基于詞干單元的維-哈語文本關鍵詞提取研究*
2020-03-04 08:15:24沙爾旦爾帕爾哈提米吉提阿不里米提艾斯卡爾艾木都拉
計算機工程與科學 2020年1期
沙爾旦爾·帕爾哈提,米吉提·阿不里米提,艾斯卡爾·艾木都拉
(新疆大學信息科學與工程學院,新疆 烏魯木齊 830046)
1 引言
關鍵詞提取是對一組最能概括文本中討論內(nèi)容的詞或術語的自動識別方法[1]。關鍵詞提取在文本挖掘[2]、信息檢索[3]和文本分類[4]等領域具有極其重要的意義。在搜索過程中,關鍵詞被廣泛用于對搜索結果進行分類,幫助用戶快速查找特定數(shù)據(jù)。文本關鍵詞提取任務中的一個重要問題是如何表示文本中的詞語,使計算機能夠有效地讀取最有代表性和起決定性作用的關鍵詞。
維吾爾語和哈薩克語(以下稱維-哈語)是粘著性語言,維-哈語的語法和詞法結構是基本一致的。維-哈語的句子由自然分開的詞組成,詞由詞干追加詞綴來派生,因此維-哈語中詞匯量巨大。其中,詞干是具有實際意義的詞匯單元,詞綴提供語義及語法功能,因而詞素切分和詞干提取能夠使我們獲取有效的、有意義的特征,并減少特征的重復出現(xiàn)率和特征位數(shù),如以下例子所示:
(維語原型)musabiqidA musabiqiniN vaHirqi musabiqA numurini velip,tallanma musabiqidin GAlbilik vOtti.
(維語詞素切分后)musabiqA+dAmusabiqA+niN vaHir+qimusabiqAnumur+i+ni val+ip,talla+an+mamusabiqA+din GAlbA+lik vOt+ty.
(哈語原型)jaresta jaresneN soNGe jares nomeren alep,taNdaw jarestan jENespEn votte.
(哈語詞素切分后)jares+tajares+neN soNGejaresnomer+en al+ep,taNdawjares+tan jENespEn vot+te.
以上句子中文意思是:在比賽中取得比賽的[比賽]終局分數(shù),勝利地通過了選賽。在中文中,中括號[ ]里的‘比賽’這個詞一般不會出現(xiàn),但在維-哈語句子中對應于這個詞的第4個詞musabiqA和jares,是必不可少的。
以上每個維-哈語句子中有10個詞,其中4個詞的詞干(被加粗部分)都是musabiqA(比賽)或jares(比賽),將以上句子經(jīng)過詞素切分和詞干提取后,1個詞干能夠表示4個詞的主要意思,并獲取4個詞特征,特征位數(shù)會大幅減少,如表1所示。

