基于神經網絡的可學習Kd樹
2020-01-02 05:57:40彭永鑫
商洛學院學報 2019年6期
關鍵詞:模型
彭永鑫
(云南大學 軟件學院,云南昆明 650000)
近幾十年來,高維數據在數據倉庫、信息檢索、數據挖掘等方面的應用越來越廣泛。Kd 樹作為一種用于查詢高維鍵值的流行算法,由于其準確性高、可擴展性強、查詢速度較快,通常被用來進行多維空間關鍵數據的檢索。使用Kd樹進行k 近鄰搜索,就是對于給定的一個查詢點q,需要從一個構成Kd 樹的數據集D 里找到距離q 最近的k 個數據。當k=1 時,就是最近鄰搜索。
使用Kd 樹在高維向量空間中進行搜索時,由于高維向量的距離計算需要花費相當大的代價,使得查詢在一定程度上變為線性搜索,極大影響了查找效率。為了減少距離的計算,提高執行效率,目前已有很多文獻對此提出了不同的解決方法。這些方法能夠有效的回答低維和中維空間中的最近鄰查找問題[1-4],但是由于“維度災難”[5],依然不能很好地應用于中高維空間的搜索。
隨著大數據和gpu 技術的繁榮,人們能夠探索更高的計算能力和更靈活的數據結構。然而傳統上的數據結構更多是為了適應cpu 而設計的,其特點是按照固定的模式來組織數據,并不考慮數據的分布。如何設計高效靈活的數據結構以降低原有模型的復雜度成為一個急需解決的問題。神經網絡經常被用于實現各種復雜的功能,使用Kd 樹進行最近鄰查找可以看作是一個分類問題,這與神經網絡完成的工作沒有本質上的區別。因此,使用神經網絡來代替Kd 樹應該是一種具有可行性的工作。傳統的索引結構是按固定的方式構建的,而機器學習模型是在訓練數據的基礎上建立的,但這兩者本質上都是對空間位置的定位和尋找,潛在來說神經網絡和索引是具有一定聯系的。文獻[6]提出了一種基于機器學習的可學習索引的方法,該方法具有學習數據分布的能力。它探索了使用神經網絡在一定程度上代替傳統索引結構的可行性,并進一步討論了可學習哈希映射索引與傳統哈希映射索引之間的區別。在之前的工作[7]中,探索利用神經網絡建立倒排索引,表明了無監督的可學習索引相比傳統索引有著明顯的優勢。在此基礎上,本文提出了基于神經網絡的可學習Kd 樹模型,用于解決中高維空間中的最近鄰搜索問題。在本文的方案中,首先構建一棵Kd 樹,并對構成Kd 樹的數據構建索引。隨后通過Kd 樹找到輸入數據的最近鄰點,將最近鄰點所在的分類作為標簽進行訓練。
