基于隨機森林的船舶碰撞事故缺失數據插補*
2019-12-27 10:16:36張金奮范存龍胡衛東
武漢理工大學學報(交通科學與工程版) 2019年6期
吳 郁 張金奮 范存龍 胡衛東
(武漢理工大學航運學院1) 武漢 430063) (武漢理工大學內河重點實驗室2) 武漢 430063) (武漢理工大學智能交通系統研究中心3) 武漢 430063) (武漢理工大學國家水運安全工程技術研究中心4) 武漢 430063)
0 引 言
交通事故數據是分析事故致因、梳理事故規律、揭示事故機理、預測事故演化的基礎.針對交通事故數據的研究主要包括:①基于事故數據量的分析,常用的方法如模型驅動[1-2]、數據驅動[3-4];②基于事故致因或機理的研究,通過事故數據凝練事故規律[5]或通過構建事故致因模型分析事故個案[6];③基于事故數據和事故模型的交互模式,事故數據、專家經驗、事故或安全生產理論等為事故模型的構建提供支持,或事故致因機理的調整.且所構建的事故模型用于分析或預測事故,該模式應用貝葉斯理論或貝葉斯網絡較多[7-8].但是,水上交通事故數據通常存在數據缺失、信息不完備、記錄不準確等問題.
數據缺失或不完備問題在實際數據分析中廣泛存在.Little等[9]根據數據缺失原因將數據缺失類型分成三類:完全隨機缺失(missing completely at random,MCAR)、隨機缺失(missing at random,MAR)和非完全隨機缺失(missing not at random,MNAR).按照數據缺失模式又可以分為單調缺失模式和任意缺失模式兩類.本文研究對象屬前者,任意缺失模式下缺失數據的插補可參見.數據的缺失最終會影響研究結果的信效度,因此需要對缺失數據進行恰當處理.
針對缺失數據,常用的處理方法可總結為四類[10]:①直接去除樣本中缺失數據,如個案剔除法(listwise deletion)、成對刪除法(pairwise deletion)等;②對樣本中缺失數據進行簡單插補,如正確項目平均分替代法(corrected item mean substitution imputation,CM)、平均數插補法(mean imputation)等;③對樣本中缺失數據進行高級插補,如回歸插補法(regression imputation)、多重插補法(MI)、EM算法、機器學習的方法等;④直接分析帶有缺失數據的樣本,較多采用機器學習的方法,如直接擴充粗糙集,決策樹等.在事故數據維度高時,若用模型驅動(傳統的概率統計或回歸模型)則需要基于一定的統計假設,而此類假設在實際中是難以完全嚴格保證的;若假定服從某一分布則結果的準確性存疑.分類水平較多時,由于穩健性差和缺乏可操作性使得模型驅動的應用受限,比如,本文研究對象事故記錄中的時間被分成九個時段.另一方面,隨著機器學習等數據驅動方法的發展與應用,缺失數據插補方法逐漸發展與豐富,其中比較典型的機器學習方法如隨機森林方法[11].該方法處理缺失數據和非平衡的數據比較穩健,對異常值和噪聲具有很好的容忍度且不容易出現過擬合,對數據的分布無限制,能有效分析高維復雜數據[12].徐凱等[13]利用隨機森林回歸預測算法地震道缺失數據進行插補,且取得良好應用效果,證明隨機森林方法的正確性與有效性.謝翹楚等[14]運用隨機森林算法處理不完全規律缺失數據(連續型數據),以均方根誤差和填補準確度為評判指標,實驗結果證明該方法的準確性和有效性.
以江蘇海事局2012—2016年船舶碰撞事故記錄為研究對象,根據事故記錄中“區域”“經緯度”“事故處理程序”的屬性,采用隨機森林方法進行缺失數據插補.其中,針對“區域”和“經緯度”的缺失,主要采用專家經驗并結合電子江圖等進行插補;針對“事故處理程序”缺失,采用隨機森林的分類方法.研究的目的與意義在于插補事故記錄中缺失數據,為后續的事故分析和安全研究提供完整的數據.
1 數據描述
選取的數據主要包括長江干線江蘇段945起船舶碰撞事故,每起事故包含23項記錄,如事故名稱,日期,轄區,水道,區域等.其中轄區、區域和經緯度均包含事故地理信息.因為轄區主要供管理部門參考,所以選取區域和經緯度研究事故地理信息.事故名稱、浮標、地點、事故簡況、事故客觀原因、事故直接原因為詳細的文本描述難以劃分類別而未考慮,但可為部分變量缺失插補提供參考,如事故簡況可為區域記錄或經緯度記錄缺失的插補提供參考,因此,選用16項記錄見表1,共945起事故為研究對象.

