面向云端的文件多層破碎混淆機制
2019-11-09 06:51:28唐成華李海東周江山強保華
小型微型計算機系統 2019年10期
唐成華,李海東,潘 然,周江山,強保華,
1(桂林電子科技大學 廣西云計算與大數據協同創新中心,廣西 桂林 541004) 2(廣西可信軟件重點實驗室,廣西 桂林 541004) 3(廣西密碼學與信息安全重點實驗室,廣西 桂林 541004)E-mail:tch@guet.edu.cn
1 引 言
作為一種新興的計算模式,云計算帶來了全新的巨量資源共享虛擬化技術,滿足于企業脫離IT基礎設施管理和維護,而專注于自身核心業務的發展.云計算成為當前信息領域的工業化革命,伴隨著其業務不斷普及和信息的爆炸式增長,云計算安全問題已逐漸得到人們的關注,并成為制約云計算發展的重要因素[1].2018年2月,Under Armour遭遇1.5億賬戶數據泄漏事件;3月,Facebook發生公司史上最大規模的個人信息泄漏事件,超過5000萬用戶信息遭到竊取;同年8月,華住旗下多個連鎖酒店開房信息數據在暗網出售,泄露數據總數接近 5億條.這些事件不斷警醒著人們,若要大規模應用云計算技術與平臺,必須解決云計算安全問題,特別是當前移動終端用戶使用先進的Wifi/5G網絡和云技術時,面臨高級持久威脅(APT)容易遭受被滲透到不同級別的云和移動基礎設施中以竊聽、竊取和修改數據[2],因此目前云端中的數據隱私安全保護研究極為重要.
針對云端的文件數據安全問題,研究者們提出了一些解決方案,主要有隱式切割和顯式加密等方式.對于上傳到云端的重要文件,通常是對文件進行加密處理,而當數據塊數量增多時,加密的效率變得低下,超過了用戶所能容忍的時間,因此,Parakh等[3,4]提出隱式數據安全及其改進方法,不需要使用加密機制,使得非授權用戶不能獲取文件內容.在此基礎上,毛劍等[5]對數據保護提出了二次混淆數據分割方案,在隱式數據分割的基礎上,對文件進行二次分割.對文件分塊的設置并非易事,并且可能會對性能產生重大影響,較大的塊可能包含用戶未請求的信息,較小的塊則可能需要更多的訪問請求,基于此考慮,Chung等[6]結合跟蹤技術提出了動態分區算法.史玉良等[7,8]提出隱私約束概念,通過隱私約束數量來調整數據塊數量的保護機制.張宏磊等[9]在隱私約束的基礎上,提出基于分塊混淆的動態數據隱私保護機制,同時提高云計算的安全性和應用的效率.Kauthale[10]和Mohammed[11]分別對差分隱私保護方案進行了改進,提出了兩段垂直劃分的隱私保護算法,將敏感屬性數據和非敏感屬性數據分開放置在不同的塊中.通常具有多個敏感屬性的數據更為常見,Wang等[12]分別采用聚類方法和主成分分析法將敏感屬性記錄劃分成組,基于k-匿名化過程實現隱私封閉化過程,但在原始信息保留上存在一定的弊端.Kapusta 等[13]分析了現有的分布式存儲系統,提出了分兩組進行碎片分塊的機制,一組解決存檔數據的需求,一組解決機密數據的存儲要求,從而避免了完全加密,提升了數據安全的處理效率.當然,存儲在云端的數據必須有完整性驗證機制[14].
上述文件數據分塊方法,可以在特定存儲環境和特定保密環境下實現文件切割.本文借鑒于此,針對云計算環境提出一種文件破碎混淆保護方案,即進行兩次文件切割,且只有一次加解密操作.在安全性得到保障的前提下,文件數據處理效率也得到了明顯提升.
2 基本概念
定義1.可接納容忍度ω,是指攻擊者在進行文件暴力破解時,個人可承受時間成本的最大值.時間成本具有不同的單位,本文規定時間成本的基準單位是秒(s).在實際破解過程中,攻擊者破解目標對象所需要消耗的時間存在一個容忍程度范圍.從心理學上來說,為了破解一個文件,攻擊者所能容忍的時間遠遠高于一個正常切割文件所有者所能容忍的時間.