這種基于神經網絡的可學習的Kd 樹方案新穎而且可擴展,為最近鄰查找提供了一種全新的思路。該方案使用神經網絡,能夠并行的解決搜索問題,能在更短的時間內進行較為精確的查找,運行時間更具優勢。
1 傳統Kd樹
傳統上研究人員使用Kd 樹進行最近鄰搜索。Kd 樹是每個節點為一個k 維向量的二叉樹。每個非葉子節點可以看作一個超平面, 而這個超平面將多維空間分割為兩個子平面。在這個超平面左側的點被分為左子樹, 右側的點則被分為右子樹。決定這個超平面方向的方式如下:每個 Kd 樹中的點都與k 維向量中的一個特定維度相關聯,而這個維度正是垂直于分割空間的超平面的軸的維度。舉個例子,如果這個軸是X 軸,那么x 的值小于決定這個超平面的點的剩余點被分到左子樹,所有x 的值大于這個點的被分到右子樹。
使用Kd 樹進行最近鄰搜索方法如下:假設有一棵已經構建好的維度為d 的Kd 樹,對這個數據集進行最近鄰搜索,首先,給定查詢點q。需要做的是從樹上找到一個節點o,使得點o 到查詢點q 之間的歐式距離,小于這棵樹上除點o 之外任意一點oi到q 的距離。具體做法是比較查詢點q 和分裂節點的分裂維的值,小于等于就進入左子樹分支,等于就進入右子樹分支直到葉子結點。順著二叉樹的搜索路徑進行搜索。然后再回溯搜索路徑,并判斷搜索路徑上的結點的其他子結點空間中是否可能有距離查詢點更近的數據點,如果有可能,則需要跳到其他子結點空間中去搜索(將其他子結點加入到搜索路徑)。重復這個過程直到搜索路徑為空。其中,空間中兩個點 x1(x11,x12,…,x1k)與 x2(x21,x22,…,x2k)間的歐氏距離 d(x1,x2)定義為:
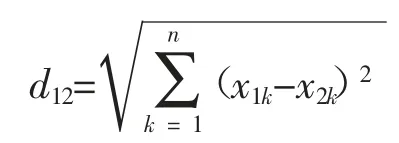
使用傳統Kd 樹進行最近鄰查找存在諸多問題,例如占用存儲空間大,需要進行大量的回溯操作等。尤其是當數據的維度很高時,Kd樹的查找效率變得特別低,性能甚至不如線性掃描,產生了“維度災難”。其他用于k 近鄰查詢的樹形結構例如R 樹[8],采用了空間分割的理念,其核心思想是聚合距離相近的節點并在樹結構的上一層將其表示為這些節點的最小外接矩形,這個最小外接矩形就成為上一層的一個節點。因為所有節點都在它們的最小外接矩形中,所以跟某個矩形不相交的查詢就一定跟這個矩形中的所有節點都不相交。在此基礎上,R* 樹[1]作為 R 樹的一種變體,提升了 R樹的性能。然而,隨著維度的升高,這些索引技術的效率會變得較低,線性掃描成為唯一可行的解決方案。