語音端點檢測算法研究及其VerilogHDL設計概述
2019-10-21 08:03:50龐盼段圓夢
科學與信息化 2019年6期
龐盼 段圓夢

摘 要 本文以語音端點檢測算法為基礎,著重研究了基于短時平均能量以及過零率的語音端點檢測算法原理及其實現,并且對其算法進行測試,基于該算法使用verilogHDL對其進行硬件設計,最后對該算法在硬件設計模塊上的性能進行了仿真,取得了較好的效果。
關鍵詞 語音端點檢測;短時能量;VerilogHDL
Abstract Based on the speech endpoint detection algorithm, this paper focuses on the principle and implementation of speech endpoint detection algorithm based on short-term average energy and zero-crossing rate, and tests its algorithm. Based on this algorithm, verilogHDL is used to design hardware. Finally, The performance of the algorithm on the hardware design module was simulated and good results were obtained.
Keywords Voice activity detection; Short-term average energy; VerilogHDL
1語音端點檢測背景及其研究現狀
語音端點檢測(voice activity detection)又稱VAD,是指在一段語音中準確檢測出語音的起止點和終點,這種技術廣泛應用于語音識別和語音增強技術中,例如在語音識別中,先檢測出端點再進行語音識別,這樣不僅能提高識別準確率,并且可以降低功耗,通常來講,語音端點檢測就是各種語音信號系統研究中的預處理。
語音端點檢測的發展歷史最早可以追溯到1950年左右,經過幾十年的研究發展,VAD相關的算法研究已經比較成熟,甚至有相當的算法經過人們改進之后可以設計為硬件模塊或者IP核,這也提高了VAD檢測的速度,本文將基于一種VAD算法的研究,并且將其硬件設計實現[1]。
2VAD相關算法
VAD算法的應用基本是處于兩個背景下的,一種是基于中高信噪比的VAD算法,一種是基于低信噪比的VAD算法。