Table 1 Uyghur-Kazakh word variants表1 維-哈詞語變體
維-哈語自然語言處理NLP(Natural Language Processing)的主要問題是資源缺乏和語言形態(tài)結構多變,從互聯(lián)網(wǎng)上收集的數(shù)據(jù)在拼寫和編碼等方面具有噪聲和不確定性等特點[5]。方言以及在拼寫和編碼等方面的不確定性對提取和分類帶噪聲文本數(shù)據(jù)的可靠性帶來了巨大挑戰(zhàn)[6]。然而,提取和分類有噪聲的文本數(shù)據(jù)是維-哈語NLP中不可避免的重要步驟。
以往的維-哈語詞干提取相關的研究大多基于以后綴為基礎的詞干方法和一些人工收集的規(guī)則[7,8],因此存在歧義。維-哈語詞干提取任務中1個特殊的問題是聲音的和諧與不和諧,這個問題導致詞形的變化,這需要通過句子層面的語境分析來解決。基于句子或長上下文的可靠詞干提取方法可以正確預測噪聲文本中的詞干和詞條,有利于維-哈語等少數(shù)民族語言NLP的其他許多方面的研究。基于上述方法的多語言處理工具[6]可以為整個句子提供形態(tài)分析,并減少噪聲文本中的歧義。
常用的關鍵詞提取方法有4種:(1)基于統(tǒng)計的方法,包括詞頻TF(Term Frequency)[9]和詞頻-逆文檔頻率TF-IFD(Term Frequency-Inverse Document Frequency)[10]。TF是統(tǒng)計1個文本中每個詞的出現(xiàn)頻率,把出現(xiàn)頻率高于某個閾值的詞選為關鍵詞。這種方法簡單快捷,但它將所有高頻詞視為關鍵詞,并排除所有低頻詞,這就降低了它的準確率。TF-IDF通過降低出現(xiàn)頻率高但可分類性低的詞語的權重來避免所有高頻詞被選為關鍵詞。因為TF-IDF算法需要考慮整個語料庫來計算給定詞的IDF值,所以語料庫較大時,這種算法才能更正確地提取關鍵詞。(2)基于語義的方法[11]。該方法利用詞之間的語義特征來提取關鍵詞。(3)基于機器學習的方法,包括樸素貝葉斯NB(Naive Bayes)分類器[12]、支持向量機SVM(Support Vector Machine)分類器[13]等。該類方法將關鍵詞提取問題轉化為二元分類問題,即確定候選詞是否為關鍵詞。(4)基于文檔網(wǎng)絡的方法。在這類方法中,將文本映射到以詞語為頂點和以詞語之間的關系為邊的網(wǎng)絡,如TextRank算法[14]。TextRank算法認為1個詞的重要性由與此詞有關的其他詞來投票確定,投票的重要性是由詞的權重來確定。
