基于自注意力網絡的圖像超分辨率重建
2019-10-23 12:23:56歐陽寧梁婷林樂平
計算機應用 2019年8期
歐陽寧 梁婷 林樂平

摘 要:針對圖像超分辨率重建中紋理細節等高頻信息恢復的問題,提出一種基于自注意力網絡的圖像超分辨率重建方法。該網絡框架利用兩個重建階段逐步地將圖像的精確度從粗到細進行恢復。在第一階段中,首先將低分辨率(LR)圖像作為輸入通過一個卷積神經網絡(CNN),并輸出一個粗精度的高分辨率 (HR)圖像;然后將粗精度圖像作為輸入并產生更加精細的高分辨率圖像。在第二階段中,使用自注意力模塊計算特征之間所有位置的關聯性,通過捕捉特征的全局依賴關系來提高紋理細節的恢復能力。
在基準數據集上的實驗結果表明,與現有基于深度神經網路的超分辨率重建算法相比,所提算法不僅圖像視覺效果最好,而且在數據集Set5和BDSD100上的峰值信噪比(PSNR)平均提高了0.1dB、0.15dB,表明該網絡可以通過增強特征的全局表達能力來重建出高質量圖像。
關鍵詞:深度卷積神經網絡;從粗到細;自注意力;全局依賴關系;超分辨率
中圖分類號: ?TP391.41
文獻標志碼:A
Self-attention network based image super-resolution
OUYANG Ning1,2, LIANG Ting2, LIN Leping1,2*
1.Key Laboratory of Cognitive Radio and Information Processing of Ministry of Education (Guilin University of Electronic Technology), Guilin Guangxi 541004, China ;
2.School of Information and Communication, Guilin University of Electronic Technology, Guilin Guangxi 541004, China
Abstract:?Concerning the recovery problem of high-frequency information like texture details in image super-resolution reconstruction, an image super-resolution reconstruction method based on self-attention network was proposed. Two reconstruction stages were used to gradually restore the image accuracy from-coarse-to-fine. In the first stage, firstly, a Low-Resolution (LR) image was taken as the input through a Convolutional Neural Network (CNN), and a High-Resolution (HR) image was output with coarse precision; then, the coarse HR image was used as the input and a finer HR image was produced. In the second stage, the correlation of all positions between features was calculate by the self-attention module, and the global dependencies of features were captured to enhance texture details. Experimental results on the benchmark datasets show that, compared with the state-of-the-art deep neural networks based super-resolution algorithms, the proposed algorithm not only has the best visual effect, but also has the Peak Signal-to-Noise Ratio (PSNR) improved averagely by 0.1dB and 0.15dB on Set5 and BDSD100. It indicates that the network can enhance the global representation ability of features to reconstruct high quality images.