例如,攻擊者為了破解一個重要文件,通過暴力破解需要等待的時間是30天,換算為基準單位為:2.59200×106s,那么ω=2.59200×106.如此同時,對于同一份文件,用戶所能容忍的時間成本可能是5秒之內.
定義2.文件密級Ψ,按照官方的定義,有狹義和廣義兩種,其中狹義的密級是指保密行政管理部門對于涉及國家秘密的訴訟和非訴訟案件,應辦案機關的要求,就案件中涉嫌涉密事項做出的鑒別和認定;廣義的密級是指保密工作部門對某一事項是否屬于國家秘密和屬于何種密級進行鑒別以及認定[15].
本文Ψ是指文件上傳者對該文件自定義的保護等級,規定Ψ的取值范圍為1-100,其中1表示最低等級,100表示最高等級.例如:用戶上傳一份公司的核心收購計劃,涉及的范圍和金額巨大,此時可以定義文件的等級為90級;若用戶只是上傳一份臨時的個人清單計劃,則可以定義文件的等級為5級.
定義3.算力η,是指計算機的運算能力,可表示為計算機運行一個程序或者應用所消耗的時間,也可表示為計算機在一秒鐘內能運行程序的次數.
按照最新公布的數據,目前全球最快的超級計算機是美國能源部下屬橡樹嶺國家實驗室的“Summit”,其峰值是每秒運行1.87659×1017次.參照超級計算機“頂點”的運行次數,定義最大算力為ηmax,則ηmax=1.87659×1017.
定義4.算力和密級、文件大小的關系,在實際應用中,使用ηmax的概率比較小,更多使用的是與ηmax呈現一定比例的實際算力η.
本文中認為當文件的大小較大時,需要切割塊數也較多,從而需要很高的算力去破解文件,當文件較小,切割塊數也較少,從而需要的算力較低;同時當文件密級程度很高時,也會需要很高的算力去破解文件,文件密級程度屬于中下時,需要的算力趨于一個平穩的值,由此定義實際算力的指數次冪和密級呈現凸函數的關系.通過定義Ψ的值和其對應的η,對這些定義的值進行支持向量機SVM處理,可以得到一個算力和密級、文件大小之間的函數關系,如公式(1)所示.
η=ηmax×100.00179×(Ψ,2-10,4-0.12849×δ)
(1)
定義5.文件破解效率ξ(n,Ψ,δ),是指文件在一個確定的容忍度ω、確定的文件大小的情況下,破解一個密級為Ψ、文件大小為δ,塊數為n的文件所需要的ω的個數,即需要達到多少個ω時,文件將會被攻擊者破解.
定義6.文件大小δ,是指文件實際需要切割的大小,本文規定文件大小的基準單位是k.
3 文件破碎保護
3.1 文件破碎混淆模型
為了保護云計算用戶的文件存儲安全,設計了一種文件破碎混淆模型保護方案,如圖1所示.該方案包含第一層文件切割、第二層文件切割和文件還原3個部分.其中第一層文件切割主要處理文件的分塊和文件的混淆;第二層文件切割處理文件的二次切割和文件的重新組合,形成新的不可識別的文件;文件還原主要是對第二層文件切割和第一層文件切割的操作進行還原,從而獲得原文件.
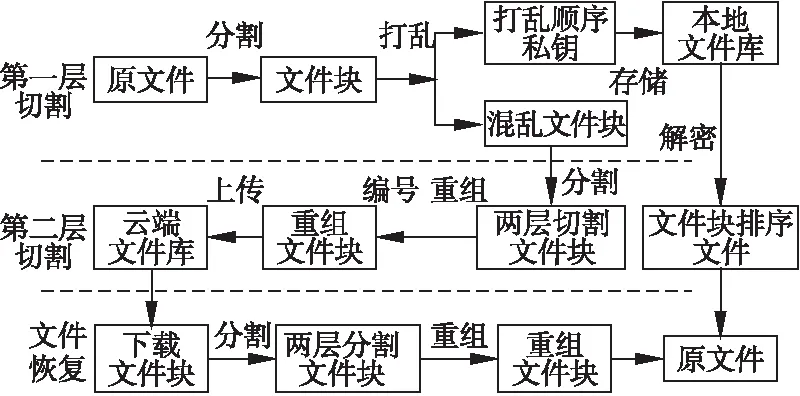
圖1 文件破碎混淆模型Fig.1 File fragmentation and obfuscation model
在第一層文件切割中,假定文件被切割成n塊,對已切割的n塊文件打亂其前后順序,同時形成打亂順序私鑰文件存儲在本地文件庫,以供在文件恢復階段能有效的恢復文件.由于切割后的文件需要存儲在云端,而云端的不可控性使得存儲在云端的文件安全性得不到保證,目前最常見的處理方式是對文件進行加密操作,若是對存儲在云端的每一塊文件都進行加密處理,會嚴重地影響到系統的效率.針對此問題,本方案對打亂順序私鑰文件進行加密處理,從而提升安全性,進而使得整個程序只需進行一次加密處理,以保證合理有效的處理效率.
