行模型的訓練。在注意力機制中將輸入特征Data看做由
其中,La為Data的長度,aj為valuej對應的權重系數,aj求解方式如式(2)所示。
利用Softmax對Q和各個Key之間相似度數值進行歸一化,同時也利用Softmax內在的機制突出重要成分的權重,而Q和各個Key之間相似度計算通常通過計算兩者之間的點積來得到,如式(3)所示。

圖2 ATT-IndRNN-CNN模型
通過上面一系列的計算可以得到特定元素Q的Attention數值。將得到特征經過注意力機制可以突出其中某些特征權重信息,進而可以更加有效地進行分析。
2.3.2 獨立循環神經網絡(IndRNN)
獨立循環神經網絡是由Li等人提出的一種新型循環神經網絡[20],這種新型循環神經網絡可以有效地解決普通RNN在訓練收斂時存在的梯度爆炸和梯度消失的問題,同時可以處理更長的序列。其基本計算如式(4)所示。
其中,σ為神經元的逐元素激活函數,u為一個循環權重向量,W為當前權重,b為神經元偏差,⊙表示u與ht-1的阿達馬積。基本結構圖如圖3所示。

圖3 IndRNN結構
IndRNN中每層的神經元是相互獨立的,但是可以將IndRNN進行多層疊加,并且層與層之間的神經元進行連接。對于隱含層第n個神經元的hn,t可以通過式(5)進行計算。
其中,μn表示第n行的循環輸入權重,而wn表示第n行的當前輸入權重,bn為第n行的神經元偏差。由式(5)可以看出,每個神經元僅接收當前狀態隱藏層和輸入其中的信息,各個神經元之間都是相互獨立的時空特征,這就使得IndRNN可以方便地進行組合。本文將經過ATT處理的特征輸入到兩層的IndRNN中,每層IndRNN包含64個隱含單元,得到包含上下文信息的全局特征。
2.3.3 卷積神經網絡(CNN)
CNN是一種前饋神經網絡,前期主要應用在圖形處理中,可以避免前期復雜的圖像處理。近年來研究者們將CNN引入自然語言處理可以有效緩解特征工程中的工作量,并且可以得到局部特征。CNN如圖4所示,主要包括輸入層、卷積層、池化層。

圖 4 卷積神經網絡
輸入層為ATT的輸出特征,經過卷積層利用卷積核對局特征進行卷積處理得到局部更具代表性的特征。基本計算如式(6)所示。
其中,x為卷積核窗口詞向量矩陣,W為權重矩陣,b為偏置,f為激活函數。池化層是卷積神經網絡的重要網絡層,該層可以對卷積層得到的特征向量進行采樣,進一步調整卷積層的輸出。池化函數利用某一位置的相鄰輸出的總體統計特征來代替網絡在該位置的輸出。當我們重點關注某個特征是否出現而不是出現的具體位置時就要利用到局部平移不變性,而池化就實現了這一點。一般的池化函數有最大池化函數和平均池化函數之分,本文使用最大池化函數。
2.3.4 特征融合
這一階段將2.3.2和2.3.3得到的特征進行融合,本文使用張量相乘的方法對兩種特征進行連接,對于兩個特征V和U其張量乘積V?U計算定義如式(7)所示。
其中,n和m分別為V和U的協變張量。利用張量積可以將兩個張量融合,并且張量積繼承了其因子的所有指標,不丟失原本張量的信息。
3 實驗和分析
3.1 語料準備
基于機器學習的指代消解的方法是需要相應的語料支撐的,目前進行的英文的指代消解的語料常用消息理解會議(Message Understanding Conference,MUC),中文指代消解采用的語料大多數是自動內容抽取會議(Automatic Content Extaction,ACE)或者OntoNotes的語料,但是目前關于維吾爾語的已標注的語料尚未見公開報道,因此需要針對維吾爾語名詞指代消解對維吾爾語語料進行篩選和標注。
本文利用網絡爬蟲從人民網和天山網等網站的維吾爾語板塊爬取的文章中篩選出存在指代鏈信息,在維吾爾語專家的指導下對其進行標注,包括標注指代鏈信息、名詞短語、語義類別、名詞單復數、格語法等特征,對標注后的語料利用Excel文件進行存儲。
本實驗中共標注了370篇文章,其中包含19 553條實體名詞,9 725條動詞和3 239條代詞,標注的語法結構包括6 172條主語,8 232條謂語,6 518條賓語,6 984條定語和10 335條狀語。語料中共有17 046條詞語包含語義類別,13 265條詞語擁有格屬性。利用2.2節中提出的方法形成訓練和測試數據集共75 084組數據,其中包括具有指代關系的20 266組正例和不具有指代關系的54 818組負例。
3.2 實驗結果與分析
為了方便實驗結果的對比,本文采用自然語言處理經常采用的3種測評標準: 準確率P、召回率R和F值,對實驗進行測評。其中P可以反映模型的準確率,R可以反映模型查全率,F值可以很好地綜合考慮P和R進而反映模型的綜合性能,F值的計算如式 (8)所示。
同時,為了實驗結果的穩定性和代表性,本實驗采用5折交叉驗證,取平均值作為最終實驗結果。每次實驗均利用GPU GTX 1050提高運行速率,進而減少運行時間。本文對不同的參數組合進行了反復實驗,確定實驗中各個模型的最優參數。后續實驗均采用最優參數進行實驗。最優參數如表3所示。

