基于多特征的微博突發(fā)事件檢測算法
2019-12-23 07:19:04王雪穎楊文忠張志豪李東昊秦旭
計(jì)算機(jī)應(yīng)用 2019年11期
王雪穎 楊文忠 張志豪 李東昊 秦旭


摘 要:為了降低社交媒體中突發(fā)事件帶來的危害,提出一種基于多特征的微博突發(fā)事件檢測算法。該算法融合了文本情感過濾和用戶影響力計(jì)算方法。首先,通過噪聲過濾和情感過濾得到飽含負(fù)面情感的微博文本;然后,采用提出的用戶影響力計(jì)算方法并結(jié)合突發(fā)詞提取算法來提取突發(fā)詞特征;最后,引入凝聚式層次聚類算法對(duì)突發(fā)詞集進(jìn)行聚類,從中提取突發(fā)事件。通過實(shí)驗(yàn)檢測,準(zhǔn)確率為66.84%,驗(yàn)證了該方法能有效地對(duì)突發(fā)事件進(jìn)行檢測。
關(guān)鍵詞:突發(fā)事件; 用戶影響力; 情感過濾; 突發(fā)詞; 聚類
中圖分類號(hào):TP391.1
文獻(xiàn)標(biāo)志碼:A
Microblog bursty events detection algorithm based on multifeature
WANG Xueying1, YANG Wenzhong1*, ZHANG Zhihao1, LI Donghao1, QIN Xu2
1.College of Information Science and Engineering,Xinjiang University, Urumqi Xinjiang 830046,China;
2.College of Software,Xinjiang University, Urumqi Xinjiang 830046,China
Abstract:
In order to reduce the harm caused by bursty events in social media, a multifeature based microblog bursty events detection algorithm was proposed. The algorithm combines text emotion filtering and user influence calculation methods. Firstly, the microblog text with negative emotion was obtained through noise filtering and emotion filtering. Then the proposed user influence calculation method was combined with the burst word extraction algorithm to extract the characteristics of burst words. Finally, a cohesive hierarchical clustering algorithm was introduced to cluster bursty word sets, and extract bursty events from them. In the experimental test, the accuracy is 66.84%, which proves that the proposed method can effectively detect bursty events.
Key words:
bursty topic; users influence; sentiment filter; burst word; clustering
0?引言
隨著近年來社交媒體的普及,人們交流和獲取信息的便利性有了大幅度的提升,人們已經(jīng)步入了一個(gè)全新的媒體時(shí)代。以微博為代表的社交媒體平臺(tái)更是憑借其發(fā)布、分享、傳播信息的便捷性,成為了大多數(shù)網(wǎng)民首選社交平臺(tái),據(jù)中國互聯(lián)網(wǎng)絡(luò)信息中心(China Internet Network Information Center, CNNIC)2018年第42次《中國互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r統(tǒng)計(jì)報(bào)告》顯示,至2018年6月30日,我國網(wǎng)民規(guī)模達(dá)8.02億,而微博用戶規(guī)模達(dá)到3.37億,網(wǎng)民使用率42.1%,較去年年底增長率為6.8%[1]。
