多噪聲環境下雙微陣列語音增強算法
2019-10-23 12:23:56羅瀛曾慶寧龍超
計算機應用 2019年8期
羅瀛 曾慶寧 龍超

摘 要:為提高雙微陣列語音增強系統在多噪聲環境下的消噪性能,提出一種適用于雙微陣列的改進廣義旁瓣抵消器語音增強算法。根據雙微麥克風陣列的結構特點,首先,用基于噪聲互功率譜估計的改進相干濾波算法消除距離較遠麥克風之間產生的弱相關噪聲;然后,利用廣義旁瓣抵消算法消除距離較近麥克風之間產生的強相關噪聲;最后,通過基于最小值控制遞歸平均的子帶譜減法有針對性地消除不同頻帶上的殘留噪聲。仿真實驗表明,在多噪聲環境下所提算法較現有的雙微陣列語音增強算法取得了更好的感知語音質量評價得分,一定程度上改善了雙微陣列語音增強系統對復雜噪聲的抑制效果。
關鍵詞:雙微陣列;噪聲互功率譜估計;廣義旁瓣抵消器;最小值控制遞歸平均;子帶譜減
中圖分類號:?TN912.35
文獻標志碼:A
Dual mini micro-array speech enhancement algorithm under multi-noise environment
LUO Ying, ZENG Qingning*, LONG Chao
Ministry of Education Key Laboratory of Cognitive Radio and Information Processing (Guilin University of Electronic Technology), Guilin Guangxi 541004, China
Abstract:?In order to improve the denoising performance of dual mini micro-array speech enhancement system in multi-noise environment, an improved generalized sidelobe canceller speech enhancement algorithm for dual mini micro-array was proposed. According to the structure characteristics of the dual mini micro-array, firstly, an improved coherent filtering algorithm based on noise cross-power spectrum estimation was used to eliminate the weak correlation noise between microphones with long distances. Secondly, the strong correlation noise between microphones with short distances was eliminated by using a generalized sidelobe cancelling algorithm. Finally, the minima-controlled recursive averaging based sub-band spectrum subtraction was used to eliminate the residual noise in different spectrum bands purposefully. Experimental results show that the proposed algorithm achieves better score in perceptual evaluation of speech quality than existing dual mini micro-array speech enhancement algorithms under multi-noise environment, and improves the suppression effect of dual mini micro-array speech enhancement system on complex noise to a certain extent.