目前,部分學者對維-哈語文本關鍵詞提取做了一些研究[15 - 17]。文獻[15]用特征加權的方法計算詞的出現(xiàn)頻率,加以考慮詞的位置信息,通過設定特征項權重因子得到詞的最后權重,以此提取維吾爾語文本的關鍵詞。文獻[16]用詞的位置信息、語義相似度以及詞頻等特征來加權的TextRank算法提取維吾爾語文本中的關鍵詞。文獻[17]利用改進的 TF-IDF算法以及詞的位置和出現(xiàn)頻率等信息進行哈薩克語文本關鍵詞提取實驗。
以上研究中用到的關鍵詞提取方法雖然利用了文本中的信息,但是并沒有對文本的表示形式進行改變,其中把詞性和詞頻等特征作為詞語的特征,這樣就忽略了文本上下文詞語之間的語義聯(lián)系,因此這些特征在聚類和分類等過程中不能提供語義有關的充分信息,就導致所提取到的關鍵詞準確率偏低。
本文提出了基于穩(wěn)健的詞素切分及詞干提取和word2vec_TFIDF融合特征表示的維-哈語文本關鍵詞提取方法。首先,用網(wǎng)絡爬蟲技術從政府網(wǎng)站下載維-哈語文本,并用多語言詞素切分工具[6]對其進行詞素切分及詞干提取,以構建詞干序列文本語料庫。然后,用word2vec將語料庫的詞干向量化,并用TF-IDF算法對詞干向量進行加權處理之后,進行了基于詞干的自動關鍵詞提取實驗。
2 提出的關鍵詞提取方法
2.1 實驗文本的處理
跨語言和跨文化交流所引起的書寫形式上的不確定性在給維-哈語文本帶來噪聲的同時,也會導致新詞、新概念和新表達的出現(xiàn)。這些新詞大多是借用新進的外來詞或詞干,以及由于拼寫習慣的不同和方言的變形而引起的噪聲整合而成。引起書寫形式上不確定性的另一個原因是書寫系統(tǒng)的歷史變化。例如,維-哈語目前使用阿拉伯字母,但30年前使用了羅馬字母。在更古老的時代,有更多的書寫形式被使用。這些不同的書寫系統(tǒng)在現(xiàn)代社會留下了它們的遺產(chǎn),雖然不太可能在官方媒體上出現(xiàn),卻廣泛存在于網(wǎng)上論壇和聊天工具中。
多語言處理工具[6]提供多種預處理功能,它將粘著性語言文字切分成詞和詞素序列。該工具在功能和語言上都是可擴展的。
