基于實例分割的雙目特征點匹配目標識別和定位研究
2020-03-04 03:40:22李山坤陳立偉
無線電工程 2020年2期
李山坤,陳立偉,李 爽
(1.哈爾濱工程大學 信息與通信工程學院,黑龍江 哈爾濱 150001;2.衛星導航系統與裝備技術國家重點實驗室,河北 石家莊050081)
0 引言
近年來,隨著科學技術的迅猛發展,圖像作為現實生活中容易獲取、包含豐富信息的一種數據,對圖像信息的處理已經成為信息科學的一個重要研究領域。
雙目視覺作為機器視覺的一個重要分支,具有效率高、精度合適、系統結構簡單和成本低等優點,在虛擬現實、機器人導航及非接觸式測量等許多方向均極具應用價值[1]。利用雙目視覺來實現特定目標測距也已經成為了一個重要研究方向。WANG[2]等人提出了基于YOLO的雙目特征點匹配和目標識別定位研究方法,他們首先通過YOLO進行目標檢測和識別,并針對相同物體利用加速穩健特征匹配算法(SURF)特征點進行匹配,并且針對物體紋理少,不能實現有效定位的問題,提出了多特征點融合算法,將Canny邊緣檢測算法和FAST角點算進行結合,使得物體可以檢測目標的邊緣信息,從而提高紋理少物體的匹配點的數量。然而,由于YOLO檢測網絡屬于目標檢測模型,并且提取信息是基于邊框內部的物體特征,會提取到與目標無關的特征點,從而影響定位精度。
為解決這樣的問題,本文引入了Mask R-CNN(Mask Region with Convolution Neural Network Feature)網絡模型[3],并通過SURF來實現雙目視覺的物體識別和定位。Mask R-CNN是完成對圖像的將目標檢測與分割并行計算的神經網絡模型,該檢測網絡能夠快速確定圖像中的目標位置,經網絡訓練選取出區域建議框,在此基礎上進行像素級別的分割,具有較高的檢測性能。實驗結果證明,應用結合相較于單獨的目標檢測任務效果更好。
1 系統流程
雙目視覺定位系統流程如圖1所示。
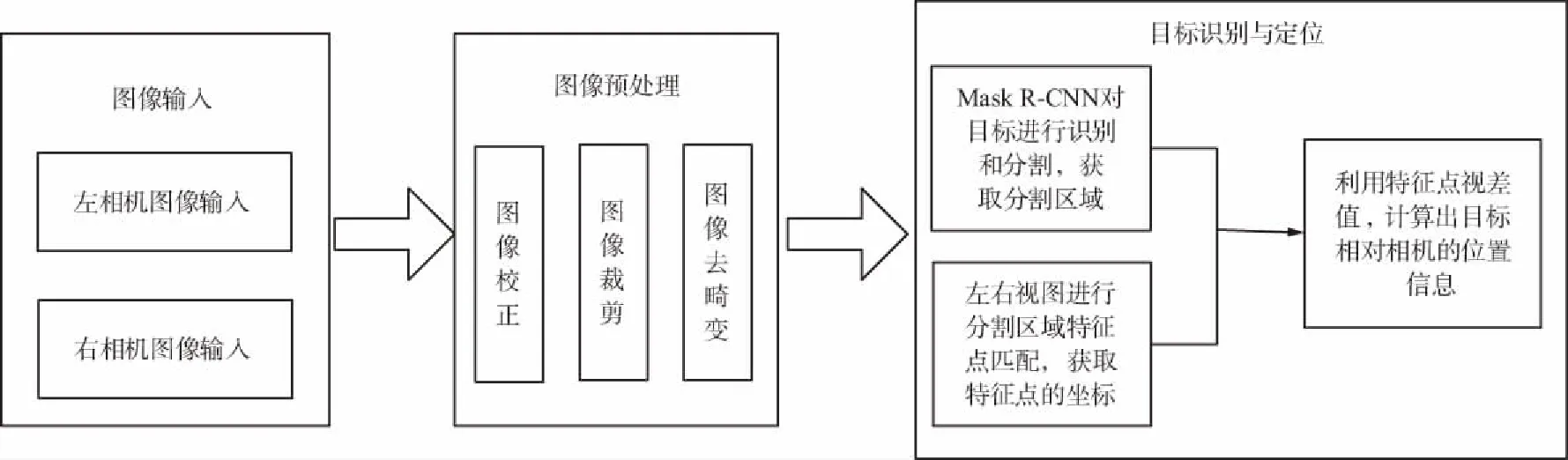
