一種快速全局中心模糊聚類方法
2019-10-30 02:14:39孫冬璞譚潔瓊
哈爾濱理工大學學報 2019年4期
孫冬璞 譚潔瓊

摘 要:針對模糊C均值算法對初始中心敏感、容易陷入局部最優解,且算法迭代速度慢等問題,依據模糊聚類的全局中心理論,建立了一種快速全局中心模糊聚類系統模型,并給出了相關理論分析和算法流程。該模型通過DKC值方案對各數據成員進行密集度分析來確定初始質心,并結合AM度量提出自定義尋優函數,依據該函數在算法運行的每一個階段來逐一動態增加聚類中心,直至算法收斂。通過實驗對比和驗證,該過程降低了隨機選取聚類中心對聚類結果的影響,跳出局部最優解,減少計算量,具有更高的聚類精度和更快的收斂速度。
關鍵詞:模糊聚類;全局中心;DKC;AM度量;噪聲點
DOI:10.15938/j.jhust.2019.04.019
中圖分類號: TP311
文獻標志碼: A
文章編號: 1007-2683(2019)04-0110-08
Abstract:In terms of the problems that the fuzzy C-means algorithm is sensitive to the initial center, easy to fall into the local optimal solution, and the algorithm iteration speed is slow, a rapid global center fuzzy clustering system model is established according to the global center theory of fuzzy clustering, and the relevant theoretical analysis and algorithm process is given. In the model, the initial centroid is determined by the DKC value scheme, and the self-defined optimization function is proposed based on the AM metric. According to this function, the cluster centers are dynamically added one by one to every stage of algorithm operation