該工具根據(jù)詞素和語音規(guī)則,從對齊的詞-詞素平行訓練數(shù)據(jù)中自動學習粘著性語言詞語的各種表面形式和聲學變化。詞素邊界上的音素根據(jù)語音和諧規(guī)則改變其表面形式。當發(fā)音準確時,可以在文本中清楚地觀察到語音和諧。該工具基于維-哈語的詞素規(guī)則所準備的詞干、詞綴表、語音和諧與不和諧等語音規(guī)則的搜索算法,通過匹配方法依次切分候選詞,并根據(jù)切分結果分別與詞干、詞綴表和維-哈語詞的各種表面形式進行匹配,來導出每個候選詞的所有可能的詞素切分形式。將這些詞素送入1個獨立的統(tǒng)計模型,從前N個最好的詞素中選擇最佳詞素。該工具為詞干提取提供了可靠的依據(jù),極大地改進了少數(shù)民族語言文本處理效果,詞素切分流程如圖1所示。
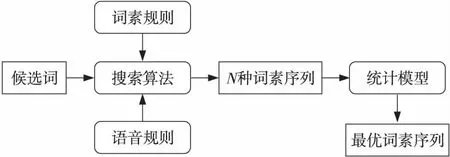
Figure 1 Morpheme segmentation process圖1 詞素切分流程
本文用該工具在包括10 025個維吾爾語句子和5 000個哈薩克語句子的詞-詞素平行訓練語料庫上訓練統(tǒng)計模型,選擇其中80%的句子作為訓練語料,其余部分作為測試語料,進行詞素切分和詞干提取實驗,其詞干提取準確率最高分別達到97.66%和95.87%,所有自動切分的詞素與人工切分的詞素完全匹配的百分比如表2所示。
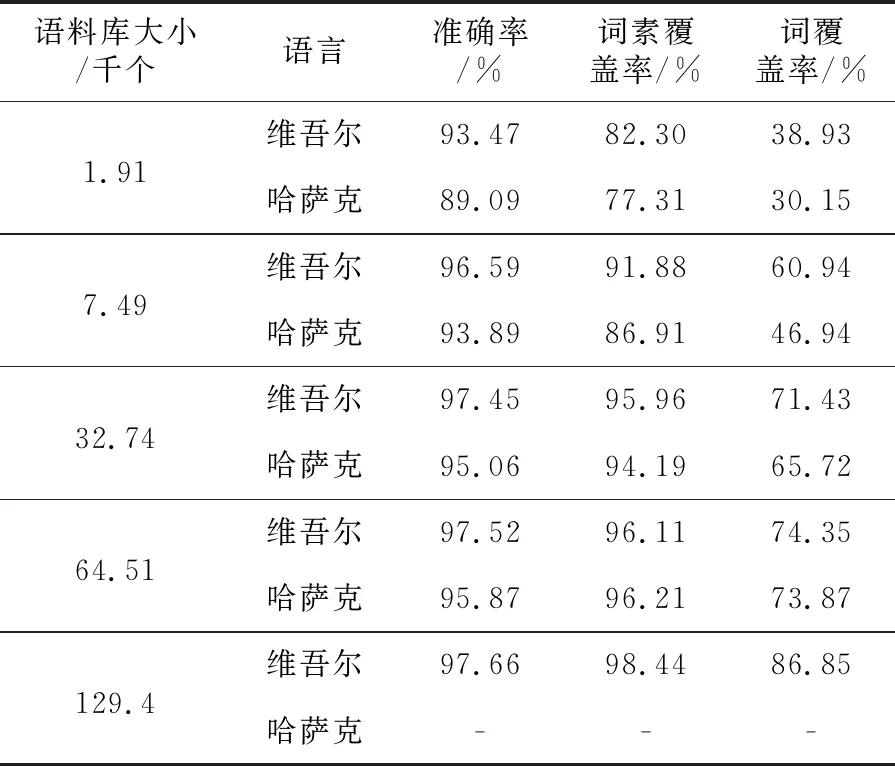
Table 2 Morpheme segmentation based on rule表2 基于規(guī)則的詞素切分
2.2 基于word2vec_TFIDF的文本表示
近期,深度神經(jīng)網(wǎng)絡和表示學習[18,19]提供了更好的文本表示和緩解數(shù)據(jù)稀疏問題的方法。Mikolov等人[20]提出了word2vec文本表示方法,并利用深度學習和向量運算的思想,通過訓練把文本內(nèi)容的處理簡化到Q維向量空間,以尋求文本數(shù)據(jù)更深層次的特征表示,并使用向量空間中的相似度來表示文本的語義相似度。
2.2.1 詞向量學習方法
詞(詞干)向量是1個真數(shù)向量[21],利用word2vec可以快速有效地訓練詞干向量。通過計算任意2個給定的詞干向量之間的距離,可以容易地找到它們的相似度。word2vec包括2個重要的子模型:連續(xù)詞袋CBOW(Continues Bag Of Words)模型[22]和Skip-gram模型[23]。
CBOW是1個在給定上下文詞干Wt-c,W(t-c)-1,…,Wt-1,Wt+1,Wt+2,…,Wt+c的條件下預測特定詞干Wt發(fā)生的概率P(Wt|Wt-c,W(t-c)-1,…,Wt-1,Wt+1,Wt+2,…,Wt+c)的模型。在這個模型中,1個詞干由在這個詞干前后的c個詞干表示,c是預選窗口的大小,輸出是這個特征詞干Wt的詞干向量,如圖2所示。本文使用CBOW模型訓練詞干向量。
