基于用戶軌跡數據的用戶興趣區域推薦(云南大學信息學院,云南 昆明 650504)
2019-12-06 06:25:15龍玉絨王麗珍陳紅梅
軟件工程 2019年11期
龍玉絨 王麗珍 陳紅梅


摘? 要:推薦系統是通過分析已知信息和用戶偏好,在用戶選擇物品或服務時,向用戶提供幫助和建議的系統。但是目前大部分推薦系統都是基于用戶評價或評分信息向用戶推薦購物、電影等電子商務服務,基于用戶軌跡數據進行用戶興趣區域推薦的研究十分罕見。用戶的軌跡數據蘊含了用戶的偏好,不同的軌跡反映不同的用戶特性。所以提出一種從用戶軌跡數據中挖掘最大頻繁項集,并將最大頻繁項集用于計算用戶相似性和偏好的推薦方法。該推薦方法還綜合考慮了相似用戶訪問次數、置信度和用戶住宅信息等可能會影響推薦質量的因素。將提出的方法和基于協同過濾的推薦方法、基于關聯規則的推薦方法進行比較,結果顯示本文提出方法的效果較好。
關鍵詞:軌跡數據挖掘;區域推薦;相似用戶;頻繁項集
中圖分類號:TP391? ? ?文獻標識碼:A
User Interest Region Recommendation Based on User Trajectory Data
LONG Yurong,WANG Lizhen,CHEN Hongmei
(School of Information Science and Engineering,Yunnan University,Kunming 650504,China)
Abstract:A recommendation system is a system which provides help and advice to users by analyzing the existing information and users' preferences when users choose goods or services.However,most recommendation systems recommend shopping,movies and other e-commerce services to users based on user evaluation or scoring information.It is very rare to conduct research on user interest region recommendation based on user trajectory data.User's trajectory data contains users different preference,reflecting different user characteristics.Therefore,it is? necessary to make recommendations based on user trajectory data.This paper presents an interest region recommendation method,which calculates user similarity and preference by mining maximum frequent itemsets from user trajectory data.We take into account three factors,including numbers of similar user visits,confidence and user residence information.In the paper,the proposed method is compared with the recommendation algorithm based on collaborative filtering and the recommendation algorithm based on association rules,and the results show that the proposed method is effective.