在一些實際應用中,由于并不需要嚴格查找到完全準確的k 近鄰點,因此可以犧牲一定的搜索精度來實現實際的運行時間[9-11]。在這種情況下,NN(Nearest neighbor)和 kNN 問題分別被轉化為 ANN(Approximate nearest neighbor)和kANN 問題。作為一種流行的 kNN 查詢方法,局部敏感哈希(LSH)[12]被廣泛使用。
2 LK模型
2.1 LK模型架構及執行過程
可學習的Kd 樹,本質上是利用訓練好的深度學習模型替換掉傳統Kd 樹中的搜索部分,并且,訓練好的深度學習模型可以仍保持原有數據的局部空間不變性。所以,如何訓練這個深度學習模型,將是模型中最重要的研究部分(如圖1 所示)。

圖1 LK 基本架構
首先,生成一棵維度為d 的Kd 樹,這棵Kd樹由n 條數據構成。隨后,隨機為構成這棵Kd樹的數據從0 開始打上標簽,則可以得到對應的從0 開始直到n-1 一共n 個類別。訓練的時候,將訓練數據和測試數據輸入Kd 樹,得到最近鄰點,根據最近鄰點得到相應的類別。最后,將這n 個類中最近鄰點的索引值的位置為1,其余置為0,作為訓練集和測試集的標簽。由于神經網絡能夠對空間進行定位和尋找,因此使用神經網絡來構建模型,用來模擬Kd 樹的結構。神經網絡的輸出值是預測到的索引值所在的位置。
模型分為五個部分:輸入階段、映射階段、標簽階段、索引階段、計算階段。如圖2 所示。

圖2 LK 框架和執行過程
輸入階段:輸入的數據要求具有相同的維度。一般來說,輸入的數據不應和構成Kd 樹的任何一條數據相同。這些數據可以直接輸入神經網絡而不需要進行額外的處理。如果是圖片或者音頻,則需要進行數據的轉化才能輸入神經網絡。一條輸入數據為 I=(i1,…,id),其中 d 為輸入數據的維度。則整個輸入數據為I*=I1,...,Ix,其中x 為輸入數據的尺寸,I1,…,Ix中 d 值都相同。
映射階段:這個階段實現了傳統Kd 樹的查找功能。將輸入數據(假設為m 條)輸入神經網絡之后,由神經網絡進行運算處理。這是整個模型最為重要的一個階段, 由多層神經網絡構成。神經網絡的層數和每一層神經網絡的節點數會根據實驗的結果不斷的調整,使得神經網絡能夠輸出預期的結果,每一層神經網絡的節點數可能不相同。每條數據都會輸出一個1*n 的向量。因此,整個神經網絡會輸出一個m*n 的矩陣,矩陣中每個值都為一個0 到1 之間的數。
