基于K-means的選擇性任務(wù)調(diào)度算法研究
2019-11-23 08:46:52劉燕龍陶躍陳占芳周玉軒范威振
長春理工大學(xué)學(xué)報(自然科學(xué)版) 2019年5期
關(guān)鍵詞:資源
劉燕龍,陶躍,陳占芳,周玉軒,范威振
(1.長春理工大學(xué) 計算機科學(xué)技術(shù)學(xué)院,長春 130022;2.長春理工大學(xué) 電子信息工程學(xué)院,長春 130022)
云計算是分布式計算領(lǐng)域中一項正在加速發(fā)展的技術(shù),任務(wù)調(diào)度問題[1]是云計算研究中的重要階段,云計算平臺上可以接收多樣化的應(yīng)用和請求,不同的應(yīng)用有著各自不同的任務(wù)和不同的任務(wù)特性,對資源的需求也各有不同。尋找合適的方法對用戶任務(wù)進行分類,使相似任務(wù)聚合,相異任務(wù)分離,縮小任務(wù)的特性維數(shù)是非常有必要的。聚類算法[2]是任務(wù)分類的有效手段。聚類分析的目的使聚類中的任務(wù)特性彼此高度相似,不同聚類中的特性有明顯的差異。聚類內(nèi)部的相似性和聚類之間的差異性越大,聚類結(jié)果越好。K-means算法[3]是聚類算法中的經(jīng)典分類算法,具有出色的速度和良好的可擴展性,在實踐中被廣泛應(yīng)用。在云計算環(huán)境中,云計算是通過互聯(lián)網(wǎng)媒介按需付費的方式來使用計算資源,所以云資源具有差異性,與用戶任務(wù)相似,對云資源進行聚類劃分,面向具體類別的應(yīng)用任務(wù)特性有針對性的調(diào)度到類別相似的云資源上,有效提高資源調(diào)度優(yōu)化的效率,將會大大提高任務(wù)的執(zhí)行效率和資源的利用率。
在任務(wù)調(diào)度時,對于資源和任務(wù)的分配,既要考慮任務(wù)的完成時長,也要考慮系統(tǒng)資源的利用,由于調(diào)度問題是一個NP難問題,許多學(xué)者對其做出研究,提出了大量的啟發(fā)式調(diào)度算法,如Min-Min算法[4]、模擬退火算法(SA)[5]、遺傳算法(GA)[6]、蟻群算法(ACO)[7-8]、人工神經(jīng)網(wǎng)絡(luò)(ANN)等[9-10]。而經(jīng)典的Min-Min算法和Max-Min算法是啟發(fā)式算法中具有代表性的算法,算法采用貪心策略,調(diào)度算法的總完成時間短、執(zhí)行效率高,并且算法思路簡單,結(jié)合Min-Min算法和Max-Min算法兩者優(yōu)點,通過啟發(fā)式算法來尋求實現(xiàn)資源最優(yōu)分配。
