多數據集深度學習模型的修圖處理識別*
2020-02-20 03:42:08陳先意
計算機與生活 2020年2期
楊 濱,陳先意
1.江南大學 設計學院,江蘇 無錫 214122
2.江南大學 輕工過程先進控制教育部重點實驗室,江蘇 無錫 214122
3.南京信息工程大學 計算機與軟件學院,南京 210044
1 引言
當下自拍風靡各種平臺,成為人們日常生活中不可或缺的展示途徑。近幾年,圖像處理軟件的飛速發展,也帶動移動應用領域一大批修圖、美化應用的興起,如Snapseed、Retouch、Inpaint等。照片經過這些修圖軟件處理后變得更美麗,數字攝影作品經過美化處理后帶來了更強的視覺沖擊力。如圖1所示,圖1(a)經過Retouch軟件去除了圖像上部的手,得到圖1(b)。但是修圖、美化軟件的快速發展和普及也帶來了一些社會問題和安全問題。攝影作品造假、網絡詐騙等事件頻繁出現,看到的圖像有多少是可信的,正成為一個棘手的問題[1]。

Fig.1 Example of removing objects by using Retouch圖1 Retouch去除物體的例子
由于所有的圖像操作都不可避免地會扭曲圖像中相鄰像素之間的某些固有關系,不少學者針對這些相鄰像素點間固有關系的不一致性進行深入研究[2]。
文獻[3]是較早關注Inpainting圖像修復領域研究的文獻,他們提出了一種基于實例的修復去除物體的有效偽造檢測算法。該方法使用了中心像素映射、最大零連通組件標記和片段拼接檢測三種技術以提升檢測的準確率。早期基于篡改特征的圖像取證方法主要使用淺層網絡實現,例如支持向量機(support vector machine,SVM)。文獻[4]提出了一種基于圖像邊緣分析和模糊檢測的人工模糊邊界取證方法。作者基于非次采樣輪廓線變換系數,將邊緣劃分為三種類型,然后提取每種邊緣類型的六維特征并用于訓練SVM。實驗結果表明,該方法可以檢測出拼接篡改的模糊邊界[5]。但是該方法有個缺點,即它不能應用于未經歷過濾波操作的圖像。因此,設計一個能夠檢測各種篡改操作留下的特征的方法非常重要。為了實現這一點,使用了來自深度學習的工具,即卷積神經網絡(convolutional neural networks,CNN)。
近年來,深度學習技術飛速發展,不少數字取證方法也開始借助深度學習工具,這其中以卷積神經網絡最為常用。一般最直接的方法是把中值濾波后的圖像直接輸入到CNN中訓練。但是這種方法準確率很低[6]。文獻[7]嘗試用從篡改圖像中提取出中值濾波殘差特征對CNN進行訓練。最終通過訓練過的取證CNN獲得90%以上的正確率。數據的結構信息是表示先驗知識的一種有效方式,可以有效提升分類器的效率[8]。