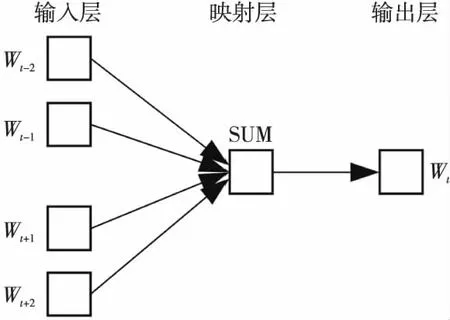
Figure 2 CBOW model圖2 CBOW模型
Skip-gram模型的思想與CBOW模型相反,它在給定特定詞干Wt的條件下,預測上下文詞干Wt-c,W(t-c)-1,…,Wt-1,Wt+1,Wt+2,…,Wt+c的發(fā)生概率P(Wt-c,W(t-c)-1,…,Wt-1,Wt+1,Wt+2,…,Wt+c|Wt),如圖3所示。
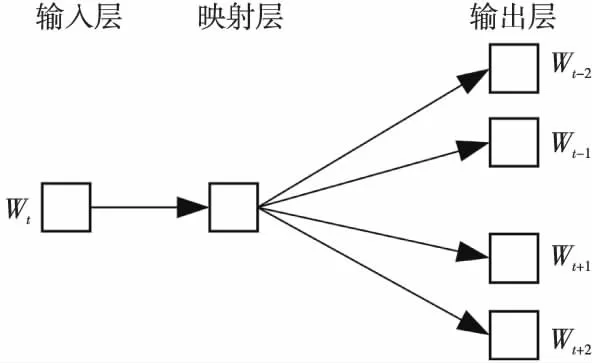
Figure 3 Skip-gram model圖3 Skip-gram模型
通過word2vec訓練得到的詞干向量可以通過其余弦距離來判斷語義相似度。計算得到的余弦值越大,語義越相近;反之,語義相差越遠,如表3所示。
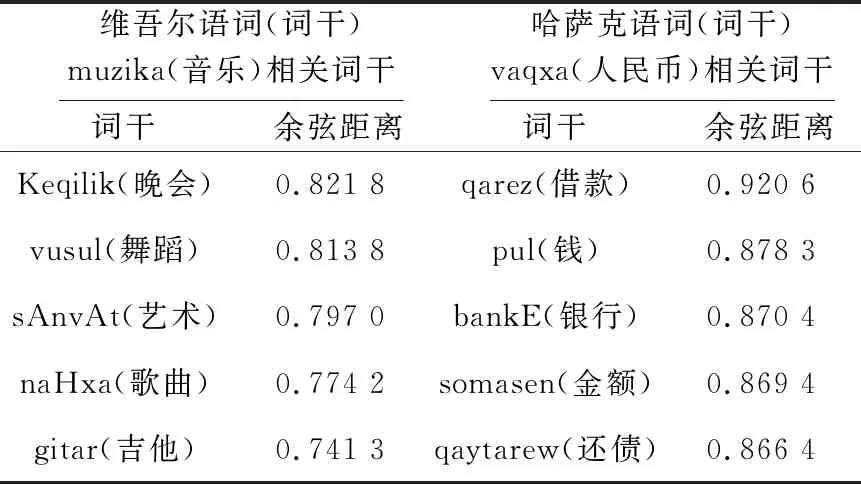
Table 3 Semantic similarity of stem vector 表3 詞干向量語義相似度
從表3可以看出分別輸入維吾爾語詞muzika(音樂)和哈薩克語詞vaqxa(人民幣),并通過計算詞干向量之間的余弦距離來得到的與這2個輸入詞語義最相近的5個詞干。
2.2.2 TF-IDF權重
對于包含M個文本的集合D,其中Di∈D,i=1,2,…,M,通過CBOW模型得到詞干向量。對于文本中的每個詞干,通過TF-IDF算法計算其權重值tfidf(Wt,Di),它是指詞干Wt在文本Di(i=1,2,…,M)中的權重值。TF-IDF考慮單個文本中的詞干頻率tf和整個文本集的詞干頻率idf。TF-IDF的計算公式如式(1)所示:
(1)
其中,tf(Wt,Di)是詞干Wt在第i個文本中的出現(xiàn)頻率,分母是歸一化因子。idf(Wt)是詞干Wt的逆文檔頻率,計算公式如式(2)所示:
idf(Wt)=log(M/nt)
(2)
其中,M是訓練集中的文本總數(shù),nt是詞干Wt在訓練集中的出現(xiàn)次數(shù)。
每個詞干的詞干向量被tfidf值加權來表示1個文本,如式(3)所示:
(3)
其中,vec(Di)指的是每個文本Di的詞干向量,wt表示詞干Wt的N維詞干向量,tfidf(Wt,Di)表示詞干Wt在文本Di中的TF-IDF權重值。
2.3 關鍵詞提取方法
