一種面向財務文本分類的TF-IDF改進算法
2020-02-22 03:09:35孫德華孫晨
現代信息科技 2020年18期
孫德華 孫晨
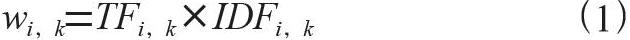
摘? 要:結合財務文本特征,對TF-IDF方法在應用到財務文本分類時的不足進行了分析,提出了一種新的特征詞權重計算方法(SNGTI-LFDF)。該算法以TF-IDF方法為基礎,引入停用詞失效的N-Gram方法和特征詞位置詞頻因子,保留特征詞位置信息并改善了特征詞的權重分配。采用樸素貝葉斯方法對分類性能進行了驗證,實驗結果表明,相對于TF-IDF和同類改進算法TF-IDF-DL,SNGTI-LFDF方法取得了更高的準確率、召回率和F1值。因此該算法在能較好地提高財務文本分類性能。
關鍵詞:TF-IDF;N-Gram;位置因子;SNGTI-LFDF;財務文本分類
中圖分類號:TP301.6? ? ? 文獻標識碼:A 文章編號:2096-4706(2020)18-0107-05
Abstract:Combining with the characteristics of financial texts,the TF-IDF algorithm was investigated for its shortcomings when applied to financial text classification,and a new algorithm for calculating the weight of feature words (SNGTI-LFDF) was proposed. This algorithm is based on TF-IDF method,and introduces the N-Gram method of invalid stop words and term frequency location factor,which retains the location information of the feature word and improves the weight distribution of the feature word. The Naive Bayes method is used to verify the classification performance. The experimental results show that compared with TF-IDF and the similar algorithm TF-IDF-DL,the SNGTI-LFDF method achieves higher accuracy,recall and F1 value. Therefore,the algorithm is better improving the performance of financial text classification.
Keywords:TF-IDF;N-Gram;location factor;SNGTI-LFDF;financial text classification
0? 引? 言
