基于深度森林的安卓惡意軟件行為分析與檢測
2019-12-06 08:48:53石興華曹金璇蘆天亮
軟件 2019年10期
石興華 曹金璇 蘆天亮

摘? 要: 隨著移動互聯網漸漸滲入人們的日常生活,面向安卓的惡意軟件也對用戶產生著愈發巨大的負面影響。本文針對傳統安卓惡意軟件靜態檢測技術在檢測多分類惡意行為時準確性及靈活性的不足,提出了一種基于深度森林(Gcforest)的惡意軟件行為檢測機制,最后經過實驗測試與對比,證明此機制在惡意軟件行為檢測效果、參數調節難易度上具有明顯優勢。
關鍵詞: 安卓惡意軟件;靜態檢測技術;深度森林;多分類行為檢測
中圖分類號: TP311.56? ? 文獻標識碼: A? ? DOI:10.3969/j.issn.1003-6970.2019.10.001
本文著錄格式:石興華,曹金璇,蘆天亮. 基于深度森林的安卓惡意軟件行為分析與檢測[J]. 軟件,2019,40(10):01-05+72
Analysis and Detection of Android Malware Based on Gcforest
SHI Xing-hua, CAO Jin-xuan*, LU Tian-liang
(School of Information Technology and Network Security, People's Public Security University of China, Beijing 100038, China)
【Abstract】: As the mobile Internet gradually infiltrates into People's Daily life, android malware also has an increasingly large negative impact on users. Based on the traditional static testing technology in android malware detection has more classification accuracy when the malicious behavior and the lack of flexibility, this paper proposes a detection method based on Gcforest malware behavior. Finally, through experimental test and comparison, it is proved that this method has obvious advantages in the detection effect of malware behavior and the difficulty of parameter adjustment.
【Key words】: Android malware; Static detection technology; Gcforest; Multi-classification behavior detection
0? 引言
近幾年,隨著安卓市場的不斷擴大,安卓惡意軟件也越發猖獗。2018年全年,360互聯網安全中心共截獲移動端新增惡意軟件樣本約434.2萬個,平均每天新增約1.2萬個[1],對安卓系統的生態環境造成了極大的安全威脅。
安卓惡意軟件對用戶或系統安全的破壞主要體現為以下幾種行為:第一類是通過對系統設置進行惡意更改,使系統無法正常運行甚至宕機;第二類是對用戶數據的監聽與竊取,對用戶的隱私安全造成損害;第三類是誘使用戶點擊某個假按鈕、假鏈接跳轉到病毒網站或直接發送付費短信到虛擬號碼,對用戶造成不同程度的財產損失。