圖1 Mask R-CNN雙目視覺定位系統流程Fig.1 Mask R-CNN binocular vision positioning system
基于Mask R-CNN的雙目神經網絡與雙目視覺物體識別與定位的系統實現,通過雙目相機采集雙目左右圖像,并且利用Matlab工具包對相機進行標定,獲取相機內參和外參,然后根據獲取的參數對圖像去畸變和極線校正。以左相機圖像為參考進行分割,然后利用SURF算法進行特征點匹配[4],根據特征點的視差值計算出物體相對相機的位置。但在對相機標定的過程中,受到相機標定精度、圖像去畸變和極線校正精度的影響,在遠距離情況下,計算距離會出現明顯偏差,為此采用最小二乘法對相機參數和位置信息進行擬合校正,提高定位精度。
2 Mask R-CNN
2.1 網絡架構
Mask R-CNN是REN等人在Faster R-CNN[5]基礎上進行完善的深度神經網絡模型,在對圖像物體識別和分割任務上具有重大的開創性意義。該網絡模型主要由5部分組成:特征提取網絡、特征組合網絡[6]、區域建議網絡(Region Proposal Network,RPN)、感興趣區域對齊操作(RoIAlign)和全連接網絡(FCN)[7-8]。
Mask R-CNN繼承了Faster R-CNN的網絡結構,在Faster R-CNN網絡架構的基礎上進行了改進,采用了深度卷積神經網絡進行圖像底層特征提取得到特征映射,由區域建議網絡計算得到感興趣區域(RoI),并且使用ROIAlign替代了感興趣池化操作(RoIPool),取消了量化操作,解決了輸入輸出像素不對齊的問題,并采用雙線性插值的方法獲得確定位置的像素,輸出固定尺寸的特征圖,在輸出特征圖后面連接全連接網絡層進行分類和檢測回歸,另一分支連接FCN進行圖像像素級別的語義分割,由此,實現了對圖像的檢測和分割,即實現了實例分割。Mask R-CNN網絡流程如圖2所示。
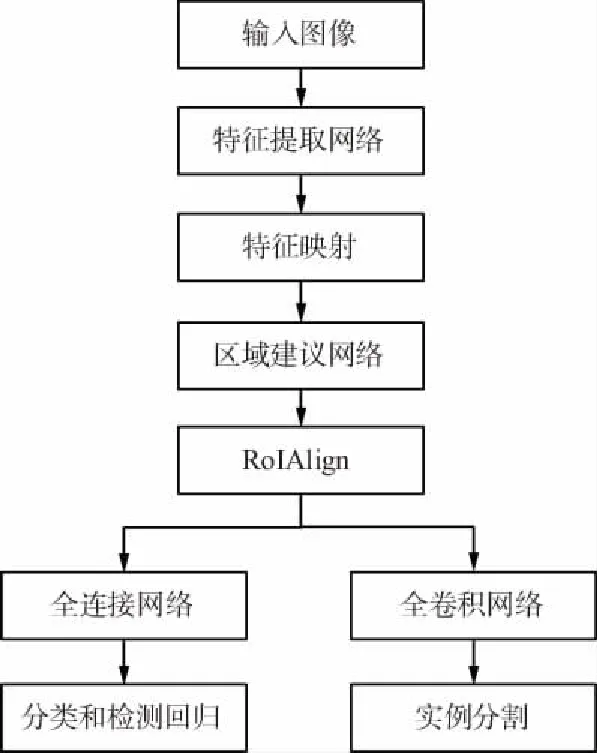