通過對云計算的任務(wù)調(diào)度和資源分配問題的分析,本文提出了一種基于K-means的啟發(fā)式云資源調(diào)度方法,通過K-means算法對執(zhí)行任務(wù)和云資源進行分類,將任務(wù)集合分配到合適的執(zhí)行資源中,避免了造成任務(wù)與資源的不匹配,從而造成的資源浪費的問題,達到提高任務(wù)執(zhí)行效率的效果。同時在K-means對任務(wù)劃分的基礎(chǔ)上,采用Min-Min算法和Max-Min算法相結(jié)合的選擇性調(diào)度算法,根據(jù)任務(wù)的長度和預(yù)期完成時間,選擇合適的調(diào)度算法,通過對任務(wù)長度和預(yù)期執(zhí)行時間的計算,合理的分配任務(wù)與資源,快速的處理任務(wù)集群,達到縮短任務(wù)集群整體執(zhí)行時間的效果。
1 基于K-means的任務(wù)聚類策略
聚類方法是對任務(wù)進行劃分的過程,根據(jù)相似性或唯一性標(biāo)準(zhǔn)分組。聚類算法不僅僅是用于分類,也用于任務(wù)特性簡化。用n個屬性變量來表示m個任務(wù)對象,如任務(wù)需求的資源為處理器、內(nèi)存、存儲、帶寬等屬性。用戶任務(wù)對資源的需求可以采用任務(wù)向量距離公式表示,本文采用歐幾里得距離,它表示在m維空間中兩個點之間的真實距離,如式(1)所示。其中,D(i,j)表示任務(wù)i與 j的數(shù)據(jù)的相似程度;k表示m個任務(wù)對資源需求的某一特性。
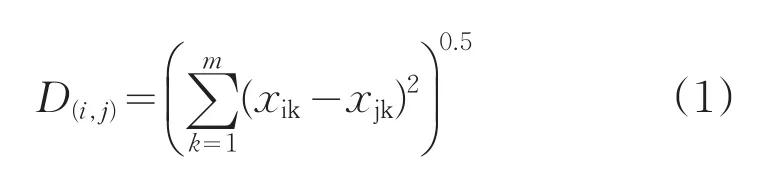
K-means算法是通過劃分將m個任務(wù)對象劃分為k類,首先確定所要的聚類的類簇k,k值的選定關(guān)乎著算法結(jié)果,因為任務(wù)所需求的資源屬性值包括計算能力、寬帶能力和存儲能力,k值可以預(yù)先選定為3,用戶任務(wù)聚類并不完全是是非此即彼的類別劃分,聚類結(jié)果的每一個類簇都會有一部分的邊緣任務(wù)數(shù)據(jù),稱為邊緣域[11],邊緣域一定程度的影響了聚類結(jié)果的準(zhǔn)確率,為了提高用戶任務(wù)分類的準(zhǔn)確率,確定合適的聚類數(shù)目是重中之重。為了確定聚類數(shù)目,本文將任務(wù)分類k值在一個區(qū)域內(nèi)(其中Tk值小于任務(wù)總量),對區(qū)域內(nèi)的k值,進行依次的迭代聚類,對所有的聚類結(jié)果進行分析。對于這些聚類結(jié)果,計算其聚類的評估函數(shù)(Clustering Performance Index)CPI,聚類評估函數(shù)結(jié)合了聚類內(nèi)部的相似性和聚類之間的差異性這兩個因素,一般說來,通過類簇中數(shù)據(jù)和類簇中心的內(nèi)聚程度來衡量聚類內(nèi)部的相似性,用類簇之間的分離程度來衡量聚類之間的差異性。本文從內(nèi)部的相似性和聚類之間的差異性出發(fā),定義新的評估函數(shù),并設(shè)計了新的有效性指數(shù)CPI。選擇聚類評估函數(shù)CPI最小的聚類為最優(yōu)聚類結(jié)果,該最優(yōu)聚類結(jié)果代表了最符合任務(wù)需求資源特性的分類結(jié)果。
K-means的任務(wù)聚類策略算法流程圖如圖1所示。
