基于風格遷移和薄板樣條的擴充漢字樣本方法
2020-01-15 05:29:32
浙江工業大學學報 2020年1期
關鍵詞:變形
(浙江工業大學 信息工程學院,浙江 杭州 310023)
隨著人工智能的快速發展,漢字識別在信息錄入與分析、辦公室自動化等方面發揮了重要的作用。國內研究漢字識別始于20世紀70年代末,經過幾十年的發展,從印刷體識別到無約束手寫體識別,從脫機識別到聯機識別,從單個字符識別到整篇文檔的識別[3],漢字識別技術已日漸成熟并取得了大量成果[1]。然而因為漢字自身具有結構復雜、字符集巨大、字符相似度高和字體風格多樣等特點,使得相關研究面臨了很大的挑戰[3]。目前在基于深度學習的漢字識別研究領域,所遇到的最主要的難題是用于算法訓練的樣本數據比較匱乏。在這樣的情況下,會出現過擬合的問題,同時訓練出來的算法模型也難以在實際場景中得到有效應用。因此,漢字樣本庫的豐富程度成了訓練效果的關鍵因素。但是采用傳統手段來采集漢字樣本(例如掃描、拍照等手段),人力、物力以及時間成本上的投入均比較高,而且采集效率也比較低下。
針對上述傳統采集方法的弊端,提出了一種基于融合風格遷移和薄板樣條變形的算法,生成能夠模擬自然條件下(光照、紋理、傾斜、扭曲變形)拍攝采集效果的漢字樣本庫。該算法一方面采用基于塊的快速任意風格遷移方法,生成具有真實感紋理的漢字樣本圖片,這種方法避免了早期的風格遷移方法(例如:使用卷積神經網絡[4](Convolutional neural network,簡稱CNN)進行特征提取[5-6],或是訓練另一個神經網絡來使得該網絡在單前饋計算中逼近最優[7])所遇到的輸出樣本的風格數量有限且運算耗時的問題;另一方面采用了基于薄板樣條變形的插值算法生成有傾斜與扭曲變形的圖片,該方法需要選取N對坐標點來實現漢字圖像的形變,通過選取不同的坐標點對可以實現多種變形。相比余弦整形變換[8]或變形變換[9-10],薄板樣條函數能夠實現更多的變形種類。將上述兩種算法融合起來,對通過風格遷移獲取的效果圖片再進行薄板樣條變形處理,得到既有光線變化效果又有扭曲變形特點的漢字樣本圖片。
1 風格遷移的紋理生成
圖像風格遷移是一種圖像合成問題,以一幅圖像的風格呈現另一幅圖像的內容[11],而圖像合成是基于紋理合成實現的[12]。筆者采用的風格遷移算法的主要組成部分是基于塊的操作,用于在給出風格圖像和內容圖像的情況下在單個層中構造目標激活。
1.1 風格遷移的實現過程
讓C和S分別表示圖像內容和風格的RGB值,并且讓Ф(·)代表預訓練CNN的完全卷積部分函數,該函數能將圖像從RGB映射到某個激活空間。在計算激活之后得Ф(C)和Ф(S),風格遷移的過程為
步驟1為內容和風格激活提取一組塊,分別用{Φi(C)}i∈nc和{Φj(S)}j∈ns表示,其中nc和ns是提取塊的數目。提取的塊應該有足夠的重疊,并包含激活的所有通道。
步驟2對于每個內容激活塊,使用基于歸一化的交叉相關度量來確定最匹配的風格塊。
(1)