until the algorithm converges. Through experimental comparison and verification, the process reduces the influence of random selection of cluster centers on clustering results, and jumps out of local optimal solution, reduces computation, and has higher clustering accuracy and faster convergence speed.
Keywords:fuzzy clustering; global center; DKC; AM metric; noise point
0 引 言
模糊C均值聚類[1-2](fuzzy C means clustering,FCM)是眾多模糊聚類的代表,在傳統的硬聚類算法中,每一個數據成員只隸屬于一個類別[3],但在真實世界的數據集中,各成員對各自屬于哪一類往往沒有明顯的界限。而FCM算法在執行過程中,根據不同的隸屬度值,每個數據成員可以按照一定概率屬于多個類別,FCM通過迭代式爬山算法來尋找問題的最優解。然而,該算法具有一定的局限性,比如,對初始條件較為敏感[4],容易陷入局部最優,易受噪聲點影響,且聚類數目難以確定,算法執行速度慢等缺陷[5-6]。為此,國內外學者做了大量研究。有通過模擬自然進化過程的搜索最優解的方法,將遺傳算法引入模糊聚類[7-8],避免算法陷入局部最優解,但仍存在局部搜索能力較弱、容易陷入“早熟”等缺點。也有將模擬退火算法與FCM相結合,使算法具有較強的局部搜索能力[9],但模擬退火算法本身對全局搜索空間了解不多,運算效率不高。文獻[10]提出了一種非噪聲敏感性FCM算法(INFCM),取消了對隸屬度的限制條件,構建出一種增加了懲罰因子的目標方程,具有較好的魯棒性,但算法依然不能保證跳出局部極小值、取得全局最優解。文[11]提出了快速全局FCM聚類算法,雖然該方法在很多方面彌補了FCM算法的不足,改善了算法性能,但仍容易受噪聲點或孤立點的影響,且聚類精度低、速度慢等問題依然存在。