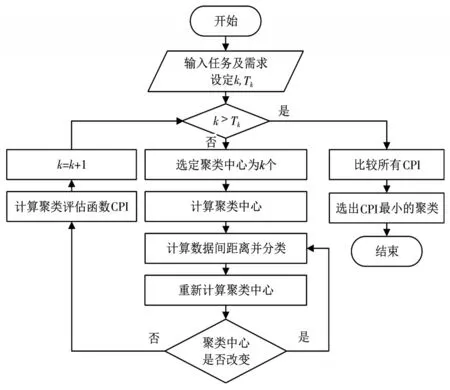
圖1 K-means的任務(wù)聚類策略流程圖
圖1中K-means的任務(wù)聚類策略具體步驟如下所示:
輸入:用戶提交的n個任務(wù)的資源需求特征D={p1,p2,???,pn},其中 pi={計算需求,寬帶需求,存儲需求},Tk=8。
輸出:任務(wù)聚類結(jié)果。
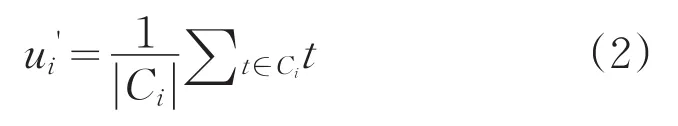
(7)如果當(dāng)前聚類中心不再改變,確定所有的聚類中心:C={C1,C2,???,Ck}。
(8)計算聚類結(jié)果評估函數(shù),根據(jù)類內(nèi)緊湊性和類間分離性因素考慮,首先計算每類類內(nèi)樣本間的平均距離(如式(3)所示)和不同的類的類間距離(如式(4)所示)。

計算聚類評估函數(shù),如式(5)所示:
(2)將任務(wù)按長度進行排序,令排序的任務(wù)以k倍劃分,選擇每組中位數(shù)為聚類中心,共k個聚類中心:C={u1,u2,???,uk}。
(3)對于其他任務(wù),根據(jù)歐式距離,計算所用的任務(wù)數(shù)據(jù)與類簇中心的距離。
(4)根據(jù)歐氏距離,選擇與聚類中心距離最小的類簇,將tj分到相應(yīng)的類簇中。
(5)根據(jù)式(2),重新計算每個類簇的中心點,確定新的聚類中心。

(9)根據(jù) k=3,4,???,Tk,重復(fù)步驟(1)-(8),計算所有的聚類,比較每一個聚類評估函數(shù)CPI,CPI值越小說明得到的聚類效果越好,確定聚類的中心值k和任務(wù)聚類結(jié)果。
2 云計算資源的聚類
云計算中的資源是使用虛擬化將計算資源(如網(wǎng)絡(luò)、服務(wù)器、存儲、應(yīng)用和服務(wù)等)進行封裝共享,不同的資源提供的性能不同。
資源模型表示為式(6)所示:
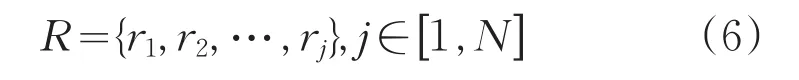
式中,rj表示第 j個資源節(jié)點;資源節(jié)點數(shù)為N。
資源節(jié)點 j的資源特性可以用一維向量表示:rj={rid,rcpu,rmips,rbw,rstor},其中,rid為資源編號,rcpu為資源的CPU數(shù)目,rmips表示每秒執(zhí)行的百萬條指令數(shù)目,rbw、rstor代表資源的通信能力、存儲能力[12]。其中,資源的計算能力可以通過rcpu和rmips的乘積表示。該乘積越大代表該資源的計算能力越強。
任務(wù)調(diào)度結(jié)果同時受資源計算、帶寬和內(nèi)存的影響,因此將資源以計算型資源、帶寬型資源和存儲型資源為基礎(chǔ)屬性進行K-means分類,與第二節(jié)中任務(wù)聚類的原理一樣,在聚類開始,將聚類數(shù)目k值設(shè)定在一個區(qū)域內(nèi)(其中Tk值小于任務(wù)總量),對區(qū)域內(nèi)的k值,進行依次的迭代聚類,對所有的聚類結(jié)果進行分析。然后對于這些聚類結(jié)果,計算其聚類評估函數(shù)CPI,選擇聚類評估函數(shù)CPI最小的聚類結(jié)果為資源的最優(yōu)分類。
