融合圖結(jié)構(gòu)與節(jié)點關(guān)聯(lián)的關(guān)鍵詞提取方法
2019-10-21 02:01:52馬慧芳
中文信息學(xué)報 2019年9期
馬慧芳,王 雙,李 苗,李 寧
(1. 西北師范大學(xué) 計算機科學(xué)與工程學(xué)院,甘肅 蘭州 730070;2. 桂林電子科技大學(xué) 廣西可信軟件重點實驗室,廣西 桂林 541004;3. 中國科學(xué)院 信息工程研究所,北京 100093)
0 引言
隨著網(wǎng)絡(luò)技術(shù)的普及,網(wǎng)頁新聞與各類電子文檔快速地融入人們的生活,用戶如何從海量文檔中獲取有價值的信息,文本關(guān)鍵詞提取技術(shù)顯得至關(guān)重要。在大多數(shù)的文本挖掘任務(wù)中,關(guān)鍵詞提取均表現(xiàn)為根據(jù)詞項對文本內(nèi)容的相關(guān)程度對其排序,所以各種單篇文本的關(guān)鍵詞提取算法也隨之而生。
單篇文本的關(guān)鍵詞提取技術(shù)依賴于詞項所處的上下文語境,在去除停用詞并按照某種特定規(guī)則生成關(guān)鍵詞的候選集后,可采用基于統(tǒng)計的方法[1-4]、基于潛在語義分析的關(guān)鍵詞提取方法[5-6]、基于圖的關(guān)鍵詞排序方法[7-10]從候選集中選取關(guān)鍵詞。基于統(tǒng)計的方法關(guān)注詞項在文本的內(nèi)部統(tǒng)計特征和在語料庫的外部統(tǒng)計特征,例如,詞頻—逆文檔頻率[1](term frequency-inverse document frequency,TF-IDF)、JSD[2](Jensen-Shannon Divergence)等算法關(guān)注詞頻與詞項位置等內(nèi)部特征統(tǒng)計信息,基于Query logdoe的抽取關(guān)鍵詞方法[3]、語義關(guān)聯(lián)抽取關(guān)鍵詞方法[4]等結(jié)合搜索引擎記錄關(guān)注詞項在語料庫中的詞頻、鏈接次數(shù)等外部特征統(tǒng)計信息,通過計算權(quán)值選出高權(quán)重的詞項作為關(guān)鍵詞。從潛在語義而言,PLSA[5],LDA[6]采用文檔主題生成模型技術(shù)來識別大規(guī)模文檔集中潛在的語義信息,其重點關(guān)注建立詞項、主題和文檔三層結(jié)構(gòu),并得到詞項與文檔之間的隱藏語義關(guān)系。基于圖對關(guān)鍵詞排序算法的基本來源為PageRank[7]。PageRank模仿上網(wǎng)者以一定概率在各個頁面游走,經(jīng)過有限次游走可到達(dá)一個穩(wěn)定狀態(tài)的概率分布,該分布即為節(jié)點的排名依據(jù)。TextRank[8]將PageRank應(yīng)用于文本的關(guān)鍵字和關(guān)鍵句提取,可自動生成文本摘要。GraphSum[9]認(rèn)為節(jié)點之間的關(guān)聯(lián)性聯(lián)系有強弱之分,負(fù)關(guān)聯(lián)關(guān)系的節(jié)點之間投票時應(yīng)降低相應(yīng)的Page-Rank分?jǐn)?shù)。AttriRank[10]指出計算節(jié)點的重要性時不僅要考慮圖的結(jié)構(gòu),更要關(guān)注節(jié)點屬性之類的外部信息。
本文綜合考慮節(jié)點的圖結(jié)構(gòu)屬性、語義信息與節(jié)點間的關(guān)聯(lián)性特征,提出了一種融合圖結(jié)構(gòu)與節(jié)點關(guān)聯(lián)的關(guān)鍵詞提取方法(A Keywords Extraction Method via Combining Graph Structure with Nodes Association,GSNA)。首先,為了避免挖掘冗余的頻繁項集造成執(zhí)行效率低下,本文挖掘文檔的頻繁封閉項集并生成強關(guān)聯(lián)規(guī)則集合;其次,將強關(guān)聯(lián)規(guī)則集合中不重復(fù)的規(guī)則頭與規(guī)則體作為節(jié)點,節(jié)點之間有邊當(dāng)且僅當(dāng)彼此存在強關(guān)聯(lián)規(guī)則時,以關(guān)聯(lián)規(guī)則的關(guān)聯(lián)強度作為邊權(quán)重構(gòu)建文檔的關(guān)聯(lián)圖;然后,使用GSNA在關(guān)聯(lián)圖上隨機游走,迭代計算每個節(jié)點的重要性分?jǐn)?shù);最后,為了避免提取的關(guān)鍵詞之間有語義包含關(guān)系,對結(jié)果降序排序,并選取前若干個節(jié)點聚類,取出所有的類中心作為文檔的關(guān)鍵詞提取結(jié)果。基本技術(shù)流程如圖1所示。
本文致力于脫離語料庫的單篇長文本關(guān)鍵詞提取,依據(jù)節(jié)點的圖結(jié)構(gòu)屬性、語義信息和彼此間的關(guān)聯(lián)性對詞項排序,主要貢獻(xiàn)如下:
(1) 通過挖掘頻繁封閉項集生成強關(guān)聯(lián)規(guī)則用于構(gòu)建關(guān)聯(lián)圖,得到的強關(guān)聯(lián)規(guī)則規(guī)模小、速度快且無信息損耗,避免了重復(fù)掃描事務(wù)集與提取冗余的頻繁項集導(dǎo)致圖結(jié)構(gòu)過于復(fù)雜的問題,提高了算法的整體執(zhí)行效率。
(2) 綜合考慮關(guān)聯(lián)圖中節(jié)點的圖結(jié)構(gòu)屬性與語義信息,計算節(jié)點在關(guān)聯(lián)圖中的相似度,增大與關(guān)聯(lián)圖相似程度更大的節(jié)點被選中的概率,解決了節(jié)點之間等概率跳轉(zhuǎn)的缺陷。