文獻[9]設計了一個新的卷積層,輸入圖像經過該卷積層后,將輸出圖像每個像素的預測誤差特征,通過該特征訓練CNN,以實現篡改識別。該方法能有效檢測出多種篡改操作。因為通過像素預測算法對滑動窗口的中央像素進行預測,并統計出該像素點的預測誤差特征,所以在濾波檢測中的錯誤率也相對較高。
文獻[10]提出一種基于深度神經網絡的圖像修復取證算法,該算法可通過解碼器網絡預測出像素的類別,根據類別的不一致性判斷圖像是否經過修復篡改操作。同時也使用特征金字塔網絡對解碼器網絡中的特征圖進行信息補充。
文獻[11]提出了一種基于多尺度CNN的篡改圖像檢測方法。通過對多尺度CNN檢測器的分析,可以得到一組每幅圖像的篡改概率圖。通過對能量函數最小化,利用圖切割算法實現篡改概率圖的數據融合問題。
由于數字圖像中常用模糊操作隱藏或抹去篡改的痕跡,針對常用的高斯模糊、均值模糊及中值模糊操作的識別問題,文獻[12]通過在傳統的卷積神經網絡模型中添加一個信息處理層的方式,構建了一種深度卷積神經網絡模型。通過提取出輸入圖像塊的濾波頻域殘差特征,讓網絡模型具備識別一次濾波與二次濾波操作的能力。
目前,大多數卷積神經網絡結構只支持單標簽數據。利用現有的單標簽網絡實現多標簽分類的最直接方法是訓練多個模型,從而將多分類轉化為二分類,以消除多標簽產生的歧義性問題。但將多個標簽完全分開,分別進行特征提取和分類識別,也同樣忽略了它們之間可能存在的關聯對分類提供的有效信息。文獻[13]提出了一種基于改進卷積神經網絡的醫學圖像分割方法。首先采用卷積神經網絡對冠狀面、矢狀面以及橫斷面三個視圖下的2D切片序列進行分割,然后將三個視圖下的分割結果進行集成,得到最終的結果。
為了使得深度神經網絡模型能夠更準確高效地學習到不同數據集的共性特征,本文提出了一種基于多數據集學習卷積神經網絡模型的修圖操作識別方法。首先從原始圖像和修改后圖像中提取周期性特征組成多數據集訓練集。在訓練過程中,將不同數據集的圖像特征數據輸入到多數據集神經網絡模型中。此外,還設計了一個多域損失函數,以增強深入學習特征的識別能力。
2 多數據集學習的神經網絡模型
近年來,多數據集學習(multi-dataset learning,MDL)的神經網絡模型被提出,并應用在多個領域。MDL是一種通過跨不同但相關領域共享知識來改進學習的策略[14]。多數據集學習是指在不同的上下文域中共享關于同一問題的信息。該學習必須以一種有效編碼多個域通用功能的方式對超參數進行關聯。當在多個不同但相關的數據域中有一個任務數據時,就形成多數據集神經網絡[15]。文獻[16]使用MDL技術對面部屬性進行分類。文獻[17]使用MDL技術從人臉圖像中區分人的性別。
盡管MDL技術在人臉識別、目標識別和目標跟蹤等傳統的計算機視覺應用中得到了很大的成功,但是在取證領域卻較少出現相關應用的研究。