當文件塊的切割數量較小時,通過暴力破解所消耗的時間Tn成本很低,所以為了確保在一定的時間范圍內,攻擊者不能通過排列組合的方式得到正確的文件塊順序,需要對文件切割數量有一定限制.定義暴力破解次數為g,則g與文件塊數量呈一定函數關系,如公式(2)所示.
g=n!
(2)
破解的次數由文件塊的數量決定,根據定義3,攻擊者要達到對應的破解次數,與攻擊者計算機的運行能力η有直接關系.根據定義2,用戶上傳文件的同時會設定一個Ψ,而對于不同Ψ的文件,要求的文件破碎時間成本不一樣,根據定義4,當給出一個確定的Ψ時,η的值也隨之確定,可得破解的時間成本為:
(3)
根據定義1,攻擊者會存在一個ω,我們以ω為一個基準,根據定義5,ξ(n,Ψ,δ)可以理解為存在有多少個ω基準,由此可以得出,ξ(n,Ψ,δ)為:
(4)
通過公式(2)、公式(3)和公式(4)可以得到:
(5)
根據定義4和定義6,將公式(1)帶入公式(5)中可得:
(6)
求解函數ξn,當n滿足公式(7)時,可得到一個最合理的切割數量.

(7)
3.2 破碎混淆算法
文件破碎混淆算法包含兩層切割過程.其中第一層文件切割包括兩個核心步驟:文件分塊和文件混淆.首先定義需要切割的文件f,假定文件需要被均勻的切割成n塊文件,為了能有效地恢復文件,需要對切割后的每一塊文件進行編號存儲,則切割后的文件塊為f1,f2,…,fn-1,fn.為了文件的安全,需要對每塊文件塊的編號位置進行隨機重排,確保每次上傳到云端的文件塊順序是隨機亂序的,通過公式(2)和公式(7)可以確定切割數量n.
文件第二層切割也包括兩個步驟:文件二次切割和文件重組.通過第一層對文件的切割和混淆,文件被切割為n個長度相等的塊f1,f2,f3,…,fn.二次切割時,對其中每一塊文件分別均分成m份,將這m份文件塊進行編號1,2…,m-1,m,定義為后續編號,總共得到n×m份文件塊.將第一層切割的文件塊以一維數組的形式表示,第二層切割的文件塊以二維數組表示.可得變化過程如公式(8)所示.
(8)
文件重組是對后續編號相同的文件塊合并到一起,重組形成一個新的文件塊,通過重組,將n×m份文件塊合并成m份文件塊,重組過程如公式(9)所示.
(9)
為了提高第二層文件破碎的安全性,在每份重組文件塊前附加上一個隨機字符.在文件塊數和打亂順序都被已知的情況下,攻擊者按照獲取的情報,仍然不能得到正確的破解文件.將隨機字符ln寫入重組文件塊中可得到最終的重組文件塊,如公式(10)所示.
