一種可重構以太網數據包解析器中可重構單元的設計*
2020-03-04 08:20:48殷樹娟李翔宇
計算機工程與科學 2020年2期
關鍵詞:指令
趙 宇,殷樹娟,李翔宇
(1.北京信息科技大學理學院,北京 100192;2.清華大學微電子學研究所,北京 100084)
1 引言
近年來互聯網產業迅猛發展,各種新型網絡技術層出不窮,隨著網絡體系的不斷膨脹及特殊服務種類的增加,出現了大量的新型協議,如MPLS(Multi-Protocol Label Switching)、GRE(Generic Routing Encapsulation)、IP-in-IP等。為了適應新的網絡業務需求,運營商不得不快速更新網絡中轉設備,但是更新硬件開發周期較長且部署成本較高,問題隨之而來。
交換機作為網絡中不同設備之間數據交互的中轉機制,是設備之間的鏈路樞紐。如果能夠提高網絡中轉發設備(交換機)的性能,尤其是通用性和靈活性,使其能夠在不重新部署的情況下隨著網絡體系升級,這將對解決上述問題有極大的幫助。
交換機在工作時,第1步是實現數據包的解析,而傳統網絡數據包包頭的報文序列通常是具有固定格式的。但是,現代網絡中,如前文所述,交換機需要處理的報文格式更加豐富,而且可能需要處理用戶自定義的未知協議報文,因此需要實現更加靈活通用的數據包解析器來滿足現代網絡中不同業務的需求,在不降低解析速度的情況下可支持新的協議加入。
在這之前相關研究人員已經做出了大量努力,如CPHP(Configurable Parser for Heterogeneous Protocols)[1]和RDFE(Reconfigurable Dataplane for network Function Evolution)[2]設計通過引入可配置用戶定制模塊和配套的解析樹映射算法,將用戶定制的協議映射到硬件結構中,從而實現異構協議的解析。但是,這2個設計在解析較長的數據包包頭時解析路徑相對較長,其相應消耗的解析時鐘周期較多,解析速度會明顯下降。CAFE(Configurable pAcket Forwarding Engine)[3]和SwitchBlade[4]設計是通過一種任意比特提取器來實現包頭解析時包頭中的任意比特域的提取或組合,這種設計思想僅初步實現了用戶自定義匹配域抽取模式,沒有解決關鍵字匹配和解析動作的可編程性問題。Kozanitis等人[5]提出了Kangaroo結構,通過可編程的協議樹預測解析,實現多個數據包的同時處理,其解析能力可以達到40 Gbps。但是,它利用TCAM(Ternary Content Addressable Memory)來實現對數據包中預定義偏移的預測性提取,其數據包存儲在內存系統中,提取指令每次都要從中取出相應的字段,這樣其處理協議的預測跨度將受限于可從內存子系統中提取字段的多少。DrawerPipe模型[6]將網絡功能抽象為5個標準的“抽屜”,不同的“抽屜”根據需要裝載不同的處理模塊,通過組合處理模塊實現各種網絡功能。這一模型目前僅能實現對數據中心網絡中各種數據進行不同功能的分組處理,還沒有用于數據交換的實例。劉中金等人[7]提出了EPC(Elastic Protocol Customization)結構及其對應的映射算法,其核心思想是通過偏移量信息來提取匹配域,但僅支持4個匹配域的提取,故無法滿足實際應用的需求。王永娜等人[8]使用XML語言描述可擴展協議報文的方法,以簡單協議解析為基礎,將解析器功能模塊化,從而設計出異構協議動態解析器模型,但是其目前只適用于工業控制網絡。Bosshart等人[9]提出了基于 TCAM 的可編程解析器架構,同時在解析模塊中引入 RAM 存儲匹配域的偏移量,從而實現匹配域的用戶自定義。為實現解析器的快速設計,Benacek等人[10]和Attig等人[11]分別將高級數據包處理語言 P4(Programming Protocol-independent Packet Processors)和PP(Packet Parsing)映射到FPGA中,實現了數據包解析器的快速生成,但是在每次處理協議變化時還要重新編譯生成新的解析器的FPGA配置文件,FPGA作為一種通用的細粒度可重配置芯片,其實現效率相對較低,所實現的解析器性能受到了限制。