Key words:?dual mini micro-array; noise cross-power spectrum estimation; generalized sidelobe canceller; minima-controlled recursive averaging; multi-band spectral subtraction
0 引言
在實際環境中,目標語音存在于多種噪聲混合的噪聲環境中,多噪聲環境嚴重影響目標語音的獲取。在實際應用中,譜減[1]、維納濾波[2]、最小均方誤差估計[3]等傳統的單通道語音增強方法會受到各種不同場景的限制,同時還會造成一定程度的語音失真。基于麥克風陣列[4]的語音增強方法能同時利用時域和空域信息來有效消除噪聲,這使得其應用場合更為廣泛,在應用于助聽器及移動通信設備時都具有較好的效果。
廣義旁瓣抵消器(Generalized Sidelobe Canceller, GSC)[4]是一種能較好抑制相關噪聲的麥克風陣列語音增強算法,但由于GSC算法在消除弱相關噪聲時的效果依賴于陣列的陣元數量及陣元間距,因此應用于小型及微型麥克風陣列時不能有效地消除較近陣元間的弱相關噪聲。相干濾波(Coherence Filtering, CF)算法[5]在抑制弱相關噪聲時具有良好的效果。文獻[6]提出了一種基于相干濾波與GSC相結合的小麥克風陣列語音增強方法,對多噪聲環境下的噪聲消除有一定的效果。文獻[7]提出了一種基于雙微陣列的語音增強算法。雙微陣列的結構如圖1所示,麥克風M1和M2、M3和M4分別構成雙微陣列中的兩個子陣,兩個子陣的間距為16cm,子陣中的兩個麥克風間距為2cm。文獻[7]中先用譜修正濾波器對雙微陣列子陣中的兩個距離為2cm的麥克風接收的信號進行增強,生成4路增強信號作為GSC的輸入,通過GSC進一步消除相干噪聲后再用調制域譜減法消除殘留噪聲。通過在white噪聲、f16噪聲等單一噪聲環境的仿真實驗驗證了該算法具有較好的消噪性能。但在雙微陣列中,兩個距離較近麥克風中的噪聲呈現強相關性,而距離較遠麥克風中的噪聲呈現弱相關性[8-9],文獻[7]所提出的算法選擇子陣中距離較近的兩個麥克風進行譜修正濾波,不能較好地解決距離較遠麥克風產生的弱相關性噪聲消除問題。同時,在多噪聲混合的環境下,通過GSC增強后的信號的殘留噪聲在不同頻帶上的分布并不均勻,調制域譜減法不能針對性地對各頻帶上的殘留噪聲進行消除。
本文根據雙微陣列中麥克風的排列特點,提出一種適用于多噪聲環境下的雙微麥克風陣列語音增強算法。首先分別對距離較遠的四組麥克風M1和M3、M4,M2和M3、M4采用基于噪聲互功率譜估計的改進相干濾波算法消除弱相關噪聲,然后將4路增強信號作為輸入,通過GSC算法消除強相關噪聲,最后采用基于最小值控制遞歸平均的子帶譜減法對不同頻帶上的殘留噪聲進行有針對性的消除。
1 本文算法框架
圖2是本文算法的原理框圖,y1、y2、y3、y4分別代表麥克風M1、M2、M3、M4所采集到的信號。用y1和y3、y4,y2和y3、y4分別進行改進互功率譜估計的相干濾波,得到GSC的四路輸入信號yout_13、yout_14、yout_23、yout_24。
經過GSC增強后的信號YGSC_out再采用最小值控制遞歸平均(Minima Controlled Recursive Averaging, MCRA)子帶譜減抑制殘留噪聲后得到最終的輸出Ymcra_out。
2 改進互功率估計的相干濾波
Jeannès等[10]提出利用帶噪語音互功率譜減去噪聲估計互功率譜的方法以改進相干濾波器,因此噪聲互功率譜估計的準確性決定了改進相干濾波器的消噪性能。本文在最小跟蹤噪聲功率譜估計算法[11]的基礎上,對最小跟蹤算法進行改進并用以估計含噪語音的噪聲互功率譜。其基本原理如圖3所示。
首先對分別來自不同子陣的兩路麥克風采集到的信號yi和yj進行分幀和傅里葉變換,接著通過基于互功率譜譜減的相干濾波函數式(1)對帶噪語音進行增強。