微博作為一個(gè)迅速興起并基于用戶實(shí)時(shí)獲取、共享信息的平臺(tái),其日活躍用戶數(shù)已達(dá)到了1.65億。與傳統(tǒng)新聞媒體相比,作為一種新型社會(huì)媒體,微博特有的短文本性、弱關(guān)系性和即時(shí)性等特點(diǎn)在信息傳播中發(fā)揮了重要作用[2],網(wǎng)民們能第一時(shí)間在平臺(tái)上獲得自己感興趣的信息。因此, 微博的輿情傳播速度要遠(yuǎn)遠(yuǎn)快于傳統(tǒng)媒體,逐漸成為了主要的輿論場所,如果某件受廣大民眾關(guān)注的事件對(duì)公共安全造成了危害,則會(huì)變成突發(fā)事件。為了及時(shí)在微博的海量信息中發(fā)現(xiàn)輿情并及時(shí)地對(duì)微博的言論進(jìn)行管控和疏導(dǎo),微博突發(fā)事件檢測對(duì)社會(huì)穩(wěn)定有著重要意義。
1?相關(guān)工作
有關(guān)微博輿論檢測的研究,近年來受到了國內(nèi)外廣大專家學(xué)者的廣泛關(guān)注。他們?cè)谖⒉┦录z測的效率提升上都做了很多工作,其主要研究大致分為兩類:
一是以微博文本為中心,Cui等[3]為了有效解決短文本中數(shù)據(jù)稀疏的問題,以LDA(Latent Dirichlet Allocation)為基礎(chǔ)建模,提取文本中潛藏的主題信息。Lee等[4]將LDA與時(shí)間序列等特征進(jìn)行結(jié)合,提高了單一的LDA檢測模型的效率,但是LDA模型中涉及話題數(shù)量選擇的問題,需要人工的干預(yù),數(shù)值不同,對(duì)結(jié)果也會(huì)造成不同的影響。
二是基于突發(fā)特征為中心。在這類文本聚類的文章中, 首先對(duì)微博突發(fā)內(nèi)容的特征進(jìn)行提取,再對(duì)提取后的突發(fā)特征進(jìn)行聚類,最后通過聚類結(jié)果提取突發(fā)事件:張魯民等[5]通過對(duì)微博構(gòu)建情感符號(hào)模型,判斷出網(wǎng)民情感在大多數(shù)情況下能主導(dǎo)事件的擴(kuò)散程度,突發(fā)事件的發(fā)生導(dǎo)致信息量的暴漲,網(wǎng)民的情緒也隨之波動(dòng),因此對(duì)微博原文、評(píng)論內(nèi)容進(jìn)行情感分析,能夠明顯提高突發(fā)事件檢測的精確度,但僅考慮情緒的變化特征并不夠全面;郭跇秀等[6]通過分析用戶行為特征,認(rèn)為影響力大的用戶能夠更多地主導(dǎo)事件的擴(kuò)散程度,通過結(jié)合突發(fā)詞特征的抽取提出了一種基于用戶影響力的計(jì)算方法來對(duì)突發(fā)事件進(jìn)行檢測,然而一些流量明星的博文也具有較高的影響力,因此并不能有效地排除;仲兆滿等[7]認(rèn)為突發(fā)事件具有地域突發(fā)特征,提出了一種基于網(wǎng)絡(luò)地域的突發(fā)事件檢測方法,然而這個(gè)方法會(huì)遺漏一些不具有地域突發(fā)特征的博文,如“范冰冰偷逃稅”事件;Du等[8]引入了PageRank的算法來計(jì)算用戶影響力權(quán)重,并結(jié)合了突發(fā)詞特征來發(fā)現(xiàn)突發(fā)事件,該方法增加了用戶對(duì)話題的影響力,但忽略了用戶的一些信息,容易受到僵尸用戶的影響。
基于以上分析,本文考慮了將通過用戶特征的多個(gè)方面來計(jì)算得到每個(gè)用戶的影響力權(quán)重,并結(jié)合情感過濾的方法來抽取突發(fā)詞,然后引用凝聚式層次聚類算法對(duì)突發(fā)詞進(jìn)行聚類得到多個(gè)類簇,其中每一個(gè)類簇代表一個(gè)突發(fā)事件,并從中選取突發(fā)特征最高的博文來描述該事件。本文提出了一種基于用戶影響力和情感過濾的方法模型來實(shí)現(xiàn)對(duì)突發(fā)事件的檢測。最后通過實(shí)驗(yàn)檢測對(duì)比,驗(yàn)證了該方法的有效性。
2?微博預(yù)處理