Keywords:trajectory data mining;region recommendation;similar users;frequent itemset
1? ?引言(Introduction)
近年來,基于位置的社交網絡[1]十分流行,用戶可以將他們的活動軌跡數據或者訪問的地點在網絡上進行共享,這些數據都帶有位置信息。推薦系統[2-4]可以運用于此類數據。Berjani B[5]、Hu L[6]和Liu Y[7]等人均是利用社交數據進行位置推薦。但是,現有的位置推薦方法大體有如下不足:
(1)數據多為用戶簽到數據,蘊含信息單一,不能準確評估用戶偏好。
(2)向用戶推薦的是一個興趣點而不是一個興趣區域。
(3)對用戶進行相似性評估時,需要用戶的評分信息。
針對上述問題,本文提出了一種從用戶軌跡數據中挖掘最大頻繁項集,并基于最大頻繁項集計算用戶相似性和偏好用于興趣區域推薦的方法。
本文主要貢獻包括:
(1)不需要用戶的評分信息,從用戶軌跡數據轉化得到的事務數據中挖掘最大頻繁項集,基于最大頻繁項集定義用戶相似性。
(2)提出一種不產生候選模式,只需要掃描兩次數據庫的頻繁項集挖掘方法。
(3)提出一種考慮了相似用戶訪問次數、置信度和住宅信息三種因素的用戶興趣區域推薦方法,該方法能更準確地進行用戶興趣區域推薦。
2? ?定義(Definition)
基于用戶軌跡數據進行用戶興趣區域推薦的算法中,主要的挑戰是相似用戶的度量及用戶興趣區域推薦。本節首先對停留區域和停留區域間的鄰近關系進行定義,用于將軌跡數據轉化為事務數據。其次給出相似用戶的定義及推薦得分的定義,最后給出本文的問題定義。
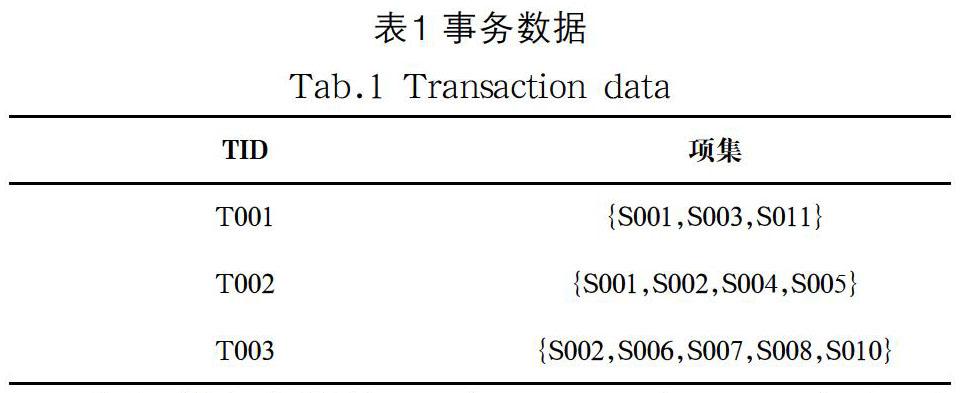
設I={i1,i2,i3,..,in}是項的集合,則稱為項集,K=|X|,X稱為K項集。事務是事務數據庫中的一條記錄,代表發生的一次事件。數據庫D={T1,T2,T3,...,Tm}是事務的集合,稱為事務數據庫。支持度計數是指包含特定項集的事務個數。頻繁項集是指在事務數據D中出現的頻率大于支持度計數閾值的項集。如果頻繁項集L的所有超集都是非頻繁的,那么頻繁項集L為最大頻繁項集。
例1:如表1所示,S001是項,{S001,S003}是一個項集,TID:T001是一個事務。D={T001,T002,T003}是事務數據庫。{S001,S003}的支持度計數為:1,因為只有一條事務包含{S001,S003}。
定義1(數據點描述)
定義2(軌跡數據)軌跡數據是由許多數據點按時間順序組成的一個數據點序列。
定義3(停留區域)停留區域是指用戶軌跡數據中移動速度低于平均速度或某個用戶給定的速度閾值的區域。
例2:如圖1所示,圖中給出用戶A的一條軌跡數據P={p1,p2,p3,p4,p5,p6,p7}。如果用戶A在點p3、p4、p5、p6區域內的移動速度小于一個給定的速度閾值,例如30米/分鐘,那么區域A1:{p3,p4,p5,p6}是用戶A的一個停留區域。
本文定義停留區域是為了對用戶的軌跡數據進行預處理,將軌跡數據中對推薦沒有價值的數據忽略。由于我們擬推薦的是用戶可能訪問的興趣區域,所以我們只關注用戶長時間停留或移動速度較慢的區域,即停留區域。假設用戶A在區域B1內的速度為600米/分鐘。我們只認為用戶A經過了區域B1,并不認為A訪問了區域B1。
定義4(鄰近關系)假設有兩個停留區域A1和B2,如果兩個停留區域的最小外包矩形有重疊時,我們稱停留區域A1和B2具有鄰近關系。
圖1 停留區域
Fig.1 Stay region
圖2 鄰近關系
Fig.2 Proximity relationship
本文定義停留區域間的鄰近關系是為了確定用戶興趣區域的位置相關性,并確定訪問過相關區域的用戶。已知停留區域集:SR={A1,A2,B1,B2,C3}。通過計算確定A1、B2、C3具有鄰近關系,可以確定訪問了鄰近區域的用戶A、B、C具有一定的訪問相似性。