3 資源與任務(wù)的映射匹配
通過前兩節(jié)對任務(wù)和資源的聚類劃分后,得到相應(yīng)的分類的類簇,同一類簇中的任務(wù)對資源的需求具有相似性,通過將聚類結(jié)果進行權(quán)值化,進行調(diào)度時偏向選取與任務(wù)權(quán)值相近的資源,將資源與用戶任務(wù)之間形成相應(yīng)的映射關(guān)系,通過映射匹配將任務(wù)集分配到合適的執(zhí)行資源類中,對任務(wù)進行合理調(diào)度,達到提高任務(wù)調(diào)度的執(zhí)行效率的效果。
(1)通過計算(c)、內(nèi)存(r)、寬帶(b)三種屬性對任務(wù)和資源分別建立對比矩陣,這里以資源為例,如式(7)所示。其中vmij表示要素i相對于要素 j的重要程度。
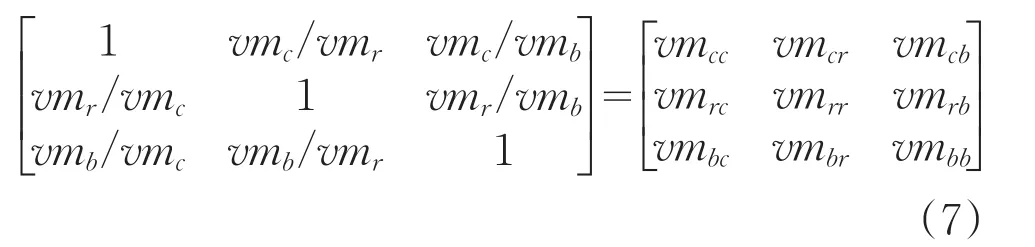
(2)進行對比矩陣的一致性檢驗,如式(8)所示。
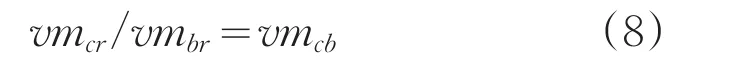
(3)如果矩陣的一致性滿足要求,則可以根據(jù)矩陣的最大特征值進一步計算得到對應(yīng)的特征向量,并通過對特征向量進行標(biāo)準(zhǔn)化將其轉(zhuǎn)化為權(quán)向量[13]。如式(9)和式(10)所示,其中的各分量反映了各要素的影響權(quán)重。
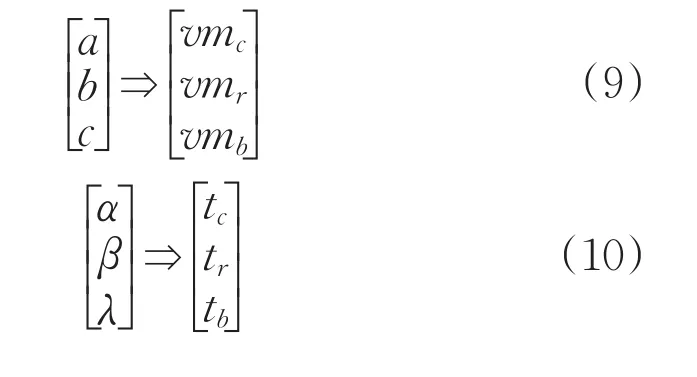
(4)通過對比矩陣求出權(quán)向量,利用如下式(11)和式(12)計算任務(wù)集需求度和資源綜合能力:
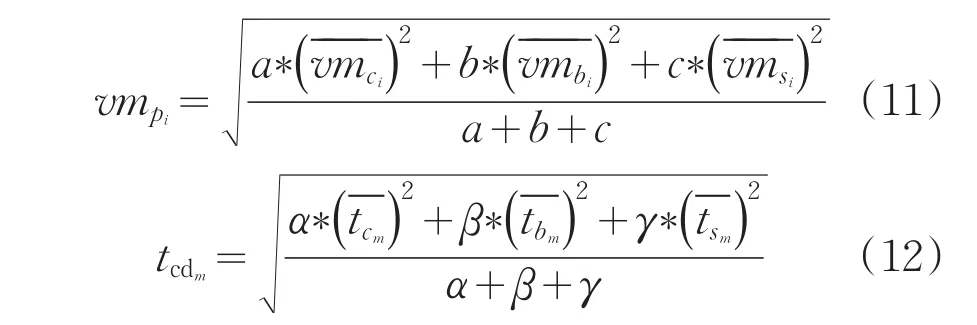
(5)按式(13),通過任務(wù)集需求度和資源綜合能力之間的最短距離da,對任務(wù)和資源進行映射匹配,將任務(wù)集分配到合適的執(zhí)行資源中。
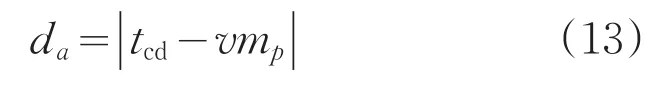
4 任務(wù)調(diào)度階段
經(jīng)過K-means算法對任務(wù)和資源的分類,使任務(wù)和資源形成映射關(guān)系,再將任務(wù)分配到合適的資源之后,對于同一資源中的任務(wù),采用選擇性啟發(fā)調(diào)度算法,啟發(fā)式(heuristic)任務(wù)調(diào)度算法是解決云計算任務(wù)調(diào)度中簡單有效的方法,其中的Min-Min算法和Max-Min算法[14]是經(jīng)典的調(diào)度算法,開銷小,且執(zhí)行速度快。選擇性調(diào)度算法是采用Min-Min算法和Max-Min算法相結(jié)合的算法,根據(jù)任務(wù)的長度和預(yù)期完成時間合理選擇與任務(wù)集群最相配的調(diào)度算法。
