分布式主題輿情采集與分析系統設計
2020-01-05 07:00:06董富江張文學
軟件導刊 2020年11期
董富江 張文學


摘 要:在大數據和移動互聯網的時代背景下,輿情信息的迅猛增長為其采集與分析帶來挑戰。運用分布式計算技術,有利于對領域海量主題輿情的快速采集與分析。研究主題輿情采集與分析關鍵技術,包括主題輿情采集技術、領域詞典和中文分詞,探討分布式計算環境下的主題輿情采集與輿情數據分析,并利用面向對象的分析與設計方法,基于開源爬蟲設計并實現了一個分布式主題輿情采集與分析系統。利用4個爬蟲節點進行分布式采集,相比傳統采集模式,該系統的平均采集速度提升了2.74倍。
關鍵詞:分布式;主題輿情;信息采集;開源爬蟲
DOI:10. 11907/rjdk. 201708????????????????????????????????????????????????????????????????? 開放科學(資源服務)標識碼(OSID):
中圖分類號:TP319 ? 文獻標識碼:A ??????????????? 文章編號:1672-7800(2020)011-0116-04
The Design of a Distributed Subject Public Opinion Collection and Analysis System
DONG Fu-jiang,ZHANG Wen-xue
(College of Science,Ningxia Medical University,Yinchuan 750004,China)
Abstract: In the era of big data and mobile Internet, the rapid growth of public opinion information brings challenges to its collection and analysis, and the design of distributed subject public opinion collection and analysis system is conducive to the rapid collection and analysis of mass subject public opinion information. The key technologies of subject public opinion collection and analysis are studied, including subject public opinion collection, field dictionary and segmentation of Chinese word. The collection and analysis technology of subject public opinion in distributed computing environment is discussed.A distributed subject public opinion collection and analysis system based on open source crawler is designed and implemented by object-oriented analysis and design method. Four crawler nodes are used for distributed collection, and the average collection speed is improved by 2.74 times compared with the single-machine collection mode.