表1 事故記錄項類型或取值范圍
945起事故記錄完整度為82.65%,存在如下缺失:①只缺失“區域”記錄有20起,占江蘇段干線碰撞事故的2.116%;②只缺失“經度”和“緯度”記錄有19起,占干線事故的2.011%;③只缺失“事故處理程序”記錄有2起,占干線事故的0.211 6%;④缺失“事故處理程序”和“經濟損失”記錄有12起,占干線事故的1.27%;⑤只缺失“經濟損失”記錄有150起,占干線事故的15.87%.缺失比率越高,參數估計準確性越差且參數估計變異性越大.根據專家經驗并結合事發地點、事故簡況在長江航道局電子江圖、船訊網提供的專業江圖上確定“區域”“經度”和“緯度”,由此解決缺失(1)、(2).區域和經緯度缺失數據插補后的數據見表2.由于篇幅限制,本文主要針對缺失(3)、(4)進行插補,即采用隨機森林的分類方法對“事故處理程序”記錄缺失進行插補,缺失數據插補工作流程見圖1.

表2 區域和經緯度記錄缺失插補后數據
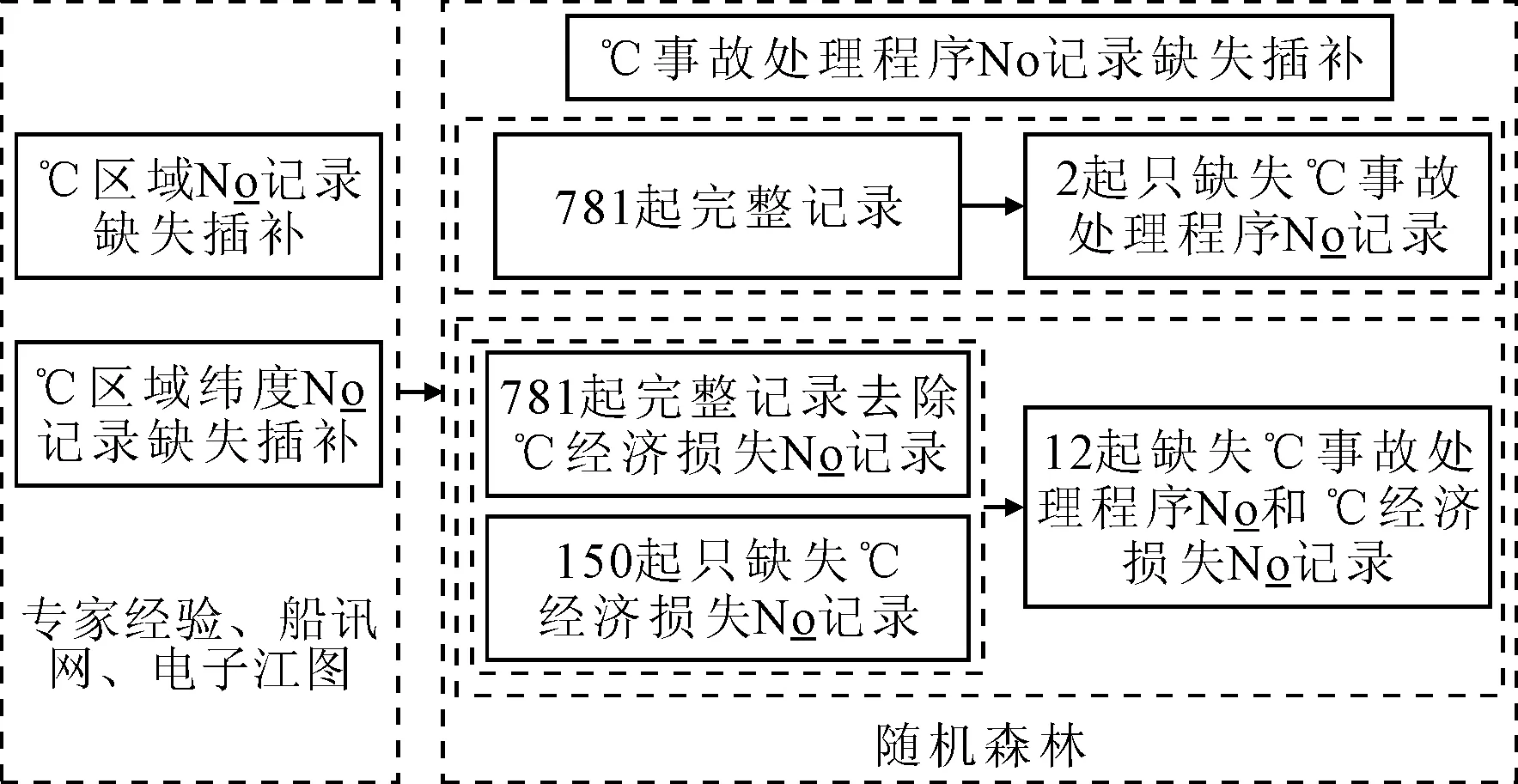
圖1 缺失數據插補流程
2 基于隨機森林的分類方法
2.1 隨機森林概述
隨機森林基本思想見圖2[15].隨機森林讓每棵樹盡可能生長,而且不進行修剪.隨機森林也會給出分類中各個變量的重要性.文中采用R語言中的RandomForest包.