隨著信息技術的發展,網絡文本充斥著人們生活的方方面面,財務文本是網絡文本中的一大分支,在財務危機預測[1]、資本市場調研、企業管理等方面都有重要的指示作用。就財務文本的性質和作用可以將其劃分為政策類財務文本、規章制度類財務文本、統計數據類財務文本。其中政策類財務文本是國家各行政部門、企業財務部門等針對財務狀況出臺的一系列財務管理的方針、政策,這類文本為個人和企業提供政策指引,做出更好的財務決策;規章制度類財務文本是各企業制定的符合企業發展的章程,對企業和財務工作者制定符合其發展的規章制度有很高的參考價值;統計數據類財務文本是符合客觀財務信息并能反映一段時間內企業財務狀況的文本,統計類財務文本可以幫助規避投資風險、預防財務詐騙等。然而在這個大數據時代下,各類財務錯綜復雜,使得我們很難快速準確地找到所需類別的財務文本,由于缺乏信息資料進而造成損失。作者結合實習項目“財務機器人”的開發,對智能財務機器人的實現進行了深入調研,智能財務機器人的實現要依據大量的已知類別的財務文本,通過學習每種類別的文本的特征,總結經驗,實現智能化。因此如何快速準確地對財務文本進行分類就成了一個待解決的課題,傳統的基于人工進行財務文本分類同時存在效率低下和人為失誤不可避免等問題。機器學習和人工智能技術的發展使得自動高效地進行財務文本分類[2]變成了可能,有效地改善了人工分類時所帶來的問題,它通過學習已標記類別的文本集,建立文本特征詞與文本類別之間的關系模型,進而通過該模型對新的文本進行類別判定。
對文本進行分類要遵循文本所具有的特征。本文擬根據財務文本特征定向的改進文本分類中常用的方法——TF-IDF算法[3],以較好地提升財務文本分類的性能。因此本文收集調研了大量的財務文本并對財務文本的特征總結為:
(1)財務特征詞的不可分割性:財務特征詞又可叫作財務術語,不可分割性是指一旦分割就會偏離原詞所表達的含義。如“固定資產”雖然可以被拆分為“固定”和“資產”兩個有實際意義的詞,但是其已經偏離了原特征詞所表示的含義;
(2)財務文本結構的嚴謹性:結構的嚴謹性是指大多數財務文本都符合類似“總分總”這樣的文本特征,在文本始末都會出現對文本進行總結的內容。
TF-IDF算法是一種基于詞頻統計的特征權重計算方法,通過計算詞頻和逆文檔頻率來計算特征詞的權重,在應用到文本分類時取得了良好的效果,但是傳統的TF-IDF方法還存在有明顯的缺陷,第一,依賴于特征詞提取的效果,在特征詞提取準確率不高的情況下,分類性能較低;第二,未考慮特征詞出現的位置信息,默認賦予所有特征詞同樣的權重。基于此,結合財務文本的特性,本文的主要工作為:
(1)引入了基于去停用詞的N-Gram方法,在豐富特征詞的同時清除了無效特征詞帶來的影響;
(2)引入特征詞位置因子,加重符合文本主題的特征詞的權重;
(3)提出了基于N-Gram特征詞失效和位置因子和詞頻統計的TF-IDF方法(SNGTI-LFDF)并在財務數據集上取得了良好的效果。
1? 相關工作
為了考慮一個詞語對其上若干個詞語的依賴關系,Jestes[4]等人在2013年便提出了N-Gram的概念,N-Gram在保留詞匯的特征信息的同時也保留了特征詞的位置信息;文獻[5]將N-Gram方法用到計算機病毒特征碼的提取中,取得了較好的結果;文獻[6]在SQL注入檢測中結合N-Gram中提取SQL語句固定維數的特征向量,提高了檢測率降低了誤報率;文獻[7]將N-Gram模型結合卷積神經網絡,從而提升了短文本分類的分類性能。文獻[5-7]的結果表明,N-Gram方法與特定領域結合使用時,可以在一定程度上取得較好的效果。
對于TF-IDF算法來說,其核心就是特征詞的權重計算,計算方式為:
其中,wi,k為文本i中的第k個特征詞的權重。針對傳統的TF-IDF算法存在的不足,眾多學者都其進行了研究改進。文獻[8]通過改進特征詞權重計算,提出詞頻-逆重力矩計算方法,提升分類效果;文獻[9]引入去中心化詞頻因子和特征詞位置因子,加強特征權重的準確性;文獻[10]將新詞納入TF-IDF的權重計算中,達到了特征降維的目的,提升了文本分類的效果;文獻[11-12]均引入權重影響因子,對TF-IDF算法的權重進行優化,這些改進算法雖然提升了文本分類的準確率,但其在應用到財務文本分類時,由于未結合財務文本特征,還存在著一定的局限性。
2? 改進的TF-IDF權重計算方法
