基于遺傳算法和代碼相似性自動修復程序錯誤
2019-12-23 09:28:13石建樹王憲勇
電腦知識與技術 2019年31期
石建樹 王憲勇
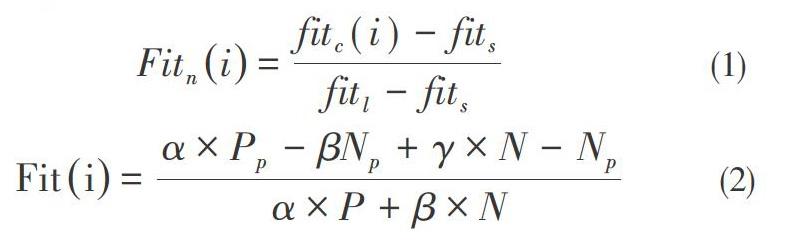
摘要:由于軟件產品的復雜性,軟件開發過程中開發人員無法避免bug的產生。為了提高軟件開發的效率,提出了一種基于遺傳算法和代碼相似性的bug自動修復方法。首先,搜索與源程序相似的bug代碼,并找到與其相關的修復代碼。然后,將修復代碼轉換為抽象語法樹,生成候選補丁。接下來,使用基于給定測試用例的適應度函數來驗證候選補丁是否有效。最后,生成輸出補丁修復源錯誤代碼。
關鍵詞:遺傳算法;代碼相似性;自動程序修復;軟件維護
中圖分類號:TP311.5 文獻標識碼:A
文章編號:1009-3044(2019)31-0209-03
1概述
由于現代軟件產品的復雜性,軟件開發過程中開發人員無法避免bug的產生。由于有大量的bug報告,開發人員必須花費更多的時間和精力來修復bug。由于每天都有大量的bug,開發人員需要花費更多的時間來跟蹤這些bug。開發人員手工生成的補丁的正確率也難以保證。因此,一種速度快,準確率高的自動修復技術可以顯著地節省軟件開發的時間和成本,提高軟件質量。
如果開發人員能夠獲得有用的信息描述,開發人員就可以輕松地跟蹤并修復bug。但是,如果錯誤報告包含的信息不夠,開發人員可能很難進行調試。因此,利用相似的bug代碼的修復信息進行自動修復,可以在缺少描述信息的情況下有效地修復bug。
針對上述問題,本文提出一種基于遺傳算法和代碼相似性的程序自動修復方法。搜索與源bug代碼相關的類似bug代碼,以及其修復代碼。然后,將其轉換為抽象語法樹(AST)。最后應用遺傳規劃為源bug代碼生成補丁。此方法支持自動修復,可以減少修復bug的時間和工作量,并且可以提高bug修復的質量和補丁的可讀性。
2相關工作
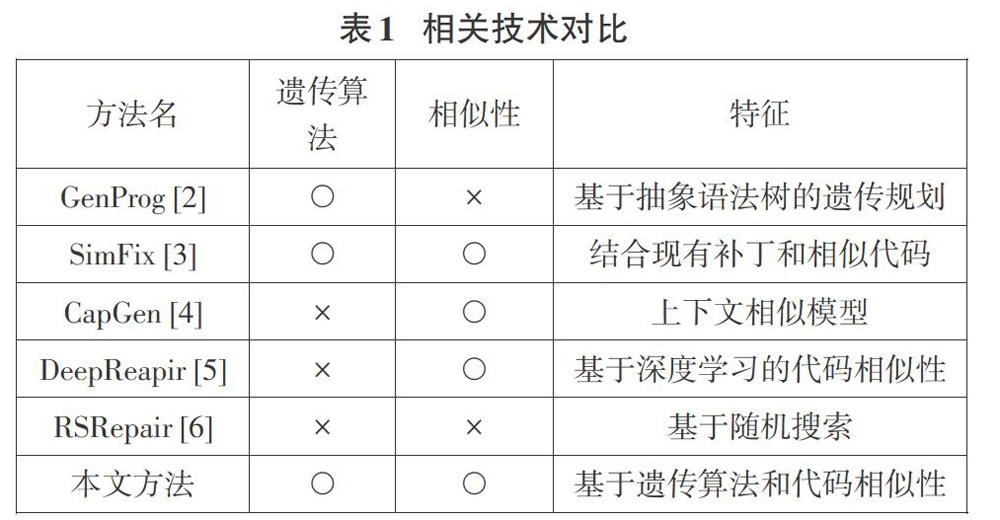
許多研究人員提出了程序自動修復方法。如表1所示,我們對與本文相關的自動修復技術進行了比較。
Le Goues等人提出了GenProg,其使用基于AST的遺傳規劃。GenProg將錯誤的源代碼轉換為AST,然后使用選擇、交叉、變異等操作生成新的AST。齊玉華等人為了驗證GenProg中遺傳編程對補丁生成過程是否有效,提出了基于隨機搜索的RSRepair方法。Simfix通過分析現有補丁形成抽象的過程修復空間,并且通過分析相同程序中相似的代碼片段形成具體的修復空間。文明等人提出了CapGen,CapGen以細粒度的方式在AST節點級別工作,這種設計使其能夠找到更精確的修復組件。為了解決細粒度所帶來的搜索空間巨大的問題,其使用三種上下文模型使正確的補丁能夠排在更靠前的位置。DeepRepair使用基于深度學習的代碼相似性對修復成分進行優先級排序和轉換。它計算代碼元素之間的距離來度量相似性。其通過智能選擇和調整修復成分來生成補丁。
3錯誤修復
3.1數據集