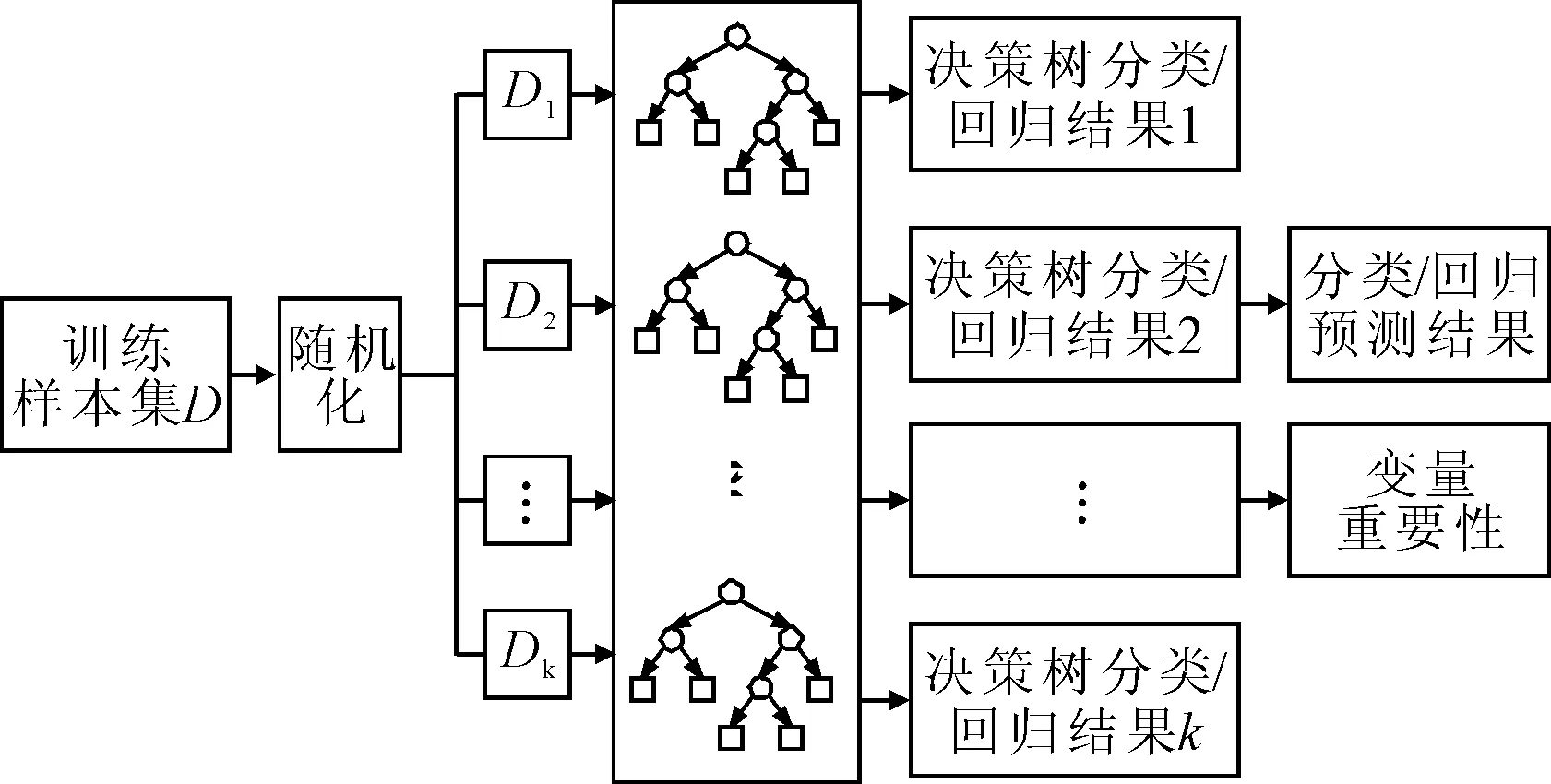
圖2 隨機森林的基本思想
2.2 隨機森林的分類方法
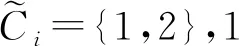
步驟2模型評價 通過訓練集獲取隨機森林模型,并通過運用該模型對該訓練集進行分類.對于分類問題,可通過混淆矩陣和基于OOB的誤分率來評價模型.