由于微博中有大量的無用信息,如用戶的廣告、日常生活等信息,這些信息會(huì)對(duì)突發(fā)事件的檢測造成干擾。根據(jù)文獻(xiàn)[9]爬取的話題微博數(shù)據(jù)顯示,手機(jī)產(chǎn)品的微博中,垃圾微博占比高達(dá)70%。因此在突發(fā)事件檢測前,需要對(duì)微博數(shù)據(jù)進(jìn)行合理的預(yù)處理,去除噪聲微博,保留有用數(shù)據(jù),提高后續(xù)工作的效率和正確率。
2.1?微博噪聲過濾
NLPIR(Natural Language Processing and Information Retrieval)分詞系統(tǒng),是由張華平博士多年科研工作累計(jì)的成果,其主要功能包括中文分詞、英文單詞分割、組合注釋、命名實(shí)體識(shí)別、新詞識(shí)別、關(guān)鍵詞提取, 支持各種編碼、各種操作系統(tǒng)、多種的開發(fā)語言和平臺(tái)。本文采用NLPIR分詞對(duì)去噪后的數(shù)據(jù)進(jìn)行分詞、過濾停用詞等,后續(xù)采用一定過濾規(guī)則進(jìn)一步過濾掉無用微博文本。
1)參考文獻(xiàn)[10]過濾規(guī)則,在新聞?lì)I(lǐng)域中,有新聞六要素之說,即何時(shí)(When)、何地(Where)、何人(Who)、何事(What)、何故(Why)和如何(How),簡稱為5W1H。由于一般微博篇幅字?jǐn)?shù)都比較小,分析認(rèn)為如果微博要描述一個(gè)完整的突發(fā)事件,需要至少包含3個(gè)要素,即何人、何地、何事。
2)過濾粉絲數(shù)在某一閾值以下的用戶。本文將不會(huì)對(duì)粉絲數(shù)接近于0的用戶進(jìn)行信息采集,他們其中一部分可能是平臺(tái)生產(chǎn)出的僵尸用戶,負(fù)責(zé)發(fā)大量的廣告或成為水軍,另一部分可能為只獲取微博信息的不活躍用戶,這些用戶所發(fā)布的信息無法造成大面積擴(kuò)散,因此刪除這類用戶所發(fā)布的微博信息,可以有效降低噪聲干擾。
3)去除文本中URL連接、表情符號(hào)、英文等。
2.2?情感過濾
突發(fā)事件,在一定程度上指的是突然發(fā)生的,并且會(huì)對(duì)社會(huì)公共安全造成一定的危害的事件,文獻(xiàn)[11]認(rèn)為網(wǎng)民的情感是主導(dǎo)突發(fā)事件發(fā)生的催化劑,飽含負(fù)面情緒詞較多的事件,成為突發(fā)事件的概率更大。情感傾向性分析主要有基于語義的情感詞典方法和基于機(jī)器學(xué)習(xí)的方法[12],機(jī)器學(xué)習(xí)過濾需要耗費(fèi)大量人力和時(shí)間,因此本文使用BosonNLP情感詞典來得到每篇文檔的情感值,每篇文檔的情感值計(jì)算方法如式(1)所示:
Se(n)=∑wi∈positivepositive_word(wi)+∑wj∈negativenegative_word(wj)(1)
其中: Se(n)表示第n個(gè)文檔的情感值;positive為情感詞庫中的正面詞;negative表示情感詞庫中的負(fù)面詞;positive_word(wi)表示該文檔中包含正面的情感詞數(shù);negative_word(wj)表示該文檔中包含負(fù)面的情感詞數(shù)。
3?突發(fā)詞提取
文獻(xiàn)[8]中對(duì)突發(fā)詞給出了定義:突發(fā)詞是指在某個(gè)時(shí)間窗內(nèi),若某一個(gè)實(shí)詞被大量使用,且在之前的時(shí)間窗內(nèi)很少被使用,則該實(shí)詞被視為一個(gè)突發(fā)詞。時(shí)間窗指每個(gè)獨(dú)立的時(shí)間段。本文統(tǒng)一以1d為單位。文獻(xiàn)[13]提出的老化理論,認(rèn)為每個(gè)詞都具有一個(gè)生命周期,即出生、發(fā)展、消退、死亡。
根據(jù)以上定義,本文將微博數(shù)據(jù)文本以天為單位劃分成一個(gè)個(gè)單獨(dú)的時(shí)間窗(可根據(jù)需求改變時(shí)間窗的大小)并提出了詞的突發(fā)度計(jì)算方法,主要從詞頻、詞頻增長率、詞權(quán)重、用戶影響力來得到詞的突發(fā)度。
1)詞頻增長率的計(jì)算。
因?yàn)槊餍切?yīng),每天都會(huì)有粉絲為明星刷大量微博來制造話題,只從一個(gè)詞在單位時(shí)間窗內(nèi)出現(xiàn)的頻率來定義一個(gè)詞的突發(fā)度是不夠全面的,因此本文計(jì)算一個(gè)詞在單位時(shí)間窗內(nèi)的增長率計(jì)算公式如式(2)所示:
Fi,k=SFi,k-SFi,k-11+SFi,k-1 (2)
