基于ARMA模型的我國油菜籽單產預測分析
2019-12-06 06:21:15邵艷君
中國市場 2019年28期


[摘要]隨著我國人口的增長,農產品的單產一直備受關注。油菜籽作為油菜的種子和油料的原料,在農產品中占有重要地位。文章將采用國家統計局在1985—2017的數據,對其中1985—2014年的數據進行分析,建立ARMA模型,用2015—2017的數據進行擬合結果檢驗,并預測出2018—2020年的油菜籽單位產量,為油菜的留種和播種提供一定的指導。
[關鍵詞]ARMA模型;油菜籽;單產預測
[DOI]1013939/jcnkizgsc201928050
1引言
農作物的單產一直是農學界關注的重點之一。[1]我國人口增長和耕地減少的現象使得我國油菜的單產越來越受到重視[2],油菜籽是油菜的種子,也是油菜種中油料的主要來源,所以預測分析我國油菜籽的單產對指導油菜的留種和播種具有現實意義。
在估測油菜單產時,蔡承智等利用ARIMA模型預測了2017—2020年我國的油菜單產,為油菜的生產提供一定的決策依據,提出著重改良中低耕地,并同時保持高產耕地的策略;[3]熊艷芳等預測了油菜籽的生產效率,根據1987—2009年的數據,采用最小二乘法并考慮了油菜籽的技術創新對產量的影響。[4]蔣貴飛提出了考慮油菜籽的種植密度來提高油菜的種植品質,并利用BP神經網絡預測油菜品質。[5]但是,運用ARMA模型宏觀預測油菜籽單產的文獻鮮見。
常用的預測模型需要結合必要的生長因子等大量歷史數據,盡管運算結果可靠性高,但運算過程比較復雜。文章所采用的ARMA模型不用考慮油菜籽種植的影響因素,也不用考慮生產投入要素變化。因為這些投入變量理論上都是隨時間變化的,故可以采用 “時間序列”來集中反映影響因素和投入變量的變化[3]。該模型需要的數據量較少,計算也比較方便,但預測結果可靠性受“時間序列”數據平穩性的影響,且只能進行短期預測。
2基于ARMA模型的我國油菜籽單產預測
文章采用1985—2014年我國油菜籽單產數據建立ARMA模型,用2015—2017的數據檢驗擬合結果,進而預測2018—2020年我國油菜籽的單產值。ARMA模型主要用于預測分析“時間序列”變量的宏觀變化趨勢,是較為公認的預測方法。該方法要求變量隨時間推移呈現一定變化趨勢,且每個步驟符合模型的推理邏輯,但不要求考慮變量的影響因子。1985—2014年我國油菜籽單產的歷年統計值變化隨時間在波動中保持增長趨勢,如圖1所示。因此可以選擇ARMA模型進行短期趨勢預測分析。
運用ARMA模型的預測步驟為:首先,檢驗1985—2014年我國油菜籽單產數據的平穩性。其次,選擇、建立、擬合相應ARMA模型,通過與2015—2017年統計數據的比較判斷擬合效果。最后,運用ARMA模型對2018—2020年我國油菜籽單產進行預測分析。
3我國油菜籽單產預測模型建立
31數據預處理
1985—2014年我國油菜籽單產“時間序列”數據ADF單位根檢驗結果如表1所示。
t統計量低于在5%和10%水平下的臨界值,表明我國油菜籽單產“時間序列”在90%和95%的置信度下,時間序列平穩(歷史數據具有一定的可靠性),不需要進行差分處理,可以基于該數據對數值構建預測基礎數據。
為了選擇擬合度最高的模型預測我國油菜籽單產,參考自相關(AC)和偏自相關(PAC)的統計圖,確定階數p、q的取值,建立基礎模型。AC值的檢驗結果是拖尾,而PAC的檢驗結果也是拖尾,由此判斷可以采用ARMA模型。
32建立預測模型
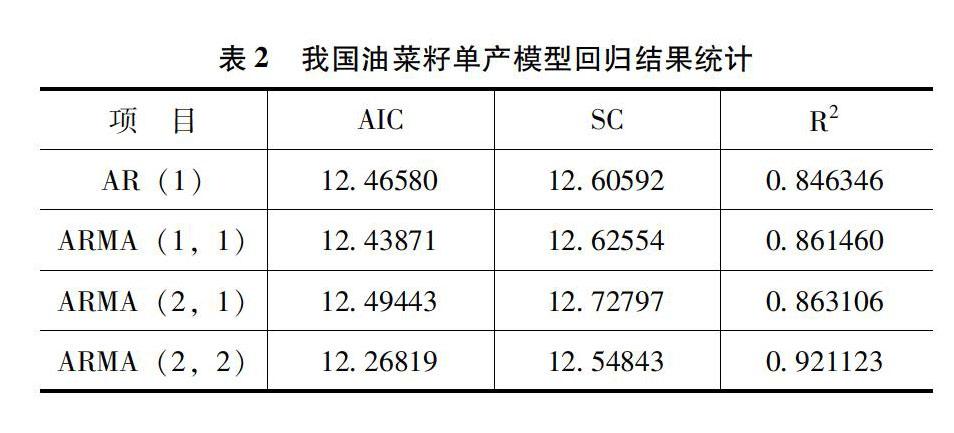
為了選擇擬合度較高的模型,在建立完全符合AC與PAC的檢驗結果的AR(1)模型后,采用逐步回歸,嘗試了其他ARMA模型的擬合結果,并將各個模型的擬合結果進行了比較。檢驗結果如表2所示。