步驟3重要度分析 根據步驟2中隨機森林模型分析自變量對因變量的重要度.

結果的驗證,可以將模型預測的結果與事故記錄、事故簡況等實際情況進行對比分析.
3 “事故處理程序”記錄缺失插補
3.1 對兩起事故處理程序的缺失插補
對于兩起事故只缺失“事故處理程序”記錄的插補,訓練集選取781起完整事故記錄.“事故處理程序”為因變量,其余15個記錄項作為自變量.
1) 通過遍歷設定mtry參數為1~15進行15次建模,經試算,當mtry取3,ntree取500時,誤分率總體穩定.
2) 設定mtry和ntree參數后,利用R語言中RandomForest程序包運行得到隨機森林模型.通過該模型對該訓練集數據進行分類,所得混淆矩陣見表3,其誤分率為0.249 7.

表3 基于隨機森林方法所得混淆矩陣
事故處理程序的判斷屬于分類問題,可采用傳統的統計模型,如Logistic回歸、Probit回歸等模型.從機器學習的角度,該問題屬于監督學習(supervised learning),隨機森林還可采用樸素貝葉斯(naive bayesian)等方法.通過對比四種方法對781條完整數據(訓練樣本)判斷的誤分率見表4,隨機森林方法優于其他方法.

表4 四種方法對事故處理程序的分類的誤分率
3) 隨機森林的變量重要度評估.圖3為各個變量對事故處理程序兩種情況的相對影響.由此,可以認為影響事故處理程序的重要因素有經濟損失,沉船艘數,事故等級,死亡失蹤,經緯度、區域、船舶航行狀態、交通態勢.由此可見,對經緯度和區域的插補是必要的.
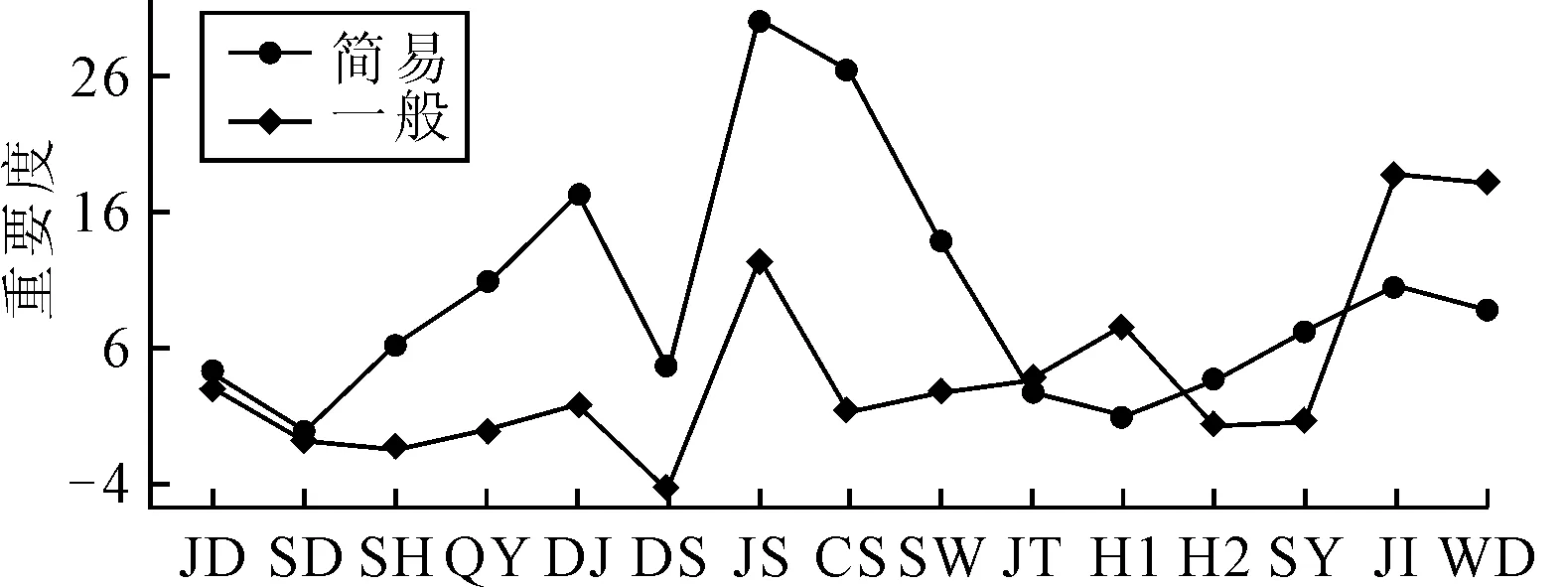
圖3 自變量對因變量水平響應的重要度
4) 根據隨機森林對“2014-07-22-1918-新寶航87-海長翔”“2014-08-13-2206-申燃22-皖鳴遠1119”進行事故處理程序分類,結果均為簡易程序,見表5.對比兩起事故,二者僅在經緯度、交通態勢分析和事故原因有不同差別.盡管經濟損失相差較大,但根據《水上交通事故統計辦法》(中華人民共和國交通運輸部令2014年第15號)第六條,兩起事故從經濟損失判斷均屬于小于100萬元的小事故.由此,將這兩起事故的處理程序判斷為簡易具有一定的合理性.