通過以上操作得到的是一張由內容圖像的結構和風格圖像的紋理合成的效果圖。
1.2 優化方法
風格化圖像的像素可以通過在具有目標激活Φss(C,S)的激活空間中的損失函數來計算。使用平方損失函數并將筆者的優化目標定義為
Istylized(C,S)=
(2)
式中:合成圖像的維度為h×w×d;‖·‖F為Frobenius范數;TV(·)為圖像生成方法中廣泛使用的總方差正則化項。因為Ф(·)包含多個最大池化操作,這些操作將對圖像進行下采樣,筆者將此正則化用作自然圖像先驗,從而獲得重新上采樣圖像的空間平滑結果。總變差正則化為
(3)
由于函數Ф(·)是預訓練CNN的一部分,并且函數是可微分的,可以直接采用梯度下降不斷更新輸入I以得到最終的風格圖片。
1.3 風格遷移的結果
風格遷移使用Torch7框架實現,目標層是VGG-19網絡的relu3_1層,因為在relu3_1層上風格圖像的紋理更加明顯,且在結構上與內容保持一致。VGG-19網絡沒有使用全連接層。表1為VGG-19網絡從輸入層到relu3_1層的體系結構。由于塊的大小影響風格遷移的結果,隨著塊大小的增加,內容圖像的結果將丟失,并替換為風格圖像的紋理,所以選擇塊的大小為,卷積層使用的濾波器為3×3。
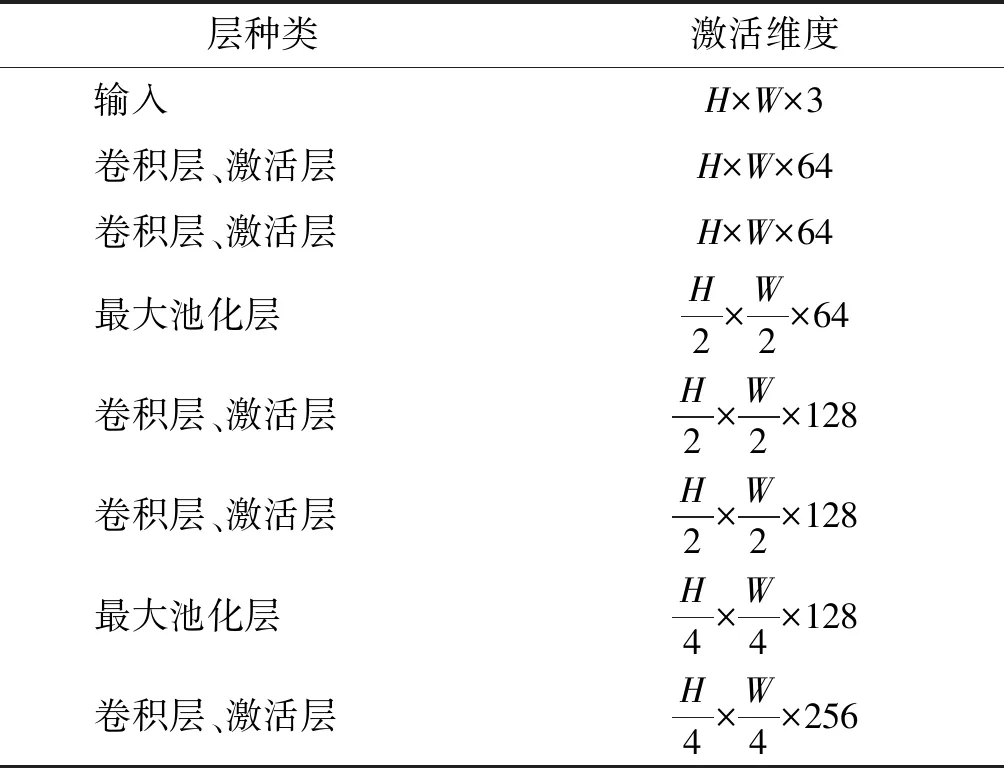
表1 VGG-19網絡結構從輸入層到relu3-1Table 1 Truncated VGG-19 network from the input layer to “relu3-1” (last layer in the table)
選用兩個風景圖片作為內容圖片,選用兩種不同的藝術畫風作為風格圖片,通過風格遷移使風景圖片具有藝術畫風。風格遷移結果如圖1所示。

圖1 風景圖的風格遷移效果圖Fig.1 Style transfer effect picture of landscape
由于漢字識別對樣本的多樣性有一定要求,為了得到具有不同光照和紋理的樣本圖,筆者采用風格遷移的方法,將具有不同光照和紋理的漢字樣本圖片遷移到標準的漢字庫圖像中,以生成具有真實感光照和紋理的漢字樣本圖。圖2是基于相同漢字的風格遷移效果圖,圖3是不同漢字的風格遷移效果圖。從圖2,3可以看出,光照和紋理的風格遷移針對相同漢字和不同漢字的效果是比較理想的。

圖2 相同漢字的風格遷移效果圖Fig.2 Style transfer effect picture of the same Chinese character

圖3 不同漢字的風格遷移效果圖Fig.3 Style transfer effect picture of different Chinese characters
2 TPS的樣本變形
薄板樣條是一種常見的2D插值算法,常用于圖像變形(Image warping)和圖像配準(Image matching)中[13]。在一張2 維圖像上標出N個坐標點Ai(i=1,2,…,n),再給出對應的N個坐標點Bi(i=1,2,…,n)求插值函數Φ(A),即
