基于logistic回歸的信用反欺詐預(yù)測模型
2020-02-14 06:00:29吳駿一
價值工程 2020年1期
吳駿一
摘要:隨著時代的飛速發(fā)展,互聯(lián)網(wǎng)離我們的生活越來越近。互聯(lián)網(wǎng)可以說是一把雙刃劍,即帶來了更加便捷的網(wǎng)絡(luò)金融服務(wù);又帶來了如信用卡盜刷,電信詐騙,網(wǎng)絡(luò)釣魚等危害。文章基于對信用貸款業(yè)務(wù)的理解,利用銀行業(yè)務(wù)數(shù)據(jù),結(jié)合機器學(xué)習(xí)模型實現(xiàn)了一種基于邏輯回歸算法的信用反欺詐預(yù)測模型。該模型能有效減少信用卡盜刷事件的發(fā)生,減少銀行的損失;同時,該模型還能提高銀行的工作效率,具有較好的工程應(yīng)用價值。
Abstract: With the rapid development of the times, the Internet is getting closer to our lives. The Internet can be said to be a double-edged sword, which brings more convenient online financial services and also brings harm such as credit card theft, telecommunications fraud, phishing, and so on. Based on the understanding of credit loan business, this paper uses bank business data and machine learning models to implement a credit anti-fraud prediction model based on logistic regression algorithm. This model can effectively reduce the occurrence of credit card fraud and reduce bank losses. At the same time, the model can also improve the bank's work efficiency and has good engineering application value.
關(guān)鍵詞:信用卡;反欺詐;logistic
Key words: credit card;anti-fraud;logistic
中圖分類號:F831 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻標識碼:A ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文章編號:1006-4311(2020)01-0206-06
1 ?研究背景
層出不窮的網(wǎng)絡(luò)欺詐,如銀行理財產(chǎn)品漏洞被利用,虛假借款詐騙等正深深地困擾著人們。與此同時這些網(wǎng)絡(luò)金融欺詐的手段正向復(fù)雜化,多樣化方向發(fā)展。金融行業(yè)急需例如本文所提到的模型來解決上述問題。對于新時代的金融機構(gòu)來說,創(chuàng)造出完整的風(fēng)險預(yù)測與控制體系是極為必要的,因為這樣能有效避免欺詐等違法行為的發(fā)生。尤其在消費金融業(yè)務(wù)方面,毫不夸張地說,風(fēng)險控制能力的高低直接決定了業(yè)務(wù)盈利能力的強弱。欺詐案件的發(fā)生,不僅給金融企業(yè)帶來了巨大的經(jīng)濟損失,還給社會帶來了許多不穩(wěn)定因素,挑戰(zhàn)著人們經(jīng)濟與道德的底線。