Key words:?deep convolutional neural network; from-coarse-to-fine; self-attention; global dependency; super-resolution
0 引言
近來,深度學習在計算機視覺[1-3]方面的重大進展已經影響到超分辨率領域中[4-9]。單幅圖超分辨率[10]是一個不適定的逆問題,旨在從低分辨率(Low-Resolution, LR)圖像中恢復出一個高分辨率(High-Resolution, HR)圖像。目前典型的方法是通過學習LR-to-HR的非線性映射來構造高分辨率圖像。Dong等[4]首先引入了一個三層的卷積神經網絡(Convolutional Neural Network, CNN)用于圖像的超分辨率,提出了基于卷積神經網絡的超分辨率重建(Super-Resolution using Convolutional Neural Network, SRCNN)方法,以端對端的方法學習LR到HR之間的非線性映射關系。得益于殘差網絡[4]的出現解決了訓練深度網絡的梯度爆炸/梯度消失等關鍵問題,應用于SR的網絡也往更深更寬的趨勢發展。Kim等[6]受深度神經網絡(Very deep convolutional networks for large-scale image recognition, VGG)[11]啟發提出了一種非常深的卷積網絡重建精準的超分辨率(accurate image Super- Resolution using Very Deep convolutional networks,VDSR),該網絡達到20層,為了提高收斂速度,使用非常高的學習率,運用殘差學習與梯度裁剪來解決梯度爆炸問題;Ren等[7]提出了融合多個神經網絡用于圖像的超分辨率重建(image super resolution based on Fusing multiple Convolution neural Networks, CNF),由于各個網絡的輸出特征映射具有不同的上下文特征,將其融合來提升整體網絡的精度。此外,Lai等[8]利用金字塔的結構提出了深度拉普拉斯網絡來實現快速準確的超分辨率(deep Laplacian pyramid Networks for fast and accurate Super-Resolution, LapSRN),將LR圖像作為輸入來減少計算量,采用從粗到細的方式逐步預測子帶的殘差圖。該方法在超分辨率中利用從粗到細的逐步優化方法,能更好地去尖銳和模糊。
將深度學習應用于超分辨率領域中,隨著網絡的加深,其感受野變得越來越大,使得網絡不僅具備局部特征,且能捕捉到更加全局的特征,而全局特征的加入又更有利于超分辨率紋理細節的恢復。但一味地增加深度會帶來巨大的計算量,甚至導致網絡難以訓練等問題。而且在層層卷積的網絡中只能根據低分辨率特征圖的空間局部點生成高分辨率細節,沒能充分利用特征之間的全局依賴關系進行建模。另一方面,自注意力機制[12-13]在建模全局依賴關系以及計算效率上表現出良好的性能。Zhang等[13]對自注意機制捕捉模型內部的全局依賴關系進行了研究,可以使用來自所有特征位置的關聯生成細節信息。自注意力機制的出現為超分辨率重建獲取全局特征來恢復紋理細節提供了新思路。
本文提出一種基于自注意力網絡的圖像超分辨率(Self-Attention Network for images Super-Resolution, SASR-Net)重建方法,以獲取全局特征及豐富的語義信息來恢復更多的高頻細節。基于從粗到細的思想,本文的網絡結構分為兩個階段來逐步提高高分辨率圖像的精確度。
第一階段,本文先用一個由殘差單元組成的CNN來提取特征,以原始LR圖像作為輸入減少計算量,恢復出一個粗精度的HR圖像。