本文根據對安卓惡意軟件及現有檢測方法進行深入研究后,借鑒深度森林算法[2]在應用軟件缺陷預測[3]、漏洞挖掘[4]等領域取得成功的經驗,提出了一種基于深度森林的惡意軟件行為檢測機制。本文除了對機制中具體特征提取、數據處理、模型訓練等模塊做詳細說明外,還與惡意軟件行為檢測常用的隨機森林、深度學習方法進行了測試與對比,實驗證明本文所用機制在惡意軟件行為檢測效率及參數調節上具有明顯優勢。
1? 相關研究
1.1? 惡意軟件檢測技術
對安卓惡意軟件的安全檢測方法可以分為動態和靜態檢測技術。動態檢測技術是將待檢測軟件置于虛擬機或沙箱等真實環中運行,通過收集其網絡流量數據并對比惡意軟件樣本庫來確定是否為惡意軟件[5-6]。
相對于動態檢測,運用特征進行學習的靜態檢測技術[7]能夠更加準確地對惡意軟件的特征進行刻畫,且只需要在模型的一次訓練上投入時間成本。在特征選取方面,一般會選取metadata(元數據)和申請權限[8]API Calls(API調用)[9];機器學習算法方面,常用的有Bayesian(貝葉斯)算法[10]、深度學習等[11]。目前國內外對安卓惡意行為檢測研究在準確度方面取得了很好的效果,但對參數調節的準確度要求太高,且局限于將應用軟件進行二分類預測,即為惡意還是良性,卻沒有對安卓惡意軟件具體行為進行更加細粒度的劃分。
1.2? 深度森林算法
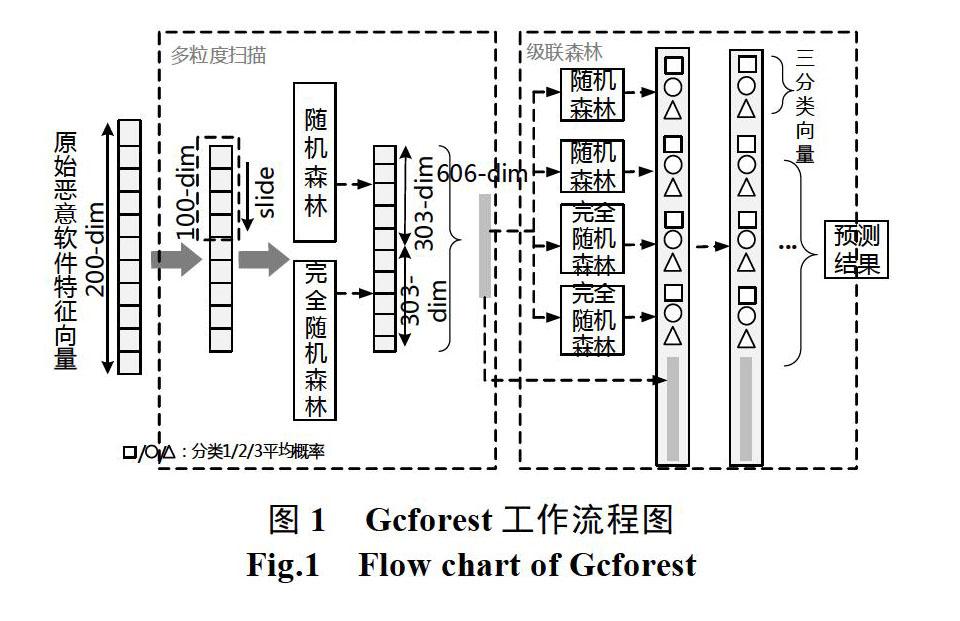
深度森林,又叫多粒度級聯森林(multi-Grained Cascade forest,Gcforest)[2]是南京大學周志華教授所提出的一種通過對集成決策樹所構建的級聯結構進行學習的分類算法。Gcforest主要包含級聯森林結構和多粒度掃描結構兩部分。
級聯森林中每一層都由多個隨機森林組成。為了增強模型表征的泛化能力,每層的隨機森林都會包含完全隨機森林(completely-random tree forests)和一般隨機森林(random forests)的隨機組合。
多粒度掃描過程中,受神經網絡在處理特征關系方面的啟發,Gcforest也使用滑動窗口來掃描原始特征。在處理如惡意軟件特征的序列數據時,得到特征向量個數的計算公式:
(1)
其中,表示原始特征維度;表示滑動窗口大小,滑動過程從數據“頭”到“尾”。假設有200-dim的惡意軟件特征數據,需要對其進行三分類:首先采用100-dim的滑動窗口進行處理,則會得到101個100-dim的特征向量。將得到的特征向量放入到級聯森林第一層中進行訓練,會根據樹的大小和分類情況得到類分布向量,然后把類分布向量與滑動窗口處理得到的101-dim特征向量進行拼接,并作為第二層級聯森林的輸入數據,重復此過程,直到驗證收斂。Gcforest中對特征向量進行一次轉換及處理的整體工作流程如圖1所示。
2? 基于Gcforest的惡意軟件行為檢測機制
為了對安卓惡意軟件進行有效的評估與識別,本文提出了基于Gcforest的惡意軟件行為檢測機制,如圖2所示。本檢測機制運用反編譯工具、Python編程,整個流程可分為特征提取、機器學習檢測模型訓練、未知惡意軟件行為識別三部分。
其中,特征提取模塊用于提取惡意及良性軟件中的敏感權限、服務及API調用特征并對惡意軟件行為進行分類,然后將這兩部分結果合并規范化為獨熱編碼(One-HotEncoding)的特征向量;模型訓練模塊是將規范化的特征向量放入Gcforest算法模型中進行多分類訓練;行為識別模塊用于選取樣本測試集并將其放入多分類模型中進行惡意軟件行為分類測試,并因此來評價模型效果。
3? 數據預處理
3.1? 樣本收集
本文從實驗室及研究機構共獲取惡意安卓軟件30608個;利用爬蟲從安卓官方應用市場Google Play爬取安卓社交類、購物類等軟件共13004個。因為Google Play本身就有嚴格的惡意軟件安全檢測機制,所以默認所爬取的應用軟件都不具備惡意行為;為了進一步研究惡意軟件行為,將惡意安卓應用軟件放入VirusTotal網站中進行標注并保存其惡意軟件家族屬性,一共得到71種不同的惡意軟件家族,按照出現次數進行排序后的前10種惡意軟件家族情況如表1所示。