從表中可以看出,根據模型的回歸結果,可以分別得出四個模型赤池信息準則(AIC)和施瓦茨信息準則(SC)的取值,因為這兩個值在模型的擬合中越小說明的擬合效果越好,所以分析比較表2中的數據,可以看出ARMA(2,2)模型的AIC和SC最小,R2的值最大,并且R2的結果變大的比較明顯,所以最后選擇ARMA(2,2)模型來對我國油菜籽單產的情況進行預測。
根據Eviews 90軟件的運行結果可以估計出ARMA(2,2)模型的系數,由于滯后階數為2,由原方程模型:
q=c+φ1qt-1+φ2qt-2+εt+θ1εt-1+θ2εt-2
結合如表3所示的模型系數估計結果,得出我國油菜籽單產的預測模型為:
q=1565023+1987423qt-1-0999999qt-2+εt-1987805εt-1+0999800εt-2
4我國油菜籽單產預測分析
41模型檢驗
通過對擬合結果進行分析比對,證實擬合結果具有一定的可信度,在具體的取值上有一些滯后性,但基本符合變化趨勢。對估計后的殘差序列進行白噪聲檢驗,結果顯示模型殘差序列的樣本自相關數和偏相關數都落入隨機區間內,所有Q值都小于005 的檢驗水平下的分布臨界值,所以殘差序列是白噪聲序列,模型是顯著有效的。通過對回歸方程的殘差序列進行單位根檢驗,結果如表5所示。
t統計量低于在5%和10%水平下的臨界值,表明我國油菜籽單產“時間序列”在90%和95%的置信度下,殘差序列保持穩定,所以ARMA可以用于我國油菜籽單產預測。
42我國油菜籽單產預測分析
根據ARMA(2,2)模型對我國2018—2020年的數據進行如圖7所示的預測。在Eviews 90軟件中在估計模型下對數據進行預測,結果如表6所示,將2015—2017年的數據作為比對數值,來考慮2018—2020年的數據可信度。
根據2015—2017年的差值以及之前一些年份根據ARMA(2,2)模型的預測結果可以看出,前期模型的差值較小,后期擬合之后的數值,普遍比真實值要小,所以在針對之后2018—2020年的油菜籽單產數據進行分析的時候可以適當地在預測值上進行擴大化預測,一定程度上可以更貼近真實值,從而對我國油菜籽的產量進行有效的管理。
5結論
文章中分析得出的ARMA模型擬合值雖然高,但是與實際值仍有一定的差距,并且在后期的預測中,預測的數據普遍偏小,這是數據本身缺少了考慮重大的技術突破[4],或者耕地面積的增大等政策對分析數據會造成的影響,但是就預測數值本身而言,在僅僅以數據為參考進行分析的情況下,能夠較好地得出一個接近的數據,并且該數據具有一定的參考價值,也是文章的價值所在,后期可以對預測數值與實際數值的差值進行分析,從而將差值的擾動因素加入模型,提高模型預測的精準度。從文中的數據可以猜測出,油菜籽單產數據估計在后期進行調控的時候可以適當地在預測值上進行擴大化預測,保證在一定程度上更貼近真實值,從而讓管理部門對近些年的產量有初步的判斷,進而進行油菜播種和留種前期的調控。
參考文獻:
[1]吳麗麗,李谷成,尹朝靜生長期氣候變化對我國油菜單產的影響研究——基于1985—2011年中國省域面板數據的實證分析[J].干旱區資源與環境,2015,29(12):198-203
[2]劉愛民,賈盼娜,王立新,等我國飼(草)料供求及未來需求預測和對策研究[J].中國工程科學,2018,20(5):39-44
[3]蔡承智,王芳,莫洪蘭,等基于ARIMA模型的我國油菜單產預測分析[J].中國農業資源與區劃,2018,39(1):71-76
[4]熊秋芳,段志紅,周江霞,等油菜新品種對油菜籽種植面積和單產影響的經濟學評價——以湖北省為例[J].農業技術經濟,2013(8):40-46
[5]姜貴飛 精準播種環境下的油菜品質預測[D].安徽農業大學,2015
[作者簡介]邵艷君(1995—),女,漢族,江蘇無錫人,西安工業大學在讀研究生,研究方向:管理科學與工程。