如圖2所示,本文提出的MDL神經網絡模型主要包含兩個相同的組成部分CNN。這組CNN模型分別對應兩種美圖軟件的實驗圖像集。在本實驗中,使用Retouch和Snapseed兩款軟件產生的圖像作為實驗圖像集。兩個CNN模型之間共享參數,每個CNN包括4個卷積+池化層組。在最后的卷積+池化層組之后的是兩個全連接層,用于為每個輸入樣本生成表示。最后,利用一個針對多數據集網絡模型的損失函數來得到目標表達式的分布,并計算分類誤差,以便對參數進行微調。
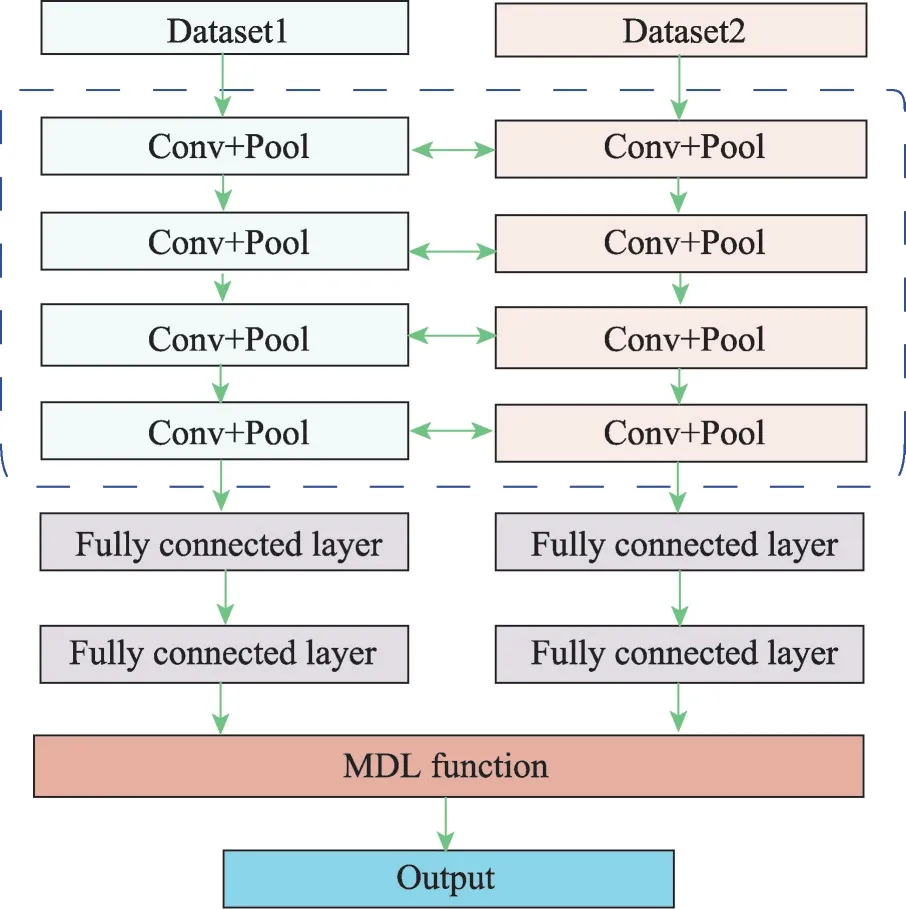
Fig.2 Proposed MDL neural network model圖2 本文提出的MDL神經網絡模型
其網絡模型參數設置如表1所示。用m×m@N表示卷積+池化層組的卷積參數,其中m表示卷積核的大小,N表示卷積核數量。最大池層(max-pooling)用于在卷積層之后減小特征映射的大小。使用串聯校正線性單元(concatenated rectified linear units,CReLU)技術以實現在不損失精度的情況下減少一半的計算量。
網絡模型之間使用了參數共享機制。參數的共享機制是神經網絡的多任務學習中最常見的一種方式。該機制應用到所有任務的所有隱含層上,保留了任務相關的輸出層。共享機制也降低了過擬合的風險。
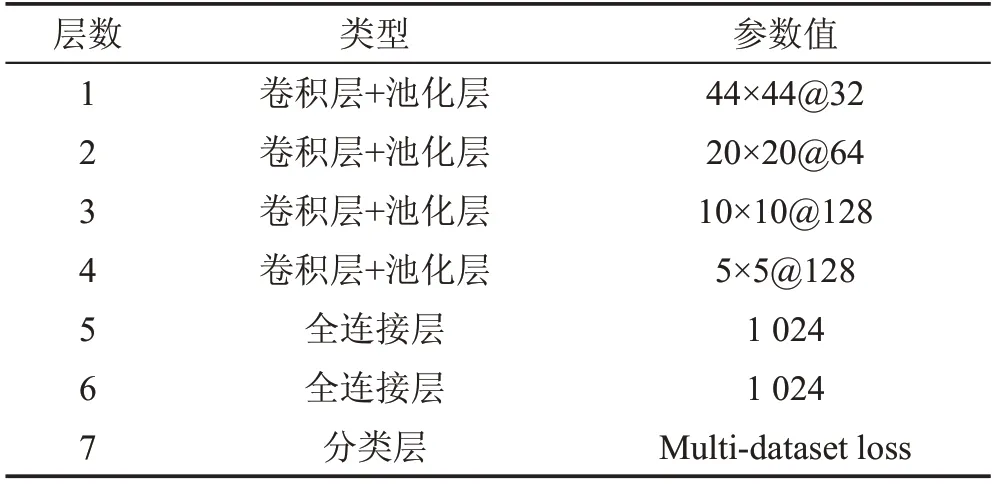
Table 1 Parameters setting of network model表1 網絡模型參數設置
使用不同數據庫的多域方法的主要困難之一是,并非所有樣本都標記為所有任務[18]。為解決這一問題,研究人員在不同領域中設計了各種類型的損失函數。在CNN中,通常使用SoftmaxLoss函數來強制不同類別的特征保持分離。網絡所學習的特征對應于不同的特征空間聚類。但由于類內變化較大,不同聚類中的特征可能會變得分散。同時由于各個階間的高度相似性,集群也經常會出現重疊現象。
為了解決該問題,文獻[17]提出了使用Center Loss算法來減少聚類內的特征變化幅度。它在估計每個類特征的中心的同時,調整屬于不同類中心的特征之間的距離。中央損失函數可以將特征聚集到相應的類中心。然而,由于該算法沒有考慮類間相似性,在多數據集學習中效果還有進一步提高的空間。
在中央損失函數算法的啟發下,提出了一種新的MDL函數來增強神經網絡特征學習的識別能力。MDL不僅能夠壓縮每個集群,而且能夠隔離集群。
假設LC為中央損失函數,其定義為:
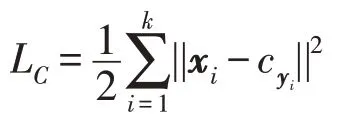
其中,yi和xi分別表示第i個對象和它從全連接層得到的特征向量。是所有標記為yi的特征向量的中心,k是該聚類中的特征數量。在反向傳播(back propagation,BP)的過程中,計算相對于LC輸入樣本的xi的偏導數的中心:
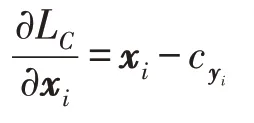
在迭代優化中更新聚類的中心:
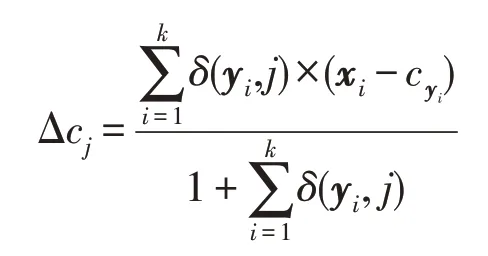
其中,δ(yi,j)定義為:
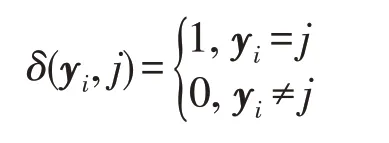
為了充分利用多數據集處理的特征信息,計算其中某一個樣本與其他所有聚類中心之間的距離,設為LMT。
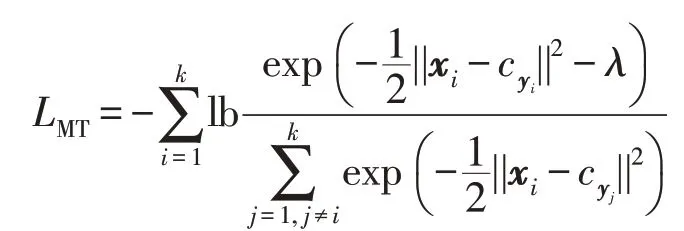
其中,λ是預定義的邊界參數,為了減少計算量,使用隨機梯度下降(stochastic gradient descent,SGD)算法[18]通過在線學習來更新參數。這樣上式變為:
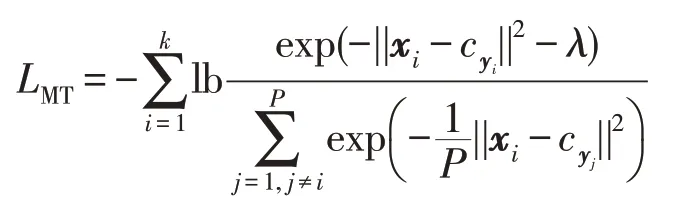
選擇合適的參數P以跳過一些與當前中心相對較遠的類中心。在本文中,P設置為1.5倍聚類中心距離。最后,根據不同數據集的LMT值得到損失函數LML
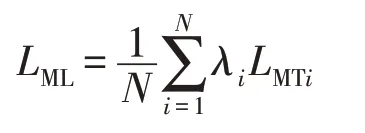
3 圖像特征提取和神經網絡訓練
在對數傅里葉域中,模糊前后的圖像具有等距性。基于此特性,文獻[19]提出了一種基于黎曼測地線(Riemannian geodesic)[20]的高斯模糊核恢復方法,該方法對原始圖像和模糊圖像之間的模糊不變量進行評估,并從模糊圖像中恢復模糊核。該方法有效應用于Retouch軟件模糊的圖像中。受到該算法的啟發,基于黎曼測地線提取圖像塊中的高斯模糊核參數作為深度學習的圖像特征。設Kε為卷積核函數,滿足歸一化性質。設為f的傅里葉變換,Kε的傅里葉變換為:
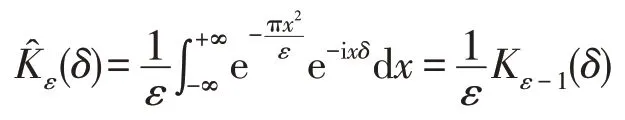
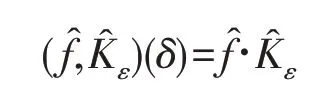
由于卷積在頻域表現為乘性操作,取對數運算可把卷積轉換為求和。設在對數傅里葉空間的卷積為:
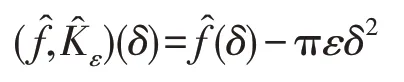
上式表明對數傅里葉空間函數卷積后偏移了πεδ2的距離。在二維空間里,函數f和Kε在空域、頻域和對數傅里葉域的卷積操作與一維域類似。文獻[20]對黎曼對稱空間上的高斯分布概率進行了深入研究,指出指數黎曼度量和多項式黎曼度量對R →C(C為復數域)函數系在R+(正實數集)上卷積操作具有等距性,因此指數黎曼度量和多項式黎曼度量可量測卷積前、后的信號變化。設偏移πεδ2的軌跡方向單位向量為:
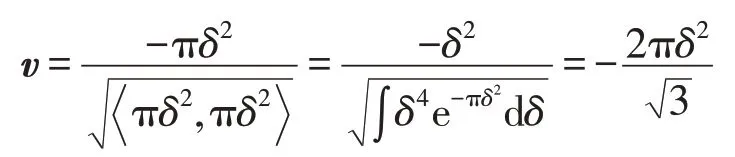