2.1? 基于停用詞失效的N-Gram方法
N-Gram方法是從一個句子中提取連續的N個字的字符串集合,可以獲取到字的前后信息的同時還可以提高特征詞提取的豐富程度。例如“資產轉移手段”,如果按照傳統的TF-IDF涉及的關鍵詞計算過程,其關鍵詞信息只有“資產、轉移、手段”,但結合N-Gram方法進行詞匯特征的選取,以2-Gram為例,程序和執行結果如下所示:
In[1]: content = “資產轉移的手段”
...: ls_word = list(content)
...: bigram = []
...: for i in range(len(ls_word)-1):
...:? ? word = “”
...:? ? ?for j in range(i,i+2):
...:? ? ? ? ?word+=ls_word[j]
...:? ? ?bigram.append(word)
...: print(bigram)
[“資產”,“產轉”,“轉移”,“移的”,“的手”,“手段”]
由以上結果可以看出,原來僅有的3個特征詞,經過2-Gram的處理變長到了6個,特征詞的豐富程度得到了極大的提升,但這種方式也帶來了無效特征詞的干擾,如上述結果中的“產轉、移的、的手”,這類特征詞不僅不具備特定的意義而且還會對文本處理的結果產生干擾,影響文本分類的性能。其中部分的無效特征詞可以通過一定的手段將其識別并從特征詞分詞表中刪除,如“移的、的手”兩詞都包含有字符“的”,而“的”通常是描述定語和形容詞之間的修飾關系,與其組成的詞在語義上無任何意義,相同的一類詞在文本中經常出現的還有“是、為、也、了、個”等,與這些詞組成的特征詞在語義上無任何意義,因而又被稱為停用詞。停用詞失效是指一個特征詞如果包含有停用詞,那么這個特征詞是無意義的,對文本分類結果產生負面影響。
基于停用詞失效的N-Gram方法就是在使用N-Gram方法進行特征詞劃分選取時,對特征詞是否包含停用詞進行判別,判別公式如式(2)所示:
其中,termi,k指文本i中的第k個特征詞,validi,k第k個特征詞的有效性,stw指停用詞。
其具體步驟為:
(1)使用N-Gram方法對文本處理得到一個特征詞集合TC;
(2)使用式(2)對TC中的第k個特征詞進行有效性判定,結果為True則轉到步驟(3);若結果為False,轉到(4);
(3)從TC移除當前的第k個特征詞,TC長度減1;
(4)k加1,轉到(2),直到k值等于TC的長度,結束處理過程。
2.2? 特征詞位置詞頻影響因子
在財務文檔中,大多數文檔都符合中文文本“總分總”的結構,即在文本的開始和末尾都會包含符合文本主題的特征詞信息,這類特征詞對文本較為重要,應該賦予更高的權重,所以本文將特征詞的位置信息作為特征詞權重調節的重要影響因子。以1為度量單位,將所有的特征詞以第一次出現的位置排列成一個序列,取文本序列最中間的位置為原點,建立二維直角坐標系,x軸存儲特征詞的相對位置信息,y軸存儲特征詞的詞頻(Term Frequency,TF)信息,以原點為基礎,計算其他特征詞與原點的距離(x軸絕對距離),距離越大,說明其越是位于文本的開始或者末尾,應該賦予更高的權重。在一份文檔中,文本的開始和末尾包含有若干特征詞,特征詞的TF值可以客觀地反映特征詞對文本的重要程度,將特征詞位置因子和詞頻因子結合,距離越遠、頻次越高的特征詞對文本更重要,應賦予更高的權重。但在實際處理過程中,會出現某個特征詞在長文本中出現的頻次比短文本中出現頻次高,產生偏袒長文本的現象,因此需要對TF值進行規范化處理,通過取特征詞的詞頻和文本中特征詞的總數的比值定義規范化公式如式(3)所示:
其中,RTFi,x為規范化處理后的詞頻值,結果取兩位小數點,Mi為文本i包含的特征詞的總數,TFi,x為文檔i中位置x的特征詞的詞頻。