表3 參數設置
其中,ε表示訓練過程中的學習率,batch表示每次迭代時批量處理的個數,act表示模型的激活函數,filters表示CNN中卷積核的數目,filter-size表示CNN中卷積核的大小,dropout表示在訓練過程中的丟碼率,epochs表示迭代的次數。迭代次數對實驗結果的影響如圖5所示。
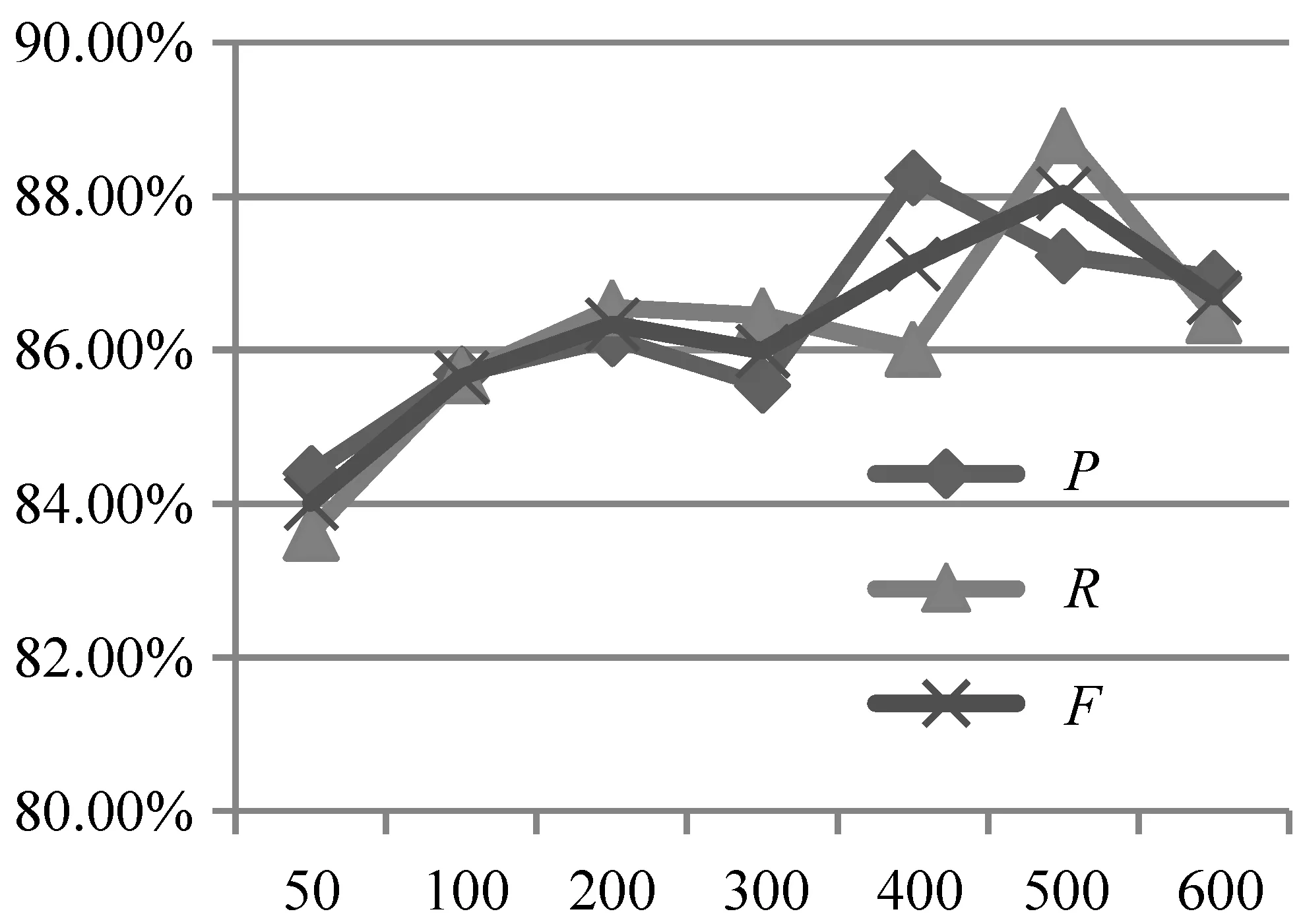
圖5 迭代次數對實驗結果的影響
3.2.1 ATT-IndRNN-CNN模型的有效性
在維吾爾語名詞指代消解上,為了驗證本文提出的模型的有效性,在特征相同的情況下,對不同的神經網絡進行了對比實驗,為了使得實驗更具有說服性,各個網絡均在自己的最優參數下進行實驗,實驗結果如表4所示。