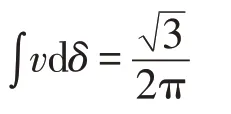
得到:
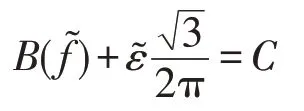
上式是以高斯型卷積核Kε為基礎的推演結果。通過以下步驟計算模糊核的預測值。
步驟1把圖像I、潤飾圖像Im變換至對數傅里葉空間,分別得到。
步驟2分別計算模糊量。
步驟3計算模糊核的預測值ε。
步驟4當預測值ε大于給定閾值v的時候,則判定該圖像進行了模糊修飾操作。
4 實驗和結果分析
使用在一臺配有Nvidia GeForce GTX 1080Ti 11 GB RAM顯卡的服務器上進行神經網絡模型架構并執行訓練任務。從多個公共實驗庫中選取了5 000張實驗圖像,其中的公共數據庫包括:BOSSbase1.01[21]、UCID圖像數據庫[22]、CASIA v2.0圖像庫[23]。圖像分辨率為512×512至2 048×1 356之間。隨機對其中70%的圖像進行Retouch和Snapseed操作,得到兩個訓練圖像集,剩下的30%圖像作為測試集。本文所提的檢測方法以圖像塊為檢測對象,這樣有利于定位出圖像的具體修改位置,因此圖像塊大小的選擇十分重要,過大的圖像塊會造成少量像素修改難以被檢測;而過小的圖像塊的修改特征又難以被神經網絡所學習。根據多次實驗結果,本文確定分割圖像塊的大小為64×64像素。因此所有圖像被裁剪為64×64大小的圖像塊。
采用真陽性率(true positive rate,TPR)和假陽性率(false positive rate,FPR)對檢測結果進行檢測。TPR是正確識別的被篡改圖像的分數,而FPR是將原始圖像識別為被篡改圖像的分數。
圖3和圖4分別給出了使用本文提出方法對Snapseed數據集和Retouch數據集中例子的識別結果。圖3第一行實驗圖像使用了修復功能,第二行實驗圖像使用了局部增亮功能;圖4的兩行實驗圖像則分別使用了Retouch軟件的去除及拉伸功能。實驗結果表明,本文提出的方法能夠準確判別出當前主流軟件的大部分修圖處理操作。

Fig.3 Detection examples on images processed by Snapseed圖3 對Snapseed處理過的圖片的識別例子
表2給出了本文提出的修圖檢測方法的實驗結果。從測試結果可以看出本文方法具有較高的TPR和較低的FPR值,可以應用于實際取證、識別場景中。

Fig.4 Detection examples on images processed by Retouch圖4 對Retouch處理過的圖片的識別例子
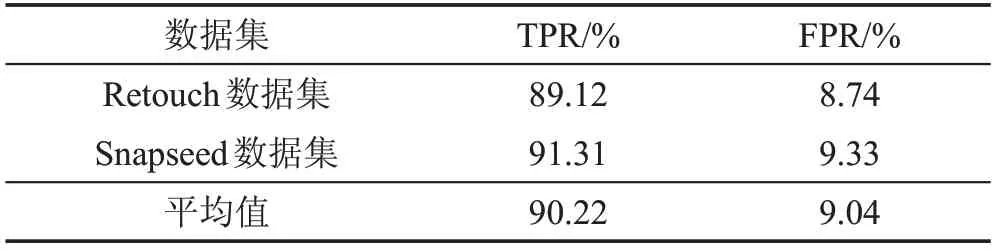
Table 2 Experimental results on different datasets表2 不同數據集上的實驗結果