Key Words:distributed; subject public opinion; information collection; open source crawler
0 引言
在大數據與移動互聯網蓬勃發展的時代背景下,網絡輿情具有傳播迅速、快速裂變、紛繁復雜等特點,對這些網絡輿情進行有效的管理、控制與引導,避免釀成不良網絡輿情事件,對于保障社會穩定具有重要意義。借助于輿情監控平臺,可幫助相關部門或行業對互聯網輿情信息進行跟蹤、分析與管理[1-2]。設計面向各政府部門或行業的主題網絡輿情信息采集與分析系統,如醫療[3-4]、疫情[5]、食品安全[6]等領域,可輔助政府部門或企業及時獲取所需的輿情信息[7-12],為進一步輿情管理與決策奠定基礎。當前互聯網上的輿情信息飛速增長,呈現海量性特點,給傳統的輿情采集與分析帶來極大挑戰[13-14]。運用分布式技術,可提高對大規模主題輿情信息的采集、分析與處理效率。
1 主題輿情采集與分析關鍵技術
1.1 主題網絡輿情采集
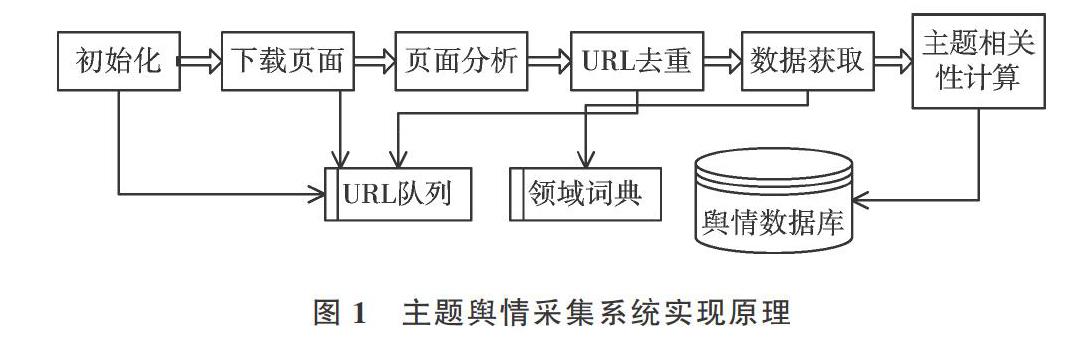
廣義的主題網絡輿情采集是指針對特定領域或特定行業的輿情信息采集,如藥品安全輿情采集等;狹義的主題網絡輿情采集是指采集某領域關于某個或某些事件的輿情信息,如針對某個城市新冠肺炎疫情防控的輿情信息采集等。基于開源通用網絡爬蟲如Nutch、WebCollector、Scrapy等構建主題爬蟲系統,是主題輿情采集系統的低成本設計與實現方案。主題輿情采集系統具體實現原理如圖1所示。
在圖1中,方框代表采集系統的模塊,粗線箭頭代表系統流程,細線箭頭代表模塊對數據的應用。初始化模塊用于設置要采集的輿情信息主題或者輸入主題詞,設置種子鏈接列表;網頁下載模塊在初始化完成后,從種子鏈接開始,利用爬取算法對頁面進行下載;頁面分析模塊可對網頁下載模塊獲取到的網頁進行解析,提取出頁面中的鏈接與文本內容;URL去重模塊用于過濾重復網頁,若判斷當前頁面已存在于URL隊列中,則不進行存儲;數據獲取模塊采用某種算法從Web頁面中抽取所需數據;主題相關性計算模塊是系統的關鍵模塊,其根據設計好的算法計算當前頁面與給定主題的相關性,若相關則進行保存,否則予以丟棄。URL隊列采取FIFO方式存儲待下載的頁面鏈接,領域詞典保存面向特定主題的詞匯,支撐中文分詞與數據獲取。
1.2 關鍵詞提取
主題輿情采集方法之一是利用基于主題詞的方法,在采集時由人工輸入一個或多個主題詞,主題相關性計算模塊首先提取網頁上的文本關鍵詞,然后匹配輸入的主題詞及網頁關鍵詞。若匹配成功,說明網頁是主題網頁,系統保存該網頁的輿情數據。系統設計采用TF-IDF算法,其思想是若某詞語在某文本中出現次數相對較多,但在其余文本中出現次數相對較少,則該詞語為關鍵詞[15]。
1.3 主題向量
采用主題自動生成方法,在系統運行前利用一些人工采集的主題頁面,經過機器學習算法如LDA[16]學習得到用向量模式表示的特定主題,對頁面進行下載與處理后也表示成向量空間模型,之后系統利用設計好的相關性計算算法比較主題向量與頁面主題。若計算結果大于設定閾值,則判定該頁面為面向特定主題的頁面,系統將從該頁面提取的數據作為主題輿情進行保存。由于移動互聯網時代信息增長迅速,新的網絡語言和網絡詞匯不斷涌現,將導致系統采集性能下降,所以可利用系統采集的數據定期重新計算主題向量。為提高計算效率,可利用之前采集數據時所得的主題相關度高的頁面進行計算,或隨機抽取一些主題頁面進行計算。
1.4 中文分詞與領域詞典
中文分詞模塊是數據獲取模塊的重要組成部分。若要下載的頁面中含有中文信息,提取所需數據前須對頁面中的文本進行中文分詞處理,將中文文本拆分為中文詞語序列。中文分詞和領域詞典維護流程如圖2所示。分詞模塊使用領域詞典將中文文本分解為詞語構成的列表。去停用詞模塊使用停用詞表去除詞語集合中諸如“a,the”和“啊,了”等出現頻率高,但信息含量很低的詞。