表5 基于隨機森林的預測概率
3.2 對12起事故數據的處理程序的缺失插補
對于12起既缺失事故處理程序又缺失經濟損失的記錄的插補,訓練集選取931起事故記錄,其中781起為去除經濟損失項的完整記錄,150起為只缺失經濟損失的記錄.“事故處理程序”為因變量,其余14個記錄項作為自變量.重復上述步驟1~4,設定mtry為6和ntree為500后,通過R語言中RandomForest程序包運行得到隨機森林模型.通過該模型對該訓練集數據進行分類,所得混淆矩陣,見表6,誤分率為0.244 9.

表6 基于隨機森林方法所得混淆矩陣
圖4為自變量對因變量水平響應的重要度,由圖4可知,沉船艘次、經緯度、航行狀態、事故等級、當事方數、區域對結果的影響大.
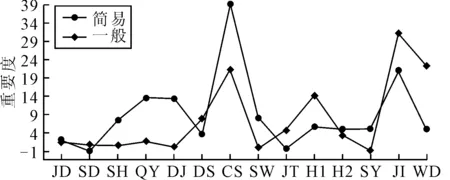
圖4 自變量對因變量水平響應的重要度
12起記錄的事故處理程序的預測分類及其概率,見表7.隨機森林方法將除“揚州-碰撞-興航136-長通海”事故判定為簡易外,其他均判定為一般.與其他11起事故相比,“揚州-碰撞-興航136-長通海”事故雙方船舶在事故發生時間均處于錨泊狀態,由于雙方未留足距離導致碰撞事故發生,其造成的事故后果較小.而其余事故則是航行船碰撞錨泊船或航行船碰撞航行船,造成的事故后果更大.

表7 基于隨機森林的預測概率
4 結 束 語
數據缺失、信息不完備、記錄不準確是水上交通事故數據較為常見的問題.缺失數據的存在將降低基于數據挖掘的事故規律解析或事故機理揭示的可信度.水上交通事故記錄項數據類型多、維度高、信息冗余等特性在事故缺失數據插補過程中決定了方法的選取、變量的篩選等.研究表明:經濟損失,沉船艘數,事故等級、區域等是影響事故處理程序的關鍵因素;事故等級,死亡失蹤人數,事發經緯度等是影響經濟損失的關鍵因素.在相同測試樣本下,隨機森林方法的精度優于Logistic回歸、Probit回歸和樸素貝葉斯等方法.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