本文使用Defects4i數據集。高質量的數據集對于評估自動修復方法的有效性是必不可少的。Defects4i缺陷數據集共包含6個Java項目(Commons Lang、JFreeChart、CommonsMath、Joda-Time、Mockito和Closure Compiler),總bug數為438個,近年來關于自動修復的研究也廣泛采用了該基準。Defects4i數據集中的錯誤程序都來自實際項目,并且其自帶的測試用例集能夠較好的覆蓋程序的預期行為。
3.2錯誤定位
識別錯誤代碼行是修復的先決條件。為了找到錯誤代碼的位置,應該執行錯誤定位技術。錯誤定位技術的精確度對后續的修復效果起到關鍵的影響。目前研究人員已經提出了大量的程序錯誤定位方法。其中基于程序頻譜的定位方法是目前的主流方法。其根據測試用例的覆蓋率來判斷語句的可疑度。最終向修復過程輸出一組按可疑度大小排列的語句。本文使用錯誤定位工具Gzoltar,此工具使用Ochiai算法檢索故障空間和可疑值。
3.3遺傳規劃
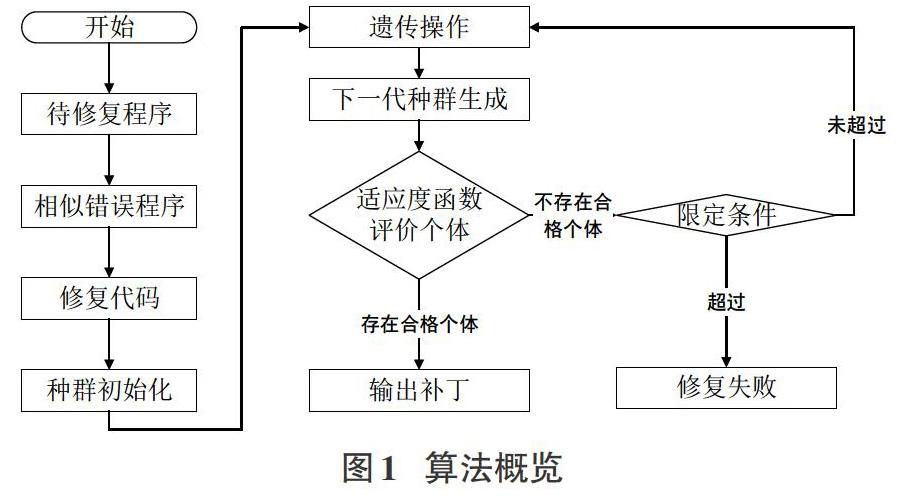
在本節中,我們將使用相似的bug修復信息描述遺傳規劃的應用。算法概覽如圖1所示。
3.3.1種群初始化
利用克隆檢測技術㈣搜索與源bug代碼相似的bug代碼,并得到相似錯誤代碼的修復代碼。為了找到最相似的修復代碼,將修復代碼中的每一行代碼轉換為令牌序列。使用最長公共子序列(LCS)對這些行和源錯誤行的令牌序列進行比較。從這些行中獲取具有最高LCS值的令牌序列。保留關鍵詞、變量名和常數,使用隨機操作符生成新的代碼行,并將該行與錯誤行交換。重復這個步驟,直到初始補丁的數量等于種群的大小。
3.3.2遺傳操作
當前種群中沒有合格的個體時,將執行選擇操作符。我們用適應度函數將個體按降序排序,使一半的個體都為父代。為了便于初始種群的構建,將適應度函數做規范化處理。以下為個體i的適應度函數規范化處理過程,這個規范化的適應度值僅用于初始種群選擇。
其中,i為種群中第i個個體;fitc(i)表示i個體適應度值;fits表示種群中最小適應度值;fit1表示種群中最大適應度值。
交叉的目的是交換兩個AST中的子樹節點。在每個母樹中選擇可更改的目標節點。選擇目標節點后,通過跟蹤父節點來驗證兩個節點是否可以交換。在變異中,選用刪除、插入和交換三種操作。
3.3.3適應度函數
迭代遺傳規劃算法,直到某些值達到限定條件。設置了三個限定條件;運行時間、代數和適應度值。如果達到限定時間和迭代次數還沒有生成正確的補丁,則修復失敗。個體適應度值如果是1,則停止迭代輸出補丁。在每個迭代步驟中,并必須計算每個個體的適應度值。
其中,a為通過正測試用例的系數;β為未通過反測試用例的系數;y為通過反測試用例的系數;Pp代表通過的正測試用例;Ⅳ。代表通過的反測試用例;P為正測試用例集,N為反測試用例集。
方程結果的取值范圍為0~1。值越接近1,個體越接近正確解。由于此模型包含了基本的功能,并且沒有引發意外的行為,所以適應度更接近于1。a的值應大于β和y,因為此系數表示個體是否包含基本功能。
4結論
本文提出了一種自動修復程序缺陷的方法。首先,我們通過手工檢查發現了可疑的錯誤代碼行。然后,我們使用具有類似bug修復信息的GP生成候選補丁。接下來,我們驗證候選補丁是否可采用。最后,我們生成補丁來修復程序錯誤。使用我們的方法,我們期望花費在修復bug上的時間和精力可以減少。在未來,計劃創建一個自動故障修復工具并且利用大規模的bug修復信息修復和測試用例排序技術更有效地完成自動修復過程。