中文分詞詞典對于分詞精度有著重要影響,面向特定主題的領域詞典能進一步提高主題輿情采集系統的分詞精度及系統處理性能。在構建系統時設計詞典調整模塊,該模塊能夠采用自動統計方法向詞典中加入新詞匯。在系統運行初期可采用通用分詞詞典,隨著系統的運行,詞典調整模塊能夠自動增加詞匯,從而進一步提升主題輿情采集精度。
2 分布式技術應用
分布式技術思想是先將分布式計算系統部署在一些廉價計算設備上,然后將大型計算項目分解成許多小的計算任務,再把這些任務分配到廉價計算設施上進行計算,待各個小任務處理完成后進行結果合并,即得到所需的計算結果。因此,將分布式技術運用于主題輿情采集,從理論上而言,可提高對于大量主題輿情數據的采集與分析效率。
2.1 分布式主題輿情采集
分布式主題輿情采集使用分布式爬蟲系統,采用基于局域網的主從模式[17]。該模式利用一臺機器作為Master,負責管理各爬蟲節點,并分配任務。因為各爬蟲運行在同一局域網中,爬蟲之間以及爬蟲與控制節點之間通信效率較高。在該模式下,爬蟲節點之間甚至無需進行通訊。系統實現的分布式主題爬蟲架構如圖3所示。
架構中SpiderMaster指任務中央控制節點,由Master啟動,其功能是將任務分解、分配給SpiderWorker;SpiderWorker指爬蟲節點,由Worker啟動,負責輿情采集工作,SpiderWorker功能如1.1節所述;URL隊列用來保存待爬取的鏈接,可采用Key-Value數據庫實現;輿情數據庫可采用文件數據庫,用來存放采集的主題輿情數據。
2.2 分布式輿情分析
輿情分析包括主題相關度分析、熱點分析、焦點分析和情感分析等[18]。主題關注度是指在已逝去的某時段內,某輿情主題被大家所關注的水平,通常用與該主題相關的頁面數量進行度量。熱點是指在已逝去的某時段內被集中關注的輿情主題。熱點計算方法為:首先計算某輿情主題關注度,其次比較該關注度與事先設定的某個閾值,若該關注度大于等于該閾值,則此主題輿情為熱點,否則不是熱點。焦點是指在已逝去的某時段內被各類媒體報道頻次較高的輿情信息。焦點計算方法為:首先計算某主題輿情在某時間間隔的焦度,接下來判斷計算得到的焦度與事先設定好的焦度閾值的關系,若焦度大于等于閾值,則該輿情信息為輿情焦點,否則不是輿情焦點。輿情信息焦度等于時間間隔兩端點處與該主題輿情相關的網頁數之差。由輿情分析的描述可知,針對海量輿情信息進行輿情分析,使用分布式技術可加快輿情分析速度。基于分布式技術的輿情分析如圖4所示。
以焦度計算為例,可以先在各個節點上計算輿情信息N的焦度,然后對從這些節點上計算得到的焦度進行綜合,即可得到該輿情信息在整個網絡上的焦度。
3 系統設計與實現
3.1 系統分析與設計
主題輿情采集系統首先能夠從各大門戶網站、微博、論壇等平臺及時、準確、全面地抓取與特定主題有關的頁面,接下來對抓取的頁面進行信息提取,然后進行分詞,最后對得到的數據進行主題相關性計算,如果主題相關則存儲到輿情數據庫中。系統應具備以下功能:①輿情主題生成。利用人工采集的主題網頁或輿情數據庫中的數據,通過分析與計算得到輿情主題向量;②領域詞庫自動維護。基于通用詞庫,通過系統的運行生成與完善領域詞典;③主題輿情采集。通過分布式主題網絡輿情采集爬蟲獲取主題輿情數據,并保存在輿情數據庫中;④輿情分析。利用采集的輿情數據進行輿情熱點、焦點計算及情感分析等。
為了便于系統日后維護,采用面向對象技術進行系統分析與設計。在需求分析完成后構建系統用例,之后畫出系統的分析類圖和設計類圖,使用序列圖描述系統活動,最后基于開源爬蟲實現系統。主題輿情采集模塊設計類圖如圖5所示。
輿情管理類OpinionManager通過爬蟲類Spider進行頁面下載、分析與分詞;Opinions是輿情集合類,與輿情類Opinion之間是聚合關系;頁面類Page可進行關鍵詞提取與中文分詞;輿情類Opinion進行主題相關性計算與輿情信息保存;輿情管理類OpinionManager借助于輿情集合類Opinions進行輿情數據分析。
3.2 輿情數據庫設計