“反欺詐系統(tǒng)永遠都不是靜態(tài)的,有些人一直試圖尋找它的漏洞,并利用它”。[1]運用傳統(tǒng)方法很難去定義新型詐騙手段。在此情況下,我們必須采取相對的對策。當(dāng)今機器學(xué)習(xí)發(fā)展迅速,在此大背景下,人們很快就將人工智能(AI)技術(shù)融入金融市場之中。利用這種技術(shù),不僅可以使得銀行、證券交易等金融企業(yè)的運營和維護成本有所降低,而且信用評估系統(tǒng)分析的準確率也大大提高。AI技術(shù)投入使用一段時間后,各類網(wǎng)絡(luò)欺詐行為都得到有效控制,各類企業(yè)和客戶的利益都得到了有效保護。
目前運用機器學(xué)習(xí)技術(shù)雖然能夠有效控制網(wǎng)絡(luò)欺詐行為,但是這種新投入市場使用的技術(shù)仍然存在一定的缺陷——在各類金融企業(yè)的數(shù)據(jù)庫中,盡管有足夠量的數(shù)據(jù)以供測試訓(xùn)練和交互驗證,但是其內(nèi)置的反欺詐模型均為靜態(tài)模式,只能對類似于以往已發(fā)生的欺詐行為進行檢測,而面對層出不窮的新型詐騙手段,其檢驗結(jié)果不孚眾望。過去的反欺詐模型,基本都是用傳統(tǒng)的單一化的方式處理問題,并且易受到各類條件的限制,在使用中常捉襟見肘,疲于應(yīng)付如今防不勝防的欺詐手段。由此可見,一種新的反欺詐模型的建立和運用是必然的,也是極為重要的。
2 ?數(shù)據(jù)預(yù)處理
我們選取了來自于kaggle上符合模型需要的數(shù)據(jù)包,數(shù)據(jù)包里的數(shù)據(jù)由歐洲部分信用卡持卡人在2013年9月某兩天內(nèi)進行卡片交易的數(shù)據(jù)組成。數(shù)據(jù)顯示,在284807筆交易中,有近500次信用卡被盜刷記錄,占所有交易量的0.17%。但是,此次選取的數(shù)據(jù)包數(shù)據(jù)波動較大,并且只包含了作為PCA(主成分分析)轉(zhuǎn)換結(jié)果的數(shù)字輸入變量。在法律層面,為保護信用卡持有者的隱私,相關(guān)的數(shù)據(jù)功能和持卡人背景信息不予提供。通過使用PCA獲得主要組件,特征V1,V2,……V28,沒有用PCA轉(zhuǎn)換的唯一特征是時間和交易金額。特征“時間”包含數(shù)據(jù)集中每個事務(wù)和第一個事務(wù)之間經(jīng)過的秒數(shù)。特征“金額”即為交易金額,這是可用于實例依賴的成本認知學(xué)習(xí)的特征。特征“類”即所謂的響應(yīng)變量,如若發(fā)生盜刷事件,則取值1,否則為0。
在基本信息方面,其缺失值情況如圖1的缺失值矩陣圖所示,每一維度沒有缺失值,不需要進行補值操作。
就統(tǒng)計信息而言,V1-V28個維度的均值mean為0.0000,標準差std大約為1,分布較為均勻;amout的均值為88.3496,標準差std為250.1201,分布不均勻,且數(shù)值較小的次數(shù)多,偶爾數(shù)值偏大,在此情形下我們得出了要對這個維度進行特征縮放,使得和其他維度的尺度相同結(jié)論,后續(xù)將對此進行處理。
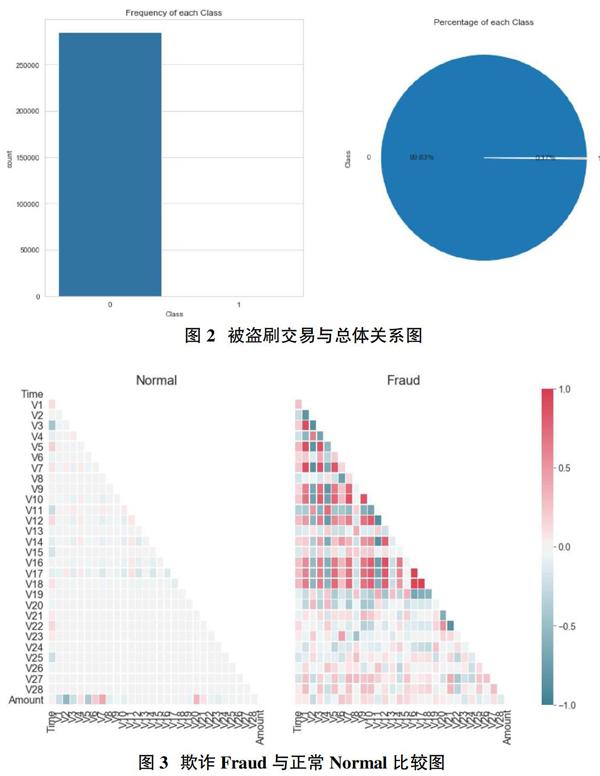
觀察了欺詐和非欺詐兩類消費在數(shù)據(jù)集中的分布情況,如圖2所示,正常消費為0,欺詐消費為1。在284807筆交易中,為0的有284315筆,為1的有492筆,且信用卡被盜刷交易占總體比例為0.17%,可由圖2看出。
通過觀察和分析以上數(shù)據(jù),可以知道信用卡交易正常和被盜刷兩者數(shù)量不平衡,樣本不平衡影響分類器的學(xué)習(xí),稍后我們將會使用過采樣的方法解決樣本不平衡的問題。
除以上操作外,為使數(shù)據(jù)更直觀,還需進行單位轉(zhuǎn)換的操作,將變量time原來的單位由秒變?yōu)樾r。