將位置因子和詞頻因子結合,定義位置詞頻(Location Factor Term Frequency,LFDF)影響因子,要增加的文本i中x位置的權重LFDF值計算如式(4)所示:
其中,ε為權重值倍數,范圍在(1,+)之間,η的范圍在(0,D/2)之間,D為序列總長度。
2.3? SNGTI-LFDF算法
將基于停用詞失效的N-Gram方法與特征詞位置詞頻影響因子相結合,定義基于停用詞失效和改進TF-IDF算法的特征詞權重計算算法(SNGTI-LFDF),算法步驟為:
(1)引入N-Gram模型,使用2.1章節的方法對特征詞集處理,得到一個有效特征詞集合;
(2)引入特征詞位置詞頻影響因子,使用式(4)計算特征詞的LFDF值;
(3)將特征詞的位置詞頻影響因子納入TF-IDF權重計算公式中,最終得到SNGTI-LFDF公式,由式(1)和式(4)得:
其中,weighti,k為由SNGTI-LFDF算法計算的文本i中第k個特征詞的權重值。
3? 實驗與結果分析
3.1? 實驗數據
目前公開的數據集中少有中文財務文本檔,本文從國內一些財經網站和相關金融媒體微博、公眾號等搜集整理了一個包含3 720條數據的財務文本集,其數據遵循的格式為:
為了保證出差人員工作和生活的需要,合理使用差旅費用,提高出差效率,特制定差旅費用報銷管理制度。
交通工具按標準乘坐,采用實報實銷制……
……
差旅費用報銷制度即日起施行
同時,對獲取的文檔進行分類處理,將其劃分為政策類、統計類、制度類三種類型的文本,各類文本的測試集和訓練集數量的劃分如表1所示。
3.2? 實驗步驟
本文采用傳統的TF-IDF算法、文獻[8]中的TF-IDF-DL算法和SNGTI-LFDF算法進行特征詞權重計算。并使用樸素貝葉斯方法實現對文本的分類,結合實驗結果進行分析,具體實驗步驟為:
(1)提取特征詞并將生成的特征詞轉化詞頻向量;
(2)分別采用傳統TF-IDF、TF-IDF-DL和SNGTI-LFDF算法對特征詞的權重進行計算,選取權重最高的M個特征詞;
(3)將訓練集文本的特征詞送入到樸素貝葉斯分類器,訓練分類器模型;
(4)對測試文本按照樸素貝葉斯理論[13]進行相似度的計算,對最后相似度的大小排序,選擇相似度最大的作為待分類文本的類別;
(5)對比分析實驗結果。使用準確率、召回率、和F1值作為分類器性能的評估指標。其中準確率指分類結果中正確分類為A類別的樣本數占所有分類為A類別的樣本數的比例;召回率指分類結果中正確分類為A類別的樣本數占實際為A類別的樣本數的比例;F1值為準確率和召回率的調和平均值。
3.3? 實驗對比
采用SNGTI-LFDF算法進行特征詞權重計算時,首先需要計算出需要選取的N-Gram方法中的N值來完成特征詞的劃分。由于N-Gram方法也適用于所有的權重計算方法,本文采用TF-IDF方法對不同的N值設定的情況下,財務文本集分類的準確率結果進行了計算驗證,結果如表2所示。由表2可知,分類的準確率、召回率和F1值隨著N值的增加均有上升的趨勢,在N=4時,分類的準確率、召回率和F1值均達到最高,而后隨著N值的增加分類的性能不斷降低,因此可以斷定4為分類的一個峰值,應采用4-Gram作為本文的特征詞劃分方法。
3.3.1? 參數選擇
在文本分類中,特征詞的選取直接關系到文本分類的結果。少量的特征詞不能準確的表達文本的主題,造成文本分類效果較差,但特征詞數量過大,也會對實驗產生一定的消極影響。因此在分類前,首先要計算出需要送入樸素貝葉斯分類器中的權重值最高的M個特征詞數量M。由于特征詞數量的選取適用于所有的權重值計算方法,因此本文采用傳統的TF-IDF方法在財務數據集上的文本分類的準確率和時間兩個方面綜合考慮M值的選取,圖1為特征詞數量對分類的準確率的影響。