圖1 基本技術(shù)流程圖
(3) 考慮節(jié)點間的關(guān)聯(lián)性事實,在關(guān)聯(lián)圖上隨機游走時,節(jié)點間投票有正負(fù)關(guān)聯(lián)之分,加強節(jié)點間的正關(guān)聯(lián)投票分?jǐn)?shù),降低節(jié)點間的負(fù)關(guān)聯(lián)投票分?jǐn)?shù),使得節(jié)點得分更加合理。
1 相關(guān)理論
文檔可視為由句子構(gòu)成的事務(wù)數(shù)據(jù)庫,文檔的關(guān)聯(lián)圖刻畫了節(jié)點所代表詞項之間的關(guān)聯(lián)關(guān)系。本文的關(guān)鍵詞提取算法作用于關(guān)聯(lián)圖之上,首先將文本處理為一個事務(wù)集,然后將CLOSE[11]算法作用于該事務(wù)集,挖掘強關(guān)聯(lián)規(guī)則集合,最后將強關(guān)聯(lián)規(guī)則集合建模成關(guān)聯(lián)圖。
1.1 文本預(yù)處理
文本在經(jīng)過數(shù)據(jù)去噪、分詞、停用詞過濾等預(yù)處理步驟后,可視為由一組停止標(biāo)記(“。”,“?”,“!”,“……”)分隔的句子集合S={s1,s2,…,sn}。si是由一組不重復(fù)的詞項序列構(gòu)成的句子,wiq是si的第q個詞。假設(shè)si存在與之對應(yīng)的事務(wù)ti,那么wiq可視為事務(wù)ti的第q個詞項。所以,由S中每個句子對應(yīng)的事務(wù)就構(gòu)成了文檔的事務(wù)集T={t1,t2,…,tn}。表1是一篇文檔的原始內(nèi)容,經(jīng)過預(yù)處理后,得到該文本的事務(wù)集T,如表2所示。

表1 原始文檔

表2 文檔的事務(wù)集
1.2 CLOSE算法
關(guān)聯(lián)規(guī)則[11]反映了事務(wù)中不同項集之間的關(guān)聯(lián)關(guān)系,基本形式為A→B,其中A∩B=?,A≠?且B≠?。關(guān)聯(lián)規(guī)則的挖掘建立在事務(wù)集之上,文檔的事務(wù)集為T,詞典為I={w1,w2,…,wm},基本概念定義如下:
定義1(k-項集)一個項集中項的數(shù)目稱為項集的長度,長度為k的項集稱為k-項集。
定義2(項集的支持度)令TA表示T中包含項集A的事務(wù)集合,則A在事務(wù)集的支持度如式(1)所示。