例3:如圖2所示,根據定義4,A1、B2和C3是相互鄰近的停留區域,對于這樣的相互鄰近的停留區域,我們可以確定一個用戶興趣區域S,用戶興趣區域S為A1、B2和C3三者最小外包矩形并集的最小外包矩形,圖2中虛線的矩形就是用戶興趣區域S。并且確定用戶A、B、C訪問過該區域。我們將其轉化為一條事務:TID為S,項集為{A,B,C}。表示興趣區域S被用戶A、B、C訪問過。
根據上述的定義,我們可以將用戶的軌跡數據轉化為兩類事務數據集,一類事務數據TID為用戶興趣區域,項集為用戶,如表2所示為一個可能的“興趣區域—用戶”事務數據集,其中TID為用戶興趣區域的編號,項集為訪問過該區域的用戶。例如第一條事務表示用戶{A,B,C,F,H}訪問過用戶興趣區域S001。第二類事務數據TID為用戶,項集為用戶訪問過的興趣區域,如表3所示為一個可能的“用戶—興趣區域”事務數據集。例如第一條數據表示用戶A訪問過興趣區域S001、S003、S005。
我們從第一類事務數據集中挖掘最大頻繁項集,其中項為用戶,包含在最大頻繁項集中的用戶都是頻繁訪問過相同的興趣區域的用戶,在一定程度上這些用戶的興趣區域是相似的,于是認為用戶偏好也是相似的。所以不需要用戶評分數據,我們可以定義相似用戶。
定義5(相似用戶)假設L為一個最大的頻繁項集,我們稱屬于L的用戶為相似用戶,其相似性為1,表示為:
其中ui、uj分別表示兩個用戶。
我們知道,關聯規則X1X2表示項集之間的關聯關系。規則置信度是指項集X1出現的情況下項集X2出現的概率。我們將其運用到推薦得分的定義中。
定義6(推薦得分)給定一個待推薦的用戶興趣區域S,Score(s)表示待推薦用戶興趣區域S的推薦得分,Score(s)的計算如下:
其中,為相關規則置信度,vt為該用戶興趣區域被相似用戶訪問的次數,d表示用戶住宅區與該用戶興趣區域的距離。
為何要如此定義推薦得分?
從二類事務數據中可挖掘出項為用戶興趣區域的頻繁項集。考慮規則置信度是為了推薦頻繁項集中的用戶興趣區域。規則置信度表示該用戶在訪問過其他頻繁項集的情況下訪問待推薦用戶興趣區域的概率,規則置信度越高,用戶訪問該用戶興趣區域的概率越大。假設用戶興趣區域{S1,S2,S3}是頻繁項集,用戶A訪問過用戶興趣區域S1和S2,將用戶興趣區域S3推薦給A時,需要考慮規則{S1,S2}{S3}的置信度。考慮相似用戶的訪問次數是為了將相似用戶偶然訪問的用戶興趣區域排除,并且用戶興趣區域被相似用戶訪問的次數越多,說明該用戶興趣區域對這類用戶的吸引力越大。考慮用戶住宅區和推薦用戶興趣區域之間的距離是因為推薦時離用戶住宅區距離較近的用戶興趣區域更有可能被該用戶訪問。
問題定義(基于用戶軌跡數據的用戶興趣區域推薦)給定用戶軌跡數據集{PA,PB,PC,...,Pk},支持度計數閾值。向用戶推薦top-n個最有可能訪問的用戶興趣區域。
3? ?算法(Algorithm)
在這一部分,將介紹我們提出的兩個算法:基本算法basic_algorithm和改進算法improved_algorithm。basic_algorithm算法挖掘頻繁項集時運用的是類apriori方法。由于基本算法在計算停留區域間鄰近關系時,算法時間復雜度較高,挖掘頻繁項集時需要多次掃描數據庫、產生大量的候選,所以提出改進算法:improved_algorithm。改進算法將網格劃分運用到鄰近關系的計算中減少不必要的計算,減少時間的耗費。同時,改進算法在挖掘頻繁項集時提出一種不需要多次掃描數據庫、不產生候選模式的挖掘方法。
3.1? ?基本算法:basic_algorithm
首先介紹基本算法basic-algorithm,基本算法中挖掘頻繁項集運用的是類apriori[8]方法。
算法1:basic-algorithm
輸入:用戶的軌跡數據;top-n的n值;頻繁項集支持度計數閾值sup。
輸出:推薦給用戶的top-n個用戶興趣區域。
變量:SRS:用戶停留區域集;D:事務集;PIS:“興趣區域—用戶”事務數據(項為用戶)的最大頻繁項集;RPIS:“用戶—興趣區域”事務數據(項為興趣區域)的頻繁項集;Fk:k階頻繁項集;Ck:k階頻繁項集候選;SUS:相似用戶集;Result:推薦結果;RL(i):用戶i的推薦列表。
步驟:
步驟1是從用戶的軌跡數據中產生停留區域。步驟2是運用用戶和其停留區域等信息將軌跡數據轉化為事務數據集。步驟3是運用類apriori方法產生項為用戶的最大頻繁項集,其中3.1是賦初始值,3.2是產生一階的頻繁項集,步驟3.5是通過連接k-1的頻繁項集產生k階頻繁項集的候選模式,步驟3.6是統計k階候選模式的支持度計數,步驟3.7是判斷候選模式的支持度計數是否滿足閾值產生k階的頻繁項集,步驟3.8是停止條件,當k階頻繁項集為空時循環停止。步驟4是產生項為用戶興趣區域的頻繁項集。步驟5是產生相似用戶集。步驟6是產生top-n個推薦用戶興趣區域,其中6.1是產生候選推薦集、計算每一個候選推薦用戶興趣區域的得分并按得分進行降序排序,步驟6.2返回top-n個推薦用戶興趣區域。
3.2? ?改進算法:improved_algorithm
由于基本算法耗時長,查找停留區域間的鄰近關系的時間復雜度為。挖掘頻繁項集時需要多次掃描數據庫。為了改進這些問題我們提出了改進算法。
根據鄰近關系的定義,如果兩個停留區域的最小外包矩形重疊,兩個停留區域之間具有鄰近關系。為了識別所有的鄰近關系,我們需要計算所有停留區域之間的關系,所以當停留區域的數量巨大時,這是一步非常耗時的操作。為了減少不必要的計算,在改進算法中我們采用網格劃分來快速搜索鄰近關系。接下來,我們將介紹網格劃分。
網格劃分:首先,找到所有停留區域最小外包矩形中最大的長度和寬度,分別表示為Lw和Lh。對于一個最小外包矩形,長度是指它在X軸方向上的長度,寬度是指它在Y軸方向上的長度。接下來,找出最小外包矩形最小的X、Y坐標和最大的X、Y坐標,分別表示為minX、minY、maX和maxY。所有停留區域的最小外包矩形的X坐標位于區間[minX,maxX],Y坐標位于區間[minY,maxY]。將空間[(minX,minY),(maxX,maxY)]劃分為許多網格。網格的長度是Lw,寬度是Lh。圖3給出了網格劃分示例。
如何將停留區域的最小外包矩形映射到網格中?
因為停留區域的最小外包矩形是一個區域而不是一個點,它可能位于多個網格中。所以我們將最小外包矩形的中心點映射到網格中,中心點所在的網格也就是該停留區域所在的位置。首先,我們定義一個二維數組:grid來存儲位于網格中的停留區域。其次,我們計算停留區域所在的網格。最后將其存儲在數組中。
圖3 網格劃分
Fig.3 Grid partition
例4:在空間中maxX=9、maxY=13、minX=1、minY=1、Lw=2、Lh=3,{(3,3),(3,6),(5,6),(5,3)}這四個點是停留區域o最小外包矩形的坐標。我們可以計算出最小外包矩形的中心點(4,4.5),中心點所在的網格就是停留區域o所在的網格。因此,我們可以計算o所在網格的行數和列數。行號為:=1,列號為:=1。因此,grid[1,1]是o所在的網格。
搜索區域:一個網格的搜索區域是它自己和周圍的8個網格。
例5:如圖3所示,對于停留區域最小外包矩形o所在的網格,陰影網格為搜索區域。假設位于o附近的停留區域的外包矩形都是最大的。如果它們的中心點位于陰影網格中,它們可能與o有鄰近關系。如果中心點沒有位于陰影部分則它們不可能與o有鄰近關系。因為網格的長度是停留區域最小外包矩形的最大長度,網格的寬度是停留區域最小外包矩形的最大寬度,即使最小外包矩形是最大,停留區域最小外包矩形也不會在X軸方向或Y軸方向跨三個網格。所以,我們不需要搜索其他區域。
另外,由于基本算法在挖掘頻繁項集時需要多次掃描數據庫,這個操作十分耗時,并且會產生大量的候選集。在改進算法中我們提出一種新方法來挖掘頻繁項集。我們以字典序來存放項集和其支持度計數,當我們遍歷數據庫時對結果集進行更新。這種方法只需要掃描兩次數據庫,并且不產生候選。為了方便描述,我們將產生頻繁項集這部分算法稱為DIC_Item。例6詳細地闡述了DIC_Item算法挖掘頻繁項集的過程。
例6:以從表2的事務數據中挖掘頻繁項集為例說明DIC_Item算法。第一次進行遍歷數據庫,將數據庫中支持度計數小于閾值的項去掉,如表4所示,我們進行遍歷后可以得到項和其支持度計數:{A:2,B:2,C:2,D:2,E:1,F:1,G:1,H:2},假設我們的閾值為2。我們將支持度計數小于2的項去掉,對項集進行映射,得到如表4所示的結果。