MongoDB適合于分布式環境下數據的快速存儲[19]。MongoDB是一個基于分布式文件存儲的NoSQL數據庫,其中的數據庫(database) 概念對應關系型數據庫中的模式(schema),集合(colloction)對應表(Table),文檔(document)對應行(row) [20]。為便于大量主題輿情數據在分布環境下存儲,采用MongoDB數據庫。為提高檢索速度、提升系統性能,將不同類型頁面對應的輿情數據保存在不同的輿情數據集合中。以微博輿情信息采集為例,微博輿情數據集合如下:
……
{ “NID”:1,
“Owner”:“owner1”,
“keyWords”:[{“name”:“新冠”,“fre”:3},{“name”:“藥” ,“fre”:3 }]
“Text”:“俄羅斯批準使用法維拉韋。……”,
“Url”:“https://weibo.com/owner1?refer_flag=1005055013_& is_all=1”,
……
}
……
以上集合顯示了一個文檔,該文檔表示編號為1的輿情信息。該輿情信息對應頁面的博主為“Owner1”,輿情采集系統分析出的關鍵詞“新冠”在頁面中出現了3次。文檔還存儲了微博正文信息和頁面的URL。
3.3 系統實現與運行
基于Nutch實現分布式網絡爬蟲是可行的[21]。分布式主題輿情采集系統實現原理如圖6所示,其基于Nutch2.3。利用爬蟲抓取頁面并提取結構化信息后,再經過分詞和主題相關性計算實現主題輿情采集。任務數據庫(隊列)基于Key-Value數據庫Redis實現,可將所有爬蟲需要爬取的URL隊列和已爬取的URL隊列放在共享的URL數據庫中。爬蟲節點從該共享隊列中按需取出URL進行爬取,已爬取過的頁面不會重復爬取[22]。
采用圖6所示的方法對Parse模塊進行擴展、改造,使其具有主題相關性計算功能。若解析得到的數據與主題相關,則將其存入輿情數據庫,并繼續利用從該頁面解析得到的URL繼續進行深度爬行,否則僅進行深度爬行。該方法的數據提取、主題相關性計算是在線進行的,即邊下載網頁邊計算其主題相關性,下載花費時間較長,且不利于利用網絡擁堵低峰期,因此完成采集任務所需時間較長。如果經過主題相關性計算后發現頁面不是主題相關的,則不利用該頁面繼續進行深度爬行,從而提高采集速度,但可能導致一些主題相關頁面丟失。
以下對比分布式采集模式與單機采集模式的性能。分布式采集系統利用5臺機器搭建,1臺部署SpiderMaster,其余4臺部署SpiderSlave,采用相同的機器配置:CPU為酷睿i3-2100,內存為4GB(DDR3-1333MHz),磁盤容量為250GB(SATA)。局域網出口帶寬為100Mb/s,交換機上下行帶寬均為100Mb/s。單機采集系統僅用1臺上述機器實現。系統調試成功后,設置Seed頁面數為5個,depth為10,節點線程數為5,topN為100。選取關鍵詞主題模式并手動輸入關鍵詞,分別運行15、30和60min進行實驗,分布式采集與單機采集處理的鏈接數Ld和Ls如表1所示。
由表1可知,在該局域網部署4爬蟲節點的分布式主題輿情采集系統,采集平均速度約為單機采集系統的2.74倍。因此,利用廉價或老舊計算機實施分布式主題輿情采集與分析系統,是實現快速、大規模主題輿情采集的高性價比解決途徑。
4 結語
截至目前,針對網絡輿情采集技術,國內外都取得了較多研究成果,但是針對主題輿情采集、中文輿情采集以及分布計算技術應用等內容仍有待深入研究。本文基于Nutch設計了一個分布式主題輿情采集與分析系統,可用來初步采集與分析網絡主題輿情信息。相比傳統采集模式,該系統平均采集速度提升了2.74倍。未來還將針對分布計算環境下的輿情信息處理、輿情應對決策、主題生成技術、領域詞典自動化維護技術等作進一步研究。
參考文獻:
[1] 李彥辰,艾慶忠,王少非. 基于Redis的分布式搜索引擎研究[J]. 軟件導刊,2018, 17(3):201-204.