(1)
定義3(關(guān)聯(lián)規(guī)則的支持度)對于關(guān)聯(lián)規(guī)則A→B,A?I,B?I,A∩B=?,令TA∪B表示T中包含A∪B的事務(wù)集,則關(guān)聯(lián)規(guī)則A→B的支持度如式(2)所示。

(2)
定義4(關(guān)聯(lián)度)對于關(guān)聯(lián)規(guī)則A→B,A?I,B?I,A∩B=?,則A→B的關(guān)聯(lián)度如式(3)所示。

(3)
由于lift(A→B)=lift(B→A),所以lift滿足對稱性。由條件概率分析可知,當(dāng)lift(A→B)=1時,A與B服從獨立概率分布,表明A與B無關(guān)聯(lián)關(guān)系;當(dāng)lift(A→B)>1時,表示引入A后B的后驗概率高于B的先驗概率,說明A與B之間存在正關(guān)聯(lián)關(guān)系;反之,當(dāng)lift(A→B)<1時,表示A與B之間存在負(fù)關(guān)聯(lián)關(guān)系。
定義5 (強關(guān)聯(lián)規(guī)則)對于關(guān)聯(lián)規(guī)則A→B,A?I,B?I,A∩B=?,若滿足sup(A→B)≥minsup且lift(A→B)≤max-lift或lift(A→B)≥min+lift,則A→B為強關(guān)聯(lián)規(guī)則。其中,minsup為關(guān)聯(lián)規(guī)則的最小支持度閾值,max-lift為最大負(fù)關(guān)聯(lián)度閾值,min+lift為最小正關(guān)聯(lián)度閾值。
定義6(頻繁封閉項集)項集X為頻繁封閉項集當(dāng)且僅當(dāng)sup(X)≥minsup且S(X)=X。其中,(X)為X的閉包運算[12],minsup為X在事務(wù)集中的最小支持度。
為了快速地從文檔事務(wù)集中提取有效的強關(guān)聯(lián)規(guī)則,本文應(yīng)用CLOSE算法挖掘頻繁封閉項集,進(jìn)而生成強關(guān)聯(lián)規(guī)則集合,該算法使用閉包運算,結(jié)合廣度優(yōu)先策略搜索項集空間,實現(xiàn)非頻繁項集與非封閉項集的快速剪枝。相比于傳統(tǒng)的關(guān)聯(lián)規(guī)則挖掘,CLOSE算法提高了執(zhí)行效率。在獲取到不同長度的頻繁項集集合L={L1,L2,…,Lk}后,由Li中的i-頻繁項集生成m-項集(1≤m≤i-1)的規(guī)則頭與(i-m)-項集的規(guī)則體;然后,根據(jù)L計算lift(m-項集→(i-m)-項集),對CLOSE算法中抽取強關(guān)聯(lián)規(guī)則的步驟改進(jìn);最后,取出lift≤max-lift或lift≥min+lift對應(yīng)的強關(guān)聯(lián)規(guī)則。本文對CLOSE算法中抽取強關(guān)聯(lián)規(guī)則的改進(jìn)步驟如表3所示。

表3 強關(guān)聯(lián)規(guī)則生成步驟
1.3 關(guān)聯(lián)圖構(gòu)建
從文檔事務(wù)集中挖掘得到的強關(guān)聯(lián)規(guī)則集合為AR,將AR中所有不重復(fù)的規(guī)則頭與規(guī)則體作為關(guān)聯(lián)圖的節(jié)點集合N。關(guān)聯(lián)圖中的任意兩個節(jié)點之間有邊當(dāng)且僅當(dāng)彼此存在滿足lift≤max-lift或lift≥min+lift的強關(guān)聯(lián)規(guī)則,由于lift具有對稱性,所以節(jié)點之間只要有強關(guān)聯(lián)關(guān)系就一定存在雙向邊,且邊的權(quán)重定義為lift值。
表4為預(yù)處理后的文檔事務(wù)集樣例,假設(shè)minsup=0.6,min+lift=1.2,max-lift=0.95,由CLOSE算法得到該事務(wù)集的頻繁封閉項集為FC={{a,c},{b,e},{c},{b,c,e}},導(dǎo)出強關(guān)聯(lián)規(guī)則集合AR={a?c,c?be,c?b,c?e,b?ce,b?e,e?bc},抽取出AR中不重復(fù)的規(guī)則頭與規(guī)則體作為關(guān)聯(lián)圖節(jié)點N={{b,c},{b,e},{c,e},{a},{b},{c},{e}},以強關(guān)聯(lián)規(guī)則的關(guān)聯(lián)強度作為邊權(quán)重,構(gòu)建得到如圖2所示的無向加權(quán)關(guān)聯(lián)圖。