H(k,l)= ?| PYiYj(k,l) | - | PNiNj(k,l) | ??PYiYi(k,l)PYjYj(k,l)
(1)
其中:PYiYi(k,l)表示通道i帶噪語音信號的自功率譜密度;PYjYj(k,l)表示通道j帶噪語音信號的自功率譜密度;PYiYj(k,l)表示通道i和通道j帶噪語音信號之間的互功率譜密度;PNiNj(k,l)表示通過改進最小跟蹤算法估計得到的噪聲互功率譜密度。
為計算噪聲互功率譜密度估計,首先需要對帶噪語音信號互功率譜PYiYj(k,l)進行平滑:
PYiYj(k,l)= 0.7×PYiYj(k,l-1)+0.3×Yi(k,l)Y*j(k,l)
(2)
接著引入平滑因子λ(k,l)對噪聲互功率譜密度進行估計:
P?? ^?? NiNj(k,l)= λ(k,l)PNiNj(k,l-1)+(1-λ(k,l))Yi(k,l)Y*j(k,l)
(3)
本文提出一種基于先驗信噪比SNR(k,l)的平滑策略,通過各個頻帶k上的信噪比來更新平滑因子λ(k,l)以便及時地跟蹤噪聲互功率譜。平滑因子的計算方式為:
λ(k,l)=0.96-0.3? G(k,l) 1+G(k,l)
(4)
其中G(k,l)表示信噪比參數,通過帶噪語音信號的先驗信噪比得到:
G(k,l)=exp(min(0.66×SNR(k,l)-1,200))
(6)
帶噪語音信號的先驗信噪比由當前幀互功率譜密度估計 | PYiYj(k,l) | 與前一幀的噪聲互功率譜密度估計 | PNiNj(k,l-1) | 的比值求得:
SNR(k,l)= | PYiYj(k,l) | ?/ ?| PNiNj(k,l-1) |
(7)
計算出噪聲互功率譜密度初值P?? ^?? NiNj(k,l)后再利用一個長度為D幀的窗口搜索該窗長內的局部最小噪聲互功率譜Pmin(k,l):
Pmin(k,l)= (P?? ^?? NiNj(k,l),P?? ^?? NiNj(k,l-1),…,P?? ^?? NiNj(k,l-D+1))
(8)
由于Pmin(k,l)總小于噪聲平均值,因此需要利用無偏因子Bmin(k,l)對Pmin(k,l)進行補償。Bmin(k,l)與搜索窗長D有關。本文算法中D的取值為150。噪聲互功率譜估計PNiNj(k,l)最終通過式(9)計算得到。
PNiNj(k,l)=Pmin(k,l)Bmin(k,l)
(9)
最后經過改進互功率估計的相干濾波后,輸出一路增強信號yout_ij。
3 廣義旁瓣抵消器
廣義旁瓣抵消器基于線性約束最小方差(Linearly Constrained Minimum Variance, LCMV)條件提出,其結構由上通道模塊的約束部分與下通道模塊的阻塞矩陣組成。圖4是GSC的簡易原理圖。上通道主要作為參考信號,利用固定波束形成器對改進噪聲互功率譜估計的相干濾波結果 Y OUT(n)=[yout_13,yout_14,yout_23,yout_24]進行初步增強得到增強信號Yd(n):
Y d(n)= Y OUT(n) W T
(10)
其中 W T=[w1,w2,w3,w4]為固定波束形成器的權值向量。
參考噪聲 D (n)由下通道的阻塞矩陣 B 與噪聲互功率譜估計的相干濾波結果獲得:
D (n)= Y OUT(n)· B
(11)
其中 B 是滿足約束條件 B · 1 = 0 的3×4維矩陣。使用歸一化最小均方算法迭代得到噪聲估計值 D c(n),同時利用語音活動檢測(Voice Activity Detector, VAD)技術在非語音段更新濾波器系數:
D c(n)= D (n)· C
(12)
其中 C 是由自適應算法得到的歸一化最小均方權值系數。最后GSC的輸出為:
Y GSC_out(n)= Y d(n)- D c(n)
(13)
4 MCRA子帶譜減
MCRA算法[12]在平穩及非平穩噪聲環境中都能有較好的魯棒性,并且在噪聲急劇變化時能快速跟蹤噪聲。其噪聲功率譜估計由式(14)可得:
λ ??^?? d(k,l)=? d(k,l)λ ??^?? d(k,l-1)+[1- d(k,l)] | Y(k,l) | 2
(14)
其中:λ ??^?? d(k,l)表示在第l幀語音,第k個頻點處噪聲的功率譜估計; | Y(k,l) | 2表示在此處帶噪語音信號的功率譜。平滑參數 d(k,l)由式(15)計算得到。