其中:Fi, k表示詞i在窗口k中的詞頻增長率;SFi,k表示詞i在窗口k中出現(xiàn)的頻率。當(dāng)突發(fā)事件發(fā)生時(shí),網(wǎng)民會(huì)創(chuàng)作或轉(zhuǎn)發(fā)大量關(guān)于此事件的博文,因此某突發(fā)詞的出現(xiàn)的頻率也會(huì)增高,計(jì)算詞的增長率能較好地體現(xiàn)一個(gè)詞的突發(fā)度。
2)詞權(quán)重的計(jì)算。
發(fā)生突發(fā)事件時(shí),相關(guān)事件的微博數(shù)量會(huì)呈現(xiàn)爆發(fā)式增長,這也代表著微博中會(huì)大量出現(xiàn)描述同一事件的突發(fā)詞,因此本文需要一種詞語權(quán)重計(jì)算方式來描述這一現(xiàn)象。TFIDF(Term FrequencyInverse Document Frequency)作為用于信息檢索與數(shù)據(jù)挖掘的常用加權(quán)技術(shù),可以用來評(píng)估一個(gè)詞在一篇文檔或一個(gè)語料庫中的重要程度。傳統(tǒng)TFIDF算法主要運(yùn)用在某個(gè)詞在一篇文檔中出現(xiàn)較多而在其他文檔中出現(xiàn)較少的環(huán)境中,對(duì)于微博熱點(diǎn)突發(fā)詞的廣泛分布情況,傳統(tǒng)TFIDF算法表現(xiàn)較差。綜上所述,本文采用文獻(xiàn)[14]中的TFPDF詞權(quán)重算法,該算法克服了原有算法對(duì)突發(fā)事件檢測帶來的缺陷,公式如式(3)、(4)所示:
Wj=∑c=Dc=1Fjcexp(njc/Nc)(3)
Fjc=Fjc∑Kk=1F2kc(4)
其中:Wj表示詞語j的權(quán)重;Fjc表示詞j在微博文檔集c中出現(xiàn)的頻率;njc表示在微博文檔集c中出現(xiàn)詞j的微博數(shù);Nc表示文檔集c中文檔總數(shù);k表示文檔集中所有詞數(shù);D表示文檔集c的總數(shù)。
3)用戶影響力。
通常情況下,微博發(fā)送者的影響力會(huì)對(duì)其微博的擴(kuò)散帶來可觀的影響,本文引入用戶影響力概念來更加精準(zhǔn)地定位突發(fā)事件,影響力的計(jì)算包含多個(gè)維度:粉絲量、更新速度、評(píng)論數(shù)、轉(zhuǎn)發(fā)數(shù)等。綜上所述,本文定義了用戶U=(Rep,Com,F(xiàn)an,Type,Update)。其中:Update為該用戶一個(gè)月內(nèi)微博更新數(shù)量,最小取1;Rep、Com為一個(gè)月內(nèi)微博的轉(zhuǎn)發(fā)數(shù)量及評(píng)論數(shù)量總和;Fan為該用戶的粉絲數(shù)量;Type為用戶的類型權(quán)重,官方微博取1、大V微博取0.7、普通用戶取0.5。因此,考慮以上多個(gè)因素,提出了一種用戶影響力計(jì)算方法,如式(5)所示:
Du=(Repu+Comu)×Fanu×TypeuUpdateu(5)
正如前文所述,在一個(gè)輿論平臺(tái)上,如果一個(gè)用戶受到的關(guān)注量越大,相應(yīng)的,該用戶的影響力也會(huì)越大,那么他所發(fā)表的言論中,包含突發(fā)詞的博文是突發(fā)事件的可能性也越高。為了能更好地得到一個(gè)突發(fā)事件,本文將用戶影響力與突發(fā)詞特征進(jìn)行結(jié)合,提出一個(gè)突發(fā)詞的突發(fā)度計(jì)算方式,如式(6)所示:
wordj,t=1N∑t-1k=t-N(Wj,t×Fj,t×∑pn∈pj,tlb(Dpn)-Wj,k×Fj,k×∑pb∈pj,klb(Dpb)) (6)
其中:wordj,t代表詞j在時(shí)間窗t內(nèi)的突發(fā)度;Wj,t是詞j在t時(shí)間窗內(nèi)的權(quán)重;Dpn是包含詞語 j的一條微博 pn 的發(fā)布者的影響力;pj,t是在時(shí)間窗t內(nèi)包含詞語 j 的所有微博;N是時(shí)間窗的總數(shù)。
4?突發(fā)事件檢測
4.1?突發(fā)詞相似度