標簽階段:在這個階段,需要對神經網絡的輸出進行處理,并不是直接輸出最近鄰點的位置,而是輸出可能是最近鄰點的位置,從而能夠從這些潛在的最近鄰中找到真正的最近鄰。不同的輸入數據,可能是最近鄰點的數量也不相同。本文規定,如果某個位置輸出值為1,則這個位置在Kd 樹中所對應的點,就是潛在的最近鄰點;如果這個位置輸出值為0,這個位置就不是最近鄰點,在接下來的階段不需要對這個位置進行處理。由于使用了sigmoid 激活函數,因此需要一個閾值,將分布在0 到1 之間的數轉換為0 或者1。這個階段的輸出也是一個m*n 的矩陣,矩陣中的每個值,要么為0,要么為1。
索引階段:在構建Kd 樹的標簽時,構成Kd樹的每一個節點,都被劃分為 0,1,…,n-1 中的某個類別。因此,為了直觀展示和便于計算,可以將上個階段所輸出的值為1 的位置,轉化成與之對應的實際的類別,即根據值為1 的位置,得到潛在最近鄰點的索引值。對于每一條數據I,值為1 的個數可能不同,因此得到索引值的數量也不同。這表示神經網絡對于不同的輸入數據,會做出誤差不同的預測。輸出值為1 的個數越多,表示需要進行更多次的計算,才能從潛在的最近鄰點中找到真實的最近鄰點。
計算階段:實際上,神經網絡輸出的不會總是完美的得到滿足條件的最近鄰點,大多數情況下,需要在輸出的所有可能是最近鄰點的幾個點中,通過計算,找到真實的最近鄰點。因此,需要根據輸出的索引值,通過Kd 樹,得到其原本表示的數據。最后,將輸入數據I 和這幾個點所代表的存在于Kd 樹中的每一條數據,依次計算歐氏距離并排序,便能得到真實的最近鄰點。
本文中,準確率是這樣定義的:假設待查詢的數據有M 條,其中有N(N≤M)條查找到了正確的最近鄰點,則準確率為N/M×100%。
2.2 調整參數
本文中使用sigmoid 函數作為神經網絡最后一層的激活函數。由于需要將所有的輸出值映射成0 或者1,而sigmoid 函數的輸出值都在0 和1 之間,所以需要確定一個閾值,將輸出劃分為0 或者1。實驗結果表明,閾值選取的越小,準確率會越高,但需要進行查詢比較的時間就會越長。極端情況下,當閾值為0 時,幾乎所有的輸出都被置為1,這意味著基本需要將輸入數據和所有構成Kd 樹的點進行一一對比,雖然能夠達到接近百分之百的準確率,但查找所耗費的時間遠超Kd 樹和線性查找沒有區別。
閾值決定了輸出中值為1 的個數,也就決定了需要進行計算比較的次數,而計算比較的次數又決定了查找時間的長短。在第3 部分中進行了相關的實驗,展示了閾值的選取和其他指標的關系。