d(k,l)=αd+(1-αd) (k,l)
(15)
其中:αd是固定常數,本文中αd的取值為0.95; (k,l)為語音存概率,
通過式(16)進行遞歸平滑得到,其中平滑參數為αp=0.2。
(k,l)=αp (k,l-1)+(1-αp)p(k,l)
(16)
p(k,l)表示語音是否存在:
p(k,l)= 1,?? Sr(k,l)>δ0, Sr(k,l)≤δ
(17)
將Sr(k,l)與一閾值δ進行比較,本文中δ的值設為5,當Sr(k,l)>δ時認為語音存在,p(k,l)=1;
當Sr(k,l)≤δ時認為語音不存在,p(k,l)=0。Sr(k,l)通過式(18)計算:
Sr(k,l)=S(k,l)/Smin(k,l)
(18)
其中:S(k,l)=αsS(k,l-1)+(1-αs)Sf(k,l),本文中αs取0.8,Sf(k,l)表示當前幀頻點k處一定范圍相鄰頻點的平均值;Smin(k,l)表示當前幀頻點k處帶噪語音功率譜的最小值。
本文將MCRA算法作為子帶譜減中的噪聲功率譜估計方式,同時將帶噪語音的頻譜劃分為6個相互不重疊的子頻帶,利用帶噪語音各頻帶上不同的子帶信噪比值來計算獨立的過減因子。基于MCRA的子帶譜減法[13-14]計算公式可以表示為:
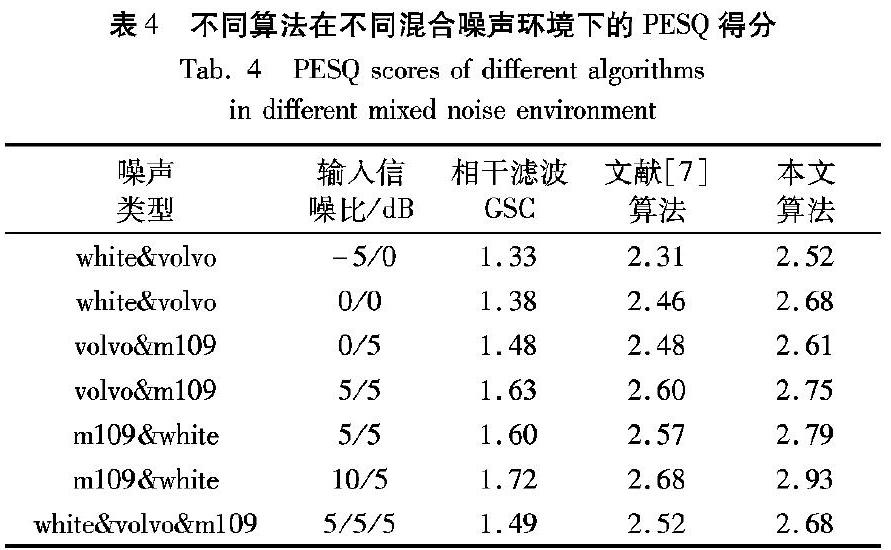
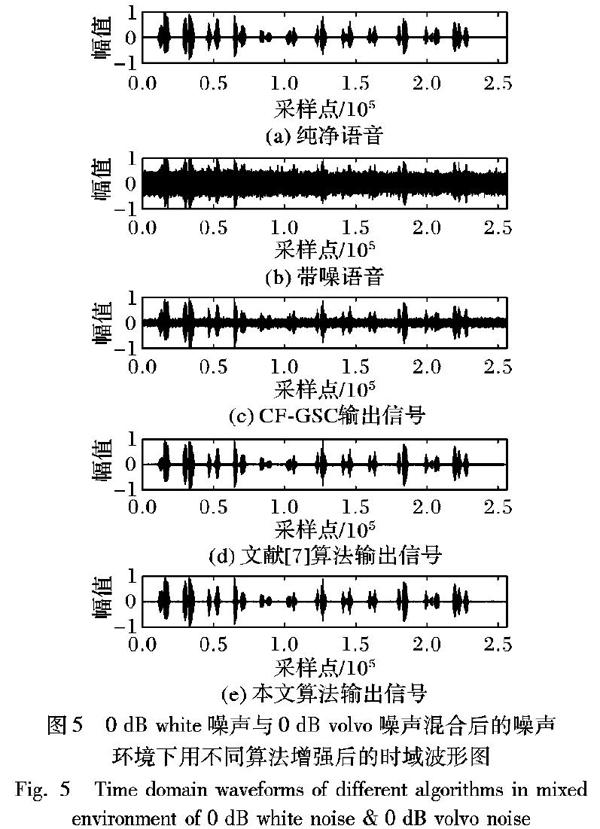
| X?? ^?? i(ω) | 2=
| Y?? ^?? i(ω) | 2-αiδi | Di(ω) | 2; bi<ω (19) 其中: | Y?? ^?? i(ω) | 2為頻帶i上帶噪語音功率譜; | Di(ω) | 2表示頻帶i上MCRA噪聲功率譜估計; | X?? ^?? i(ω) | 2表示頻帶i上對純凈語音功率譜估計;bi表示頻帶的起始點,bi+1表示頻帶的截止點;αi和δi分別是頻帶i的過減因子和減法因子。頻帶i上的子帶信噪比SNRi由帶噪語音功率譜和噪聲功率譜估計通過式(20)確定: SNRi=10lg ?∑ bi+1 bi ?| Yi(ω) | 2 ∑ bi+1 bi ?| Di(ω) | 2 (20) αi由子帶信噪比SNRi通過式(21)計算得: αi= 5,???????? SNRi<-5 4-3/20*SNRi, -5≤SNRi≤20 1, SNRi>20 (21) 減法因子δi為子帶譜減法中各子帶譜減權重控制提供更大的靈活性。δi的值通過式(22)確定: δi= 1,???? fi≤1kHz 2.5, 1kHz 1.5, fi> Fs 2 -2kHz (22) 其中: fi表示第i個子帶頻率的上界; Fs為語音采樣頻率。其中低頻帶和高頻帶譜減較為緩和以最小化語音失真。 當譜減后的功率譜出現負值時,純凈語音信號功率譜估計 | X?? ^?? i(ω) | 2由頻譜乘系數b和帶噪語音信號功率譜相乘的乘積得到: | X?? ^?? i(ω) | 2= | X?? ^?? i(ω) | 2,?? ?| X?? ^?? i(ω) | 2>0 b* | Yi(ω) | 2, ?| X?? ^?? i(ω) | 2≤0 (23) 頻譜乘系數b取0.002。 本文于廣義旁瓣抵消器的輸出端采用MCRA子帶譜減進一步對殘留噪聲進行消除。 5 實驗結果及分析 本文利用KEMAR人工頭設備與M-AUDIO多路音頻采集器采集實驗數據,語音和噪聲在同環境下錄制,噪聲源使用Noisex-92數據庫中的部分噪聲。錄制的純凈語音文件和噪聲文件都包含不同麥克風采集的4路子信號。用于實驗的帶噪語音文件是將一種或多種噪聲文件按照一定的信噪比混入純凈語音文件相對應的子信號中生成。帶噪語音文件同樣包含4路子信號。所有實驗均在Matlab仿真環境下進行。 首先,通過本文提出的改進互功率估計的相干濾波算法與譜修正濾波算法進行對比實驗,來驗證該算法對弱相關噪聲的抑制效果。實驗采用一段時長為5s左右,加入了不同信噪比(-5dB、0dB、5dB)單一噪聲類型(volvo噪聲、white噪聲)的帶噪語音文件。