為了便于算法和模型使用,我們采取了特種工程,從最初數(shù)據(jù)中提取相應(yīng)特征,并進行適當(dāng)選擇以及不同維度的變化,優(yōu)化模型的演示效果。基于此,本文對所收集的數(shù)據(jù)包進行了特征工程探究。
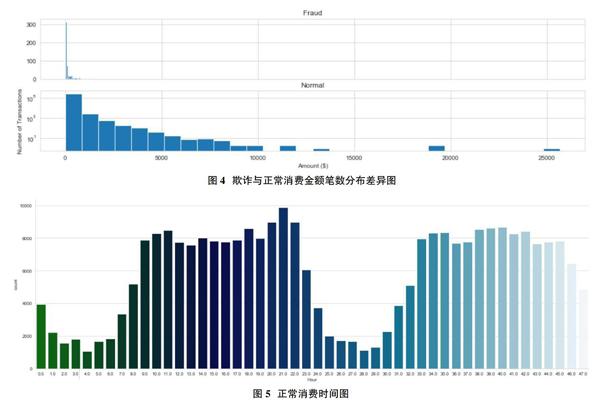
將數(shù)據(jù)集分成欺詐Fraud和正常Normal兩部分,觀察兩種情況下各個維度之間的相關(guān)性,我們可以輕松看出其顏色有深有淺,且淺色較接近0.0,而深色接近1或-1。深入觀察發(fā)現(xiàn)訂單正常的顏色較淺,而欺詐的顏色較深,且欺詐與正常之間差異很大。
從圖3可以看出,部分變量之間的相關(guān)性更突出這一現(xiàn)象在信用卡被盜刷的事件中是較為明顯的。其中變量V1、V2、V3、V4、V5、V6、V7、V9、V10、V11、V12、V14、V16、V17和V18以及V19之間的變化在信用卡被盜刷的樣本中呈現(xiàn)著一定的規(guī)律。
在欺詐與正常消費金額筆數(shù)方面,存在著明顯差異,欺詐交易的金額全部在5000以內(nèi),而正常的金額則分布廣泛,如圖4所示。
由圖5可知,信用卡正常消費的金額呈現(xiàn)出大且集中的特點,而信用卡被盜刷的涉案金額則呈現(xiàn)出小且分散的特點,很明顯,為了更大程度躲避信用卡持有者對消費交易產(chǎn)生懷疑而采取有效的法律措施,犯罪分子更傾向于采用低額盜刷手段。
將欺詐與正常的訂單數(shù)量同消費時間繪制了柱狀圖,通過觀察圖5、圖6不難發(fā)現(xiàn)有關(guān)欺詐與正常在消費時間上的差異,欺詐交易發(fā)生最多的時間是11am;而正常交易發(fā)生最多的是21pm,且在9am到22pm較集中。欺詐與正常在消費時間上的差異圖。
由圖可知,得到了每天早上9點到晚上11點之間是信用卡消費的高頻時間段的結(jié)論。
就不同時間消費金額上的差異,欺詐消費的金額大多在500以內(nèi),且分布較散;正常消費的金額集中在5000以內(nèi),較為集中。如圖7所示。
通過觀察V1-V28每一維度上正常交易和欺詐交易的數(shù)據(jù)分布情況,發(fā)現(xiàn)維度13,15,20,22,23,25分布較為相像,例舉維度13,15的圖可知。
而維度1,2,3,4,5,6,7,8,9,10,11,12,14,16,
17,18,19,21,24,26,27,28等分布較不一樣,例如維度3,維度4所示。
綜上所述,分布相似的說明無法區(qū)分正常和欺詐交易,可以刪除。與此同時,信用卡非正常交易和正常交易之間的變量分布情況有所不同,基于此特點,我們選擇非同種信用卡狀態(tài)下,動態(tài)變化明顯的變量來分析。因此剔除變量V8、V13、V15、V20、V21、V22、V23、V24、V25、V26、V27以及V28變量。這也與我們最初用相關(guān)性圖譜觀察得出的結(jié)論一致。除此之外還要剔除變量Time,保留離散程度更小的Hour變量。
有關(guān)特征縮放,之所以要特征縮放,是因為特征Hour和Amount的規(guī)格和其他特征相差較大。為解決之一問題,通過采用均值/標準差的方法進行了表轉(zhuǎn)化。
為此,我們可以選擇隨機森林的方法來解決。隨機森林是一種分類器,它包含多個決策樹,可以對異種特征的重要行排序進行計算輸出,且可以用于特征探索。正如圖8所示,把18個維度作為輸入,輸出了18個重要性。
由圖可知,v12最重要,amout hour的重要性排名比較靠后,通過前面的工作可以知道amout和hour在正常消費和欺詐消費上存在著很大的差異,是對于分類比較重要的變量,之前更有效,所以我們并沒有刪除有效。而amout hour的重要性比較小,后面的也小,沒有保留無用的,合理的。
3 ?模型訓(xùn)練
