基于數據模糊化處理的數據脫敏研究
2019-12-06 08:48:53羅長銀陳學斌
軟件 2019年10期
羅長銀 陳學斌


摘? 要: 隨著大數據產業的飛速發展,數據泄露和信息泄露事件也越來越多,基于這種情況下,如何對數據有力的保護成為我們研究的重點內容,本文利用簡單替換加密和維吉尼亞兩種傳統的算法對數據進行加密,利用模糊集里面的隸屬函數的方法,對數據進行簡單的模糊化處理,并且運用匹配度公式和模糊量詞的方法,對數據信息進行進一步的泛化處理,對單數據源的信息的保護起到了預期的效果。
關鍵詞: 數據泄露;簡單替換算法;維吉尼亞算法;模糊量詞
中圖分類號: TP391? ? 文獻標識碼: A? ? DOI:10.3969/j.issn.1003-6970.2019.10.002
本文著錄格式:羅長銀,陳學斌. 基于數據模糊化處理的數據脫敏研究[J]. 軟件,2019,40(10):0610
Research on Data Desensitization Based on Data Fuzzy Processing
LUO Chang-yin, CHEN Xue-bin*
(North China University of Science and Technology,Key Laboratory of Data Science and Application of Hebei
Province Tangshan Data Science Key Laboratory, Hebei Tangshan 06300 china)
【Abstract】: With the rapid development of the big data industry, data leakage and information leakage have become our familiar terms. In this case, how to effectively protect data has become the focus of our research. In this paper, two traditional algorithms, simple replacement encryption and Virginia, are used to encrypt data, and the membership function in the fuzzy set is used to encrypt data. Simple fuzzification processing, and the use of matching degree formula and fuzzy quantifier method, further generalization of data information processing, The protection of single data source information has achieved the desired results.
【Key words】: Data leakage; Simple replacement; Virginia; Fuzzy quantifiers
0? 引言
隨著大數據在快速發展,也給人們帶來了許多方面的挑戰,首當其沖的就是信息安全的問題。比如今年剛結束的兩會,人大委員張業遂就說:通過立法加強個人信息保護成為必然要求[1];360集團董事長兼CEO就說:安全應該成為發展人工智能的基礎和前提[2]。甚至李克強總理在中國大數據產業峰會上就明確指出信息網絡和數據安全是全球性的挑戰,中國也不例外。由此可見,數據保護已經成為我們全球范圍性的急需要解決的事情之一。
1? 預備的知識
模糊量詞[3]是一個跨學科的研究對象,涉及數學、邏輯學、語言學、計算機科學、智能科學等廣泛領域。模糊量詞(也被成為語言量詞)是指大多數、少數、大約十個、不多幾個等表示不確切數量的語言成分。