突發(fā)詞相似度計(jì)算方法建立基于上下文的詞語共現(xiàn)分析的詞語相似度計(jì)算方法。因此,為了計(jì)算兩個(gè)突發(fā)詞之間的共現(xiàn)性詞語相似度,需要從語料中獲取詞語的上下文統(tǒng)計(jì)信息。詞語共現(xiàn)相似度,即在一個(gè)規(guī)模龐大的語料庫中,有兩個(gè)詞經(jīng)常共同地出現(xiàn)在同一文檔數(shù)據(jù)中,那么認(rèn)為這兩個(gè)詞是相互關(guān)聯(lián)的,而且隨著這兩個(gè)詞共同出現(xiàn)的頻率越高,就說明它們之間的關(guān)系越緊密。如“重慶公交墜江事件”中,“公交”“墜江”這兩個(gè)詞的語義沒有相似度,但是根據(jù)本文的共現(xiàn)相似度分析,這兩個(gè)詞共同出現(xiàn)在多個(gè)博文數(shù)據(jù)的概率增加了,因此認(rèn)為這兩個(gè)詞之間的關(guān)聯(lián)關(guān)系也比較大。該方法的計(jì)算公式如式(7)所示:
Sim(wi,wj)=|{pn|pn∈Pk,wi∈pn,wj∈pn}| |Pk|(7)
其中:k為時(shí)間窗,本文以天為單位;wi、wj為兩個(gè)突發(fā)詞;Pk是時(shí)間窗k內(nèi)的所有微博集;pn是時(shí)間窗k內(nèi)包含突發(fā)詞wi、wj的微博。
4.2?突發(fā)詞聚類
使用一個(gè)正確的聚類算法是事件檢測的關(guān)鍵步驟,本文采用凝聚式層次聚類。凝聚式層次聚類是一種自底向上的層次聚類方式,其會(huì)將樣本集中的所有數(shù)據(jù)點(diǎn)都當(dāng)作為一個(gè)聚類,計(jì)算每兩個(gè)聚類之間的距離并將距離最近的兩個(gè)聚類進(jìn)行合并,重復(fù)上述步驟,當(dāng)聚類結(jié)果中數(shù)據(jù)的合并到達(dá)一定的程度,就停止該聚類步驟,步驟終止的條件并不是固定的,可以適當(dāng)性地調(diào)整聚合的閾值從而防止過度合并或確定最佳的聚類效果。
算法步驟如下所示:
輸入?樣本集合D,聚類數(shù)目或者某個(gè)條件(此為突發(fā)詞集)。
輸出?聚類結(jié)果(突發(fā)詞聚類集)。
步驟1?將樣本集中的所有的樣本點(diǎn)(突發(fā)詞)都當(dāng)作一個(gè)獨(dú)立的類簇。
步驟2?計(jì)算兩兩類簇之間的距離,找到距離最小min_distance的兩個(gè)類簇c1和c2。
步驟3?合并類簇c1和c2為一個(gè)類簇。
步驟4?若min_distance小于閾值,返回步驟2;否則輸出結(jié)果并結(jié)束。
該算法的缺點(diǎn)是計(jì)算量大、時(shí)間復(fù)雜度高。聚類結(jié)果中不同的類簇包含的突發(fā)詞數(shù)也是不一樣的,由于前文提到描述一個(gè)事件至少包含三個(gè)要素,即何人、何地、何事。因此本文過濾掉少于3個(gè)詞的類簇,剩下的每個(gè)類簇則代表了一個(gè)事件。
5?實(shí)驗(yàn)結(jié)果與分析
本文利用新浪微博的API接口采集了2018年10月28日至11月4日約10萬條微博數(shù)據(jù),其中每條微博包含的信息有用戶ID、用戶信息、轉(zhuǎn)發(fā)量、評(píng)論數(shù)、粉絲數(shù)、發(fā)布時(shí)間和博文內(nèi)容。本文首先對(duì)采集到的數(shù)據(jù)進(jìn)行預(yù)處理并以天為單位對(duì)數(shù)據(jù)進(jìn)行劃分,再根據(jù)突發(fā)詞提取算法進(jìn)行突發(fā)詞識(shí)別得到突發(fā)詞集,最后對(duì)突發(fā)詞集聚類并根據(jù)聚類結(jié)果選取權(quán)重較高的幾個(gè)突發(fā)詞進(jìn)行顯示并提取相關(guān)且熱度最高的一條微博來代表抽取的突發(fā)事件。
5.1?評(píng)價(jià)指標(biāo)
本文采用準(zhǔn)確率(Precision)、召回率(Recall)與 F值(Fmeasure)作為微博突發(fā)事件檢測方法的性能評(píng)測指標(biāo),具體計(jì)算方法如式(8)~(10)所示:
Precision=B.correctB.output(8)
Recall=B.correctB.number(9)
Fmeasure=2*Precision*RecallPrecision+Recall(10)
其中:B.correct為系統(tǒng)中識(shí)別正確的突發(fā)事件個(gè)數(shù),B.number為系統(tǒng)中事件總數(shù),B.output為識(shí)別到的突發(fā)事件個(gè)數(shù)。
5.2?突發(fā)詞抽取