針對以上分析,本文提出將動態規劃的全局思想和改進聚類中心點選取方法結合,在動態增加聚類劃分并選取最佳聚類中心的過程中,通過計算所有數據對象的DKC值[12]確定樣本分布密集區域且排除稀疏區域,降低外圍孤立點的影響。同時,本文采用AM度量[13]來提高算法穩定性,并通過DKC值和AM度量所確定的自定義尋優函數尋找一個周圍數據對象點分布比較密集且距離當前已有聚類中心都比較遠的數據對象點作為下一個簇的最佳聚類初始中心,該函數綜合AM度量和DKC值兩者優勢,更能快速且準確的確定出最佳聚類中心,加快算法收斂速度。
1 相關工作
FCM聚類算法是一種基于目標函數優化的無監督數據聚類方法,即一個反復更新聚類中心及隸屬度從而使目標函數J最小化的過程,其工作原理是:隨機初始化c個數據對象作為初始聚類中心,分別計算剩余對象與該c個成員的歐氏距離,再根據距離值將所有對象按照一定概率依次分配給最近的聚類中心,得到隸屬度矩陣,分別計算新的類內成員平均值,再次更新聚類中心。將以上過程不斷重復至算法收斂,則聚類過程結束[14]。
FCM算法雖然應用廣泛、靈敏,卻存在對初始值敏感、易陷入局部最優的問題,為此,模糊聚類的全局思想應運而生。
全局模糊聚類算法不再隨機地為所有簇分別選取初始聚類中心,而是從一個簇的聚類問題開始,在算法每一次迭代過程中,試圖動態地添加一個新的聚類中心,具體做法是:從次數q=1開始,實現一個簇的聚類劃分,得到一個簇的最佳聚類中心;在尋找q=2簇劃分結果時,默認第一個聚類中心為上一次迭代過程得到的聚類中心,并通過數據集中剩余的每一個樣本作為第二個聚類中心的候選集合,然后用FCM算法對候選集合中的所有成員進行聚類,得到各自的聚類誤差平方和,最后選擇誤差平方和最小的數據點作為第二個最佳聚類中心。在q=2聚類結果的基礎上解決q=3的聚類劃分,以此類推,得到q=c個簇的聚類問題。應用全局思想的模糊聚類算法不再受初始點影響,有效地避免了陷入局部最優解的風險,提高了聚類精確度。
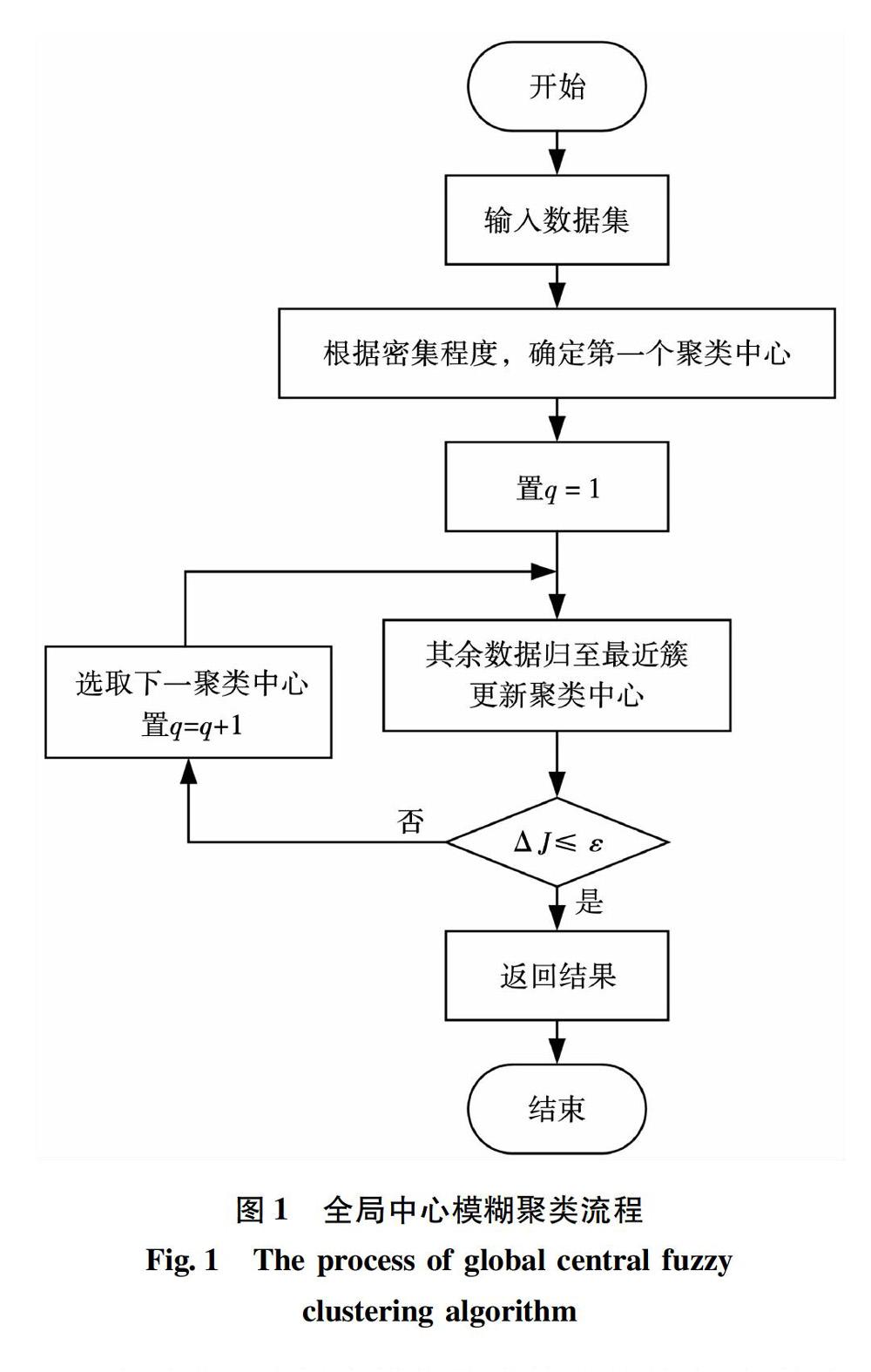
2 快速全局中心模糊聚類算法
2.1 算法的基本思想
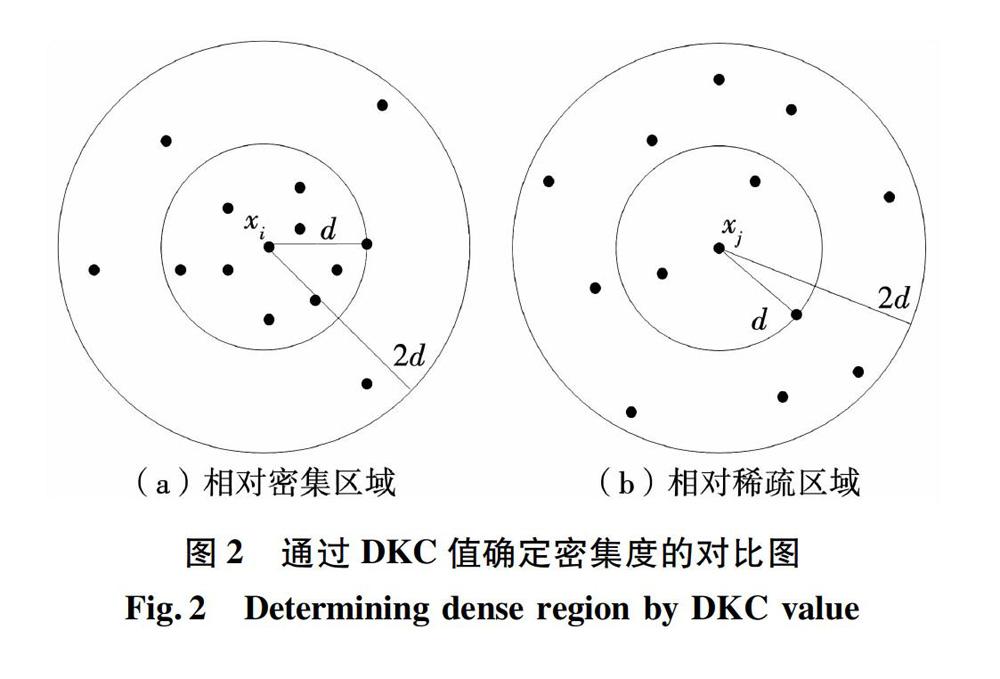
單純的全局模糊聚類算法依然沒有解決c值不確定的問題,且在聚類的每次劃分過程中都需要進行N(N為數據集合中對象總個數)次算法迭代,整個過程共需進行c×N次,導致算法的運行速度較慢,其直接原因是在確定下一聚類中心點的過程中,要將數據集合中的每一個數據對象都作為聚類中心候選點進行算法迭代測試。實際上,數據集的各個聚類中心一定會分布在樣本相對密集的區域,數據集合中的外圍孤立點、稀疏區域對象集就不可能成為最佳聚類中心備選點,故算法在選取下一聚類中心的過程中,無需將集合中所有數據對象都作為初始聚類候選中心進行測試運算,只要在樣本分布相對密集的區域尋找最佳聚類中心即可,故本文提出了一種確定樣本分布密集度的全局中心的模糊聚類算法,基本思想為:
1)計算密集度,確定初始中心點
通過計算數據集中所有對象的密集程度,選擇密集度最大的數據成員作為第一個聚類中心,并從質心備選集中刪除稀疏區域樣本點。
2)重新劃分數據對象,更新聚類中心
對于當前確定的聚類中心,將數據集中的所有數據對象分配到距離當前已有聚類中心最近的簇,并更新聚類中心。
3)判斷終止條件
前后兩次目標函數差值的絕對值ΔJ小于等于給定的某個閾值ε時,算法停止,返回結果。
4)選取下一個聚類中心
在質心備選集中按照某種自定義優化規則選擇下一個聚類中心,而不是把備選集中所有對象依次進行測試。
2.3 聚類中心的動態選擇
在傳統算法中,采用歐氏距離度量樣本之間的相似性,但歐氏距離的度量方式只對同尺寸、同密度、同形狀等相同信息且分布均勻的理想化數據具有穩定性。然而,現實數據往往都具有不同的特征,故歐氏距離度量方式使算法很容易受到外圍孤立點、噪聲點的影響,造成聚類結果的不穩定。本文在更新聚類中心和隸屬度的過程中,利用基于非歐氏距離度量方式—AM度量[13][16]的單調有界性降低外圍點或噪聲點對確定聚類中心過程的影響,來增強聚類算法的穩定性和魯棒性,并減少算法的迭代次數。
4 結 語
針對FCM聚類算法對初始聚類中心選取敏感,易受噪聲點影響,以及聚類最終結果容易陷入局部最優的問題,本文提出了ADGFCM算法,該算法采用全局中心聚類思想,結合DKC值與AM度量,并提出自定義尋優函數fi,全面考慮了所有數據對象點的分布情況,緩解對噪聲點敏感的問題。選取一個周圍數據對象分布比較密集,且距離現有聚類中心都比較遠的數據對象點作為下一個最佳聚類中心,不但使聚類結果趨于穩定,提高聚類精確度,而且減少了算法累加過程中的計算負擔,加快聚類速度,在一定程度上跳出局部最優。實驗結果表明,ADGFCM算法相比FCM算法和其他改進后的FCM算法精確度均有所提高,運行時間較短,聚類效果較為穩定,在實際數據集上有較好的應用價值。
參 考 文 獻:
[1] SANAKAL R, JAYAKUMARI T. Prognosis of Diabetes Using Data Mining Approach-fuzzy C Means Clustering and Support Vector Machine[J]. Int. J. Comput. Trends Technol.(IJCTT), 2014, 11(2): 94.