Φ(A)=(Φ1(Ai),Φ2(Ai))T
(4)
使得插值函數滿足
Bi=Φ(Ai)i=1,2,…,n
(5)
式中:定義自變量A是2維空間的一點;函數值B也是2維空間中的一點。
薄板樣條插值函數形式為
Φ1(Ai)=C+DTA+WTS(A)
(6)
式中:C是標量;向量D∈R2×1;向量D∈RN×1。
S(A)=(U(A-A1),…,U(A-An))T
(7)
U(r)=r2logr2
(8)
式中r是坐標點(x,y)到笛卡爾原點的距離。之所以選用式(4)這種形式的插值函數,是因為把插值函數想象成一個彎曲的薄鋼板,使得它穿過給定點,這樣會需要一個彎曲能量,即
(9)
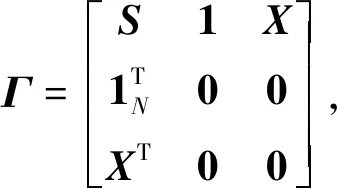
而式(4)是使得彎曲能量最小的插值函數。薄板樣條插值函數Фi有n+3個參數,而式(2)只給出了n個,只有再添加3 個約束條件才能求解,約束條件為
(10)
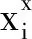
(11)
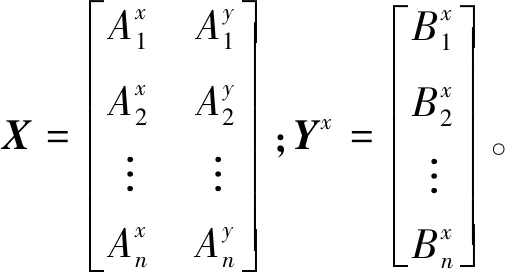
(12)
求得參數帶入式(6),就可以得到變形后的坐標點。
當不需要將對應點嚴格匹配,允許對應點形變后有一定的誤差時,可以通過引入一個正則項λ,得到更加平滑的形變,此時使得彎曲能量最小函數為
(13)
式中:第一項是數據項,它是坐標點Ai形變后的坐標與目標點Bi坐標的歐氏距離之和,用來約束對應坐標點再形變后的距離不要太大;第二項為平滑項,用于約束平滑程度,而需要的平滑程度由參數λ決定[14]。這里的參數λ是正數,當λ為零時,就是簡單的TPS插值;當λ較小時,得到一個平滑程度小的彈性變換;當λ較大時,得到一個平滑程度高且變形程度小的變換;而當λ=∞時,它就是一個仿射變換,沒有局部的變形[15]。因此要根據圖像的實際情況,選擇合適的λ值以實現圖像的變形。因為平滑程度是由λ值決定的,所以要最小化目標函數,只需改動
(14)
在原圖上找出N個坐標點,再給出對應的N個坐標點,使用薄板樣條函數可以將這N個坐標點形變到對應位置,同時給出整個圖片的插值。通過改變兩對坐標點得到不同的形變圖像,效果圖如圖4所示。

圖4 薄板樣條變形效果圖Fig.4 Thin plate spline deformation effect picture
3 融合風格遷移和TPS變形的樣本擴充方法
把上述提出的風格遷移和薄板樣條變形兩種算法進行融合,得到最終的漢字樣本圖片。首先針對原圖和紋理圖片通過風格遷移得到具有真實感的漢字紋理圖片(圖5的風格遷移效果圖),然后再把生成的具有真實感的漢字紋理圖片通過TPS變形生成最終的漢字樣本圖片(圖5的融合風格遷移和TPS變形效果圖),如圖5所示。
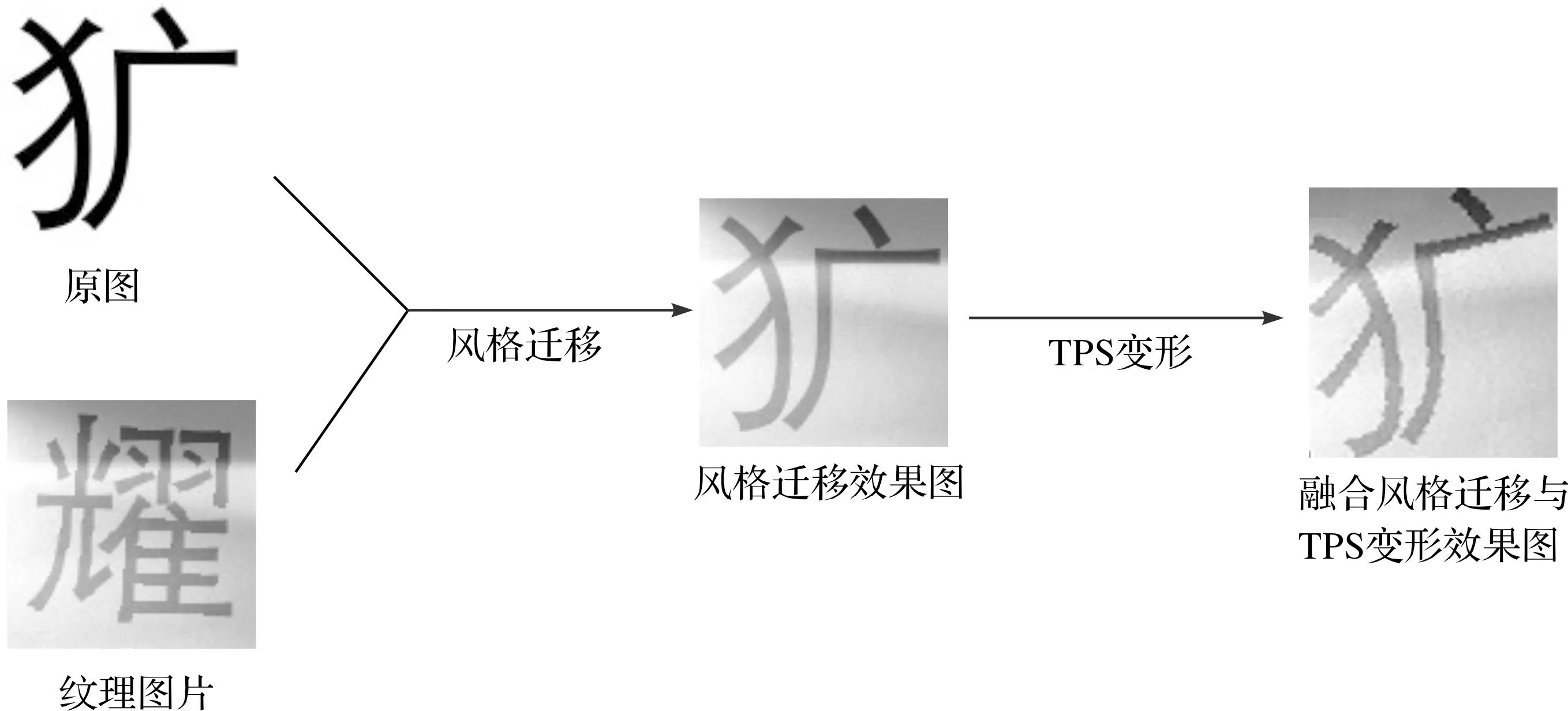
圖5 漢字樣本效果圖Fig.5 Chinese character sample effect picture