{l1+f1,1,+f2,1+…+fn-1,1+fn,1}、{l2+f1,2,+f2,2+…+fn-1,2+fn,2}、…、{lM+f1,m+f2,m+…+fn-1,m+fn,m}
(10)
算法1.破碎混淆算法
Input:需要加密的文件file,密級值secretLevel,第二層切割的塊數secondNum
Output:加密的私鑰,經過破碎重組后的文件塊數組merge[]
Begin {
1.fileSize=file.length /*文件的大小*/
2.OptimalNumberOfCuts=FindOptimalNumberOfCuts(secretLevel)
/*FindOptimalNumberOfCuts函數表示尋找最佳切塊數量,OptimalNumberOfCuts表示取得切塊的數量*/
3.fileLength=fileSize / OptimalNumberOfCuts
/*fileLength表示每塊文件的大小*/
4.for i=0 to OptimalNumberOfCuts do
5. UpsetArrary=upset(arrary)
/*upset函數的作用是打亂順序,UpsetArrary表示已經打亂的數組文件,arrary表示未打亂的數組*/
6. fileEncrypt(UpsetArrary) /*對數組UpsetArrary加密*/
7. create(fileName,UpsetArrary)
/*創建文件塊,按照UpsetArrary數組的順序*/
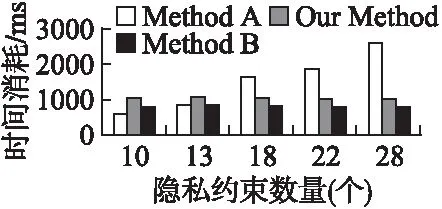
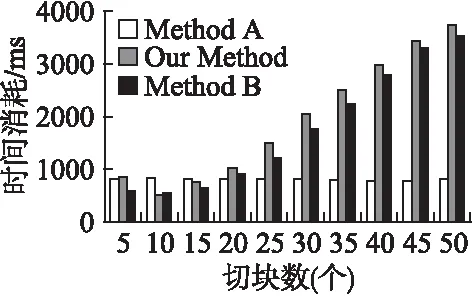
8. while(length 9. write(fileName) /*write給每塊文件寫入數據*/ 10.end for 11.savePrivateKey(file(PrivateKey),savePath) /*savePrivateKey函數保存私鑰文件,file(PrivateKey)函數表示形成私鑰文件,savePath表示存儲私鑰的本地地址*/ 12.ProcessBrokenFileBlock(fileName) /*處理切割打亂后的文件塊*/ 13.length=files.length /*經過破碎混淆算法后得到的文件塊數*/ 14.for i=0 to length do 15. filesSegmentation[]=secondSegmentation(files,secondNum) /*filesSegmentation表示經過二層切割后的文件塊數組,secondSegmentation函數表示對一個文件進行的二層分割*/ 16.allFilesBlock[][]= filesSegmentation /*allFilesBlock存儲所有經過兩層切割的文件塊*/ 17.end for 18.reorganizationFile[]= recorganization(allFilesBlock) /*reorganizationFile存儲的是重組后的數據塊,recorganization函數表示對數據塊進行重組*/ 19.} End 算法1以密級為基礎,借鑒二分插入排序思想,根據公式(7),取得文件切塊數量;采用一維數組的方式存儲打亂的文件塊編號,依據編號及切割長度,將文件寫入新生成的文件塊中,通過RSA非對稱加密算法加密數組編號,私鑰存儲在savePath中,第一層分割操作完成.第二層分割操作采用二維數組存儲二層切割文件,通過改變兩層循環的下標前后順序,從而達到對切割文件的重組. 文件經過破碎混淆后,其可用性也隨之消失,為了使合法用戶能方便迅捷地下載使用文件,需要能及時地對破碎后的文件進行恢復還原.重組后的文件塊進行文件上傳時,會根據重組文件塊的順序為每一個塊生成1個唯一的塊標識BLOCK_ID,文件通過云端下載后,會通過BLOCK_ID進行排序,同時實現完整性驗證.文件恢復算法流程如下: Step 1.從云端依次下載全部的m個文件塊,通過BLOCK_ID標識進行驗證,并實現對文件塊排序,再依次將每個文件塊中的首字母ln去掉; Step 2.對每塊文件進行n次切割,獲得n×m份文件塊;然后將后續編號相同的文件塊進行合并,從而得到n個重組的文件塊; Step 3.將本地存儲的打亂順序私鑰文件進行解密,獲得打亂對應的序號; Step 4.通過解密出來的序號對重組后的n個文件塊進行順序還原,將還原后的n個文件塊進行合并,最終得到一個完整的文件. 搭建一臺服務器作為云端服務器,配置為8核CPU Inter(R)Xeon(R)3.50GHz,8G內存,500G硬盤.