對實驗文本進行處理,通過多語言處理工具[6]進行詞素切分和詞干提取之后,建立詞干序列文本語料庫,并把語料庫分為訓練語料庫和測試語料庫2個部分,為每個文本人工選擇若干個關鍵詞干,并進行標注;然后用word2vec生成所有訓練文本的詞干向量,并用TF-IDF算法計算出每個詞干的權值,以此值加權,生成加權的詞干向量集;然后對測試文本進行向量化和加權,以生成加權的詞干向量集,算出訓練文本集中的每個關鍵詞干向量到待測試文本集中所有詞干向量之間的余弦距離,排序后,選取排在前面的K個關鍵詞干作為最終提取的關鍵詞。
3 實驗結果及分析
目前,維-哈語文本關鍵詞提取研究還處于起步階段,尚無公開可用的文本語料庫。因此,須通過下載網(wǎng)上文本來構建維-哈語文本語料庫,并用此進行實驗。
3.1 實驗語料庫
本文使用網(wǎng)絡爬蟲技術從官方的維-哈文網(wǎng),如人民網(wǎng)等,下載文本構建文本語料庫。該語料庫包括法律、財經(jīng)、體育、文化、衛(wèi)生、旅游、教育、科技和娛樂等9大類維吾爾文新聞,每類包含500篇,共4 500篇,和包括法律、財經(jīng)、體育、文化、旅游、教育、科技和娛樂等8大類哈薩克文新聞,每類包含500篇,共4 000篇。本文實驗中,從語料庫中隨機選擇維吾爾文新聞和哈薩克文新聞各1 000篇,并使用其中80%的新聞作為訓練集,其余部分作為測試集。
針對互聯(lián)網(wǎng)網(wǎng)頁中的文本易出現(xiàn)拼寫錯誤的情況,本文開發(fā)了維-哈文字拼寫檢查工具。該工具通過分析維-哈語音節(jié)的結構形式和規(guī)則,可以發(fā)現(xiàn)大部分有拼寫錯誤的維-哈語詞匯,從而能夠指導我們更正給定詞匯中的拼寫錯誤。拼寫檢查程序流程如圖4所示。
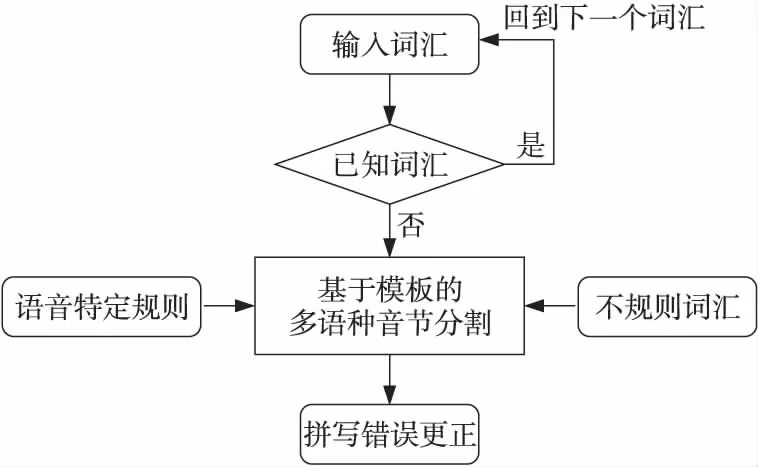
Figure 4 Flowchart of Uyghur-Kazakh spell checking program圖4 維-哈語拼寫檢查程序流程
本文將所有文本從各種編碼形式規(guī)范化成統(tǒng)一的羅馬字母編碼形式,并送入詞素切分工具包,轉換成詞素序列,提取其詞干。基于詞素和語音規(guī)則的詞干提取方法能夠很好地降低待選擇關鍵詞干的維數(shù),其中,除去詞綴和停用詞后(停用詞數(shù)為1 085),詞干詞匯的數(shù)量顯著地下降到詞詞匯數(shù)量的30%以下,如表4所示。
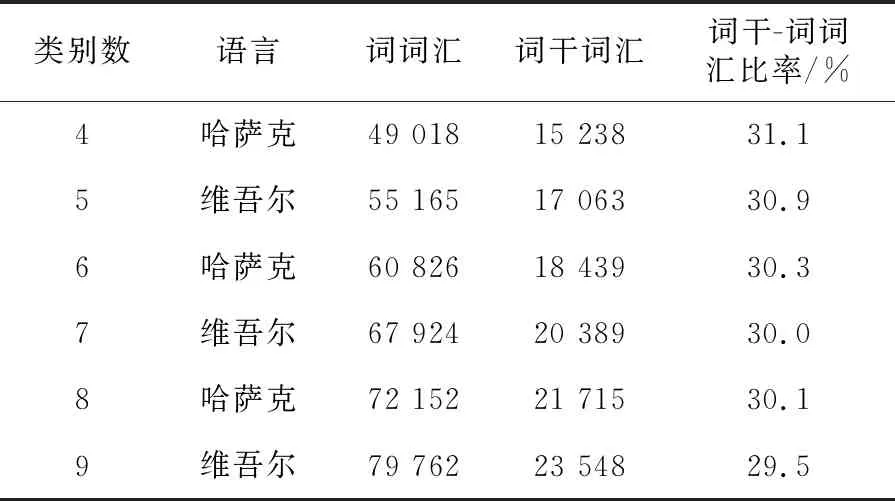