圖2 Mask R-CNN網絡流程Fig.2 Mask R-CNN network flow chart
2.2 RPN
RPN的產生需要在卷積的特征圖上進行網格滑動,利用n*n的網格框與輸入的卷積特征映射圖進行全連接,將滑動窗口映射到低維的向量,通常映射的維度為256維或512維。利用2個全連接層分別對該向量進行分類和邊框回歸,為使輸入圖像的有效區域達到最大值,將n值設為3,將網絡結構在圖中表示出來,在全連接層中,為實現空間位置的權值共享,采用了滑動窗口的方式進行計算。該結構是由一個n*n的卷積層進行卷積變換,然后再由2個1*1的滑動卷積層進行處理。區域推薦網絡結構如圖3所示。
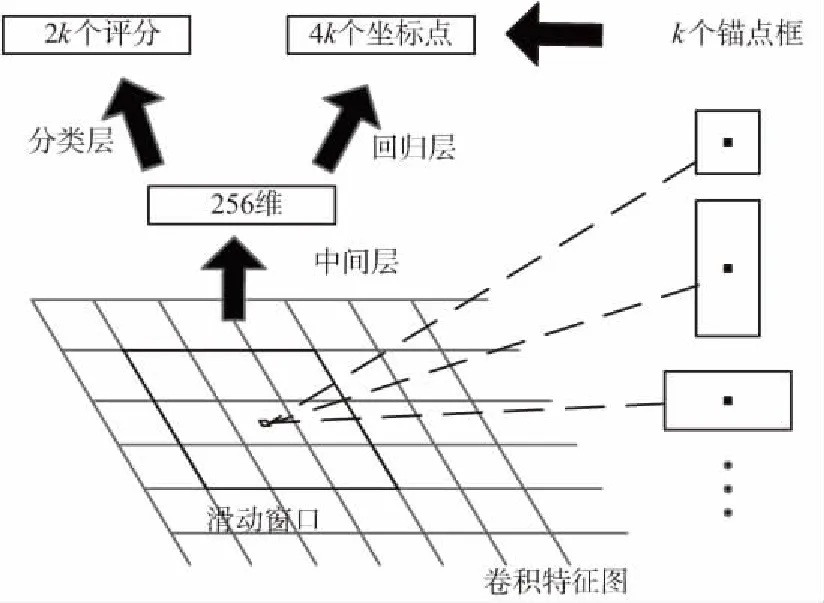
圖3 區域推薦網絡結構Fig.3 Region proposal network structure
在每個滑動窗口的位置上,可以同時預測k個推薦區域,區域回歸層會產生k個框的4k個坐標編碼。分類層會針對每個推薦區域統計的目標概率輸出2k個評分。這些被參數化后的參考框點成為錨點。每個錨點都集中在識別問題的滑動窗口中間。通常使用3個尺度和3個長寬比。使用該方法的主要原因是在計算錨和其相關的函數時都具有平移不變形。這樣可以保證在對圖像預測時,當目標位置發生了變化時,推薦目標也隨之發生變化,函數可以計算出任意位置的推薦目標區域。
最小化Fast R-CNN[9]的多任務損失函數,對于一張圖片的損失函數定義為:
(1)

2.3 RoIAlign
在Faster R-CNN的檢測網絡中,分支RoIpool對生成的每個RoI提取小特征的映射。RoIPool首先將浮點數RoI量化為特征映射的離散粒度,然后將量化的RoI細分為自身量化的空間區間,最后聚合每個區間覆蓋的特征值,在量化過程中將浮點數量化為整數,這樣直接舍棄小數部分輸出像素值就會導致像素偏差,被稱為“不匹配問題”[10]。但是對于語義分割來說,對預測各個物體精確的像素掩碼有較大影響,為了解決這個問題,便引入了RoIAlign層。