模糊集[4]:設區域,U到閉區間[0,1]的任一映射為:
(1)
(2)
確定了U的一個模糊子集,簡稱模糊集,記作A。稱為模糊集A的隸屬函數,的大小反映了x對模糊集合A的隸屬程度,簡稱為隸屬度。就是說,論域U={x}上的模糊集合是指x中具有某種性質的元素全體,這些元素具有某個不分明的界限。對于U中任一元素,都能根據這種性質,用一個[0,1]上的函數來表征該元素屬于A的程度。論域元素總是分明的,只有x的模糊子集A,B等才是模糊的,所以模糊集通常是模糊子集。的值接近于1,表示x屬于A的程度高;接近于0,表示x屬于A的程度低。
數據脫敏[5]是指對某些敏感信息通過脫敏規則來進行數據的變形,實現對敏感數據甚至于隱私數據進行保護。在不違反系統規則的前提下,以及客戶允許的情況下對客戶提供的真實的數據進行改造并且提供測試使用,比如身份證號碼、出生日期、學生在校時所填的信息等等都需要我們進行脫敏。或許你在不經意間就有可能把你的隱私數據泄露出去,比如出生證明里面的東西可能成為你個人或者一個家庭的銀行卡或者其他情況的密碼。由此可見,個人的信息泄露已經成為信息社會日益凸顯的問題。
2? 敏感數據的分類[6]
首先,我們應該對敏感數據的規則進行分類:分為可恢復與不可恢復兩類。可恢復類指脫敏后的數據可以通過一定的方式,恢復成原來的敏感數據,此類脫敏規則主要指各類加解密算法規則。不可恢復類指脫敏后的數據被脫敏的部分使用任何方式都不能恢復,般可分為替換算法和生成算法兩類。
數據脫敏方案分為靜態數據脫敏和動態數據脫敏。靜態數據脫敏是對原始數據進行一次脫敏后,脫敏后的結果數據可以多次使用,適合于使用場景比較單一的場合。動態數據脫敏是在敏感數據顯示時,針對不同用戶需求,對顯示數據進行屏蔽處理的數據脫敏方式,要求系統有安全措施確保用戶不能夠繞過數據脫敏層次直接接觸敏感數據。
3? 數據脫敏技術[8]
傳統的數據脫敏技術方式主要包含了替代、混洗、數值變換、加密、遮擋、空值插入、刪除等。數據脫敏技術類型一般采用泛化技術、抑制技術、擾亂技術和有損技術。泛化是指在保留原始數據局部特征的前提下使用一般值替代原始數據,泛化后
的數據具有不可逆性。抑制是指通過隱藏數據中部分信息的方式來對原始數據的值進行轉換,又稱為隱藏技術。擾亂是指通過加入噪聲的方式對原始數據進行干擾,以實現對原始數據的扭曲、改變,擾亂后的數據仍保留著原始數據的分布特征。有損是指通過損失部分數據的方式來保護整個敏感數據集,適用于數據集匯總后才構成敏感信息的場景。
4? 數據的預處理
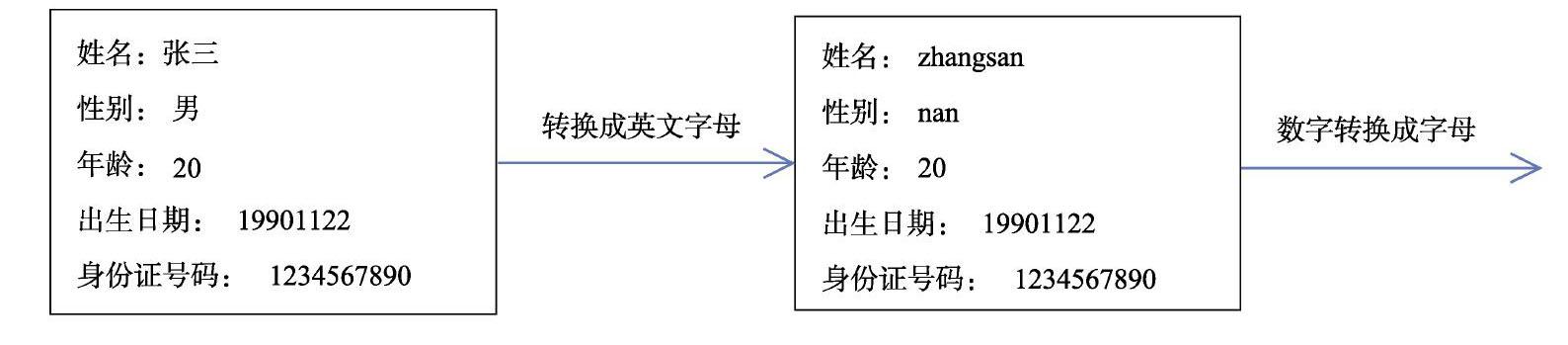
隨著大數據產業的興起,數據的脫敏問題成為我們要解決的首要問題,本文將泛化技術與加密技術相結合,對數據的脫敏進行一定程度上的分析。對于泛化技術,我們將采用模糊量詞的概念和匹配度公式對其進行操作,而加密技術我們將采用簡單替代加密法和維吉尼亞加密法的聯合對其加密。我們將把生活中所有的信息用26個英文字母的大小寫來表示,再對其進行泛化。
首先,我們將敏感信息中非數字、字符、符號的信息進行字母化處理,即先把中文漢字轉換成字母的形式。接著把數字轉換成英文字母的形式。我們可以人為的隨機的規定字母表的大寫部分代表0-4,而小寫部分代表5-9,我們可以隨機的分配一定的比例來表示0-4分別代表著什么字母,比如:我們用A-G代表0,H-N代表1,O-T代表2,U-W代表3,X-Z代表著4,依次類推,我們可以隨機的用a-z來表示5-9,本文我們將采用random.randint()這個隨機函數,隨機的用一些字母來表示這些數字。
5? 數據的加密處理