在對(duì)微博文本進(jìn)行預(yù)處理后,需要對(duì)文本中的突發(fā)詞進(jìn)行提取,前文根據(jù)提出的詞的突發(fā)度計(jì)算公式得到了詞的突發(fā)度,因此,最終選取突發(fā)度排名前100的突發(fā)詞組成該時(shí)間段內(nèi)的突發(fā)詞集。
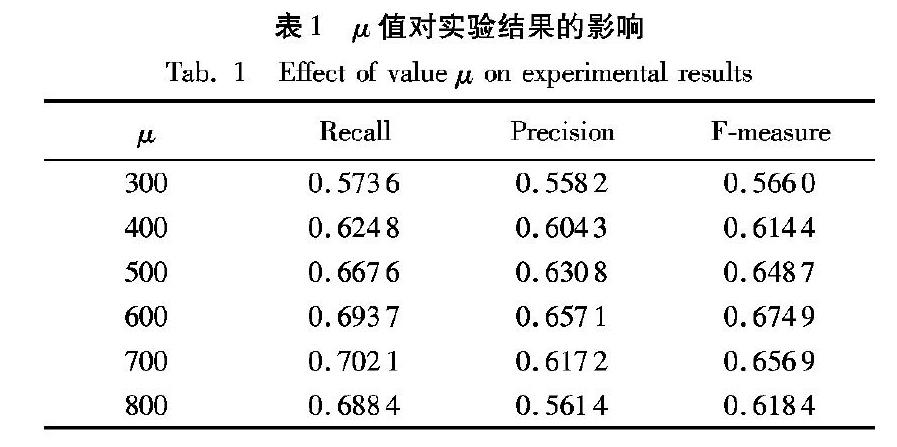
在突發(fā)詞聚類中,簇間閾值μ分別取300~800不同的值進(jìn)行檢測,實(shí)驗(yàn)結(jié)果如表1所示。
可見,當(dāng)μ取值為600時(shí),此檢測結(jié)果F值到達(dá)峰值,因此本文取μ=600對(duì)當(dāng)前的數(shù)據(jù)進(jìn)行突發(fā)事件檢測,根據(jù)抽取到的事件簇,本文選取每個(gè)突發(fā)簇中熱度最高的一篇博文來描述所代表的事件,微博的熱度主要通過其轉(zhuǎn)發(fā)和評(píng)論來決定,因此可以通過一篇微博的轉(zhuǎn)發(fā)數(shù)和評(píng)論數(shù)來大致衡量一篇微博的熱度:
微博熱度=α×轉(zhuǎn)發(fā)數(shù)+β×評(píng)論數(shù)
根據(jù)文獻(xiàn)[15]考慮到微博轉(zhuǎn)發(fā)的影響力大于評(píng)論的影響力,因此α、 β分別取0.6和0.4。
最后,本文根據(jù)每個(gè)事件簇的最高微博熱度來對(duì)檢測的事件進(jìn)行排序,并選擇用熱度最高的博文來代表描述對(duì)應(yīng)事件,如表2所示。
編號(hào)時(shí)間突發(fā)詞對(duì)應(yīng)事件
12018年10月28日重慶、公交車、碰撞、墜江、交通、相撞10月28日上午,重慶萬州區(qū)長江二橋上發(fā)生一起交通事故,一輛大巴車與一輛轎車相撞后,沖破護(hù)欄掉入長江。目前尚不清楚大巴車上乘客數(shù)量,傷亡情況不明。
22018年10月28日高鐵、女童、猥褻、父女【疑似#高鐵上父親猥褻女兒#:撩起她的衣服不停撫摸、親吻】有網(wǎng)友稱,G1402次高鐵上,一名男子對(duì)一女童做出猥褻動(dòng)作,并推測應(yīng)該是父女關(guān)系……
32018年10月29日李詠、哈文、主持人、去世、癌癥主持人李詠因癌癥在美國去世,妻子哈文發(fā)文:在美國,經(jīng)過17個(gè)月的抗癌治療,2018年10月25日凌晨5點(diǎn)20分,永失我愛。
42018年10月30日金庸、武俠、去世、香港港媒報(bào)道,金庸先生于2018年10月30日下午在香港養(yǎng)和醫(yī)院逝世,享年94歲……
52018年11月3日蘭海、高速、收費(fèi)站、蘭州、交通、死亡央視消息,蘭海高速蘭州南收費(fèi)站發(fā)生一起嚴(yán)重交通事故,一輛大貨車失控,從收費(fèi)站沖下連撞31車。目前已經(jīng)造成11人死亡,31人受傷(11重傷)……
62018年11月1日高鐵、霸座、黑名單、火車、信用【高鐵霸座姐被列入黑名單 將限制乘坐所有火車席別】11月1日,國家公共信用信息中心公布10月份新增219人被限乘火車,其中高鐵“霸座姐”出現(xiàn)在“黑名單”。
5.3?對(duì)比實(shí)驗(yàn)
實(shí)驗(yàn)一?與其他實(shí)驗(yàn)不同的是,本文是在基于突發(fā)詞聚類的基礎(chǔ)上,結(jié)合了用戶影響力和情感過濾兩方面的特征,為了驗(yàn)證算法的可行性,將從以下4個(gè)方面進(jìn)行驗(yàn)證:
1)N_S。該模型僅考慮對(duì)突發(fā)詞的聚類來提取突發(fā)事件。
2)S_S。該模型在對(duì)突發(fā)詞聚類的同時(shí),僅考慮了通過情感詞集來進(jìn)行情感過濾的特征。
3)U_S。該模型在對(duì)突發(fā)詞聚類的同時(shí),僅考慮了用戶的影響力特征。
4)B_S。該系統(tǒng)為本文提出的模型,根據(jù)突發(fā)詞的特征再結(jié)合用戶影響力和情感過濾來提取突發(fā)詞集,從而獲取最終結(jié)果。
其實(shí)驗(yàn)對(duì)比結(jié)果如表3所示。
表3描述了各個(gè)模型的效果,整體上來看,N_S效果最差,B_S效果最好,但召回率要低于U_S,這是因?yàn)樵谶M(jìn)行情感過濾時(shí)模型只保留了負(fù)面傾向的數(shù)據(jù)來進(jìn)行聚類。但是考量一個(gè)突發(fā)事件檢測模型,不僅是覆蓋范圍要廣,其準(zhǔn)確率也要高,從Fmeasure中可以看出,B_S的效果是最好的。