RoIAlign 從RoIpool的局限性源頭出發,取消了對RoI邊界和區間的嚴格量化操作,采用雙線性插值[9]的方法獲得坐標為浮點數的像素點上的圖像數值,從而將整個特征聚集過程轉化為一個連續的操作,這樣可以保證提取到的特征與輸入是相互對齊的。RoIAlign原理如圖4所示。
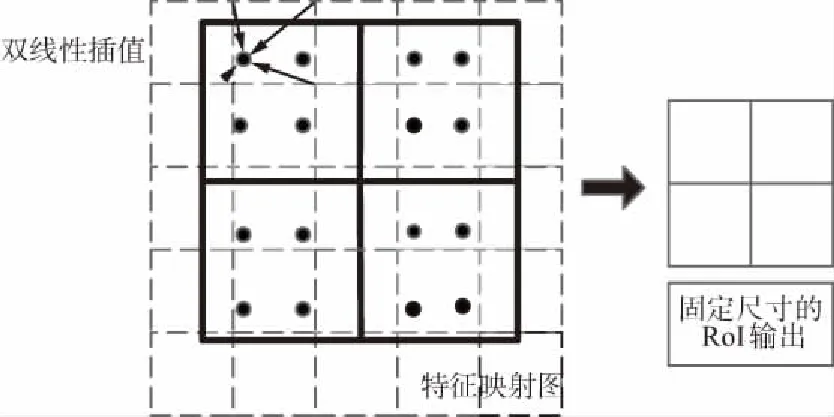
圖4 RoIAlign原理Fig.4 Schematic diagram of RoIAlign
圖4中,底部的虛線網格表示提取到的特征映射圖,黑色線框表示ROI區域,區域大小為2×2,包含4個單元,在實驗過程中,采樣點設置為4會得到最佳結果。因此在每個單元中設置4個采樣點,將每個單元劃分為4個子單元,并且計算每個子單元中心點的像素值對應的概率值,但是該像素點大概率會是一個浮點數,但在圖像上的浮點是沒有像素值的,這個值由相鄰最近的整數像素點通過雙線性插值計算得到。然后進行最大池化或者均值池化操作得到固定維度的輸出。
2.4 損失函數
整個網絡任務包括識別[11]、檢測和分割3個分支,因此損失函數包含分類誤差、檢測誤差和分割誤差,即:
L=Lcls+Lbox+Ls,
(2)
式中,Lcls,Lbox分別表示分類損失和回歸損失,利用全連接預測出每個RoI的所屬類別及其矩形框在圖中的坐標位置。分割分支采用FCN對每個RoI有k×n×n(n表示RoIAlign特征圖的大小,k表示類別數)維度的輸出,對每一個像素應用sigmoid函數進行分類,然后取RoI上所有像素的交叉熵的平均值作為Ls[12]。
3 SURF算法
SURF算法是以尺度不變特征轉換(SIFT)算法為基礎提出的一種快速魯棒性特征提取的配準算法。該算法不僅對圖像旋轉、縮放具有極強的適應性,而且圖像在光照變化、視角變化和噪聲的情況下也具有一定程度的穩定性能[13]。
3.1 特征點檢測
SURF算法對特征點檢測基于Hessian矩陣,圖像上的每一個像素點都采用Hessian矩陣進行計算,對于給定積分圖像上的一點f(x,y)在點f處[14],尺度為σ的Hessian矩陣H(x,σ)的函數表達式為:
(3)
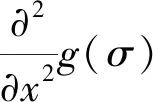
構建尺度空間的過程為在圖像上下采樣,然后將其與各尺度的二維高斯函數進行卷積操作。在進行卷積時,SURF算法使用盒子濾波器代替二階高斯濾波,大大提高了卷積計算速度[15],從而降低了算法的運行時間,簡化后的Hessian矩陣行列式為:
Δ(H)=Dxx*Dyy-(0.9*Dxy)2,
(4)
式中,Δ(H)為點I(x,y)周圍鄰域的盒子濾波器響應值;Dxx,Dxy,Dyy為模板與圖像卷積的結果。特征點的判斷通過比較極值點的鄰域信息進行確定,在一個以某極值點為中心的3*3*3的立方體鄰域內,與相鄰的上下尺度和該尺度周圍的26個鄰域值進行比較,尋找極值點作為最終的特征點。盒子濾波高斯二階微分模板簡化模型如圖5所示。
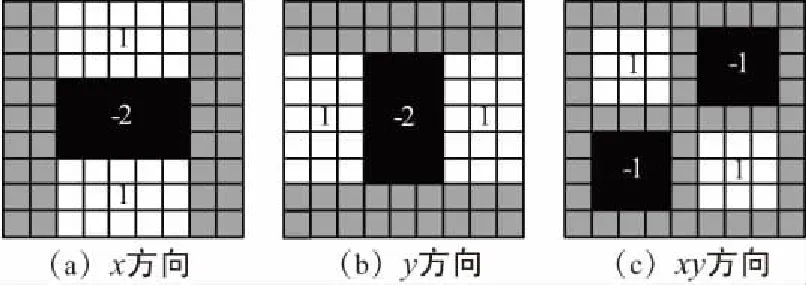
圖5 盒子濾波高斯二階微分模板簡化模型Fig.5 Box-filter Gaussian second-order differential template simplified model
3.2 特征點描述
檢測到特征點之后,以特征點為圓心,6σ為半徑的區域內計算水平方向和垂直方向的加權Haar小波響應,然后采用60°的扇形區域遍歷圓形區域,將由扇形模板內Haar小波在x,y方向響應的累計之和構成一個局部區域矢量,將最大的累加和對應的方向作為該特征點基準方向[16]。
選取基準方向后,以特征點為中心將坐標軸旋轉至基準方向,沿基準方向選取長為20σ*20σ的正方形區域,將該正方形區域劃分為4*4的子區域,每個子區域利用尺寸為2σ*2σ的Haar模板進行響應值計算,進行25次采樣,分別得到沿基準方向的dy和垂直于基準方向的dx,統計每個子區域響應值,得到V=(∑dx,∑dy,∑|dx|,∑|dy|)特征矢量,即該子區域的描述符。所有子區域的向量構成該點的特征向量,得到維度為4*4*4=64維的特征向量。特征描述符的生成過程如圖6所示。