在建模的過程中,正常和違約兩種類別的數(shù)量差別較大的特點是顯而易見的,其次該特點會對模型學(xué)習(xí)造成干擾。例如,現(xiàn)在我們收集了某銀行的1000個貸款樣本信息,在這些貸款信息中,有999個樣本屬于正常貸款,只有1個違約貸款。對于學(xué)習(xí)器來說,只需要將所有的貸款樣本信息都歸類為正常樣本,那么結(jié)果準確率將達到99.9%。然而,這樣的決策結(jié)果對我們的風(fēng)險控制于事無補。基于上述問題,我們不得不采取一定措施來有效解決樣本不均衡的問題。
通常情況下處理數(shù)據(jù)不均衡這類的方法有兩種:
第一種方式為過采樣法(oversampling),其主要內(nèi)容為增加正樣本數(shù)量,進而使得正、負樣本數(shù)目接近,然后再進行學(xué)習(xí)。
另一種方式為欠采樣法(undersampling),其主要內(nèi)容為去除負樣本數(shù)量,進而使得正、負樣本數(shù)目接近,然后再進行學(xué)習(xí)。
基于我們得到的欺詐數(shù)據(jù)非常少這一條件,我們選擇采用過采樣的方法來解決數(shù)據(jù)不均衡的問題。smote處理樣本不均衡時,通常按照如下步驟:①就少數(shù)類中每一個樣本x而言,通過采取歐氏距離為標準計算它到少數(shù)類樣本集Smin中所有樣本之間的距離,從而能夠得到其k近鄰。②為了確定采樣倍率N,需根據(jù)樣本不平衡比例來設(shè)置一個采樣比例。對于一個少數(shù)類樣x,從其k近鄰中隨機選擇若干個樣本,并假設(shè)選擇的近鄰為xn。③對于每一個隨機選出的近鄰xn,按照特定的公式分別與原樣本構(gòu)建新的樣本。經(jīng)smote處理后,產(chǎn)生的結(jié)果如表1所示。即在處理之后,正負樣本各占50%,達到均衡狀態(tài)。
Logistic Regression邏輯回歸主要用于分類問題,常用來預(yù)測概率,雖然其與多重線性回歸在實際上有諸多相似之處,但它們最大的區(qū)別就在于他們的因變量不同。我們嘗試用logistic regression模型解決本文的問題。[2]
先利用全體數(shù)據(jù)集訓(xùn)練了一個模型,其準確率為99.8%,主因是我們基于相同數(shù)據(jù)集進行了模型訓(xùn)練和測算,并由此導(dǎo)致模型產(chǎn)生過擬合問題。為了得到更優(yōu)的模型,我們采用cross-validation和grid search的方式。
通常情況下,可以將數(shù)據(jù)集劃分為訓(xùn)練集和測試集的方法有三種:①留出法(hold-out),②交叉驗證法(cross-validation),③自助法(bootstrapping)。而本次項目采用的是交叉驗證法劃分數(shù)據(jù)集,將數(shù)據(jù)劃分為3部分:訓(xùn)練集(training set)、驗證集(validation set)和測試集(test set)。讓模型在訓(xùn)練集進行學(xué)習(xí),在驗證集上進行參數(shù)調(diào)優(yōu),最后使用測試集數(shù)據(jù)評估模型的性能,并采用交叉驗證的方法進行數(shù)據(jù)集的劃分。
我們采用網(wǎng)格搜索調(diào)優(yōu)參數(shù)(grid search)的方式進行模型調(diào)優(yōu)。首先先進行參數(shù)候選集合構(gòu)建,繼而由網(wǎng)格搜索窮舉各類參數(shù)組合,并且由預(yù)設(shè)的評分機制選擇出最優(yōu)參數(shù)。結(jié)合cross-validation和grid search,具體操作我們采用scikit learn模塊model_selection中的GridSearchCV。
在進行調(diào)參的過程中,首先確定模型以及參數(shù)組合,采用5折交叉驗證的方法,模型評估的指標選擇f1-score,調(diào)節(jié)了penalty和 C兩個參數(shù),得到的最終調(diào)整參數(shù)的結(jié)果為{'penalty': 'l2', 'C': 100} ,該參數(shù)下預(yù)測的結(jié)果為0.95750。具體結(jié)果如圖9所示。