基于對縮短整體任務(wù)的執(zhí)行時間的考慮,根據(jù)任務(wù)長度和預(yù)期完成時間,選擇合適的調(diào)度算法對任務(wù)進行處理。選定參數(shù)α值,當(dāng)長任務(wù)的數(shù)量要小于短任務(wù)的數(shù)量的α倍,則采用Max-Min算法,否則,采用Min-Min算法。本章用相互映射匹配的一對類簇中的任務(wù)和資源進行選擇性調(diào)度,選擇性任務(wù)調(diào)度過程圖如圖2所示。
圖2中選擇性任務(wù)調(diào)度的流程如下所示:
輸入:同一資源中相互映射匹配的任務(wù)和資源集合。
輸出:任務(wù)調(diào)度的結(jié)果。
步驟1:當(dāng)資源都處于負載為零時,對于任務(wù)集t中的每一個任務(wù)ti,計算任務(wù)ti在資源vmj上的執(zhí)行時間ETC(ti,vmj)。
步驟2:對于任務(wù)集t中的每一個任務(wù)ti,計算ti在資源vmj上的執(zhí)行完成時間MCT(ti,vmj)(已知:rj是資源vmj準(zhǔn)備就緒去處理任務(wù)ti的準(zhǔn)備時間),如式(14)所示。
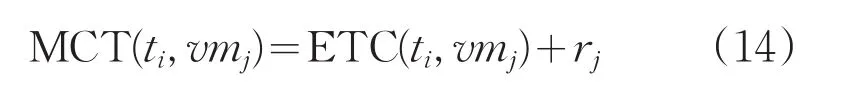
步驟3:通過MCT對任務(wù)進行排序,并計算任務(wù)集群的標(biāo)準(zhǔn)偏差sdij,如式(15)所示。
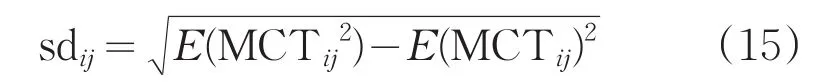
式中,E(MCTij)表示MCTij的平均值;T表示任務(wù)ti在資源vmj上運行的最大時間。
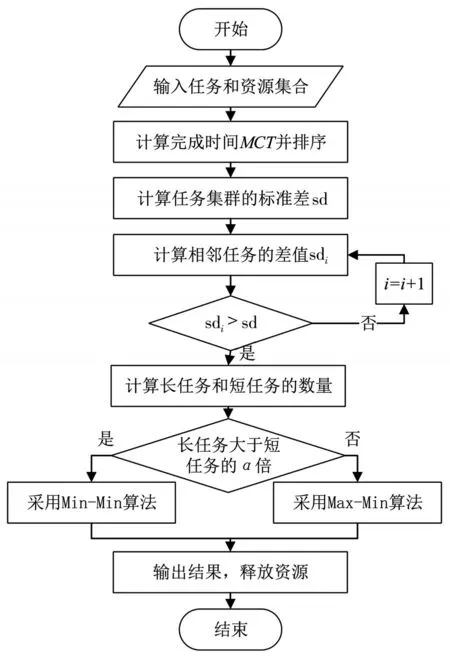
圖2 選擇性任務(wù)調(diào)度流程圖
步驟4:在己經(jīng)排好序的任務(wù)序列中找到兩個連續(xù)值的差值大sd的位置,即任務(wù)長度變化明顯的位置,用于區(qū)分長任務(wù)和短任務(wù)。
步驟5:設(shè)定參數(shù)α值,當(dāng)長任務(wù)的數(shù)量要大于短任務(wù)的數(shù)量的α倍,選擇Min-Min調(diào)度算法,優(yōu)先處理任務(wù)長度小、預(yù)期完成時間短的任務(wù),否則,選擇Max-Min調(diào)度算法,優(yōu)先處理任務(wù)長度大、預(yù)期完成時間長的任務(wù)。
步驟6:每分配一個任務(wù),更新任務(wù)集合的期望完成時間,如此重復(fù)步驟1-5,分配所用的任務(wù)集合。
步驟7:通過評價指標(biāo)評估分配策略,以任務(wù)的最后完成時間和系統(tǒng)資源利用率為標(biāo)準(zhǔn)。
其中時間指標(biāo)函數(shù)為式(16):
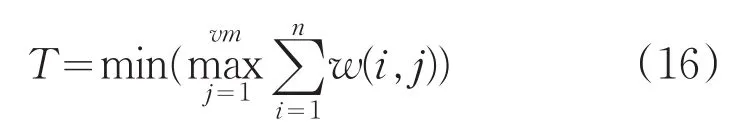
式中,vm為云資源集合總量;n為資源j上總分配的任務(wù)總數(shù);w(i,j)表示第i個任務(wù)在第j個資源上的執(zhí)行時間。
資源利用率評估指標(biāo)為式(17):
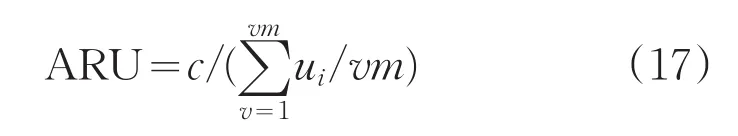