我們采用簡單替換加密算法對其加密以及RSA加密算法對其加密。簡單替換加密我們采用:VJZBGNFEPLITMXDWKQUCRYAHSOvjzbgnfeplitmxdwkqucryahso作為密匙來進行加密,可以得到的加密的消息,這里的采用大小寫可以互相轉化的方式,以此來增加其加密的復雜程度。維吉尼亞加密法的密匙是一系列的字母,可以是我們所有隨機產生的52個字母的隨機組合。比如下例就是用的是PIZZA來進行加密的。比如:
最后,我們可以采用模糊量詞的概念對加密后所得到的信息進行泛化處理。例如上面最后一個文本框中的敏感信息我們可以這樣描述,我們定義大寫字母為小,小寫字母為大,因此我們可以這樣說,大約有一大半的信息屬于小,少數的信息屬于大,如果當一個屬性中都存在大小寫字母的時候,以隸屬度函數得到的結果為準。
6? 數據的模糊化處理
對加密后的信息進行數據模糊化處理,主要是利用其隸屬函數對其操作,對于那些加密前后所得到的信息有著很明顯的規律的信息,隸屬函數的個數應該多選些。而對于那些加密前后的信息不明顯的可以少選些。對于這些加密后的信息,采用多個三角形分布或者梯形分布的模糊數來表達其選取的特征的空間分布,特征空間選擇為平均分割形式,以便我們根據隸屬度是否為0來判斷該特征是否屬于一個模糊子集。因此,對于我們所得到的加密信息就可能得到多個輸入特征的模糊隸屬函數[9]。應用模糊數學來解決實際問題,基本步驟是尋找一個或幾個隸屬函數。這個問題解決了,其他問題就迎刃而解。最簡單的隸屬函數是三角形,它是用直線形梯形隸屬函數實際上是由三角形截頂所得的。它們的形狀見圖(1)和圖(2)所示。
對于三角形的隸屬函數,其表達式可以表示為:
對于梯形的隸屬函數,其表達式可以表示為:
其中。
利用隸屬函數的表達式就可以取得相應的隸屬度。這兩種直線形隸屬函數都具有簡單的優勢,因而經常被人們利用,本文分別采用這兩種隸屬函數對加密后的信息進行模糊化處理。例如:針對我們所加密后的信息,其屬性分別為:姓名、性別、年齡、身份證號碼、出生日期,因為在前面我們規定了小寫字母為大,用隸屬區間中的1來表示,相反,大寫字母就為小,就用隸屬區間中的0來表示。因此我們對于多數人的姓名信息來說,就有以下的模糊數據表。
同理,我們將對其他的信息進行處理分別得到性別、年齡、身份證號碼、出生日期的模糊化處理表。
從上述的表中很清楚的知道每個信息里面所包含的隸屬度,根據此隸屬度再結合模糊量詞以及匹配度公式,可以計算出每個信息中的匹配度,看是否能夠達到預期的效果。例如:我們依次得到了5個信息里面的每個字母的隸屬度,采用除去最大值和最小值之外的所有字母的隸屬度的平均值的方法來表達其每個信息的整體的隸屬度。我們通過調研的方式和詢問相關專家的意見,他們分別給出了其重要程度,用A表示:A(姓名)=0.4,A(性別)=0.3,A(年齡)=0.45,A(出生日期)=0.7,A(身份證號碼)=0.85。
參考了相關的匹配度公式的文章,我們定義了本文的匹配度公式:
(i=1,2,3,4,...,n)
表示其權值(重要性程度),n代表屬性的個數。
(j表示每個屬性中每個字母所得的隸屬度)我們就依次得到了每種信息的匹配度,依次就能看出哪些信息對于我們來說比較重要,也就是我們的隱私數據。哪些數據為一般數據。
處理后的模糊化數據如下屬性信息表所示。
屬性名稱 姓名 性別 年齡 出生日期 身份證號碼
匹配度(pi) 0.4122 0.3 0.35 0.6 0.8
從表中我們可以看到年齡的重要性和姓名相差不多,就表明其實年齡也是我們應該注意的信息,但是被很多人給忽視掉了。
利用模糊量詞再一次模糊化處理,如下表所示。
相比較傳統的模糊數據集的處理方法,我們采用的是多個三角形分布或者梯形分布的模糊數來表達信息的模糊度,可以使模糊程度在原有的基礎上得到加強。而且匹配度公式的創新,使我們得出日常生活中需要被注意的數據而讓我們忽視的數據。得出這些數據之后,我們用模糊量詞的方法對處理后的數據再一次進行模糊化處理。傳統技術中簡單的運用模糊集的方法對數據進行模糊化操作后得到的數據,造成的信息泄露的幾率明顯的高于本文所用方法的幾率。