第二階段,為了獲取更加全局的特征來進一步細化所獲得的粗精度HR圖像,設計了自注意力模塊來探索任意兩點特征之間的全局依賴關系,增強特征的表達能力,有助于恢復圖像的紋理細節。本文的自注意力模塊由自注意力支路和主干支路組成:主干支路利用卷積操作對特征進行提取,獲取更高層的特征;自注意力支路被設計為明確地學習一個像素與所有位置之間的關系,使得相似的特征相互關聯,有效地抓取特征的全局依賴關系。最后,將兩個支路的特征進行相加融合,輸出最終的細精度高分辨率圖像。實驗結果表明,與SRCNN[4]、VDSR[6]、LapSRN[8]、CNF[7]等相比,本文所提出的網絡超分辨率重建效果不管是客觀評價標準還是主觀視覺效果上都要更好。
1 基于自注意力網絡的超分辨率重建模型
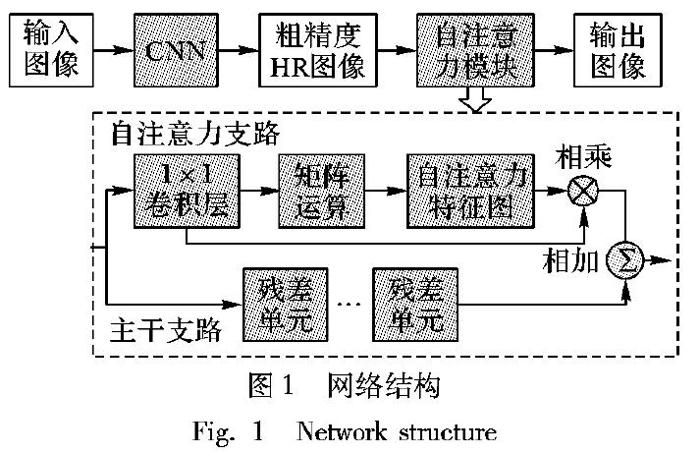
本文所設計的模型是基于一種從粗到細的逐步優化圖像精度的方法,使得圖像的質量可以更好地重建邊緣和紋理。本文的網絡結構由兩個重建階段組成,如圖1所示。第一階段以原始的低分辨率圖像作為輸入,經過一個由殘差單元構成的CNN進行初始預測,經過上采樣操作輸出一個粗精度的HR圖像。
第二階段以第一階段的輸出作為自注意力模塊的輸入,逐漸細化圖像質量。其中,輸入的圖像分別進入到自注意力模塊中的主干支路和自注意力支路,通過相加對兩條支路進行融合,從而得到最終的細精度HR圖像。
在第一階段中,直接以LR圖像作為輸入,不需要插值放大的預處理過程,能減少計算量。CNN包含10個殘差單元,每個殘差單元包括2個卷積核大小為3×3的卷積層,每個卷積層產生64個特征圖,然后緊接著修正線性單元(Rectified Linear Unit,ReLU)激活函數。采用反卷積層來實現上采樣操作,反卷積層的核大小為5×5,通過設置不同的步長來實現不同尺度大小的上采樣。
在第二階段中,主干支路也由幾個殘差單元組成,以提取高層次的特征。自注意力支路首先應用卷積層來獲得降維的特征,然后生成自注意力矩陣,該矩陣模擬特征的任意兩個像素之間的依賴關系;接下來,在注意力矩陣和原始特征之間執行乘法運算,以獲得反映全局背景的最終表示;最后,融合兩支路的高層特征和自注意力特征,以獲得恢復更多高頻細節的重建圖像。
2 自注意力模塊設計
自注意力模塊由自注意力支路、主干支路和特征融合組成。自注意力支路旨在探索特征之間的全局依賴關系,主干支路則提取更深層次的特征,然后將二者特征進行融合來增強特征的表達能力,實現圖像高質量的紋理細節恢復。
2.1 自注意力支路
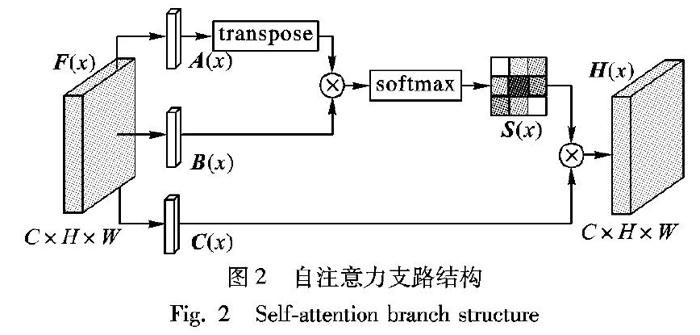
恢復出邊緣和紋理等高頻信息對超分辨率重建是至關重要的問題,旨在捕捉更加全局的特征。在特征表示中為了模擬豐富的上下文依賴關系,本文引入了自注意力機制[13]。自注意力支路將廣泛的上下文信息編碼為局部特征,使其更具全局性,從而增強特征的表達能力。因此,將自注意力模塊引入網絡中有望更好地恢復紋理等細節。
本文的自注意力支路的結構如圖2所示。特征 F (x)∈ R C×H×W來自于第一階段的輸出,首先將其送入伴隨著激活函數ReLU的1×1卷積層,分別生成三個新的特征圖 A (x)、 B (x)和 C (x)。然后將通過一個轉置矩陣的 A (x)與 B (x)進行矩陣乘法操作,并且應用一個softmax層來計算注意力特征 S (x):
Sj,i=exp(Ai,Bj) / ∑ N i=1 exp(Ai,Bj)
(1)
其中:N為整個位置空間,Sj,i表示第i個位置對第j個位置的影響。兩個位置的特征之間越相似,其響應值越大,它們之間的關聯性就越大。在此之后,將特征 C (x)與轉置后的注意力特征 S (x)執行一個矩陣乘法操作,得到最終自注意力支路的輸出 H (x)∈ R C×H×W:
H (x)= C (x) S (x)
(2)
從式(2)中可以知道,自注意力特征 H (x)表示所有位置的特征,因此,它具有全局上下文信息,當與主干支路輸出的高層特征融合時,可以根據自注意力特征選擇性地聚集上下文信息。總的來說,自注意力模塊通過學習所有位置的特征之間的聯系使得相似的特征相互關聯,可以輕松捕捉到更加全局的特征,全局特征的加入能幫助恢復更多的紋理細節。
2.2 殘差單元
本文所使用的殘差單元結構,如圖3所示。
該殘差單元包括兩個ReLU和兩個核大小為3×3的卷積層,具有預激活結構的殘差單元可以表示為:
x u= F ( x u-1, W u)+ x u-1
(3)
其中:u(u=1,2,…,U)是殘差單元的數量, x u-1和 x u分別是第u個殘差單元的輸入和輸出, W 代表著權重, F 表示殘差映射。預激活結構[14]在卷積層之前執行激活函數,預激活版本比激活后版本更容易訓練并產生更好的性能。此外,不同于原始的殘差網絡中的殘差單元,本文將批量歸一化層移除[15],目的是為了保持網絡之間的靈活性,避免得到的圖像過于平滑。因此,所設計的殘差單元有利于學習高度復雜的特征,并且在訓練期間有助于進行梯度反向傳播,不易產生過擬合。本文的殘差單元隨著網絡層數的增加來提升性能,且與沒有殘差連接的網絡相比更容易收斂。同時殘差單元的設計也緩解了梯度爆炸/梯度消失等問題。