[2] 萬文兵. 面向主題搜索的網絡爬蟲信息采集策略研究[J]. 軟件導刊, 2015, 14(11):68-70.
[3] 馮思度,楊健葉,韓煦. 基于醫療信息的網絡爬蟲系統的研究與設計[J]. 現代信息科技,2019,3(10):23-25.
[4] 周桓. 面向檢驗檢疫領域主題爬蟲的研究及系統實現[D]. 杭州:浙江大學,2017.
[5] 王相軍,劉春曉,刁慕言,等. 全球傳染病疫情信息自動收集系統的研發[J]. 中國國境衛生檢疫雜志, 2017, 40(6):431-434.
[6] 汪睿. 基于核方法的食品安全輿情分析方法研究[D]. 天津:天津科技大學,2018.
[7] 鄭文振. 社交網絡中危害國家安全的突發事件搜索研究[D].? 北京:北京郵電大學,2018.
[8] 孫學誠, 陳前, 唐家駿,等. 大數據背景下的恐怖主義信息傳播途徑分析[J]. 吉林大學學報(信息科學版), 2019, 37(1):91-98.
[9] 馬漢超. 基于主題網絡爬蟲的汽車行業多元信息web系統設計與實現[D]. 成都:西南交通大學,2015.
[10] 鄭燕娥,鄭志明. 基于Heritrix與Solr的就業主題搜索引擎的研究與優化[J]. 齊齊哈爾大學學報(自然科學版),2018,34(4):13-20.
[11] 李俊,周玉英,唐志航. 基于主題網絡爬蟲的服裝信息采集[J]. 信息技術與信息化,2018(8):97-99.
[12] 劉建成,吳保國,陳棟. 基于網絡爬蟲的森林經營知識采集系統研建[J]. 浙江農林大學學報, 2017, 34(4): 743-750.
[13] 段玉風. 大數據環境下分布式數據抓取策略的研究與應用[J]. 網絡安全技術與應用,2019(12):75-76
[14] 陶影輝, 道瑤瑤, 殷曉靚,等. 基于Hadoop的輿情分析系統模型研究[J]. 中國新通信,2019(14):167.
[15] 蔡天鴻,鄧金,史國陽,等. 基于TF-IDF 方法的文本人物群體人格分析方法[J]. 計算機應用與軟件,2019,36(5):35-38.
[16] LILI J. Emotional analysis of e-commerce online comment data[C]. Singapore:3rd International Conference on Education,Economics and Management Research,2019.
[17] 劉林.? 科技人才信息分布式采集及處理關鍵技術研究[D].? 杭州:杭州電子科技大學,2018.
[18] 廖海涵,王曰芬,關鵬. 微博輿情傳播周期中不同傳播者的主題挖掘與觀點識別[J]. 圖書情報工作,2018,62(19):77-85.
[19] YINYI C, KEFA Z, JINLIN W. Performance analysis of PostgreSQL and MongoDB databases for unstructured data[C]. Changsha:International Conference on Mathematics, Big Data Analysis and Simulation and Modeling,2019.
[20] 任明飛,李學軍,崔蒙蒙,等. 基于MongoDB的非關系型數據庫的設計與開發[J]. 電腦知識與技術,2019,15(34):1-2.
[21] 馬蕾,馮錫煒,竇予梓,等. 分布式爬蟲的研究與實現[J].? 計算機技術與發展, 2019, 30(2): 192-196.
[22] 羅嬌敏,耿茜.? 一種基于Redis的分布式爬蟲系統設計與實現[J]. 軟件,2017,38(10):83-87.
(責任編輯:黃 健)