[2] LIU L, SUN S Z, YU H, et al. A Modified Fuzzy C-Means (FCM) Clustering Algorithm and Its Application on Carbonate Fluid Identification[J]. Journal of Applied Geophysics, 2016, 129:28.
[3] 吳明陽, 張芮, 岳彩旭,等. 應用K-means聚類算法劃分曲面及實驗驗證[J]. 哈爾濱理工大學學報, 2017(1):54.
[4] 武俊峰, 艾嶺. 一種基于改進聚類算法的模糊模型辨識[J]. 哈爾濱理工大學學報, 2010, 15(3):1.
[5] NAYAK J, NAIK B, KANUNGO D P, et al. A Hybrid Elicit Teaching Learning Based Optimization with Fuzzy C-means (ETLBO-FCM) Algorithm for Data Clustering[J]. Ain Shams Engineering Journal, 2016(5):148.
[6] FILHO T M S, PIMENTEL B A, SOUZA R M C R, et al. Hybrid Methods for Fuzzy Clustering Based on Fuzzy C-means and Improved Particle Swarm Optimization[J]. Expert Systems with Applications, 2015, 42(17):6315.
[7] PAN X, LIU P, REN M, et al. Optimization of fuzzy C-means based on OBL-genetic algorithm[C]//Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), 2016 12th International Conference on. IEEE, 2016: 109.
[8] YE A X, JIN Y X. A Fuzzy C-Means Clustering AlgorithmBasedon Improved Quantum Genetic Algorithm[J]. International Journal of Database Theory and Application, 2016, 9(1): 227.
[9] LIU P,DUAN L, CHI X, et al. An Improved Fuzzy C-means Clustering Algorithm Based on Simulated Annealing[C]//Fuzzy Systems and Knowledge Discovery (FSKD), 2013 10th International Conference on. IEEE, 2013: 39.
[10]陳加順, 皮德常. 一種非噪聲敏感性的模糊C均值聚類算法[J]. 小型微型計算機系統, 2014, 35(6):1427.
[11]WANG W, ZHANG Y, LI Y, et al. The Global Fuzzy C-means Clustering Algorithm[C]//2006 6th World Congress on Intelligent Control and Automation. IEEE, 2006, 1:3604.
[12]任培花, 王麗珍. 不確定域環境下基于DKC值改進的K-means聚類算法[J]. 計算機科學, 2013, 40(4):181.
[13]WU K L, YANG M S. Alternative C-means Clustering Algorithms[J]. Pattern Recognition, 2002, 35(10):2267.
[14]李遠成, 陰培培, 趙銀亮. 基于模糊聚類的推測多線程劃分算法[J]. 計算機學報, 2014, 37(3):580.
[15]謝娟英, 蔣帥, 王春霞,等. 一種改進的全局K-均值聚類算法[J]. 陜西師范大學學報:自然科學版, 2010,38(2):18.
[16]ZHANG Dao-qiang, Chen. A Comment on “Alternative C-means Clustering Algorithms”[J]. Pattern Recognition, 2004, 37(2):173.
[17]RASTGARPOUR M, ALIPOUR S, SHANBEHZADEH J. Improved Fast Two Cycle by using KFCM Clustering for Image Segmentation[J]. Lecture Notes in Engineering & Computer Science, 2012, 2195(1).
[18]AHMAD A,DEY L. A K-mean Clustering Algorithm for Mixed Numeric and Categorical Data[J]. Data & Knowledge Engineering, 2007, 63(2):503.
[19]BEZDEK J C. A Physical Interpretation of Fuzzy ISODATA[J]. IEEE Transactions on Systems Man & Cybernetics, 1976, 6(5):615.
[20]VANI H Y,ANUSUYA M A. Isolated Speech Recognition Using Fuzzy C Means Technique[C]// International Conference on Emerging Research in Electronics, Computer Science and Technology. IEEE, 2016:352-357.
(編輯:關 毅)