3 實驗結果與分析
本文實驗使用DIV2K數據集[16]作為訓練集,它是一種新提出的高質量數據集。DIV2K數據集由800個訓練圖像組成,包括100個驗證圖像和100個測試圖像。訓練圖像被分成41×41大小的子圖像,步長為41。為了方便與其他算法比較,本文的測試集由Set5、Set14和BSDS100組成,分別有5、14、100張圖片。
本文實驗通過Adam優化方法對網絡進行訓練。利用“步長”(step)策略調整學習率,初始學習率權重base_lr為lE-5,調整系數gamma為0.5,最大迭代次數為1000000。此外,本文設置動量參數為0.9和權重衰退為lE-4。網絡訓練在雙顯卡為P4000 8GB的計算機上。
為了探究自注意力對SASR-Net網絡的影響,本部分將與移除了自注意力支路的超分辨率網絡(Network for images Super-Resolution, SR-Net)網絡進行比較,實驗結果如圖4、5所示。圖4是兩個網絡在重建倍數為3
的Set5數據集上的峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)比較,可以看出這兩個網絡都較快收斂,SASR-Net的峰值信噪比SR-Net大約高0.3dB。在圖5中,SASR-Net和SR-Net的圖像視覺效果比其他方法更清晰,而且SASR-Net的PSNR比VDSR高出0.16dB。從圖5(h)中可以看出,與其他算法相比,SASR-Net在蝴蝶翅膀紋理上的處理更好,重建出更多符合原始圖像圖5(b)的細節。這也就說明了自注意力可以增強特征的表達能力,捕捉到更為全局的特征,恢復出更多的高頻細節信息。
將本文提出的SASR-Net與現有的五種超分辨率方法如Bicubic[17]、SRCNN[4]、VDSR[6]、CNF[7]和LapSRN[8]進行對比,并利用峰值信噪比(PSNR)和結構相似度(Structual Similarity, SSIM)兩種廣泛使用的圖像質量指標對重建結果進行評估,同時比較重建倍數分別為2、3、4等不同尺度的性能,結果如表1所示。從表1可以看出,SASR-Net在Set5和BSDS100上的PSNR、SSIM均超過了其他超分辨率方法;雖然CNF在Set14上PSNR的值比SASR-Net略高,但在SSIM上SASR-Net都比其他超分辨率方法高;而且從圖6(e)中可以看出,與圖6(d)的視覺效果相比,本文方法的整體視覺效果更好,花瓣上的點恢復得更為清晰。圖7所示為BSDS100上重建倍數為4的視覺效果圖,與其他算法相比,不僅PSNR提高了0.05~1.2dB,SSIM也提高了0.006~0.116;而且從圖7(e)和圖7(f)中可以看出,VDSR以及LapSRN重建結果過于模糊和平滑,與其他超分辨率方法相比,SASR-Net重建木橋上的條紋更為清晰。大尺度重建質量不佳,也是由于高頻信息的不足引起的,而通過本文方法可以增強特征之間的全局依賴關系,恢復出更多紋理細節豐富的高質量圖像。
4 結語
本文提出了基于自注意力網絡的圖像超分辨率重建方法,將圖像精確度從粗到細逐步地恢復出高分辨率圖像。第一階段利用殘差單元構建的CNN來提升網絡性能,獲取到粗精度的高分辨率圖像;第二階段利用自注意力模型抓取任意兩點特征之間的關聯來增強特征的表達能力,恢復出更多的紋理細節來進一步細化粗精度的高分辨率圖像。實驗結果表明,自注意力能有效地捕捉特征之間的全局依賴關系,重建出更多的高頻信息。與其他超分辨率算法相比,本文方法不論是在主觀重建效果還是客觀評價標準上都有所提高的,重建出的圖像具有更高的質量并顯示更精細的細節。
參考文獻
[1]?DENTON E L, CHINTALA S, SZLAM A, et al. Deep generative image models using a Laplacian pyramid of adversarial networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 1486-1494.?[J]. Advances in Neural Information Processing Systems, 2015, 1(3): 1486-1494.