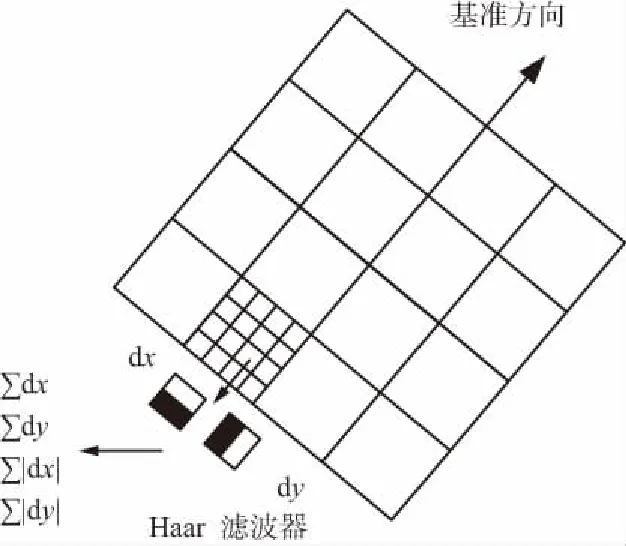
圖6 特征描述符的生成過程Fig.6 Feature descriptor generation process
4 雙目視覺成像模型
同一場景下,由于目標遠近原因會使同一物體在2張圖像上的成像位置有所不同,這也就構成了物體的視差,利用視差可以計算出相機相對于相機模型的位置信息。雙目相機經過標定之后,可以得到相機參數,經過圖像校正和極線約束后,左右視圖在同一平面上[17-18]。雙目視圖測距原理如圖7所示。
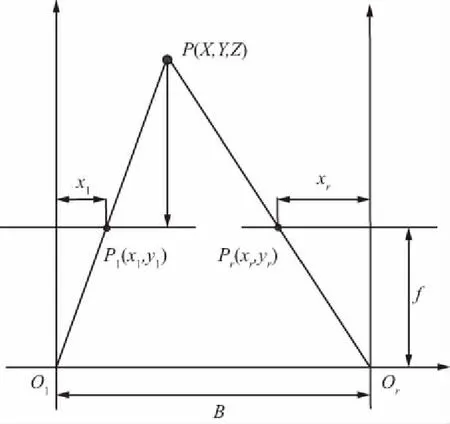
圖7 雙目視覺模型Fig.7 Binocular vision model
圖7中,Ol,Or為兩相機坐標系的原點,基線的距離為B,兩相機在同一時刻拍攝特征點P(X,Y,Z),點P對應坐標系點的原點在左相機的光心Ol。P點在左相機的像素坐標系為Pl=(xl,yl),在右相機的坐標像素Pr=(xr,yr),視差值d=xl-xr,點P的三維坐標為:
(5)
但是在實際測量的過程,受到相機參數標定及相機硬件等因素的影響,測量值與真實值會存在一定偏差,通過實驗觀察,隨著目標距離相機位置的距離和偏移量增加,誤差會進一步擴大。為此,提出利用獲取到的真實坐標值進行參數擬合,對相機進行二次校正[19],獲取坐標計算模型:
X′=g(x,d)+X,
(6)
提高定位精度。
通過構造代價函數:
(7)
并且利用梯度下降法迭代運算,即尋求代價函數最小的時的參數值:
(8)
5 實驗結果及分析
系統實驗環境為Ubuntu 16.04系統,處理器型號為 Intel i7-7700,顯卡型號為GeForce GTX1070,顯存為8 GB,內存為16 GB,相機型號為STEREOLABS ZED雙目攝像頭,基于Python語言,在PyCharm平臺,Tensorflow,Keras深度學習框架下實現系統整體流程。