提取帶噪語音文件中間距較遠、所含噪聲呈弱相關性的兩個麥克風M1和M3采集的子信號作為參考輸入。經過兩種不同算法增強后的語音通過信噪比(Signal-to-Noise Ratio, SNR)來對噪聲抑制效果進行對比。表1是譜修正濾波及改進互功率估計的相干濾波算法增強后的輸出信噪比。 通過表1對比兩種算法的輸出信噪比可以看出,在輸入信噪比小于5dB時,改進互功率估計的相干濾波算法增強信號的輸出信噪比譜修正濾波算法增強信號更高,這說明改進互功率估計的相干濾波算法對弱相關性噪聲的抑制效果更好。 接著通過對比文獻[7]算法GSC增強信號,及本文算法GSC增強信號的消噪效果,以驗證本文算法對GSC性能的改進。實驗采用一段時長為5s左右,加入了不同信噪比(-5dB、0dB、5dB)多種噪聲類型(volvo噪聲、m109噪聲、white噪聲)的帶噪語音文件。兩種算法GSC增強后的信號同樣通過信噪比對噪聲的抑制效果進行比較,結果如表2所示,其中輸入SNR-5/0表示第一類噪聲輸入信噪比為-5dB,第二類噪聲輸入信噪比為0dB。 文獻[7]提出的算法中兩次對帶噪語音的增強都主要針對雙微陣列陣元相互之間的強相關噪聲,對弱相關噪聲的抑制能力有所不足,而本文算法則對強相關噪聲及弱相關噪聲都有較好的抑制效果。通過表2中GSC增強信號輸出SNR的對比可以看出,本文算法有更好的消噪性能。 在多噪聲環境下,本文算法GSC輸出端仍殘留著一些噪聲,且這些噪聲在各頻帶上分布較不均勻,因此需要有針對性地消除這些殘留噪聲。本次實驗將調制域譜減法及本文提出地基于MCRA的子帶譜減法對殘留噪聲的抑制效果進行比較。增強后的信號采用分段信噪比(Segmental Signal-to-Noise Ratio, SSNR)[15]來評測殘留噪聲抑制效果。表3是經過不同算法抑制殘留噪聲后信號的SSNR。 通過表3可以看出,在多噪聲環境下采用MCRA子帶譜減對GSC輸出信號的殘留噪聲抑制效果比調制域譜減法更好。 最后,通過比較相干濾波GSC算法、文獻[7]算法及本文算法對一段17s左右包含12個孤立詞的帶噪語音文件的增強效果,進一步驗證本文算法的有效性。帶噪語音文件中混入了不同信噪比(-5dB、0dB、5dB、10dB)多種類型的噪聲(volvo噪聲、m109噪聲、white噪聲)。本文通過感知語音質量評價(Perceptual Evaluation of Speech Quality, PESQ)[16]對語音增強效果進行衡量。PESQ算法得分與主觀評測方法平均意見得分(Mean Opinion Score,MOS)的相關程度達到097,能有效地通過客觀評價來模擬主觀評價,同時又避免了MOS打分中的主觀因素。 圖5是混合0dB白噪聲與0dB volvo噪聲的情況下,用相干濾波GSC算法、文獻[7]的算法及本文算法進行語音增強后的信號的時域波形對比。 從圖5中可以看出:與相干濾波GSC算法相比,本文算法的消噪效果提升明顯;同時與文獻[7]的算法相比,本文算法殘留噪聲更少,消噪效果有一定的提升。 表4是不同算法在不同混合噪聲環境下的PESQ得分,更為客觀地反映了不同算法消噪性能的優劣。 通過表4的仿真數據可以看出,在多噪聲混合的噪聲環境中,本文算法比相干濾波GSC算法及文獻[7]算法的消噪效果均有所提高。與相干濾波GSC算法相比,本文算法的PESQ得分提高了近1.2分,與文獻[7]所提出的算法相比較,本文算法的PESQ得分也提高了0.2分左右。這說明,利用雙微陣列在多噪聲環境下消噪時,采用本文算法比相干濾波GSC算法及文獻[7]的算法效果更好。 6 結語 本文根據雙微陣列模型的特點,提出了改進互功率估計的相干濾波結合GSC與MCRA子帶譜減的語音增強方法。通過對比實驗驗證了本文算法在多噪聲環境下對雙微陣列信號中的強相關噪聲、弱相關噪聲及非相關噪聲都有較好的消除效果。同時,本文算法也存在一些問題,與CF-GSC算法及文獻[7]提出的算法相比,本文算法計算量偏大。在Matlab仿真環境中,CF-GSC算法及文獻[7]的算法處理一段5s左右帶噪語音文件所需時間分別為3.5s和4.9s,而本文算法則需要9.7s。這主要是由于改進互功率譜估計相干濾波算法中互功率譜估計方式需要多次迭代計算導致的。