接下來,我們再次遍歷數據庫對結果集內容進行添加和更新,我們掃描S001的映射集得到項集{AB,AC,AH,BC,BH,CH,ABC,ACH,BCH,ABCH},對結果集中沒有的項集進行添加,已存在的項集更新其Value值,得到如表5所示的結果。掃描S002的映射集得到項集{AB,AD,BC,ABD},對于結果集中沒有的{AD,ABD}項集添加對應的Key和Value。對于已有的{AB,BC}更新其Value值,得到如表6所示的結果。掃描完所有的事務后得到如表7所示的結果。掃描完所有的事務后對結果集進行遍歷,去掉結果集中Value值小于閾值的項集,最后得到的頻繁項集是:{AB,BC,BH,CH,BCH}。
根據上述方法:網格劃分、DIC_Item,我們的改進算法:improved_algorithm過程如下:
算法2:improved_algorithm
輸入:用戶的軌跡數據;top-n的n值;頻繁項集支持度計數閾值sup。
輸出:推薦給用戶的top-n個用戶興趣區域
變量:SRS:用戶停留區域集;D:事務集;PIS:“興趣區域-用戶”事務數據(項為用戶)的最大頻繁項集;RPIS:“用戶-興趣區域”事務數據(項為興趣區域)的頻繁項集;F1:1階頻繁項集;G:網格集合;GS:當前網格中停留區域集合;GI:位于搜索區域的停留區域集合;SR,SI:停留區域;S:區域集合;DIC:結果集;SUS:相似用戶集;Result:推薦結果。
步驟:
步驟1是從用戶的軌跡數據中產生停留區域。步驟2是運用用戶和其停留區域等信息將軌跡數據轉化為事務數據集,其中2.1是將停留區域映射到網格中,2.2—2.8是遍歷網格找尋鄰近關系,利用鄰近關系找尋屬于同一個用戶興趣區域的停留區域并將其轉化為事務。步驟3是利用DIC_Item算法產生項為用戶的最大頻繁項集,其中3.1是第一次掃描事務并得到事務的映射集,3.2是第二遍掃描事務,同時更新結果集,3.3是判斷結果集中Value值大于支持度計數閾值的部分。步驟4是產生項為用戶興趣區域的頻繁項集。步驟5是產生相似用戶集。步驟6是產生top-n個推薦用戶興趣區域,其中6.1是產生候選推薦集、計算每一個候選用戶興趣區域的得分并按得分進行降序排序,步驟6.2返回top-n個用戶興趣區域。
4? ?實驗(Experiment)
第一,比較基本算法和改進算法在不同支持度計數閾值和不同事務數量條件下執行的時間效率。第二,比較三種算法的推薦質量:improved_algorithm算法、基于關聯規則推薦[9]和基于協同過濾推薦算法[10]。第三,通過實驗分析推薦top-n個用戶興趣區域給用戶中n值對準確率的影響。所有算法均采用C#進行編寫,并且在Core i3 1.8GHz和4GB內存的計算機上運行。
實驗中采用的數據有兩種:一種是真實的GPS軌跡數據,它記錄了182個用戶從2007到2012年的軌跡數據。另外一種是模擬數據,模擬數據是隨機產生的,用戶興趣區域和訪問過該興趣區域的用戶都是隨機產生。
4.1? ?時間性能的比較
對basic_algorithm算法和improved_algorithm算法進行時間性能的比較。實驗研究了事務數量和支持度計數閾值兩個參數對算法執行時間的影響
4.1.1? ?事務數量對算法執行時間的影響
首先,我們來評估事務數量對算法執行時間的影響。在這組實驗中,我們采用模擬數據,事務的數目從5000增加到20000。如圖4所示,隨著事務數目的增多,算法的執行時間也增大。因為隨著事務數目的增多,項集的數目也增多,所以相似用戶的數量和待推薦用戶興趣區域都會增多,計算推薦得分的次數也會增多。因此,算法執行時間增大。然而,改進算法在計算頻繁項集時不需要多次掃描數據庫,不采用連接產生候選項集,所以改進算法的執行時間比基本算法的執行時間少。從圖4可知改進算法improved_algorithm的執行時間沒有basic_algorithm增長迅速,這說明了改進算法improved_algorithm的效果。
4.1.2? ?支持度閾值對算法執行時間的影響