基于短時平均能量及其過零率的VAD算法實現簡單,穩定性強,是一種經典的VAD算法[2];基于頻帶方差法的VAD算法著重研究語音和噪聲在頻譜中的差異特性,效果較好,衍生出來有子帶頻帶方差VAD算法,頻域BARK子帶方差的VAD算法;低信噪比條件的VAD算法處理思想要先進行增強處理然后再結合頻帶方差或者短時能零率進行檢測,對于低信噪比的信號處理效果較好,但缺點是算法復雜,常用算法有譜減法結合子帶方差法等。
3基于短時平均能量和過零率的VAD算法原理研究
基于短時平均能量和過零率的算法是VAD中最經典的算法,其原理是根據漢語發音中韻母中有元音,能量較大,而聲母是輔音,其頻率較高,總會在零點經過,所以根據這兩個特點找出聲母和韻母,就可以準確檢測出語音段[3]。
假如輸入一段采樣率為16KHZ的語音信號為x(n),對語音進行歸一化和分幀處理,假設幀長為framelen,通常為幾百個采樣點,這里設置為256個采樣點,同時幀移設為frameinc,長度為64個采樣點,處理后的語音設為xi(m),其中i表示第i幀,總幀數設置為fn語音分幀處理的原因是可以觀察語音的短時特性[4],同時也有利于語音的平滑處理。
經過上述處理,計算每幀信號的短時平均能量,設AMP為每幀信號的短時平均能量,則:
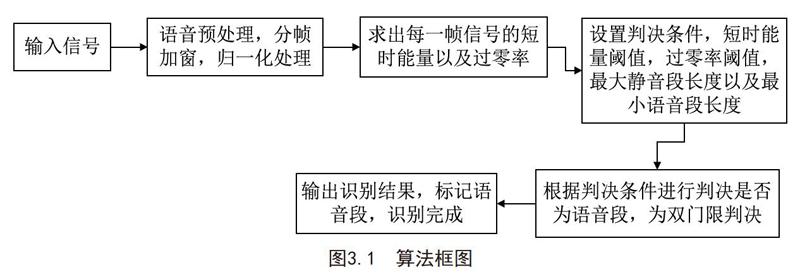
執行每幀信號的短時平均能量和過零率計算的函數如上所示,接下來根據語音段和非語音短時平均能量和短時過零率的差異特性進行檢測即可,整個算法的框架如下:
語音預處理的目的在于消除信號直流分量,分幀可以更好地觀察信號的短時特性,根據公式可以求出短時平均能量及其過零率。
對于判決條件中閾值的選擇,我們可以設置一段前導無話段來提前估算噪聲的能量,然后根據此段設置短時平均能量和過零率閾值即可。
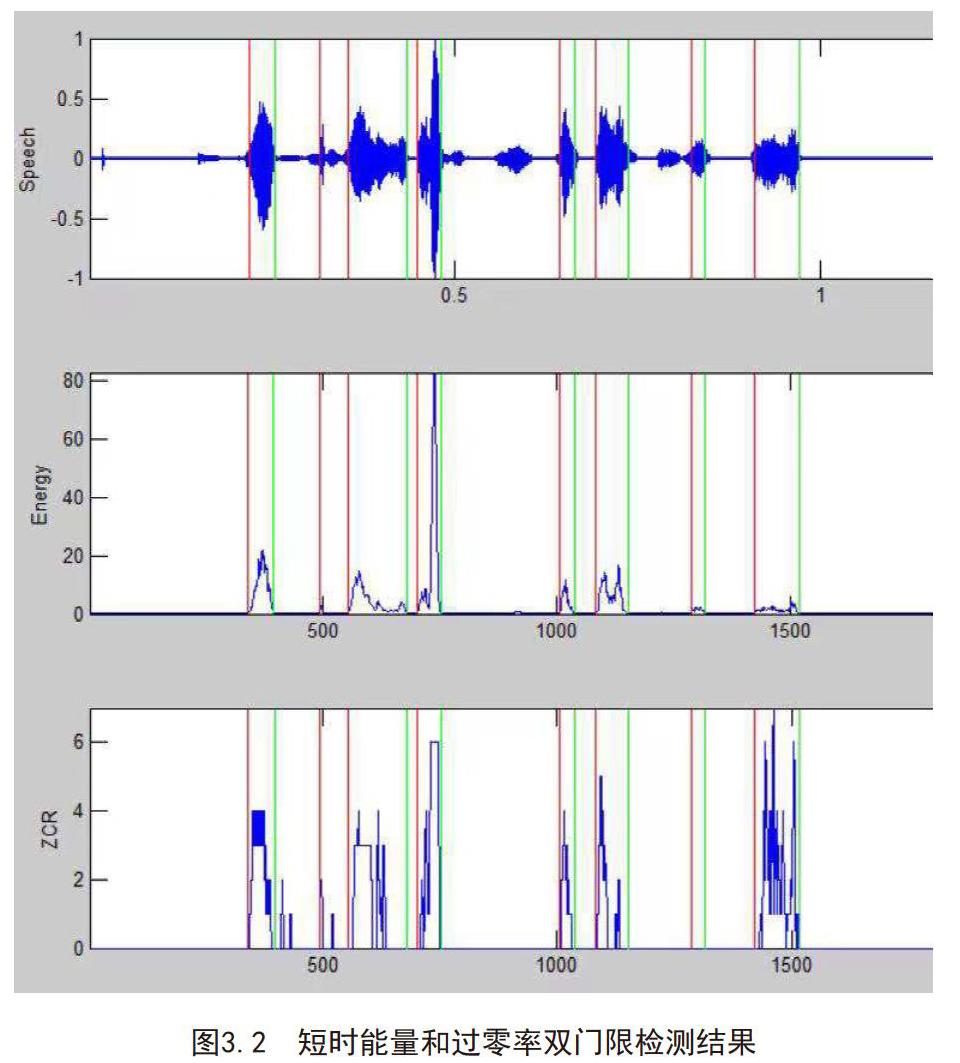
如上圖所示為其中一段測試結果,Speech為帶噪聲語音,Energy為短時平均能量,ZCR為過零率,兩邊紅綠色線截取即為語音段,也就是檢測結果,可以看出測試結果正確率較高。該算法對中高信噪比的信號檢測比較有效且算法復雜度低,易于實現,下一節將以該算法為基礎研究算法的硬件實現。
4VerilogHDL設計仿真
這一節主要設計將matlab實現的算法轉化為硬件層面的算法,使用的語言為VerilogHDL硬件描述語言,后期使用的仿真工具為VCS,dump波形工具為Verdi,對于該設計將采用VCS+Verdi聯合仿真[5]。
首先對VAD模塊端口簡單設計,主要有時鐘輸入端口,復位端口,信號選擇端口,數據輸入端口,有效信號端口,還有輸出端口。