2.3 時間復雜度
Kd 樹在進行最近鄰搜索時,首先由根結點從上到下找到對應包含查詢點的葉子結點,其中要計算該區域內的點到查詢點的最小距離(若是k 近鄰搜索,需要計算最小的k 個距離)。對于一個具有n 個節點的d 維Kd 樹,最近鄰查找的時間復雜度為tworst=O(d*n1-1/d)。
使用神經網絡進行最近鄰搜索是一個三次索引加上一次計算的過程,第一次是數據輸入神經網絡后得到的輸出值,即Kd 樹上的點所對應的索引值的位置;第二次是根據這個位置得到Kd 樹中點的索引值;第三次是根據這些索引值得到Kd 樹中的點。索引完成后,將輸入的點和查找到的點進行一一比較,得到最近鄰。因此,時間復雜度為O(1)+O(2)+O(3)+O(4),分別對應了三次索引過程和計算過程。在進行最近鄰搜索時,相對于Kd 樹需要進行多次的計算和回溯操作,模型只需要進行少量的計算。使用Kd 樹進行最近鄰查詢會在計算和回溯的過程中消耗大量的時間,而使用神經網絡在一定程度上代替了這個過程。當構成Kd 樹的數量和維度數變大時,此模型應該會表現出更明顯的優勢。
3 結果與分析
所有的實驗均使用python 編寫的代碼在Intel(R)Core(TM)i7-4770 上完成,該機器具有3.4GHz CPU,32GB RAM 和運行 Linux Ubuntu 12.04 的2TB 外部磁盤空間。
本文從準確率和運行時間兩個方面來評估模型。一方面將神經網絡查找到的結果和傳統Kd 樹找到的結果進行對比;另一方面比較兩者查找到最近鄰所需的時間。本文所使用的最近鄰點,都是通過傳統Kd 樹得到的,可以認為使用Kd 樹進行查找的準確率為100%。
在進行設計和分析的過程中,發現閾值和維度的選取會對實驗結果產生較大的影響。在實驗中,分別使用了 3 個閾值:0.001,0.005,0.01,在1 000 條數據和10 000 條數據的情況下來進行實驗觀察(都為符合正態分布的隨機數)。
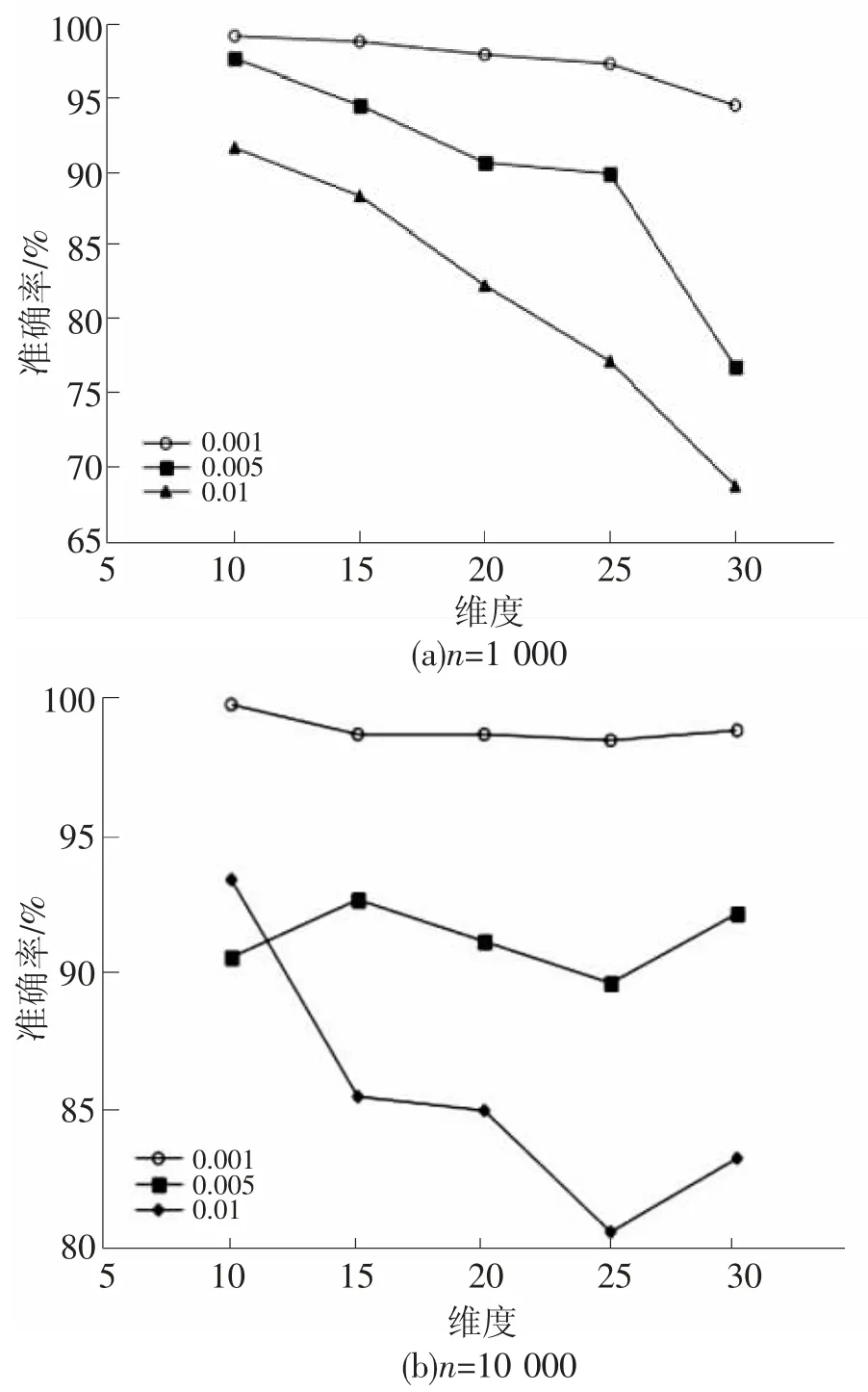
圖3 閾值和維度對準確率的影響