接下來我們分析支持度計數閾值對算法的影響,支持度計數閾值從8減少到2。如圖5所示,隨著支持度計數閾值的下降,算法的執行時間增加。這是因為支持度計數閾值變小后滿足閾值的項集會增多,從而產生更多的頻繁項集。由于本文衡量相似用戶是根據最大頻繁項集來進行衡量,所以最大頻繁項集增多相似用戶也會增多,向用戶進行推薦時需要計算更多相似用戶興趣區域的推薦得分。因此閾值下降,算法的執行時間增多。從圖5可以看出基本算法執行時間比改進算法執行時間增加得更快。因為基本算法會產生更多的候選模式及大量的連接操作。然而,改進算法不需要產生候選模式,并且它產生模式不需要連接操作。所以改進算法的時間增加的比較緩慢。
圖4 事務數目對算法執行時間影響
Fig.4 The impact of the number of transactions
圖5 閾值對算法執行時間影響
Fig.5 The impact of thresholds
4.2? ?準確率、召回率和F值的對比
接下來,我們對比改進算法、基于協同過濾推薦算法和基于關聯規則推薦算法三者的推薦質量。這部分實驗在真實數據上進行。我們用時間來對真實數據進行分類,分為2007年的數據、2008年的數據、2009年的數據、2010年的數據。2007年數據有10508條、2008年數據有19795條、2009年數據有51170條、2010年數據有10015條。推薦質量的對比算法在這四個數據集上進行。
推薦質量我們用準確率、召回率和F值來衡量。在本文中,我們將準確率定義為:推薦給用戶的用戶興趣區域集與用戶訪問興趣區域集的交集與用戶訪問興趣區域集之比。我們將用戶訪問過的興趣區域隨機的抹掉一部分,查看推薦給用戶的用戶興趣區域列表中包含多少抹掉的用戶興趣區域。
定義7(準確率)表達如下:
定義8(召回率)表達如下:
在準確率和召回率的定義中,m為用戶數目,|E(i)|為用戶i訪問用戶興趣區域被抹掉集合的長度,R(i)為推薦給用戶i的用戶興趣區域集合,為用戶i被抹掉的用戶興趣區域集合與推薦用戶興趣區域集合的交集的長度。
定義9(F值)表達如下:
其中,P為準確率,C為召回率。
在本組實驗中對三種算法的準確率、召回率和F值進行對比,參數設置如表8所示。如圖6所示,對比三者可知本文提出的算法準確率優于其他兩種算法。當數據量變化時,準確率會受一定的影響,但是從圖6中可以看出我們提出的算法波動較小,較為穩定。從圖7和圖8可以看出,我們提出算法的召回率和F值均優于對比算法。
4.3 top-n中n值對準確率的影響
我們將研究推薦top-n個用戶興趣區域給用戶的n值對推薦準確率的影響。如圖9所示,隨著n值的增加三個推薦算法的準確率也增加,但是improved_algorithm算法優于其他兩個算法。從圖7中可以看出我們提出的improved_algorithm算法在n=10時,算法的準確率較高,隨著n值的不斷增加,準確率緩慢的增加。這說明我們定義的用戶興趣區域推薦得分具有一定的合理性。用戶訪問可能性更高的用戶興趣區域,推薦得分更高,用戶興趣區域排名更靠前。所以當n值增大時,準確率不會急劇上升,因為用戶可能訪問的用戶興趣區域大部分包含在了top-10中,只會有少量出現在top-10后的推薦列表中。
圖8 F值的對比
Fig.8 Comparison of F
圖9 top-n中n值對準確率的影響
Fig.9 The impact of n on precision
5? ?結論(Conclusion)
由于許多推薦算法進行推薦時需要用戶的評分信息。這樣會因為缺少信息影響推薦質量。本文提出了一種不需要用戶評分數據的推薦算法。論文定義了停留區域,通過停留區域間的鄰近關系將用戶的軌跡數據轉化為事務數據,并基于挖掘到的最大頻繁項集來定義用戶的相似性。最后定義了推薦得分。在模擬數據和真實數據上進行了廣泛的實驗證明了提出方法的有效性,同時,將我們提出算法和基于協同過濾推薦算法、基于關聯規則推薦算法進行了對比,結果顯示本文提出算法具有更好的推薦效果。在接下來的工作中,我們將在本文基礎上擴展,將其運用于選址。
參考文獻(References)
[1] Bao J,Zheng Y,Wilkie D,et al.Recommendations in location-based social networks:a survey[J].GeoInformatica,2015,19(3):525-565.