5.1 雙目定位實驗
實例分割實驗:目標實例分割結果如圖8所示,圖像中檢測到目標的標簽為‘person’,置信度為1.00,在圖像分割區域進行掩碼操作,填充上顏色。

圖8 實例分割圖Fig.8 Example segmentation diagram
特征點匹配實驗:以左視圖為基準,利用SURF算法提取左視圖內的分割區域的特征點,并利用KNN算法與右視圖進行特征點匹配,剔除部分誤匹配特征點匹配結果如圖9所示。

圖9 SURF特征點匹配圖Fig.9 SURF feature point matching
雙目定位實驗:特征點匹配后計算特征點視差,利用三角測量法計算得到目標相對相機位置。其中,x表示偏移量,z表示目標距離相機的深度值。雙目視差計算結果如圖10所示,目標距離相機2.678 m,偏移相機距離為0.707 m。

圖10 雙目視差計算結果Fig.10 Binocular parallax calculation results
5.2 定位精度實驗
實驗場地大小為4.8 m*4.8 m,由于相機視角的原因,將相機距離測試場景2.4 m,因此測試距離最遠為7.2 m,以80 cm為間隔進行數據采集,在進行數據采集時以左相機為基準,將試驗場地中心線呈現在圖像的中心位置。在每個樣本點位置采集大約100個特征點數。所選取的實驗環境示意如圖11所示。
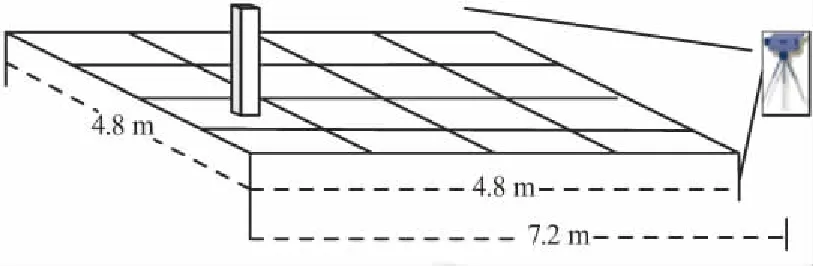
圖11 實驗環境示意Fig.11 Schematic diagram of the experimental environment
圖12表示的是在實驗環境內采集的各個樣本點定位數據的均值。由圖12可以看出,隨著目標距離相機的深度值和偏移距離的逐漸增大,計算出來的位置偏離真實樣本點值的距離也逐漸變大。經過視差擬合處理后的結果如圖13所示。
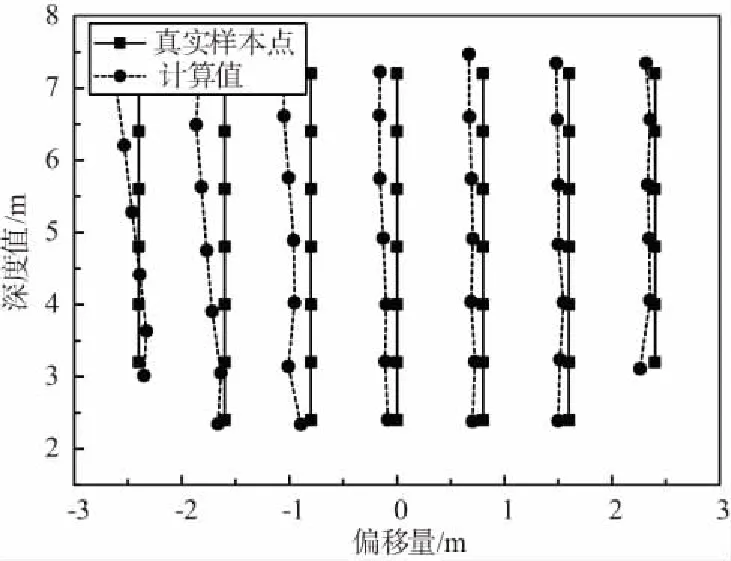