由于針對圖像修飾軟件的識別方面的研究比較少,選取了當前比較有代表性的圖像修改檢測方法(文獻[3]、文獻[9]、文獻[10]和文獻[24])在不同數據集上進行對比實驗。其中,只有文獻[3]并未使用深度神經網絡技術。這4個方法的特征如下,對比實驗的結果如表3所示。
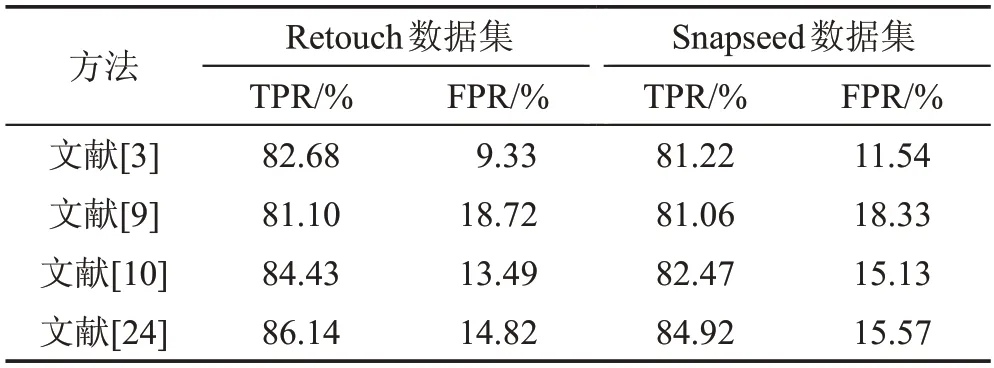
Table 3 Comparison results of each method on two datasets表3 每種方法在兩個數據集上的實驗結果對比
文獻[3]使用了中心像素映射、最大零連通組件標記和片段拼接檢測3種技術以提升檢測的準確率。
文獻[9]通過給傳統CNN添加一個處理層來檢測圖像像素點不連貫性。
文獻[10]提出使用特征金字塔網絡對解碼器網絡中的特征圖進行信息補充。
文獻[24]利用重采樣特征和A-對位分析算法,計算篡改值得分并輸出檢測結果。
總體來看,各種方法在Snapseed數據集上的檢測成績比在Retouch數據集上的低。這是由于Snapseed比Retouch的高斯模糊參數值相對較低,同時Retouch常常使用更多的邊緣虛化操作。但是總體而言,兩個數據集的實驗結果相差不大。
文獻[9]設計了一個新的卷積層,輸入圖像經過該卷積層后,將輸出圖像每個像素的預測誤差特征通過該特征訓練神經網絡,以實現篡改識別。該方法的特征提取處理相對簡單,它的TPR值并不令人十分滿意,而且其FPR值也相對較高。這是因為通過像素預測算法對滑動窗口的中央像素進行預測,并統計出該像素點的預測誤差特征。而在自然圖像中,存在不少符合該預測誤差條件的真實圖像,這將導致神經網絡模型出現誤判,提高了其FPR值。得益于卷積內核網絡的使用,文獻[24]獲得了較高的TPR和較低的FPR值。然而,該方法需要根據實際情況調整參數和熱圖輸出百分比來提升準確率,因此不太適合于實際應用中。文獻[3]中的檢測方法由于針對inpainting修改類型,因此其檢測結果也比較令人滿意。綜合實驗結果顯示,本文提出的基于多數據集深度學習模型的修圖操作識別方法優于現有主流的方法,并獲得了最高的識別成績。
5 結束語
本文針對手機APP中的修圖處理軟件,提出一種基于多數據集特征學習的神經網絡模型,并給出其網絡拓撲結構設計。區別于傳統的多個神經網絡并行操作,提出的模型能在共享網絡模型參數的同時對多個特征數據集進行深度學習,使檢測算法具備多特征識別能力。為了增強深度特征學習的能力,對多個子神經網絡輸出特征進行融合,本文還設計了一種針對多模塊神經網絡模型的損失函數。實驗結果驗證了本文提出的方法的有效性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