表4 文檔事務(wù)集樣例

圖2 文檔的關(guān)聯(lián)圖
1.4 PageRank算法
PageRank[7]為網(wǎng)頁排名算法,其認(rèn)為節(jié)點A有邊指向B可看作A對B投票,節(jié)點的入邊權(quán)重總和越高則該節(jié)點的重要性越高。PageRank模仿上網(wǎng)者,能夠在關(guān)聯(lián)圖上的相鄰節(jié)點之間移動,也可以從當(dāng)前節(jié)點跳轉(zhuǎn)至非鄰居節(jié)點。在經(jīng)過有限足夠多次游走后,各點達(dá)到穩(wěn)定狀態(tài),即節(jié)點的重要性分?jǐn)?shù)趨于定值。每經(jīng)過一次游走迭代,就會產(chǎn)生一次節(jié)點排序,該排序值即為PageRank分?jǐn)?shù)。節(jié)點Ni為關(guān)聯(lián)圖中的第i個節(jié)點,e表示Ni的入邊條數(shù),PR(Ni)表示Ni的PageRank分?jǐn)?shù),C(Ni)表示Ni的出邊條數(shù),d用于衡量一個節(jié)點跳轉(zhuǎn)至另一個節(jié)點的衰減系數(shù),Ni的PageRank分?jǐn)?shù)定義如式(4)所示。
(4)
其中,節(jié)點間的跳轉(zhuǎn)為等概率事件即1/|N|,而理論上,相似節(jié)點之間跳轉(zhuǎn)的可能性會更大。另外,節(jié)點之間還存在正關(guān)聯(lián)關(guān)系和負(fù)關(guān)聯(lián)關(guān)系,所謂正關(guān)聯(lián)關(guān)系為一個節(jié)點的出現(xiàn)后往往伴隨著另一個節(jié)點出現(xiàn),而負(fù)關(guān)聯(lián)關(guān)系為一個節(jié)點出現(xiàn)后使得另一個節(jié)點出現(xiàn)的概率降低。對于節(jié)點間的正關(guān)聯(lián)關(guān)系,需要增大PR投票分?jǐn)?shù),而對于負(fù)關(guān)聯(lián)關(guān)系,應(yīng)降低PR的投票分?jǐn)?shù)。
2 融合圖結(jié)構(gòu)與節(jié)點關(guān)聯(lián)的關(guān)鍵詞提取
關(guān)聯(lián)圖中不同的節(jié)點對文本的重要性往往是不同的,GSNA算法分別從節(jié)點的圖結(jié)構(gòu)相似性與關(guān)聯(lián)性對PageRank加以改進(jìn)。衡量節(jié)點的相似性時,GSNA考慮了節(jié)點在關(guān)聯(lián)圖中的結(jié)構(gòu)屬性與隱含的語義信息;衡量節(jié)點的關(guān)聯(lián)性時,需要增強正關(guān)聯(lián)傳播,降低負(fù)關(guān)聯(lián)傳播。GSNA合理地調(diào)節(jié)PR分?jǐn)?shù),使得節(jié)點排名更準(zhǔn)確。
2.1 節(jié)點間的圖結(jié)構(gòu)與語義相似性
從圖結(jié)構(gòu)形式而言,若兩節(jié)點與其余節(jié)點的連接形式相似,則它們極可能為圖結(jié)構(gòu)形式相似節(jié)點。
為了量化節(jié)點的圖結(jié)構(gòu)屬性,本文使用表5所示的6個指標(biāo)。其中,attr1~attr3直觀地表示了一個節(jié)點與其余節(jié)點的關(guān)聯(lián)能力,attr4體現(xiàn)了一個節(jié)點與周圍鄰居節(jié)點的相似匹配程度,attr5、attr6定量地說明了一個節(jié)點在關(guān)聯(lián)圖中的傳播能力。對于節(jié)點Ni,可將其形式化表示為Attri=(attr1,attr2,attr3,attr4,attr5,attr6)。