因為有些惡意家族的樣本收集較少,如“Fobus”的數量僅為4,但為了后續分類的準確性,均勻選取71種家族的惡意軟件樣本1060個加上篩選掉極端大小的良性樣本1050個作為后續特征提取及模型訓練的惡意及良性軟件樣本。
3.2? 特征提取
對惡意軟件特征提取選取時,選取API調用、服務及敏感權限。API調用[12]體現了不同安卓軟件實現的不同功能;敏感權限和服務[13]則體現了軟件對系統網絡連接、硬件設備或系統資源的調用情況。對這三種特征的提取既可以細致地刻畫惡意軟件的行為特征,又可以對惡意軟件及良性應用軟件進行更好地區分。因所收集的安卓軟件樣本是經過編譯后的通用二進制文件,即APK(Android Package),需使用工具Apktool進行反編譯處理[14],處理后的每個APK文件結構如圖3所示。
在圖3所示文件結構中,應用軟件所聲明的所有權限及服務都可直接從AndroidMenifest.xml中提取;API,即方法調用則通過掃描smali反匯編文件代碼及PScount提取過濾。排除掉一些無法提取特征的無效APK,最后得到1011個惡意軟件和1006個軟件樣本的特征共217種,其中包括敏感權限111種、服務39種及API調用29種。其中出現頻率前10名的API調用特征分布情況分別如圖4所示。
3.3? 惡意軟件行為分類
根據圖4可以看出在三種不同的特征中惡意軟件及良性軟件的區別非常大。對于敏感權限來說,除了一些基本的網絡連接及網絡狀態獲取權限外,惡意軟件會更頻繁地獲取額外的如地理位置
和開啟自啟動的權限;服務在安卓系統后臺服運行,通常會被惡意軟件利用來獲取用戶隱私信息,服務的命名并不由安卓提供,但可以根據提取的大量惡意軟件樣本中的權限命名學習到一些規則,比如“baidu. location.f”一定是用來后臺獲取用戶所在地;安卓API調用如“get DeviceId”、“send Text Message”就會涉及到讀取用戶終端信息、私自發送短信等方面。也進一步說明了使用敏感權限、服務、API調用特征來判斷安卓惡意軟件行為確實是可行的。
據分析提取自41種惡意家族的共2017個有效樣本的特征,可以將安卓惡意行為總結為三類:Variety1為私自獲取、收集用戶終端、聯系人、位置等隱私信息的行為;Variety2為收發付費短信或撥打付費電話等危害用戶財產安全的行為;Variety3為更改系統設置,如強行自啟動、更改系統時間、安裝子惡意軟件等行為。針對表1中前10種惡意軟件家族行為的分類情況如表2所示。
3.4? 征向量化及篩選
首先將敏感權限、服務、API調用三種特征按序排列,再將每個軟件樣本得到的217種特征表示為一個多維二進制布爾型特征向量。如某軟件包含第i個特征(0≤i≤217),則表示為,否則用表示。則分類后的樣本j的特征向量可以表示為:, ,表示前一章節劃分的三種惡意行為,表示正常軟件行為。最后形成如下特征矩陣:
(2)
據以上提取分析得到的特征一共有217個,但
當中有很多特征如“INTERNET權限申請”對惡意行為分類的結果貢獻并不大,所以需要對特征向量進行篩選。在二分類的一般問題中,一般采用基于信息增益的PCA(Principal Component Analysis,主成分分析)方法進行降維;本文涉及到的多分類算法采用ReliefF算法[15][16]進行降維。算法主要思想是通過迭代t次找出與樣本不同類的m個最近鄰來更新輸入的d個特征C的權值,如公式所示:
(3)
其中表示與樣本同類的m個最近鄰;表示樣本S、N關于特征C的距離;表示類目標的概率。求出量化的特征值后,權值越大則該特征對樣本的區分能力越好,計算后按權值大小排名篩選出前20種軟件行為特征,特征前10名如表3所示。
4? 模型訓練
本文選取以上提取的包含20種特征的2017個惡意軟件(惡意1011、良性1006)作為訓練集對深