Table 4 Reduction in vocabulary number by stem extraction表4 詞干提取引起的詞匯數(shù)量的減少
在穩(wěn)健的詞素切分和詞干提取之后,用基于Hierarchical Softmax 算法的CBOW模型訓練所有語料庫的詞干向量。在訓練時,向量的維度設置為100,訓練窗口設置為5,學習速率設置為0.025。取得詞干向量之后,用TF-IDF算法分別對所取得的詞干向量集進行加權。
3.2 實驗結果及分析
本文使用準確率P、召回率R和F1評分對本文方法性能進行評價。其中準確率P、召回率R和F1評分計算公式如下所示:
P=正確提取關鍵詞個數(shù)/全部提取關鍵詞數(shù)
R=正確提取關鍵詞個數(shù)/人工標注的關鍵詞個數(shù)
F1=2×P×R/(P+R)
為了驗證本文方法關鍵詞提取性能,將本文方法與TF、TF-IDF[18]和TextRank[17]等方法進行對比。本實驗中為每篇文本人工標注3個關鍵詞干,然后用本文提出的方法為測試集的每篇文本分別選擇訓練集中已標注關鍵詞干的詞干向量與測試集中詞干向量之間余弦距離最大的3個、4個和5個詞干作為方法提取的關鍵詞,對比實驗結果如表5~表7所示。
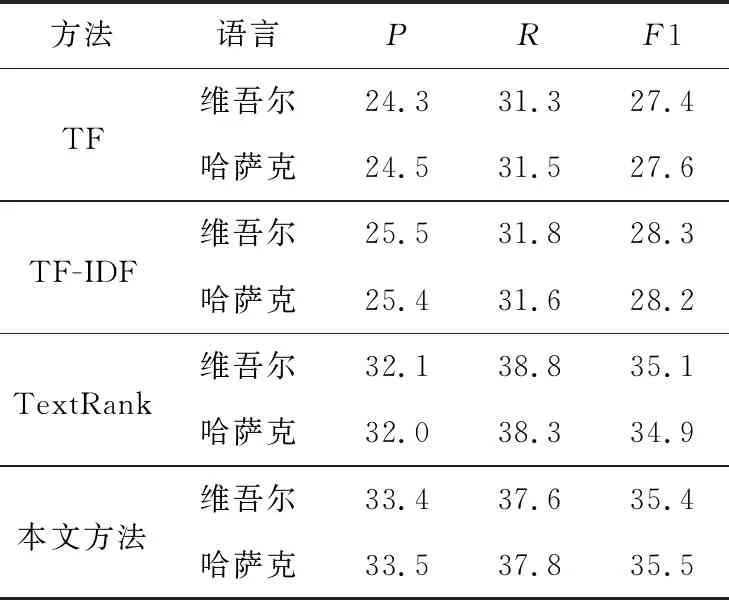
Table 5 Results comparison of extracting three keywords表5 提取3個關鍵詞的結果比較 %
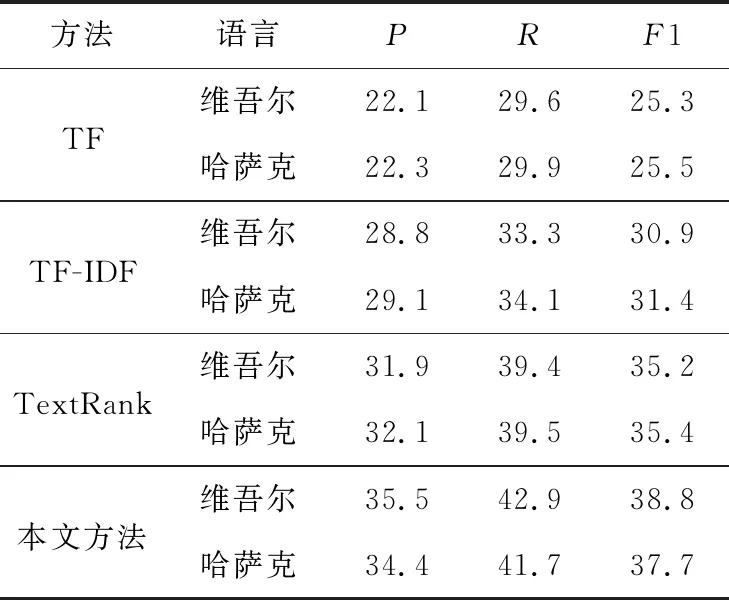
Table 6 Results comparison of extracting four keywords表6 提取4個關鍵詞的結果比較 %
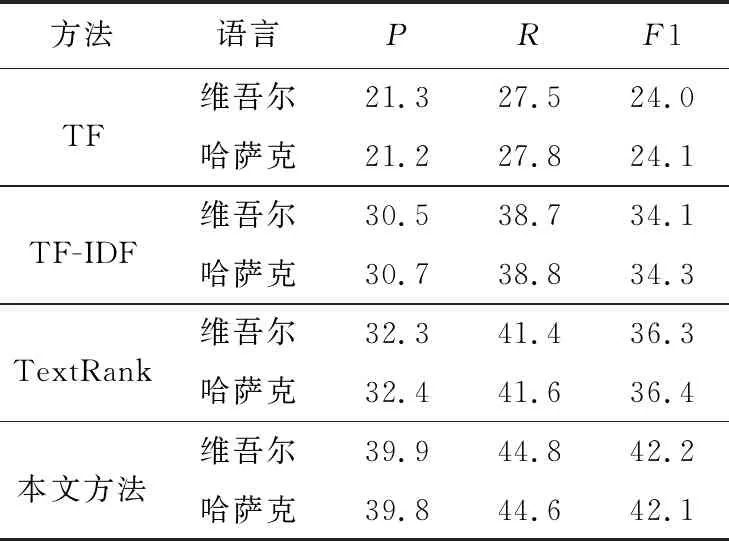
Table 7 Results comparison of extracting five keywords表7 提取5個關鍵詞的結果比較 %
從表5~表7可以看出,基于本文提出的word2vec_TFIDF融合特征表示的方法的準確率隨著被提取關鍵詞數(shù)的增加而逐漸提高,在關鍵詞數(shù)為5時,召回率和F1值分別達到44%和42%以上。傳統(tǒng)的TF算法的準確率隨著關鍵詞數(shù)的增加而下降;傳統(tǒng)的TF-IDF算法在關鍵詞數(shù)增加時準確率逐步提升,但是提取效果比較一般,準確率比本文方法低約8%;TextRank方法的準確率比較穩(wěn)定,但是比本文方法低,并且關鍵詞數(shù)增加時,本文方法與TextRank方法準確率之間的差值逐步增加。