表5 節(jié)點的結(jié)構(gòu)屬性表
從節(jié)點的語義信息而言,若兩節(jié)點與詞典中詞項的共現(xiàn)分布情況相似,則它們有可能為語義相似節(jié)點。預(yù)處理后文檔的詞典為I={w1,w2,…,wm},節(jié)點Ni與I的共現(xiàn)分布為P={p1,p2,…,pm},pj表示同時包含Ni與wj的句子在事務(wù)集中的歸一化值,Nj與I的共現(xiàn)分布為Q={q1,q2,…,qm},則Ni與Nj的語義距離[3]如式(5)所示。
(5)
綜合節(jié)點的圖結(jié)構(gòu)屬性與語義信息,節(jié)點Ni與Nj的相似度衡量如式(6)所示。當(dāng)Ni與Nj的圖結(jié)構(gòu)屬性或語義分布差異越大時,相似度sij越低,反之當(dāng)Ni與Nj的結(jié)構(gòu)屬性或語義分布越接近時,sij相應(yīng)越高。
(6)
關(guān)聯(lián)圖中存在強關(guān)聯(lián)關(guān)系的節(jié)點之間有相似度,無強關(guān)聯(lián)關(guān)系的節(jié)點之間相似度為0,則可形成關(guān)聯(lián)圖的相似度矩陣S|N|×|N|。為了更形式化地度量一個節(jié)點與所有節(jié)點的相似程度,本文將每個節(jié)點在關(guān)聯(lián)圖中的相似度計算歸一化,如式(7)所示。
(7)
其中,ri表示Ni與圖中所有節(jié)點的相似程度,使用ri修正PageRank公式,使得節(jié)點不再服從等概率跳轉(zhuǎn),而是使與關(guān)聯(lián)圖相似程度更大的節(jié)點被選中的概率更高,如式(8)所示。
(8)
由于關(guān)聯(lián)圖為無向圖,所以式(8)中C(Nk)表示節(jié)點Nk的度,e表示Nk的鄰居個數(shù)。
2.2 節(jié)點間的關(guān)聯(lián)性
在關(guān)聯(lián)圖中,兩節(jié)點之間有邊當(dāng)且僅當(dāng)它們之間存在強關(guān)聯(lián)規(guī)則。為了加強正關(guān)聯(lián)節(jié)點間的PR投票分?jǐn)?shù),降低負(fù)關(guān)聯(lián)節(jié)點間的投票分?jǐn)?shù),本文使用lift值對式(8)改進(jìn)得到式(9)。
(9)
式(9)融合了節(jié)點的圖結(jié)構(gòu)屬性、語義信息與節(jié)點之間的關(guān)聯(lián)性,使得節(jié)點重要性排名更加合理。lift(Ni,Nk)表示Ni與Nk的關(guān)聯(lián)強度,當(dāng)Ni與Nk為負(fù)關(guān)聯(lián)關(guān)系時lift<1,為正關(guān)聯(lián)關(guān)系時lift>1,所以lift能夠根據(jù)正負(fù)關(guān)聯(lián)性恰當(dāng)?shù)胤趴sPR(Nk)的大小,實現(xiàn)了加強正關(guān)聯(lián)傳播、降低負(fù)關(guān)聯(lián)傳播的目的。
根據(jù)式(9)在關(guān)聯(lián)圖上隨機游走,迭代計算每個節(jié)點的PR值、直至滿足式(10),使節(jié)點分?jǐn)?shù)達(dá)到收斂狀態(tài),其中δ為隨機游走終止閾值,往往取為10-4。
(10)
2.3 關(guān)鍵詞語義聚類
為了避免提取的關(guān)鍵詞之間有語義包含關(guān)系,對詞項的PageRank分?jǐn)?shù)降序排序后進(jìn)行語義聚類,最后取出所有的類中心作為文檔的關(guān)鍵詞提取結(jié)果。
關(guān)聯(lián)圖的節(jié)點是根據(jù)不同長度的頻繁封閉項集取子集形成的,k-項集一共含有2k-1個非空子集。例如,1-項集一定是(k-1)-項集的子集,這種現(xiàn)象可視為(k-1)-項集對1-項集有語義包含關(guān)系。為了防止得到的關(guān)鍵詞之間存在語義包含關(guān)系,本文將排序后前P個節(jié)點進(jìn)行K-Medoid聚類[12]并抽取所有的類中心作為最終的關(guān)鍵詞。K-medoid利用語義距離作為類中心選擇的基準(zhǔn),保證類中心的語義能夠兼收該類中其他詞項的語義。
本文抽取出文本的強關(guān)聯(lián)規(guī)則集合AR后,依據(jù)AR構(gòu)建文本的關(guān)聯(lián)圖,使用GSNA在關(guān)聯(lián)圖上隨機游走計算每個節(jié)點的PR分?jǐn)?shù),并對節(jié)點聚類得到文檔的關(guān)鍵詞。首先,初始化每個節(jié)點的PR分?jǐn)?shù)為1/|N|;其次,計算相似度矩陣S|N|×|N|,并歸一化得到每個節(jié)點在關(guān)聯(lián)圖中的固定相似度值ri;然后,在關(guān)聯(lián)圖上隨機游走,迭代計算每個節(jié)點的PR值直至收斂;最后,對前P個詞項聚類,取所有的類中心作為文檔的關(guān)鍵詞。