因此本文算法的進一步的研究方向旨在尋找更為快速且有效的互功率譜估計方式以提高本文算法的計算速度。 參考文獻 [1]?BOLL S F. Suppression of acoustic noise in speech using spectral subtraction [J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1979, 27(2): 113-120. [2]?靳立燕,陳莉,樊泰亭,等.基于奇異譜分析和維納濾波的語音去噪算法[J].計算機應用,2015,35(8):2336-2340. (JIN L Y, CHEN L, FAN T T, et al. Speech denoising algorithm based on singular spectrum analysis and Wiener filtering [J]. Journal of Computer Applications, 2015, 35(8): 2336-2340.) [3]?PALIWAL K, SCHWERIN B, WóJCICKI K. Speech enhancement using a minimum mean-square error short-time spectral modulation magnitude estimator [J]. Speech Communication, 2011, 54(2): 282-305. [4]?李斌,張玲華.一種廣義旁瓣抵消器結構的語音增強改進算法[J].數據采集與處理,2017,32(2):307-313. (LI B, ZHANG L H. Improved speech enhancement algorithm with generalized sidelobe canceller [J]. Journal of Data Acquisition and Processing, 2017, 32(2): 307-313.) [5]?楊立春,錢沄濤.基于相干性濾波器的廣義旁瓣抵消器麥克風小陣列語音增強方法[J].電子與信息學報,2012,34(12):3027-3033. (YANG L C, QIAN Y T. Speech enhancement with generalized sidelobe canceller based on a coherence-based filter for small microphone arrays [J]. Journal of Electronics & Information Technology, 2012, 34(12): 3027-3033. [6]?馬金龍,曾慶寧,胡丹,等.基于麥克風小陣的多噪聲環境語音增強算法[J].計算機應用,2015,35(8):2341-2344. (MA J L, ZENG Q N, HU D, et al. Speech enhancement algorithm based on microphone array under multiple noise environments [J]. Journal of Computer Applications, 2015, 35(8): 2341-2344.) [7]?毛維,曾慶寧,龍超.基于雙微陣列的語音增強算法[J].計算機工程與設計,2018,39(8):2490-2494. (MAO W, ZENG Q N, LONG C. Speech enhancement algorithm based on dual-mini microphone array [J]. Computer Engineering and Design, 2018, 39(8): 2490-2494.) [8]?PARK J, KIM W, HAN D K, et al. Two-microphone eneralized sidelobe canceller with post-filter based speech enhancement in composite noise [J]. ETRI Journal, 2015, 38(2): 366-375. [9]?ZHANG M, WU S, GUO W, et al. A microphone array dereverberation algorithm based on TF-GSC and postfiltering [C]// Proceedings of the 2016 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting. Piscataway, NJ: IEEE, 2016: 1-4. [10]?JEANNS W L B, SCALART P, FAUCON G, et al. Combined noise and echo reduction in hands-free systems: a survey [J]. IEEE Transactions on Speech & Audio Processing, 2001, 9(8): 808-820. [11]?MARTIN R. Noise power spectral density estimation based on optimal smoothing and minimum statistics [J]. IEEE Transactions on Speech and Audio Processing, 2001, 9(5): 504-512. [12]?COHEN I, BERDUGO B. Noise estimation by minima con-trolled recursive averaging for robust speech enhancement [J]. IEEE Signal Processing Letters, 2002, 9(1): 12-15. [13]??KAMATH S, LOIZOU P C. A multi-band spectral subtraction? method for enhancing speech corrupted by colored noise [C]// Proceedings of 2002 IEEE International Conference on Acoustics, Speech and Signal Processing. Washington, DC: IEEE Computer Society, 2002, 4: IV-4164-IV-4164. [14]?李真,吳文錦,張勤,等.基于最大后驗相位估計的多帶譜減語音增強算法[J].電子與信息學報,2017,39(9):2282-2286. (LI Z, WU W J, ZHANG Q,et al. Multi-band spectral subtraction of speech enhancement based on maximum posteriori phase estimation [J]. Journal of Electronics & Information Technology, 2017, 39(9): 2282-2286.) [15]?DELLER J R, Jr., HANSEN J H L, PROAKIS J G. Discrete-Time Processing of Speech Signals [M]. Upper Saddle River, NJ: Prentice Hall, 2000: 127-167. [16]?RIX A W, BEERENDS J G, KIM D-S, et al. Objective assessment of speech and audio quality — technology and applications [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(6): 1890-1901.?Journal of the Audio Engineering Society, 2002, 50(10): 755-764.