式中,vm為資源總數(shù);ui表示第i個資源的綜合利用率。
5 結(jié)果分析
CloudSim[15]是由澳大利亞墨爾本大學(xué)網(wǎng)格實驗室和Gridbus項目推出的用于云計算仿真的軟件[16],支持大型云計算基礎(chǔ)設(shè)施的建模與仿真。CloudSim可以提供模擬的數(shù)據(jù)中心,通過對資源、任務(wù)、調(diào)度機制、資源分配進行仿真實現(xiàn),通過網(wǎng)絡(luò)資源的建立,可以實現(xiàn)對云計算資源控制及任務(wù)調(diào)度的有效實驗和改進。為驗證本文提出的算法的有效性,通過擴展CloudSim仿真平臺,自定義DatacenterBroker類中的方法實現(xiàn)任務(wù)調(diào)度算法,通過重新編譯、打包實現(xiàn)了算法仿真。
5.1 實驗參數(shù)配置
(1)實驗環(huán)境配置:
硬件環(huán)境:第7代英特爾?酷睿? i7處理器,16 GB DDR4-2666 SDRAM(2×8GB)內(nèi)存,傳輸速率2 400 MT/秒。
軟件環(huán)境:IntelliJ IDEA 2017開發(fā)環(huán)境,Apache Ant 1.7,CloudSim4.0,JDK1.8.0。
(2)數(shù)據(jù)中心配置參數(shù):
任務(wù)參數(shù):任務(wù)長度(單位:MIP)的設(shè)置[500,3 000],期望寬帶(單位:MB/s)的設(shè)置[1 000,2 000],期望存儲(單位:MB)的設(shè)置[512,2 048],期望計算能力(單位:MIPS)的設(shè)置[500,3 000]。
資源參數(shù):CPU的設(shè)置[1,4],寬帶(單位:MB/s)的設(shè)置[1 000,3 000],存儲(單位:MB)的設(shè)置[1 024,4 096],計算能力(單位:MIPS)的設(shè)置[500,2 000]。
5.2 仿真過程
任務(wù)調(diào)度在CloudSim仿真系統(tǒng)中的一般流程如下:
(1)通過init方法,初始化CloudSim庫。
(2)通過createDatacenter方法,創(chuàng)建數(shù)據(jù)中心,其中dataName是數(shù)據(jù)中心的命名。
(3)通過createBroker方法,創(chuàng)建數(shù)據(jù)中心代理broker。
(4)通過定義VM對象,創(chuàng)建虛擬機列表;通過submitVmList方法,將虛擬機注冊到代理broker上。
(5)通過定義Cloudlet對象,創(chuàng)建任務(wù)列表;通過submitCloudletList方法,將任務(wù)注冊到broker上。
(6)通過自定義bindCloudletsToVmsKCMM方法,進行任務(wù)調(diào)度算法的實現(xiàn)。
(7)通過startSimulation方法,啟動仿真。