3 實驗與結(jié)果分析
為了驗證本文算法的可行性,首先選取中英文數(shù)據(jù)和恰當(dāng)?shù)脑u價指標(biāo),其次尋找最佳關(guān)聯(lián)圖模型對應(yīng)的輸入?yún)?shù),然后在最佳關(guān)聯(lián)圖的情形下對關(guān)鍵詞的抽取規(guī)模做出討論,最后選取4種關(guān)鍵詞提取算法與GSNA對比,驗證GSNA的優(yōu)越性。
3.1 實驗數(shù)據(jù)與評價指標(biāo)
為了驗證GSNA算法的有效性,本文選取達(dá)爾文的漢譯版著作《物種起源》[13]作為中文實驗數(shù)據(jù),選取Li編寫的文獻(xiàn)[14](Li’paper)作為英文實驗數(shù)據(jù)。以《物種起源》為代表的大規(guī)模數(shù)據(jù)和以Li’paper為代表的小規(guī)模數(shù)據(jù),已被許多學(xué)者用于驗證各種新型關(guān)鍵詞提取算法的準(zhǔn)確性[2-8]。在經(jīng)過數(shù)據(jù)去噪、中文文本分詞、英文數(shù)據(jù)大小寫轉(zhuǎn)換與詞干還原、停用詞過濾和事務(wù)詞項去重等預(yù)處理步驟后,《物種起源》共含有39 599個詞項、3 495個句子,分布在14個章節(jié)的各個段落;Li’paper共含有3 315個詞項,402個句子。此外,本文分別選取《物種起源》的重要詞匯注解表中的15個重要詞項與專家對Li’paper列舉的7個關(guān)鍵詞作為評價中文與英文關(guān)鍵詞提取是否有效的基準(zhǔn)。
本文將提取的關(guān)鍵詞序列標(biāo)記為Mret,將詞匯表序列標(biāo)記為Mrel,所涉及的評價指標(biāo)包括MAP[15](Mean Average Precision)、召回率Recall[3]和Fβ。其中,MAP定義如式(11)所示。
(11)
式(11)中,Mret(j)表示關(guān)鍵詞返回序列Mret的第j個詞項;g(t,Mrel)為指示函數(shù),若詞項t出現(xiàn)在原詞匯表序列Mrel中則返回1,否則返回0;P(i)與AP(i)分別表示Mret中前i個詞項的準(zhǔn)確率與平均準(zhǔn)確率。
本文期望檢索到的關(guān)鍵詞不僅準(zhǔn)確率高而且排名盡可能居前,所以將MAP引入Fβ的計算。相比于召回率,本文更側(cè)重于提升準(zhǔn)確率,故Fβ指標(biāo)中β取值為0.5,其計算如式(12)所示。
(12)
3.2 關(guān)聯(lián)圖模型參數(shù)分析
關(guān)聯(lián)圖的形式結(jié)構(gòu)直接決定了關(guān)鍵詞提取的效果,不同參數(shù)設(shè)置可能會對結(jié)果帶來不同程度的影響。CLOSE算法中的minsup設(shè)置過高則會丟棄大量有意義的詞匯,設(shè)置過低則會包含眾多冗余詞匯,min+lift與max-lift的變化會直接影響關(guān)聯(lián)圖的形式結(jié)構(gòu),同時GSNA算法在隨機游走時衰減系數(shù)d的調(diào)節(jié)也會影響關(guān)鍵詞的提取效果。
在預(yù)實驗過程中發(fā)現(xiàn),相比于節(jié)點的圖結(jié)構(gòu)屬性,節(jié)點的關(guān)聯(lián)性對關(guān)鍵詞的提取效果影響更大,所以本文設(shè)置minsup=0.8%,d=0.65。令降序排序后的關(guān)鍵詞序列為Mv,為了避免過多參數(shù)變化導(dǎo)致分析過程復(fù)雜,暫不考慮關(guān)鍵詞的提取數(shù)量,在調(diào)節(jié)模型參數(shù)時,均抽取每次所得關(guān)鍵詞序列Mv的前|Mrel|個詞項作為提取的關(guān)鍵詞序列Mret,并繪制關(guān)聯(lián)圖模型的輸入?yún)?shù)與MAP的變化曲線。
對于中文數(shù)據(jù),圖3和圖4顯示當(dāng)max-lift與min+lift分別在[0.55,0.75]和[2,14]區(qū)間內(nèi)變化時,GSNA算法的平均準(zhǔn)確率呈上升趨勢,而max-lift與min+lift的輕微增加就會引起MAP的急速下降,這是因為數(shù)據(jù)中重要詞匯彼此間的負(fù)關(guān)聯(lián)度與正關(guān)聯(lián)度更多地集中于[0.65,0.75]與[11,14]范圍內(nèi)。所以,當(dāng)min+lift=14,max-lift=0.7時,在中文數(shù)據(jù)上構(gòu)建的關(guān)聯(lián)圖模型能取得最佳提取效果。