[2] Xin M,Zhang Y,Li S,et al.A Location-Context Awareness Mobile Services Collaborative Recommendation Algorithm Based on User Behavior Prediction[J].International Journal of Web Services Research (IJWSR),2017,14(2):45-66.
[3] Wu T,Mao J,XIE Q,et al.Top-κ hotspots recommendation algorithm based on real-time traffic[J].Journal of East China Normal University (Natural Science),2017(5):195-209.
[4] Schafer J B,Konstan J,Riedl J.Recommender systems in e-commerce[C].Proceedings of the 1st ACM conference on Electronic commerce.ACM,1999:158-166.
[5] Berjani B,Strufe T.A recommendation system for spots in location-based online social networks[C].Proceedings of the 4th workshop on social network systems.ACM,2011:4.
[6] Hu L,Chen J,Shen S,et al.Recommendation Algorithm Research Based on Clustering on Users' Trajectories[C].Proceedings of the 29th CCF National Database Conference,2012:250-256.
[7] Liu Y,Pham T A N,Cong G,et al.An experimental evaluation of point-of-interest recommendation in location-based social networks[J].Proceedings of the VLDB Endowment,2017,10(10): 1010-1021.
[8] Agrawal R,Srikant R.Fast algorithms for mining association rules[M].Readings in database systems(3rd ed.).Morgan Kaufmann Publishers Inc.,1996.
[9] Kardan A A,Ebrahimi M.A novel approach to hybrid recommendation systems based on association rules mining for content recommendation in asynchronous discussion groups[J].Information Sciences,2013(219):93-110.
[10] Yi C,Leung H F,Li Q,et al.Typicality-Based Collaborative Filtering Recommendation[J].IEEE Transactions on Knowledge & Data Engineering,2014,26(3):766-779.
作者簡介:
龍玉絨(1994-),女,碩士生.研究領域:數據挖掘.
王麗珍(1962-),女,博士,教授.研究領域:數據挖掘,計算機算法.本文通訊作者.
陳紅梅(1976-),女,博士,副教授.研究領域:數據挖掘,人工智能.