5.3 實驗結(jié)果分析
(1)在實驗中,為了有效的驗證算法,首先需要確定參數(shù)α的最優(yōu)值。在實驗仿真中選取在不同α下完成時間波動比較大的任務(wù)數(shù)量進行試驗,因此,設(shè)置任務(wù)數(shù)量為n={900,1 200,1 800,2 400},通過改進的調(diào)度算法,對不同的α值,計算任務(wù)的平均完成時間,依據(jù)實驗數(shù)據(jù)對比,確定最優(yōu)的α值,不同α值下調(diào)度算法的完成時間如表1所示。
由表1不同α值下調(diào)度策略的完成時間可以看出,當(dāng)α=0.8時,任務(wù)的綜合平均完成時間最小,在α小于0.8時,長任務(wù)和短任務(wù)的劃分界限偏小,在選擇性調(diào)度時,偏向于選擇Max-Min算法,優(yōu)先處理長任務(wù),使得短任務(wù)處于長時間的等待,增加了任務(wù)的最終完成時間;當(dāng)α大于0.8時,長任務(wù)和短任務(wù)的劃分界限偏大,在選擇性調(diào)度時,偏向于選擇Min-Min算法,優(yōu)先處理短任務(wù),造成少量的長任務(wù)占用大量的執(zhí)行時間,使得選擇性調(diào)度失去意義。因此,將選擇界限參數(shù)α的值定為0.8。
(2)通過確定參數(shù)α=0.8的最優(yōu)解,為了驗證算法的有效性,算法對任務(wù)數(shù)量在n={300,600,900,1 200,1 500,1 800,2 100,2 400,2 700}的范圍中的數(shù)據(jù)進行實驗,通過進行100次迭代實驗,對實驗結(jié)果進行比較驗證。并對Min-Min算法(Min-Min)、基于K-means對任務(wù)和資源進行分類映射的Min-Min算法(K-MM)和本文提出的基于K-means的啟發(fā)式選擇調(diào)度算法(K-C-MM)通過任務(wù)的最后完成時間和資源的利用率進行比較,如圖3算法任務(wù)完成時間對比圖,圖4算法資源利用率對比圖所示。
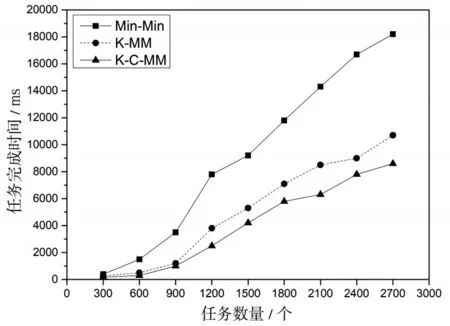
圖3 三種算法任務(wù)完成時間對比圖
由圖3任務(wù)完成時間對比可以看出,在云任務(wù)數(shù)較小的情況下,三種算法的執(zhí)行效率均較高,完成時間較快,且差異不明顯。隨著任務(wù)數(shù)量的增加,K-C-MM算法和K-MM算法的完成時間明顯低于Min-Min算法,相對于Min-Min算法,K-C-MM算法在完成時間上縮短了50%以上,K-MM算法在完成時間上縮短了接近40%,由此可以看出通過K-means的任務(wù)和資源的分類與映射匹配,將任務(wù)調(diào)度到合適的資源上運行,提高了任務(wù)的執(zhí)行效率,大幅度降低了任務(wù)的完成時間。而相對于K-MM算法,K-C-MM算法在完成時間上更具有一定的優(yōu)勢,降低了20%的平均完成時間,因此采用Min-Min算法和Max-Min算法相結(jié)合的選擇調(diào)度算法,合理分配長任務(wù)和短任務(wù)的執(zhí)行順序,在任務(wù)執(zhí)行效率方面具有一定優(yōu)勢。