度森林算法進行訓練。實驗系統為Ubantu7.3.0-16;編程語言選擇Python,首先應該在本機中安裝Gcforest庫,然后調用GCForest模塊。
Gcforest模型訓練的配置分三類情況,分別是采用默認的模型;只有級聯森林部分;多粒度掃描加級聯森林三種。超參數是指在機器學習上下文中出現的框架參數。為了增加算法參數的可調節性,本文選用多粒度掃描加級聯森林模式,其超參數包含:
(1)n_mgsRFtree:多粒度掃描期間隨機森林中樹的數量;
(2)max_depth:級聯層中決策樹最大深度;
(3)windows:多粒度掃描期間滑動窗口的大小;
(4)n_cascadeRF:級聯層中隨機森林的數量;
(5)n_cascadeRFtree:級聯層中隨機森林中樹的數量;
(6)tolerance:級聯森林生長的精度差,用于控制級聯在何種情況下停止。
5? 實驗對比與分析
本文選取最初收集的43612個安卓軟件中惡意、良性各1000個作為測試集樣本。為了驗證本文檢測機制的效果,本文還選取了深度學習及隨機森林方法作為對照。
5.1? 模型評價指標
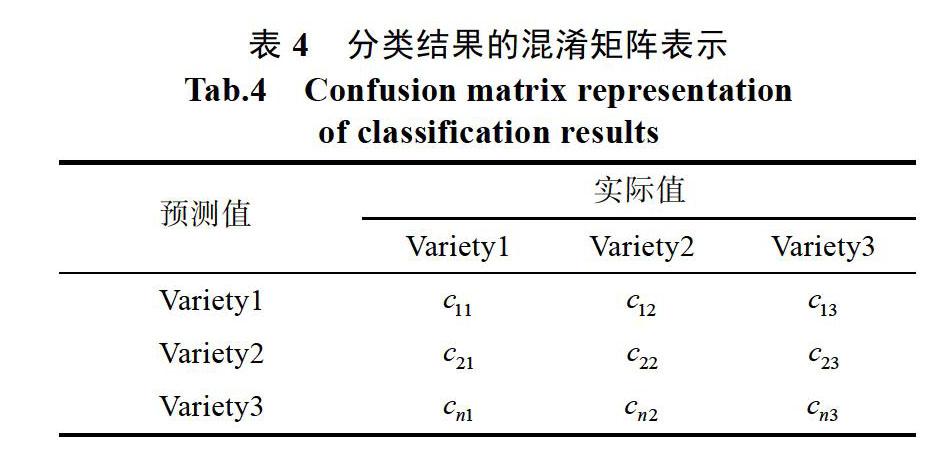
多分類預測模型的評價指標一般是使用準確率(precision)和召回率(recall)。前者表示X類的數據中有多少是預測正確的;后者表示有多少X類的數據被正確預測了,本文還使用F_score作為評價指標。首先使用混淆矩陣(交叉表)表示此次分類的結果,如表4所示。
則對于第i個類別(1≤i≤n)的準確率和召回率為:
(4)
其中,分別表示矩陣(表4)中的一行與一列。而對于i分類的為:
(5)
本文選擇,即常見的F1指標。從公式中可以看到,F_score綜合了precision和recall的結果,與實驗方法的有效性成正相關。F_score_avg為各分類F_score的算術平均,用來衡量本次各算法對本次分類的總體效果,計算方法如下:
(6)
5.2? 檢測結果
將實驗各算法的參數調節完畢后,得出的各分類預測結果如表5所示。
表5中,比較F_score值可以看出三個算法對Variety0即正常軟件行為的分類效果最好;據F_score_avg值可以看出深度學習和本文深度森林算法的整分類效果要優于隨機森林算法,而深度森林算法無論是在precision還是recall都較略優于深度學習算法,F_score_avg也達到了87%。實驗過程中還發現對于深度學習的參數調節困難較大,在模型準備階段的耗時較長,且不像深度森林算法有默認配置模型供選擇。綜上所述,深度森林在處理惡意軟件行為多分類問題上具有明顯的優越性。
6? 結論
本文提出了基于深度森林算法的惡意軟件行為檢測機制。首先通過反編譯提取了惡意及良性樣本中的敏感權限、服務、API調用特征,然后基于惡意軟件家族及具體特征確定了三種惡意軟件行為,再將加上良性行為的四種行為特征向量化,最后輸入到深度森林(GcForest)算法模型中進行訓練。通過將另選取樣本測試集對隨機森林、深度學習及本文的深度學習算法的分類情況進行測試與比較,證明了本文所提基于深度森林的惡意軟件行為監測機制無論是在參數調節難度還是在檢測效果方面都要明顯優于其他檢測方法。
參考文獻
[1] 360烽火實驗室. 2018年Android惡意軟件專題報告[OL]. [2019-5-21]. https://www.anquanke.com/post/id/171110.
[2]Zhou Z H, Feng J. Deep Forest: Towards An Alternative to Deep Neural Networks[J]. 2017.
[3]薛參觀, 燕雪峰. 基于改進深度森林算法的軟件缺陷預測[J]. Computer Science, 2018, 45(8): 160-165.