實(shí)驗(yàn)二?為了進(jìn)一步闡述本文方法的有效性,與各種方法對(duì)比效果,本文將文獻(xiàn)[15]中根據(jù)突發(fā)詞的詞頻、增長率、權(quán)重的排名來綜合提取突發(fā)詞集的方法和文獻(xiàn)[16]中提出的TimeUserLDA的事件檢測方法作為本文的baseline1和baseline2來與本文方法進(jìn)行對(duì)比實(shí)驗(yàn)。表4詳細(xì)列出檢測出了根據(jù)各種方法檢測到的突發(fā)事件前3個(gè)事件,表5描述了各個(gè)方法的檢測效果對(duì)比。
從表4可以看出,baseline1和baseline2的檢測結(jié)果中都含有非突發(fā)事件的熱點(diǎn)事件,這些事件在當(dāng)時(shí)雖然也會(huì)有較高的影響力,但并不能看作是一個(gè)突發(fā)事件。而從表5中可以看出,相比較baseline方法,本文方法在召回率、精確率和F值都有所提高,分析其原因主要有以下兩點(diǎn):
1)文獻(xiàn)[15]在微博噪聲過濾中只過濾了一部分無意義的博文,而本文方法是在此基礎(chǔ)上,添加了文本情感過濾和用戶影響力,使噪聲對(duì)突發(fā)事件識(shí)別的影響降低。
2)而文獻(xiàn)[16]中通過LDA模型對(duì)數(shù)據(jù)進(jìn)行建模,再加入時(shí)間序列和用戶信息來對(duì)數(shù)據(jù)進(jìn)行突發(fā)事件的檢測來提高檢測效率; 而本文方法是通過突發(fā)特征來識(shí)別突發(fā)事件,具有一定的針對(duì)性,并根據(jù)用戶信息和情感過濾進(jìn)一步提高了檢測效率。因此從檢測效果上來看,本文方法具有一定的可行性。
6?結(jié)語
由于微博文本內(nèi)容的簡短性和實(shí)時(shí)性,本文對(duì)微博文本特征、傳播特性作了分析,提出了基于用戶影響力和情感分析的突發(fā)事件檢測模型。從實(shí)驗(yàn)結(jié)果中可知,所提模型能夠?qū)ν话l(fā)事件有較好的檢測能力;后續(xù)研究的發(fā)展和改進(jìn)之處是繼續(xù)提高突發(fā)詞集檢測的效率,及更加準(zhǔn)確地對(duì)突發(fā)事件進(jìn)行描述。
參考文獻(xiàn) (References)
[1]? 中國互聯(lián)網(wǎng)信息中心. 第42次中國互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r統(tǒng)計(jì)報(bào)告[R].北京:中國互聯(lián)網(wǎng)信息中心,2018. (China Internet Network Information Center. The 42th statistical report of China Internet development[R]. Beijing: China Internet Network Information Center, 2018.)
[2]? 李洋,陳毅恒,劉挺. 微博信息傳播預(yù)測研究綜述[J]. 軟件學(xué)報(bào), 2016, 27(2):247-263. (LI Y, CHEN Y H, LIU T. Survey on predicting information propagation in microblogs[J]. Journal of Software, 2016, 27(2):247-263.)
[3]? CUI L, ZHANG X, ZHOU X, et al. Topical event detection on Twitter[C]// Proceedings of the 2016 Australasian Database Conference, LNCS 9877. Berlin: Springer, 2016:257-268.
[4]? LEE S, LEE S, KIM K. Bursty event detection from text streams for disaster management[C]// Proceedings of the 21st International Conference Companion on World Wide Web. New York: ACM,2012: 679-682.