整個模塊數據采用16KHZ采樣率采樣的信號,數據為16bit定點化有符號數。首先對整個數據使用寄存器緩存兩拍,對于verilogHDL實現語音分幀可以采用計數器,首先256個采樣點為一幀信號,其實是4*64個采樣點組成,可以對計算出的能量進行累加,計數器計數至64清零,之后重新計數,定義4個寄存器,將累加的64個能量值依次賦值到新定義的寄存器中,四個寄存器的值相加即可得到每幀256個采樣點,幀移為64 的信號處理結果。
對于短時平均能量的計算,matlab通常可以直接相除,但是在verilogHDL設計中不建議直接相除,因為這樣會導致仿真驗證后綜合難以完成或者綜合產生的模塊面積或者功耗過大,所以在初步設計時候,分幀的采樣點和幀移盡量設置為2的次方,這樣除法可以直接采用移位完成操作,假如不是2的次方,對于除法仍然可以采用移位相加的形式來完成。
對于短時能量的計算,直接相乘即可,對于過零率的計算,采用同步狀態機(FSM)設計,狀態機編碼采用二進制碼或者格雷碼,狀態機的轉移圖如圖4.1所示:
短時平均能量和短時過零率計算完成以后可以根據其前導無話段計算出來的閾值進行逐幀判決,判決結果輸出為0或者1。
設計完成之后編寫testbench進行仿真驗證,采用vcs和verdi聯合仿真,dump出模塊中的各個情況的輸出波形查看是否符合預期結果,經過驗證,結果符合預期,det為輸出,輸出為1則表示語音段,輸出為0則表示非語音段。
5結束語
本文以VAD算法為基礎,綜述當前比較常用的VAD算法,著重研究了短時平均能量以及過零率的算法,并且將其用verilogHDL設計成為硬件模塊,可以看出,該算法檢測效果較好,但是測試階段顯示該算法在低信噪比條件下性能不佳。
隨著神經網絡[6]的發展,現在已經有比較成熟的神經網絡算法應用在了VAD算法上,今后的VAD也肯定向這個方向發展,希望未來可以有更好的算法應用于語音端點檢測上。
參考文獻
[1] 宋知用.MATLAB語音信號分析與合成[M].北京:北京航空航天大學出版社,2018:118-119.
[2] 汪魯才,曹鵬霞,姜小龍.一種改進的含噪語音端點檢測方法[J].計算機工程與應用,2016,52(15):165-167.
[3] 朱明明,吳小培,羅雅琴.基于子帶能量的語音端點檢測算法的研究[J].工業控制計算機,2013,26(9):44-45.
[4] 韓立華,王博,段淑鳳.語音端點檢測技術研究進展[J].計算機應用研究,2010,27(4):1220-1226.
[5] 蔡覺平,翁靜純,褚潔,馮必先. VerilogHDL數字集成電路高級程序設計[M].西安:西安電子科技大學出版社,2015:346-462.
[6] 張梅.一種基于模糊神經網絡的語音端點檢測方法[J].計算機工程與應用,2012,48(16):133-134.