圖3 max-lift對關(guān)鍵詞提取效果的影響[中文數(shù)據(jù)]

圖4 min+lift對關(guān)鍵詞提取效果的影響[中文數(shù)據(jù)]
由于英文數(shù)據(jù)規(guī)模相對較小,本文設(shè)置max-lift以0.4為基數(shù),以步長為0.1的速度增長;min+lift初始值為2,以步長為2的速度增長。圖5和圖6表明,當(dāng)min+lift=6,max-lift=0.7時,MAP達(dá)到峰值0.904 8。

圖5 max-lift對關(guān)鍵詞提取效果的影響[英文數(shù)據(jù)]
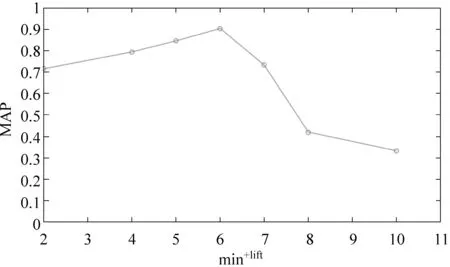
圖6 min+lift對關(guān)鍵詞提取效果的影響[英文數(shù)據(jù)]
由于兩種語料庫的規(guī)模不同,所以效果最好時的min+lift相差較大。min+lift的取值越大就會去除越多的關(guān)聯(lián)詞項,而小規(guī)模語料庫的關(guān)鍵詞候選量較少,為了更準(zhǔn)確地提取關(guān)鍵詞,所以較中文數(shù)據(jù)而言,英文數(shù)據(jù)的min+lift取值較小。
3.3 關(guān)鍵詞提取規(guī)模
關(guān)鍵詞提取注重挑選出與文本最相關(guān)的詞匯,所以選取關(guān)鍵詞的數(shù)量規(guī)模顯得至關(guān)重要。本文引入關(guān)鍵詞抽取規(guī)模參數(shù)scale=Mret/Mv,圖7展現(xiàn)了Fβ在兩種數(shù)據(jù)上隨著scale的增長而變化的曲線。