[5]? 張魯民,賈焰,周斌,等. 一種基于情感符號(hào)的在線突發(fā)事件檢測方法[J]. 計(jì)算機(jī)學(xué)報(bào), 2013, 36(8):1659-1667. (ZHANG L M, JIA Y, ZHOU B, et al. Online bursty events detection based on emoticons[J]. Chinese Journal of Computers, 2013, 36(8): 1659-1667.)
[6]? 郭跇秀,呂學(xué)強(qiáng),李卓基. 基于突發(fā)詞聚類的微博突發(fā)事件檢測方法[J].計(jì)算機(jī)應(yīng)用,2014,34(2):486-490. (GUO Y X, LYU X, LI Z J. Bursty topics detection approach on Chinese microblog based on burst words clustering [J]. Journal of Computer Applications, 2014, 34(2): 486-490.)
[7]? 仲兆滿,管燕,李存華,等. 微博網(wǎng)絡(luò)地域Topk突發(fā)事件檢測[J]. 計(jì)算機(jī)學(xué)報(bào), 2018, 41(7):1504-1516. (ZHONG Z M, GUAN Y, LI C H, et al. Localized Topkbursty event detection in microblog[J]. Chinese Journal of Computers, 2018, 41(7):1504-1516.)
[8]? DU Y, HE Y, TIAN Y, et al. Microblog bursty topic detection based on user relationship[C]// Proceedings of the 6th IEEE Joint International Information Technology and Artificial Intelligence Conference. Piscataway: IEEE, 2011:260-263.
[9]? 姚子瑜,屠守中,黃民烈,等. 一種半監(jiān)督的中文垃圾微博過濾方法[J].中文信息學(xué)報(bào), 2016, 30(5): 176-186. (YAO Z Y, TU S Z, HUANG M L, et al. A semisupervised method for filtering Chinese spam tweets [J]. Journal of Chinese Information Processing, 2016, 30(5):176-186.)
[10]? 王勇,肖詩斌,郭跇秀,等. 中文微博突發(fā)事件檢測研究[J]. 現(xiàn)代圖書情報(bào)技術(shù), 2013(2): 57-62. (WANG Y,XIAO S B,GUO Y X,et al. Research on Chinese microblog bursty topics detection[J]. New Technology of Library and Information Service, 2013(2): 57-62.)
[11]? 費(fèi)紹棟,楊玉珍,劉培玉,等. 融合情感過濾的突發(fā)事件檢測方法[J]. 計(jì)算機(jī)應(yīng)用, 2015, 35(5):1320-1323. (FEI S D, YANG Y Z, LIU P Y, et al. Method of bursty events detection based on sentiment filter[J]. Journal of Computer Applications, 2015, 35(5): 1320-1323.)
[12]? 馬力,宮玉龍. 文本情感分析研究綜述[J]. 電子科技, 2014, 27(11):180-184. (MA L, GONG Y L. Research on text sentiment analysis[J]. Electronic Science and Technology, 2014, 27(11):180-184.)
[13]? CHEN C C, CHEN Y T, SUN Y, et al. Life cycle modeling of news events using aging theory[C]// Proceedings of the 2003 European Conference on Machine Learning, LNCS 2837. Berlin: Springer, 2003:47-593.
[14]? BUN K K, ISHIZUKA M. Topic extraction from news archive using TF*PDF algorithm[C]// Proceedings of the 2002 International Conference on Web Information Systems Engineering. Piscataway: IEEE, 2002:73-82.
[15]? 陳國蘭. 基于爆發(fā)詞識(shí)別的微博突發(fā)事件監(jiān)測方法研究[J]. 情報(bào)雜志, 2014(9):123-128. (CHEN G L. Microblog Emergencies detection approach based on burst words distinguishing[J]. Journal of Intelligence, 2014(9): 123-128.)
[16]? DIAO Q, JIANG J, ZHU F. Finding bursty topics from microblogs[C]// Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2012: 536-544.
This work is partially supported by the National Natural Science Foundation of China (U1603115, U1435215), the Xinjiang Uygur Autonomous Region University Research Project Innovation Team (XJEDU2017T002), the Natural Science Foundation of Xinjiang Autonomous Region (2017D01C042).
WANG Xueying, born in 1995, M. S. candidate. Her research interests include natural language processing.
YANG Wenzhong, born in 1971, Ph. D., associate professor. His research interests include public opinion analysis, information security, machine learning.
ZHANG Zhihao, born in 1995, M. S. candidate. His research interests include early warning of emergencies, information security.
LI Donghao, born in 1994, M. S. candidate. His research interests include natural language processing.
QIN Xu, born in 1994, M. S. candidate. Her research interests include natural language processing, public opinion analysis.