接下來探究不同閾值對模型準確率的影響閾值是指在進行類別劃分時,劃分的分位點。為了探究不同閾值對結(jié)果的影響,分別設(shè)置閾值為0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,
計算出precision和recall矩陣,并畫出了同閾值下的precison-recall矩陣,如圖10。
由圖10可知,將閾值0.1至0.9分為9類,并用9種不同顏色的折現(xiàn)表示,最佳的指標是precision和recall都為1,很可惜沒有這種完美的情況,從AUC角度考慮個人認為可以選擇閾值為0.6,因為此時的情況較為優(yōu)良,但不同銀行出于不同的考慮,會有不同的選擇。
precision和recall是一組矛盾的變量。從上面混淆矩陣和PRC曲線可以看到,閾值越小,recall值越大,模型能找出信用卡被盜刷的數(shù)量也就更多,但換來的代價是誤判的數(shù)量也較大。隨著閾值的提高,recall值逐漸降低,precision值也逐漸提高,誤判的數(shù)量也隨之減少。通過調(diào)整模型閾值,控制模型反信用卡欺詐的力度,若想找出更多的信用卡被盜刷就設(shè)置較小的閾值,相反,則設(shè)置較大的閾值。
實際業(yè)務(wù)中,閾值的選擇取決于公司業(yè)務(wù)邊際利潤和邊際成本的比較;當(dāng)模型閾值設(shè)置較小的值,確實能找出更多的信用卡被盜刷的持卡人,但隨著誤判數(shù)量增加,不僅加大了貸后團隊的工作量,也會降低誤判為信用卡被盜刷客戶的消費體驗,從而導(dǎo)致客戶滿意度下降,如果某個模型閾值能讓業(yè)務(wù)的邊際利潤和邊際成本達到平衡時,則該模型的閾值為最優(yōu)值。當(dāng)然也有例外的情況,發(fā)生金融危機的發(fā)生,往往伴隨著貸款違約或信用卡被盜刷的幾率會增大,而金融機構(gòu)會更愿意不惜一切代價守住風(fēng)險的底線。
4 ?總結(jié)
通過一系列的研究,我們最終得到了該基于logistic回歸的信用反欺詐預(yù)測模型。該信用反欺詐預(yù)測模型的實際應(yīng)用,體現(xiàn)了人工智能技術(shù)在金融領(lǐng)域的發(fā)展。其優(yōu)點還是較為顯著的,首先,此模型可直觀展現(xiàn)消費者的交易習(xí)慣,例如發(fā)生交易的時間、金額等;其次,該模型能較為準確地識別出欺詐交易,從而降低欺詐案件發(fā)生的概率,金融公司也由此成為最大受益方,不僅能有效降低措手不及的網(wǎng)絡(luò)欺詐帶來的巨大風(fēng)險,高效地為企業(yè)客戶提供優(yōu)質(zhì)的網(wǎng)絡(luò)金融服務(wù),而且企業(yè)的運營和維護成本也大幅削減,企業(yè)核心競爭力明顯提高,進而為金融行業(yè)的發(fā)展注入了長足的動力。但也存在著些許不足,我們進行建模的數(shù)據(jù)是經(jīng)過脫敏后的數(shù)據(jù),對數(shù)據(jù)的不了解導(dǎo)致我們對數(shù)據(jù)維度的挖掘不夠充分,并且缺乏模型間的比較,后續(xù)可進行相關(guān)研究。
參考文獻:
[1]王威巍.人工智能在金融反欺詐領(lǐng)域的應(yīng)用[J].中國科技信息,2018(20):72-74.
[2]鏈接https://www.cnblogs.com/weiququ/p/8085964.html.
[3]仵偉強,后其林.基于機器學(xué)習(xí)模型的消費金融反欺詐模型與方法[J].現(xiàn)代管理科學(xué),2018(10):51-54.
[4]王文敬.基于SMOTE過抽樣法的個人信用評分模型研究[D].上海師范大學(xué),2019.