圖12 實驗數據Fig.12 Experimental data
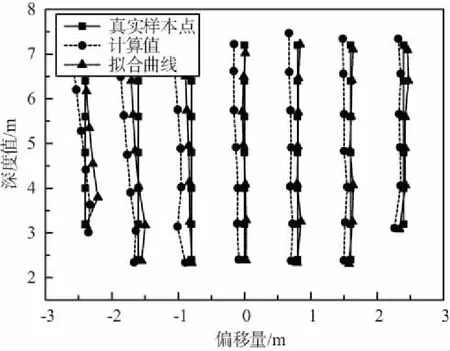
圖13 擬合曲線對比Fig.13 Fitting curve comparison
將擬合后的數值與計算值相比較,無論在深度值方向上還是偏移量方向上,擬合后的計算值與樣本點距離整體比原始計算值更近,尤其是在偏移量方向上,擬合后的曲線總體上與原始樣本點在同一條直線上,表明經過擬合,擬合后的計算值準確度有了顯著提高,將原始計算值、擬合后的值與樣本點值的誤差值分別做成距離誤差圖和誤差分布累計圖進行誤差分析,如圖14和圖15所示。
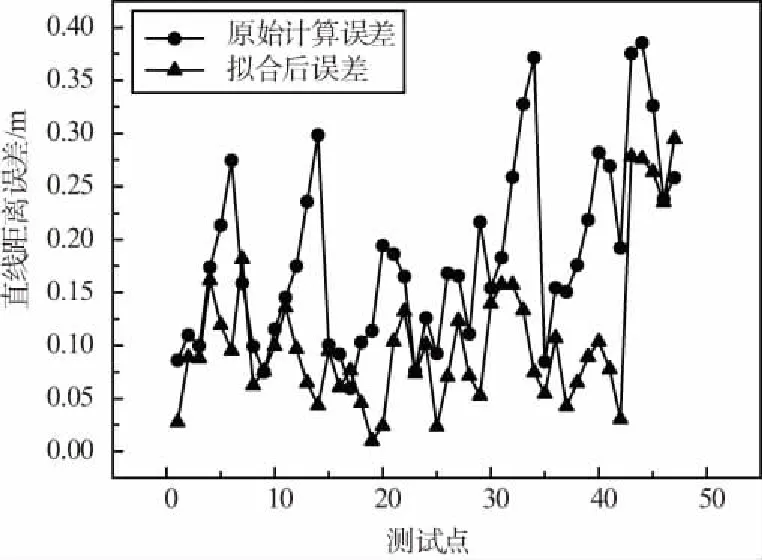
圖14 誤差對比Fig.14 Error contrast
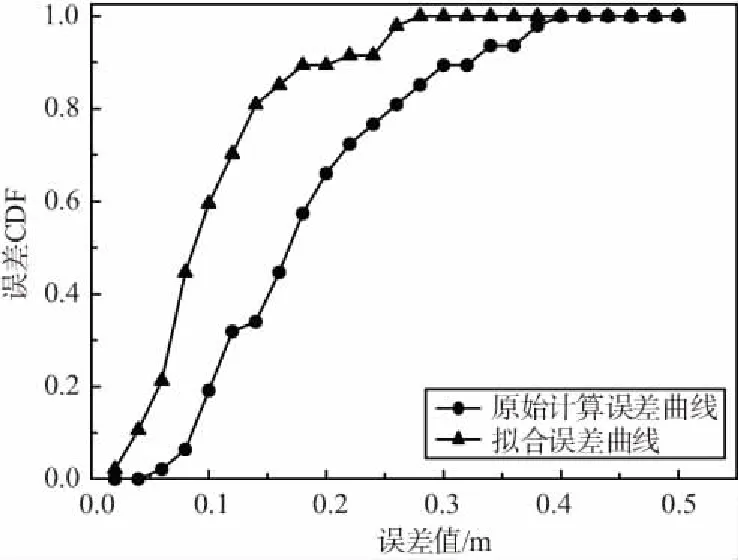
圖15 誤差累計分布曲線Fig.15 Error cumulative distribution curve
由圖14可以看出,擬合后的誤差值與原始誤差值相比,幅度有了明顯降低,誤差分布較為均勻。由圖15可以看出,擬合后的誤差曲線收斂更加快速,表明誤差范圍縮小,最大誤差由0.385 m降低到0.294 m,平均誤差值由0.183 m降低到0.106 m,定位結果有了明顯改善,滿足了精準定位的需求。
6 結束語
針對雙目視覺利用目標檢測方法定位不準確問題,本文采用了Mask R-CNN實例分割網絡,在檢測目標的同時,對目標進行語義分割,提取左右圖像分割區域的物體特征點計算視差值,進一步提高了提取物體特征點的準確性,并針對雙目相機標定后的誤差,對實驗結果和相機參數進行擬合,提高物體定位精度。本文提出的雙目定位系統,在定位精度上滿足了實用性要求。在未來的工作,應該進一步優化網絡,提高物體識別和分割速度,實現更高的計算速度和效率,實現在更多的使用場景中的應用。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