表4 模型對比
表4表明在單獨的神經網絡中加入注意力機制時,ATT-CNN比CNN的F值提高了1.09%,ATT-IndRNN比單獨IndRNN的F值提高了4.89%。這說明當在模型中加入注意力機制時,可以使模型的性能在一定程度上有所提高。當使用本文提出的ATT-IndRNN-CNN聯合模型方法時,準確率P、召回率R和F值較之單一模型或者加入注意力機制的單一模型均有提高,充分說明了本文方法的有效性。
3.2.2 語義特征對指代消解的影響
2.1.1節的規則特征僅考慮了先行語和照應語之間的關系,對兩者在句子中的語義內容考慮得較少,因此本節針對基于詞向量模式的語義特征對指代消解的影響進行了對比實驗,實驗在原有規則特征的基礎上引入100維的詞向量語義特征,分別對不同的模型進行對比實驗,并且對實驗耗時進行了記錄。實驗結果如圖6 所示,耗時結果如表5所示(表5中CNN+W表示在原有規則特征基礎上添加語義特征,其他類似)。

表5 模型耗時對比

續表

圖6 語義特征對比
由圖6可以看出,在加入語義特征后所有模型的準確率P、召回率R和F值均有顯著提高,實驗結果充分說明了加入語義特征向量的有效性,這是因為規則特征僅包含先行語和照應語之間的結構特點,缺乏對整個句子中語義信息的考慮,而加入詞向量融合特征后可以對先行語和照應語在句子中的語義信息進行建模,進而提高指代消解的準確性。
由表5可以看出,在增加語義特征時,模型耗時有少量的增加,說明加入語義特征后對于模型耗時影響較小。但將模型進行融合后耗時明顯變長,表明運行時間受模型影響較大。
3.2.3 詞向量維度對指代消解的影響
在融合語義特征時,訓練的詞向量維度的大小也會影響實驗結果,理論上向量的維度越高,包含的語義信息也就會越豐富,因此本文分別采用10維、30維、60維、100維和150維的詞向量進行了對比實驗,實驗結果如表6所示。
由表6可以明顯地看出,在詞向量維度達到100時,準確率P、召回率R和F值都達到最優,而當維度為150時, 性能有所下降。這是因為當維度越高時,包含的信息越多,就越有可能產生過擬合的現象,從而導致模型對數據的泛化能力降低。

表6 詞向量維度對比
3.2.4 規則特征對實驗的影響
為了證明本文提取的人工特征對實驗的影響,本文進行了以下的對比實驗。為了使一個規則特征可以得到有效訓練,因此加入10維的詞語向量,逐漸增加人工特征數目,其他設置按照3.2節中表3的最優設置。采用本文提出的模型進行實驗得到準確率P、召回率R和F值如表7所示。

表7 規則特征對結果的影響
由表7可以看出,在不斷增加規則特征的情況下,準確率和召回率雖有些上下波動,但F值在不斷地提升,說明本文提出的規則特征可以提高指代消解實驗的性能。
3.2.5 IndRNN層數對實驗結果的影響
在本實驗中用以提取全局特征的IndRNN采用的是兩層結構,理論上堆疊的層數越多,就可以得到更深層次、更加抽象的語義信息。因此本文驗證IndRNN層數對實驗結果的影響,實驗結果如表8所示。

表8 IndRNN層數對結果的影響
由表8可以看出,隨著層數的增加,準確率、召回率和F值都是先增加再減小,并且在層數為2的時候準確率和F值達到最大,而召回率在層數為3時達到最大。所以本文將IndRNN的層數設置為2,以便取得更好的效果。
4 總結
本文提出一種基于注意力機制的混合模型的維吾爾語名詞指代消解方法,通過引入注意力機制將特征內在的權重計算出來,進而分別利用IndRNN和CNN得到富含上下文信息的全局特征和局部特征;再將兩種特征進行融合,進而可以得到更好的結果。另外在規則特征的前提下引入了語義特征,可以得到先行語和照應語在實驗文本中的深層次語義信息,進一步提高特征的代表性。實驗結果證明,該方法對于維吾爾語指代消解有較好的效果,可以明顯提高實驗的性能,并且在引入語義特征后可以顯著提高實驗的效果。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