系統采用Ubuntu16.04版本,數據庫采用5.5.25 MySQL Community Server(GPL),編程語言為java 1.8.0_101. 為了確定密級對算法效率的影響,本文實驗先統一文件大小為10M.根據本文算法方案,首先設計出程序.通過對文件進行密級假定,得出1-80grade所對應的時間消耗,為了使數據更具有可靠性和穩定性,采用對同一組密級進行20次重復試驗,從而可以得到1600組數據,通過K-means方法對數據進行篩選,消除問題數據,最終得出一個較穩定的1-80grade所對應的時間消耗. 采用與面向隱私保護的數據塊調整機制(Method A)[8],隱式數據分割機制(Method B)[5]算法進行對比.通過對Method A中實驗還原以及與實驗數據的對比,得到Method A隱私約束數量和時間消耗所對應數據;通過對Method B中方法進行試驗還原,得到切塊數和時間消耗所對應數據. 為了驗證本文文件破碎混淆算法的效果,分別對Method A、Method B,以及文件破碎混淆算法,通過在隱私約束數量、密級和切塊數三個不同維度進行3組模擬實驗. 圖2 隱私約束-時間消耗Fig.2 Privacy constraints-time consumption 實驗1.以隱私約束數量為維度進行,方法B中隱私約束數量對應的時間消耗采用的是其方法中切塊數頻率較高的17塊所對應的時間消耗;本文方法中隱私約束數量對應的時間消耗采用的是密級使用頻次較高的50grade所對應的時間消耗.實驗結果如圖2所示. 由圖2可知,方法A隨著隱私約束數量的增多,時間消耗也逐漸增多,在隱私約束數量為13個時,三種方法的時間消耗幾乎差不多,當超過13個隱私約束后,方法A的時間消耗明顯高于本文方法和方法B.由此可以得出,當隱私約束超過13時,可以考慮使用本文的方法或者方法B. 實驗2.以密級為維度進行,方法A中密級對應的時間消耗采用的是其方法中隱私約束使用頻率較高的13個所對應的時間消耗;方法B中密級對應的時間消耗采用的是其方法中切塊數頻率較高的17塊所對應的時間消耗.實驗結果如圖3所示. 圖3 密級-時間消耗Fig.3 Secret grade-time consumption 由圖3可知,本文方法的時間消耗存在一個先上升后下降的趨勢,這是由于程序在剛開始啟動時,會對程序每一部分都進行啟動,當密級較高時,整個算法消耗的時間會超過剛開始的時間消耗.隨著密級的增大,時間消耗也逐漸增多,在密級為35左右時,三種方法的時間消耗幾乎一樣,當密級超過35時,本文的方法時間消耗明顯高于另外兩種方法,由此可以得出,當密級小于35時,建議使用本文的文件破碎混淆算法,否則,建議使用另外兩種方法. 實驗3.以切塊數為維度進行,方法A中切塊數對應的時間消耗采用的是其方法中隱私約束使用頻率較高的13個所對應的時間消耗;本文方法中切塊數對應的時間消耗是按照密級和切塊數對應的關系,采用密級對應的時間消耗.實驗結果如圖4所示. 圖4 切塊數-時間消耗Fig.4 Number of slices-time consumption 由圖4可知,隨著切塊數的增大,時間消耗也逐漸增多,在切塊數為20左右時,三種方法的時間消耗幾乎一樣,當切塊數超過20時,方法B和本文方法時間消耗遠遠高于方法A;當切割數不超過30時,方法B的時間消耗略低于本文方法,原因在于本文方法不僅考慮文件破碎后的效率問題,還要保障文件的安全性,本文方法對切割后的文件塊進行了多重操作,另外使用了一次加密,因此它的效率比方法B要略低. 針對云計算平臺中文件存儲的安全性和效率低的問題,研究文件分塊存儲情況下的安全性,提出一種文件破碎混淆保護方案,根據文件密級確定文件破解時的算力,以此來確定文件破解時的效率,通過對破解效率的求解確定文件第一層切割的塊數,實現文件切割塊數的動態變化;為了防止切割的文件塊被破解恢復,需要對文件塊打亂混淆,加密保存其打亂順序;依據隱式分割機制,對切割的文件塊進行二次切割,為了保障每一個文件塊不是完整的數據,采用對文件塊進行編號重組.實驗過程從三個維度上驗證了本文算法的優良性. 未來工作主要將云計算及文件動態傳輸結合起來,在考慮文件傳輸的效率以及文件的完整性上,實現文件云端安全.3.3 文件恢復
4 實驗分析
4.1 實驗環境
4.2 實驗數據獲取及方法
4.3 文件切割效率對比

5 結 論
猜你喜歡
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:25
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