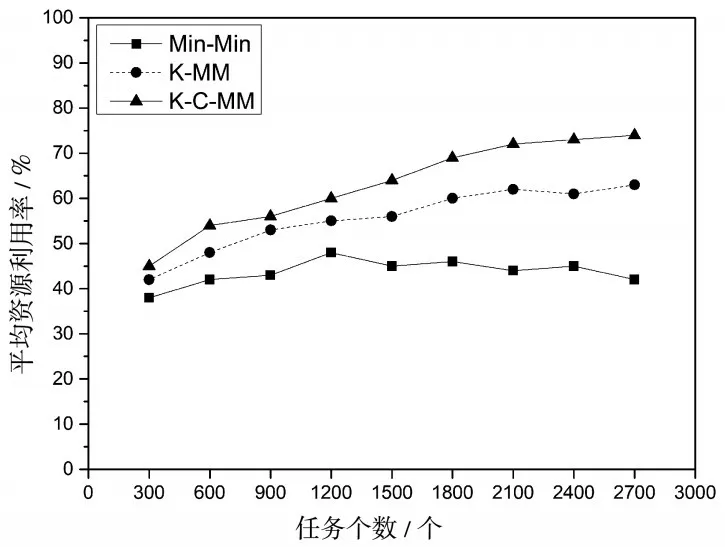
圖4 三種算法資源利用率對比圖
由圖4資源利用率對比可以看出,Min-Min算法的系統(tǒng)資源利用率的平均值只有44%,而隨著任務(wù)數(shù)量的增加,資源的利用率呈現(xiàn)下降趨勢;對于K-MM算法隨著任務(wù)數(shù)量的增加,資源利用率可以達到60%以上,因為K-MM是通過K-means算法對任務(wù)調(diào)度的改進,將任務(wù)和資源相互匹配,使得物盡其用,極大的提高了資源的利用率;但是由于Min-Min算法的負載不均衡問題,資源利用率在一定程度上還可以提高,所以本文采用選擇性調(diào)度算法K-C-MM,使得資源的利用率達到70%以上,比Min-Min算法的資源利用率提高了60%,比K-MM算法的資源利用率提高了20%左右。
綜合以上分析可知,在云計算環(huán)境中,基于K-means的選擇調(diào)度算法不僅提高了任務(wù)的執(zhí)行效率,降低了任務(wù)的最后完成時間,同時保證了較高的系統(tǒng)資源利用率。
6 結(jié)論
本文針對云環(huán)境下的任務(wù)調(diào)度進行了研究,提出了一種基于K-means的啟發(fā)式選擇調(diào)度算法,該算法首先通過K-means算法對任務(wù)和資源進行聚類劃分,依照任務(wù)與資源的匹配映射關(guān)系,使任務(wù)集群分發(fā)到相應(yīng)的資源上,避免了造成任務(wù)與資源的不匹配和資源的浪費,然后本文采用選擇性調(diào)度算法,選擇調(diào)度算法是采用Min-Min算法和Max-Min算法相結(jié)合的算法,通過對任務(wù)長度和預(yù)期執(zhí)行時間的計算,合理的分配任務(wù)與資源,縮短任務(wù)的執(zhí)行時間。實驗結(jié)果表明,本文算法能夠降低資源選擇的開銷,提高系統(tǒng)資源的利用率,縮短任務(wù)的執(zhí)行時間。與其他方法相比,具有較好的執(zhí)行效率,較強的應(yīng)用前景。
猜你喜歡
江蘇安全生產(chǎn)(2023年1期)2023-02-08 05:58:38
資源節(jié)約與環(huán)保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學(xué)學(xué)報(2021年4期)2022-01-14 02:35:48
藝術(shù)品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學(xué)版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
當(dāng)代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