4 實驗結果
為了檢驗基于薄板樣條函數和風格遷移算法生成的印刷體漢字樣本庫的有效性,新建了漢字印刷體小樣本庫用來訓練。小樣本庫包含常用的100 類漢字,使用Python的Pygame模塊通過Unicode碼將文字轉換為圖片。采集原始樣本庫:將其中一類漢字圖片使用相機采集20張既有不同真實光照又有不同變形的漢字圖片,并將圖片尺寸統一為100×100像素大小,從每一類的20 張中隨機選出16 張圖片作為訓練集,4 張測試集。建立擴充樣本庫:從原始樣本庫中隨機選出一類漢字的10張圖片作為原始圖片,再將這一類漢字圖片通過TPS變形得到10 種不同變形圖片,每一種變形圖片可以通過風格遷移得到10 張不同光照圖片,這樣一類漢字圖片可以得到100 張既具有不同光照又具有不同變形的漢字樣本集。批量生成得到擴充本庫,最后將圖片尺寸統一為100×100像素大小。以原始樣本庫作為測試集,擴充樣本庫作為訓練集。
實驗采用LeNet-5網絡訓練漢字樣本庫,初始學習率設置為0.000 01,迭代次數為100 000次。如表2 所示,擴充樣本集比原始樣本集的識別率提高了12%。由此可以驗證筆者提出的基于融合風格遷移和薄板樣條變形的漢字樣本庫擴充算法是有效的。

表2 漢字樣本集實驗結果對比Table 2 Comparison of experimental results of Chinese character sample sets
5 結 論
針對傳統漢字樣本庫采集困難的問題,提出了一種基于融合風格遷移和薄板樣條變形的算法,生成能夠模擬在自然條件下(光照、紋理、傾斜和扭曲變形)拍攝采集的漢字樣本庫。提出了使用風格遷移方法生成一批具有光線遮擋和曝光的樣本圖片,然后通過薄板樣條變形得到既有陰影又有變形的漢字樣本圖像,在擴充漢字樣本庫的同時,還解決了漢字識別中光線影響和字體變形的問題。由實驗結果可以驗證筆者提出的基于融合風格遷移和薄板樣條變形的漢字樣本庫擴充算法是有效的。
猜你喜歡
智慧少年·故事叮當(2020年10期)2020-11-06 06:19:00
中華詩詞(2020年1期)2020-09-21 09:24:52
河北理科教學研究(2020年1期)2020-07-24 08:14:34
作文成功之路·小學版(2020年11期)2020-02-01 06:26:58
作文周刊·小學二年級版(2018年29期)2018-11-26 11:20:28
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
童話世界(2018年14期)2018-05-29 00:48:08
數學小靈通·3-4年級(2017年10期)2017-11-08 08:42:59
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
數學大王·中高年級(2016年12期)2016-12-26 21:37:36