本文為了驗證詞干單元在粘著性語言關鍵詞提取任務中的優(yōu)越性,用本文提出的融合體征表示方法對原始文本中的詞特征進行表示,同時對原始文本進行詞素切分和詞干提取,然后再用此方法表示文本中的詞干特征,以此分別進行基于詞和詞干單元的關鍵詞提取實驗,并對實驗結果進行了對比,結果如表8所示。
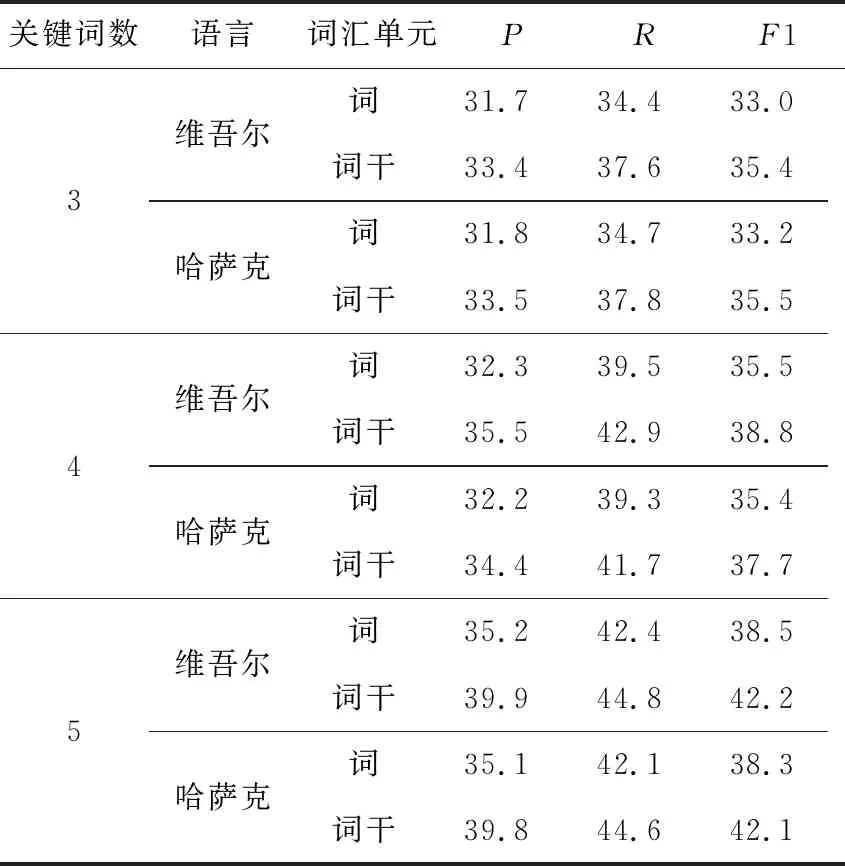
Table 8 Comparison of extraction results based on word and stem units表8 基于詞與詞干單元的提取結果比較 %
從表8可以看出,隨著關鍵詞數(shù)的增加,基于詞與詞干單元的準確率,召回率和F1值都開始增加,這就證明詞與詞干向量數(shù)增加時,能夠參加距離計算的矩陣參數(shù)就越多,也就能更準確地找到相似度更接近的關鍵詞;在所有的關鍵詞數(shù)水平上,基于詞干單元的準確率都比基于詞單元的大。隨著關鍵詞數(shù)的增加,本文方法基于詞干單元提取關鍵詞的準確率與基于詞單元的準確率的差值開始增大,當關鍵詞數(shù)為5時,本文方法基于詞干單元提取關鍵詞的準確率和F1值比基于詞單元的準確率和F1值高出約4%。由此可見,對于維-哈語等粘著性派生語言而言,詞干單元在關鍵詞提取任務中比詞等其他詞匯單元有著更優(yōu)異的效果,能夠提高關鍵詞提取的準確率。
4 結束語
關鍵詞提取是從海量數(shù)據(jù)中快速取得用戶需要信息的重要手段之一。維-哈語是一種形態(tài)豐富的粘著性語言,詞是由多個后綴所附的詞干構成,因此,維-哈語的詞匯量巨大,后綴提供語義和語法功能。因此,詞干提取和形態(tài)分析是關鍵詞提取的有效途徑。谷歌開發(fā)的word2vec詞向量技術可以將語言單元映射成基于上下文的順序向量空間。本文討論了一種基于詞-詞素平行訓練數(shù)據(jù)的穩(wěn)健詞素切分及詞干提取方法,以及一種基于word2vec和TF-IDF融合特征表示的維-哈語文本關鍵詞提取方法。本文分別用不同的關鍵詞提取方法和不同的詞匯單元進行維-哈語文本關鍵詞提取實驗。本文提出的基于詞干單元和word2vec_TFIDF融合特征表示方法,相較其他方法,能更有效地提高維-哈語等粘著性語言文本關鍵詞提取的性能。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