[2]?ILG E, MAYER N, SAIKIA T, et al. FlowNet 2.0: Evolution of optical flow estimation with deep networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 1647-1655.
[3]?HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 770-778.
[4]?DONG C, LOY C, HE K, at al. Image super-resolution using deep convolutional networks [J]// IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295-307.
[5]?DONG C, LOY C C, TANG X. Accelerating the super-resolution convolutional neural network [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Cham: Springer, 2016: 391-407.
[6]?KIM J, LEE J K, and LEE K M. Accurate image super-resolution using very deep convolutional networks [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 1646-1654.
[7]?REN H, EL-KHAMY M, LEE J. Image super resolution based on fusing multiple convolution neural networks [C]// Proceedings of the 2017 IEEE Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE, 2017: 1050-1057.
[8]?LAI W, HUANG J, AHUJA N, et al. Deep Laplacian pyramid networks for fast and accurate super-resolution [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 5835-5843.
[9]?ZHOU L, WANG Z, WANG S, et al. Coarse-to-fine image super-resolution using convolutional neural networks [C]// Proceedings of the 2018 International Conference on Multimedia Modeling, LNCS 10705. Cham: Springer, 2018: 73-81.
[10]??GLASNER D, BAGON S, IRANI M. Super-resolution from a single image [C]// Proceedings of the IEEE 12th Intermational Conference on Computer Vision. Piscataway, NJ: IEEE, 2009: 349-356.
[11]?SIMONYAN K, ZISSEMAN A. Very deep convolutional networks for large-scale image recognition [J]. arXiv E-print, 2015: arXiv:1409.1556.?[2018-02-11]. https://arxiv.org/pdf/1409.1556.pdf.
[12]?VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2017: 6000-6010.?[J]. Advances in Neural Information Processing Systems, 2017, 30(1): 6000-6010.
[13]?ZHANG H, GOODFELLOW I., METAXAS D, et al. Self-attention generative adversarial networks [J]. arXiv E-print, 2019: arXiv:1805.08318.?[EB/OL]. [2018-02-11]. https://arxiv.org/pdf/1805.08318.pdf.
[14]?HE K, ZHANG X, REN S, et al. Identity mappings in deep residual networks [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9908. Cham: Springer, 2016: 630-645.
[15]?NAH S, KIM T H, LEE K M. Deep multi-scale convolutional neural network for dynamic scene deblurring [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 257-265.
[16]?AGUSTSSON E, TIMOFTE R. NTIRE 2017 challenge on single image super-resolution: dataset and study [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE, 2017: 1122-1131.
[17]?KEYS R. Cubic convolution interpolation for digital image processing [J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1981, 29(6): 1153-1160.
[18]?孫旭,李曉光,李嘉鋒,等.基于深度學習的圖像超分辨率復原研究進展[J].自動化學報,2017,43(5):697-709. (SUN X, LI X G, LI J F, et al. Review on deep learning based image super-resolution restoration algorithms [J]. Acta Automatica Sinica, 2017, 43(5): 697-709.)