假設文本i中的特征詞的總數量為D,由圖1可知,當選取的特征詞數量M占總量D的40%左右時分類的準確率增長速度開始變慢,由圖2可知,當M占總量D的50%時,分類需要的時間開始急劇增加。因此,為了兼顧文本分類的準確率和時間性能,本實驗選取中間值45%作為每個文本作為分類的特征詞數量比例,即M=0.45×D。
此外還需要計算出特征詞位置信息的影響因子ε和η的值。η值反應特征詞的位置信息,ε為加權因子。本文等比例地從三個種類的財務文本集中抽取200個文本,其中政策類財務文本70個、統計類財務文本82個,制度類財務文本48個,對每個文本經過4-Gram方法進行分詞后,分別計算每個財務文本的始末特征詞數量與文本特征詞總數量的商,得到一個文本比例數據集,經過對數據集進行分析,發現其符合均值μ為0.12,方差σ為0.03的正態分布,其分布如圖2所示,因此可以假設所有的財務文本的始末特征詞數量與特征詞總數量的商也都符合這一分布,即需要根據位置信息對特征詞進行加權操作的特征詞數量占總特征詞數量的12%,此外,對這200個文本進行平均特征詞權重數量的計算,得到每個文本平均特征詞數量為545,由于這200個文本是隨機選取的,可以認為整財務文本數據集中的平均特征詞數量為545,因此η的最優值計算為545×(1-0.12)/2,即η=240。
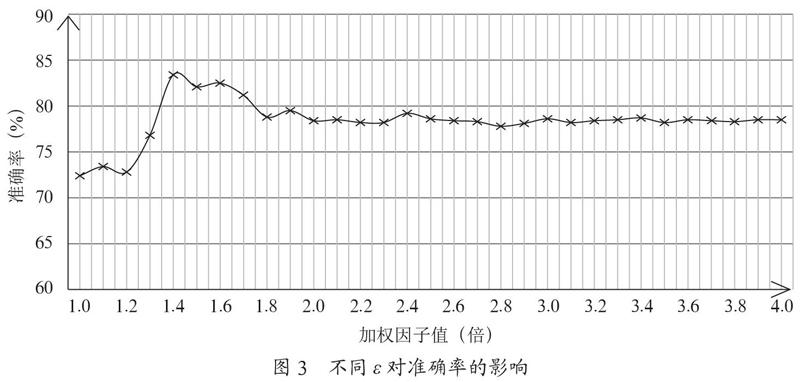
在η值確定后,把ε作為變量,對財務文本分類的準確率進行了驗證,結果如圖3所示。
由圖3可知,隨著加權因子ε的增加,文本分類的準確率也會有一定的提升,但在ε值達到1.4時,分類的準確率達到峰值,此后ε值再增加,分類的準確率反而會降低,因此本文選取ε=1.4作為特征詞權重的調節值。
3.3.2? 結果分析
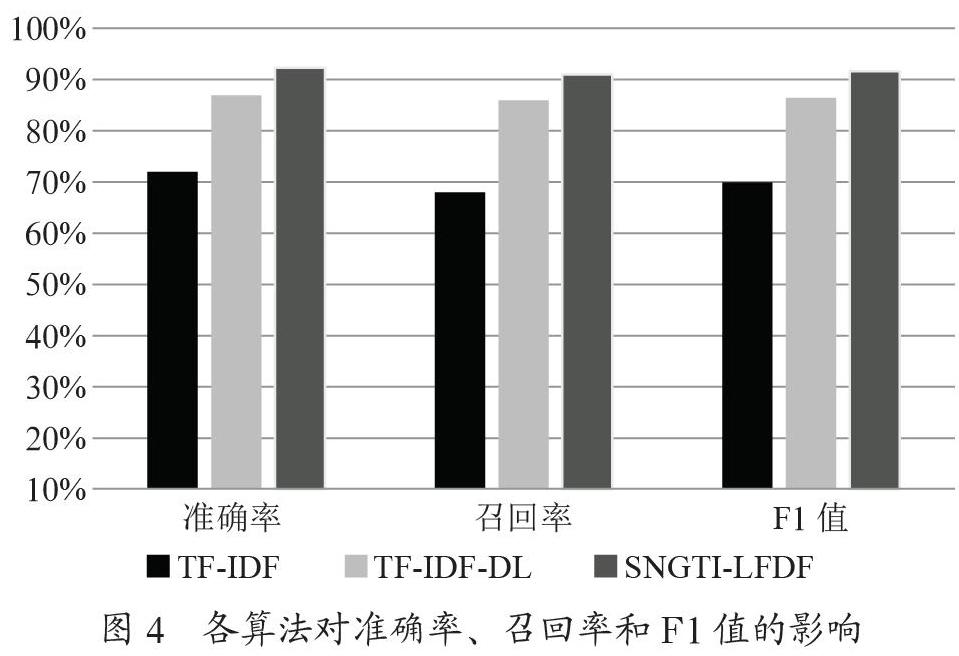
完成了對各個實驗參數的求解,分別使用TF-IDF、TF-IDF-DL和SNGTI-LFDF算法對財務數據文本進行特征詞權重的計算,并將訓練集文本的特征詞經由貝葉斯方法訓練得到樸素貝葉斯分類器,對測試集文本進行驗證,記錄每個方法計算得到的準確率、召回率和F1值,結果如圖4所示。
通過實驗對比,由圖4可知,SNGTI-LFDF算法在財務文本分類的準確率、召回率以及F1值的性能表現方面都較TF-IDF和TF-IDF-DL算法有了較明顯的提升。其中SNGTI-LFDF的準確率、召回率以及F1值較TF-IDF方法分別提升了20.3%、23.0%和21.7%,較TF-IDF-DL算法分別提升了5.3%、5.0%和5.2%。說明SNGTI-LFDF在財務文本分類中,能適應財務文本的特征,分類效果更好,是一種良好的特征詞權重計算方法。
4? 結? 論
通過調研財務文本的特征,總結TF-IDF方法在應用到財務文本分類中存在的不足,引入N-Gram方法進行財務文本特征詞提取的同時引入特征詞位置因子對TF-IDF方法進行改進,提出SNGTI-LFDF算法并結合樸素貝葉斯方法對算法的性能進行驗證。實驗采用自整理的財務文本數據集,結果表明該算法在財務文本分類中取得了較高的準確率、召回率和F1值,較好地提升了財務文本分類的效果。
參考文獻:
[1] 劉佳明.引入財務狀態分析的上市公司財務危機預測方法研究 [D].哈爾濱:哈爾濱工業大學,2018.
[2] 蘇金樹,張博鋒,徐昕.基于機器學習的文本分類技術研究進展 [J].軟件學報,2006(9):1848-1859.
[3] QU Z,SONG X,ZHENG S,et al. Improved Bayes Method Based on TF-IDF Feature and Grade Factor Feature for Chinese Information Classification [C]// 2018 IEEE International Conference on Big Data and Smart Computing (BigComp),2018:677-680.