圖7 scale對關(guān)鍵詞提取效果Fβ的影響
對于《物種起源》而言,在最佳關(guān)聯(lián)圖的情形下,經(jīng)過語義聚類后得到Mv=23個重要詞匯。當(dāng)scale=85%時,F(xiàn)β取得最大值0.854 8,實驗表明可選取規(guī)模為Mret=0.85×Mv的詞序列作為該數(shù)據(jù)的關(guān)鍵詞提取結(jié)果。對于Li’paper,聚類后返回Mv=7個重要詞項,當(dāng)scale=80%時,F(xiàn)β取得最大值 0.810 2。
3.4 算法對比及分析
為了驗證本文算法的優(yōu)越性,將TextRank[8]、GraphSum[9]、考慮圖結(jié)構(gòu)而不考慮節(jié)點關(guān)聯(lián)性的關(guān)鍵詞提取方法(Key Words Extraction Method by Nodes Association,NA)、考慮節(jié)點關(guān)聯(lián)性而不考慮圖結(jié)構(gòu)的關(guān)鍵詞提取方法(Key Words Extraction Method by Graph Structure,GS)與本文算法進(jìn)行對比。
表6和表7列舉出5種關(guān)鍵詞提取算法分別作用于中文與英文數(shù)據(jù)上關(guān)于MAP、R、Fβ指標(biāo)上的對比結(jié)果。其中,最優(yōu)指標(biāo)值用粗字體標(biāo)出,帶有灰色背景的關(guān)鍵詞表示未出現(xiàn)在Glossay的詞項。TextRank在中文數(shù)據(jù)上的詞項共現(xiàn)窗口長度為20,在英文數(shù)據(jù)上的詞項共現(xiàn)窗口長度設(shè)為5,GraphSum、NA與GS算法均在GSNA所得的最佳關(guān)聯(lián)圖上迭代計算節(jié)點的重要性分?jǐn)?shù)。
均未考慮節(jié)點的圖結(jié)構(gòu)屬性與關(guān)聯(lián)性的Text-Rank算法得到的關(guān)鍵詞效果最差。值得注意的是,分別只考慮節(jié)點關(guān)聯(lián)性與圖結(jié)構(gòu)屬性的NA與GS算法的MAP和R指標(biāo)明顯高于GraphSum和Text-Rank,說明NA和GS能檢索到更為重要的關(guān)鍵詞。GSNA算法從Fβ上比NA和GS的效果更加可觀,說明關(guān)鍵詞提取過程中節(jié)點的圖結(jié)構(gòu)屬性與關(guān)聯(lián)性均不容忽視。相對于GSNA算法,GraphSum缺少詞項的語義聚類環(huán)節(jié),導(dǎo)致提取結(jié)果存在語義冗余的詞項,故其MAP和R指標(biāo)均低于GSNA。

表6 中文數(shù)據(jù)集上不同關(guān)鍵詞提取算法的結(jié)果對比分析

表7 英文數(shù)據(jù)集上不同關(guān)鍵詞提取算法的結(jié)果對比分析
值得關(guān)注的是,5種方法在以《物種起源》為代表的大規(guī)模數(shù)據(jù)集上的性能均高于在以“Li’paper”為代表的小規(guī)模數(shù)據(jù)集上的性能。這是因為大規(guī)模的數(shù)據(jù)在構(gòu)建關(guān)聯(lián)圖時能夠形成更為復(fù)雜的圖結(jié)構(gòu)形式,同時更能充分地揭示大量節(jié)點間的關(guān)聯(lián)關(guān)系與詞項間的語義關(guān)系,所以文本規(guī)模越大,GSNA的效果會越好。
3.5 算法效率分析
為了觀測GSNA的運行效率,本節(jié)在Celeron 1.40GHz處理器的Windows操作系統(tǒng)下,比較了TextRank、NA、GS、GSNA與GraphSum這5種方法在不同詞量規(guī)模下的執(zhí)行時間,如圖8所示。由于GSNA考慮了圖結(jié)構(gòu)、語義信息、節(jié)點間的關(guān)聯(lián)性信息,所以在同等詞量規(guī)模下,GSNA的執(zhí)行效率會比其他方法更低。但隨著詞量規(guī)模的擴大,GSNA的運行時間接近于線性增長,當(dāng)詞項規(guī)模不超過40 000時,GSNA可在10s內(nèi)完成關(guān)鍵詞提取的過程。

圖8 5種方法在不同詞量規(guī)模下的執(zhí)行時間
4 總結(jié)
本文提出了一種融合圖結(jié)構(gòu)與節(jié)點關(guān)聯(lián)的關(guān)鍵詞提取方法,能夠在脫離外部語料庫的情況下檢索到單篇文本的關(guān)鍵詞。首先將挖掘到的強關(guān)聯(lián)規(guī)則建模成關(guān)聯(lián)圖,然后利用GSNA在關(guān)聯(lián)圖上隨機游走計算節(jié)點的重要性分?jǐn)?shù),最后對結(jié)果進(jìn)行降序排序與語義聚類。實驗選取中、英文驗證數(shù)據(jù),分別探索了關(guān)聯(lián)圖模型參數(shù)的影響、關(guān)鍵詞的提取規(guī)模、5種關(guān)鍵詞提取算法的性能,綜合分析,本文算法性能最佳。未來工作將致力于構(gòu)建新型關(guān)聯(lián)圖模型,優(yōu)化GSNA算法,提高整體執(zhí)行效率。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當(dāng)代陜西(2021年17期)2021-11-06 03:21:36
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
開放教育研究(2020年2期)2020-03-31 01:54:14
學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學(xué)報(哲學(xué)社會科學(xué)版)(2016年9期)2017-01-15 13:52:02
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