首先在神經網絡層數相同,維度分別為10,15,20,25,30 維的情況下進行了實驗。最終結果為10 次實驗結果的平均值(實驗結果如圖3)。結果表明,當n 為1 000 時,在相同的維度下,閾值越低,準確率越高。隨著維度的升高,不管閾值如何,準確率都在持續下降;而當n 為10 000時,除了在維度為10 的情況下出現了異常,相同維度下,閾值越低,準確率越高。同時,隨著維度的增加,準確率出現了一定程度的波動。當維度為10,閾值為0.001 時,兩者的準確率甚至達到了99%以上;當維度為30 維時,可以看到,極端情況下,當閾值為0.01 時,準確率甚至會低于70%。由于只需要查找最近鄰點(k=1),k 的值遠遠小于構成Kd 樹本身的數據量n,因此最終的預測值,值為1 的個數遠遠少于值為0 的個數。在神經網絡的輸出中,只要輸出值不為0,便傾向于這個位置是可能的最近鄰點。閾值設置的越小,就會把更多潛在的最近鄰點包含其中,使得準確率升高。一般來說,隨著維度的升高,準確率會降低;相同維度下,閾值越小,準確率越高。
圖4 展示了搜索時間和維度、閾值的關系。其中圖4(a),圖4(b),圖4(c)分別是神經網絡層數為 5,n 為 10 000,維度分別為 10,20,30 維的結果。橫坐標為不同的閾值,縱坐標為所用的時間。觀察相同維度下運行時間的變化,可以發現,運行時間隨著閾值的變大而減少。閾值設置的越小,就會把更多潛在的最近鄰點包含其中,會導致需要進行更多次的計算。
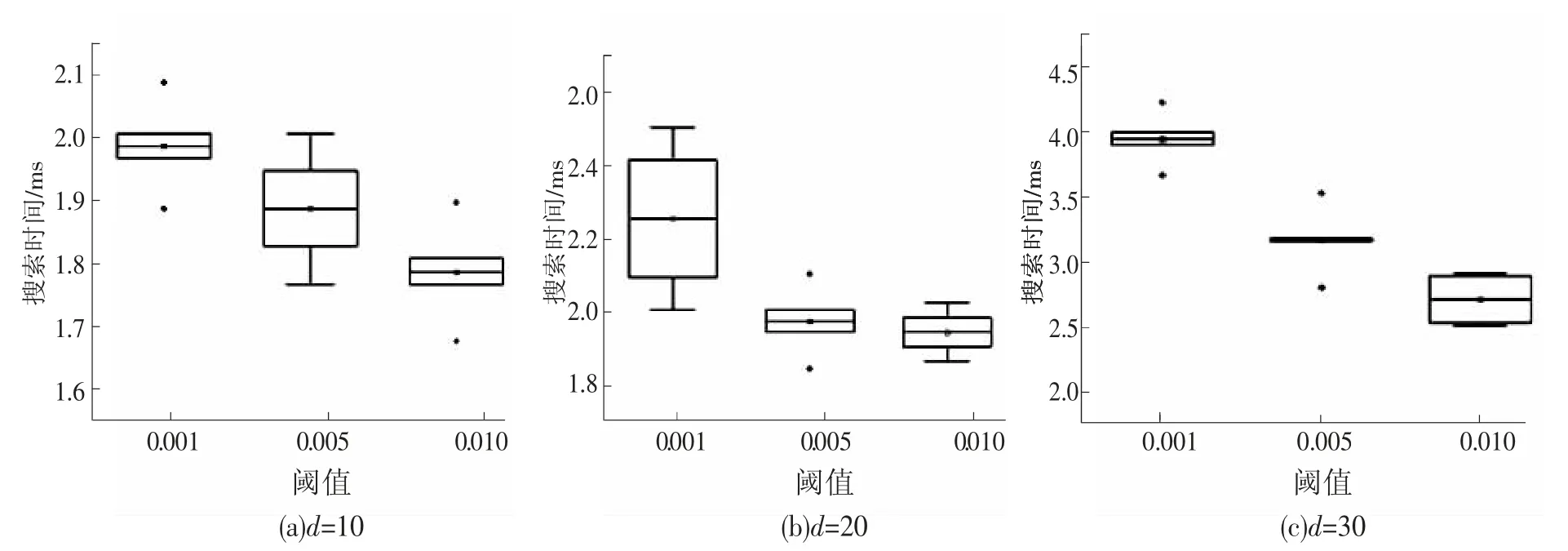
圖4 閾值和維度對搜索時間的影響
本文將使用神經網絡進行最近鄰搜索的時間和使用傳統Kd 樹進行最近鄰搜索所花費的時間,在n 為10 000,閾值為0.005 的情況下進行了對比,此時,由圖3b 可知,模型的準確率均在90%以上。兩者的運行時間如表1。從表1 可以看出,相比于傳統的Kd 樹,LK 模型在運行時間上更具優勢。
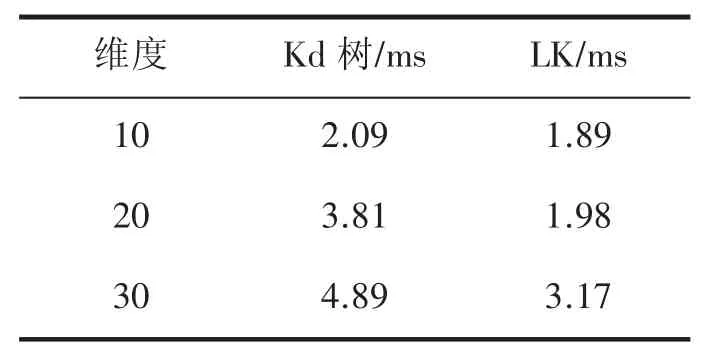
表1 運行時間對比
4 結論
本文解決了在實際計算時間內的最鄰搜索的問題,同時表現出了較高的質量。總的來說,在應用中,根據不同的需求,需要在準確率和運行時間上做出取舍。可以得到:模型的準確率隨著閾值的增加而降低,但與此同時,運行時間也在減少。在搜索中,如果需要更高的準確率,那么就需要花費更多的時間,但在一定的情況下,所用的時間也會比傳統的Kd 樹花費的時間更少;如果對結果要求不是非常精確,那么此模型就會具有更大的時間優勢。未來,將繼續研究如何在更高的維度、更多的數據量上取得更好的實驗效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