[4] KIM Y,PARK H,SHIM K,et al. Efficient processing of substring match queries with inverted variable-length gram indexes [J]. Information Sciences,2013,244:119-141.
[5] YANG Y,JIANG G P.Improved Method of Computer Virus Signature Automatic Extraction Basedon N-Gram [J]. Computer Science,2017,44(S2):338-341(in Chinese).
[6] 萬卓昊,徐冬冬,梁生,等.基于N-Gram的SQL注入檢測研究 [J].計算機科學,2019,46(7):108-113.
[7] WANG H T,HE J,ZHANG X H,et al. A Short Text Classification Method Based on N-Gram and CNN [J]. Chinese Journal of Electronics,2020,29(2):248-254.
[8] CHEN K W,ZHANG Z P,LONG J,et al. Turning from TF-IDF to TF-IGM for term weighting in text classification [J]. Expert Systems With Applications,2016,66:245-260.
[9] 許甜華,吳明禮.一種基于TF-IDF的樸素貝葉斯算法改進 [J].計算機技術與發展,2020,30(2):75-79.
[10] 葉雪梅,毛雪岷,夏錦春,等.文本分類TF-IDF算法的改進研究 [J].計算機工程與應用,2019,55(2):104-109+161.
[11] 董蕊芳,柳長安,楊國田.一種基于改進TF-IDF的SLAM回環檢測算法 [J].東南大學學報(自然科學版),2019,49(2):251-258.
[12] 但唐朋,許天成,張姝涵.基于改進TF-IDF特征的中文文本分類系統 [J].計算機與數字工程,2020,48(3):556-560.
[13] LIU P,ZHAO H H,TENG J Y,et al. Parallel naive Bayes algorithm for large-scale Chinese text classification based on spark [J].Journal of Central South University,2019,26(1):1-12.
作者簡介:孫德華(1994—),男,漢族,河南周口人,碩士研究生在讀,研究方向:自然語言處理。
猜你喜歡
現代企業(2021年2期)2021-07-20 07:57:18
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
現代經濟信息(2020年34期)2020-06-08 06:02:40
制造技術與機床(2019年10期)2019-10-26 02:48:08
意林·全彩Color(2019年9期)2019-10-17 02:25:48
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
河南水利年鑒(2017年0期)2017-05-19 02:29:27