[4]Ghaffarian S M, Shahriari H R. Software Vulnerability Analysis and Discovery Using Machine-Learning and Data- Mining Techniques[J]. ACM Computing Surveys, 2017, 50(4): 1-36.
[5]Onwuzurike L, Almeida M, Mariconti E, et al. A Family of Droids-Android Malware Detection via Behavioral Modeling: Static vs Dynamic Analysis[J]. 2018.
[6]鮑美英. 基于改進決策樹分類的Android惡意軟件檢測[J]. 軟件, 2017, 38(2): 33-36.
[7]洪奔奔, 管聲啟, 任浪, 高磊. 基于特征提取與匹配的帶鋼缺陷檢測[J]. 軟件, 2018, 39(9): 31-34.
[8]Martín Ignacio, Hernández José Alberto, Alfonso M, et al. Android Malware Characterization Using Metadata and Machine Learning Techniques[J]. Security and Communication Networks, 2018, 2018: 1-11.
[9]An Android Malware Detection System Based on Feature Fusion[J]. Chinese Journal of Electronics, 2018, 27(6): 100- 107.
[10]Yerima S Y, Sezer S, Mcwilliams G, et al. A New Android Malware Detection Approach Using Bayesian Classification [C]//2013 IEEE 27th International Conference on Advanced Information Networking and Applications (AINA). IEEE, 2013.
[11]Su X, Zhang D, Li W, et al. A Deep Learning Approach to Android Malware Feature Learning and Detection[C]//2016 IEEE Trustcom/BigDataSE/I SPA. IEEE, 2016.
[12]Salehi Z , Sami A , Ghiasi M . Using feature generation from API calls for malware detection[J]. Computer Fraud & Security, 2014, 2014(9): 9-18.
[13]侯蘇, 杜彥輝, 蘆天亮, 等. 基于K-means算法的Android權限檢測機制研究[J]. 計算機應用研究, 2018, 35(4): 1165-1168.
[14]杜煒, 李劍. 基于半監督學習的安卓惡意軟件檢測及其惡意行為分析[J]. 信息安全研究, 2018, 4(3): 242-250.
[15]Lim S C, Jang S J, Lee S P, et al. Music genre/mood classification using a feature-based modulation spectrum[C]// International Conference on Mobile It Convergence. IEEE, 2011.
[16]黃莉莉, 湯進, 孫登第, 等. 基于多標簽ReliefF的特征選擇算法[J]. 計算機應用, 2012, 32(10): 2888-2890.