基于以上討論,本文提出了一種可以通過靜態配置實現不同解析邏輯(包括用戶自定義的未知協議)的以太網交換機數據包解析器基本處理單元PE(Process Element),這種PE可以被用于任何一層協議的解析,配置文件由編譯器根據協議幀格式生成,通過流水線式級聯能夠搭建支持各種協議(包括自定義的未知協議)集合的可重構數據包解析器。由于它是面向包解析器這一特定硬件類型設計的定制可重構結構,實現效率高于通用的FPGA,配置文件規模也得到大大壓縮,與已有方案相比,其具有更少的資源占用率、更高的性能和更高的靈活性。
2 數據包解析器的整體架構
在高性能以太網交換機芯片中,目前數據包解析器普遍采用流水線結構,所有輸入的數據包都按照相同的流水線逐級傳遞,中間不能停頓以確保數據在交換機芯片內部不會出現擁塞。包解析的各步操作按照協議封裝層次順序依次排列在流水線中,大多數網絡數據包解析過程都可以看成是多叉樹結構,在每一層針對本層樹節點的對應域進行提取、匹配,從而實現本層協議的解析。因此,每層協議的解析硬件也具有相似性,每級流水線可以采用相同的可重構基本處理單元(PE)來構成,每級PE對應1層包頭(1層協議)的解析,這樣可以簡化硬件設計和配置文件的生成。
本文數據包解析器的設計思想是將包解析中固定的內容,如變化較少的L1協議、checksum等內容采用固定邏輯實現,而將需要具備可編程性的包解析部分用可重構的PE級聯實現。這樣可以最大化系統的實現效率和靈活性,同時因為采用規則的結構(復用PE),又能夠有效降低硬件設計復雜度,滿足設計時間的要求。
本文主要關注PE單元的設計,因此忽略解析器中的固定邏輯部分,這樣的解析器主體部分的整體結構示意圖如圖 1所示,它由多個可重構基本處理單元 (PE)級聯組成。PE之間的數據交換通過幀寄存器(Frame)和中間值寄存器堆IRF(Intermediates Register File)實現。交換機接收到的數據包包頭(PKT_header)會隨著Frame數據通路進行傳輸,首先由前面的預處理邏輯匹配出首層的協議所要提取的關鍵字段的位置及下1層協議類型,并對關鍵字段進行提取存放到IRF中,然后由PE單元對數據包剩下協議進行逐層解析,提取出的關鍵字段及處理結果均存放于IRF寄存器中。
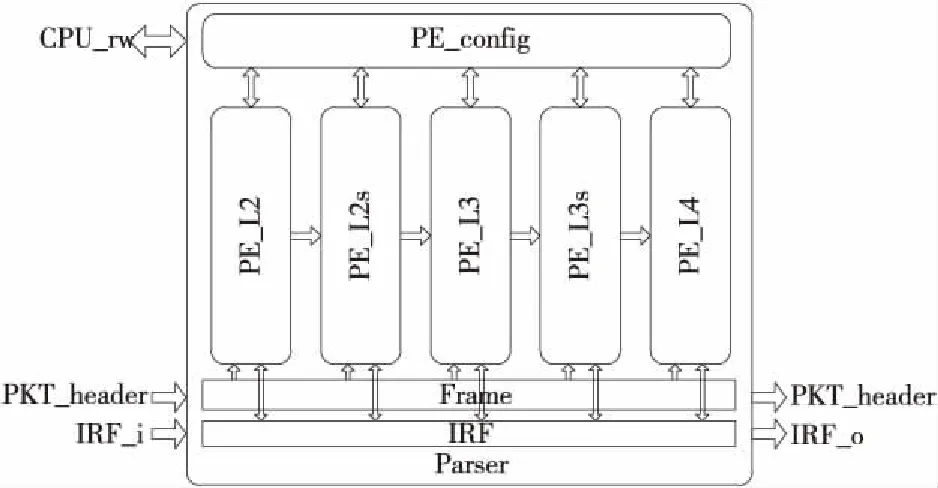
Figure 1 Overall structure of Parser圖1 Parser的整體結構框圖
圖1中可重構PE模塊是此報文解析器的核心部分,可重構PE模塊通過配置可以實現不同的硬件解析邏輯,從而支持對不同協議報文的解析。基本的設計原則是數據包的每層封裝的解析對應1級PE單元,對應現代需要解析到L4層的交換機,典型應用場景中包含5級PE。通過配置可以實現不同層之間的配合解析,也可以每層獨立解析,因此具有較高的靈活性。
3 可重構基本處理單元
硬件可重構解析處理單元的實現是本設計的關鍵所在。包含不同協議的網絡數據包,其對應數據域的位置、長度、類型均不相同,因此要處理不同協議的數據包,就需要靈活地調動同一層或不同層的硬件資源,通過這些資源的相互配合來協同工作,這就要求必須實現可靈活配置的硬件可重構單元。
由于數據包包頭是各種報文序列的組合,因此數據包的解析過程可以按層進行劃分,每層報文的解析可以概述為提取、查找、動作3個過程。接收到的數據包輸入到數據包解析器中,對應任一層協議的解析,首先要根據協議類型提取出當前協議包頭的關鍵字段,然后進行查表匹配出需要執行的動作,最后執行相應的動作(如提取關鍵字段值、字段值的比較、設定報文類型描述符等),這就完成了一層報文解析的過程。
可重構PE是實現上述解析邏輯可重構的基本單元,其結構如圖 2所示,主要是由PE配置模塊(PE_config)、 Cell_A單元、Cell_B單元、PE_bypass模塊、Offset模塊、Frame數據通路、IRF 數據通路幾個部分組成。
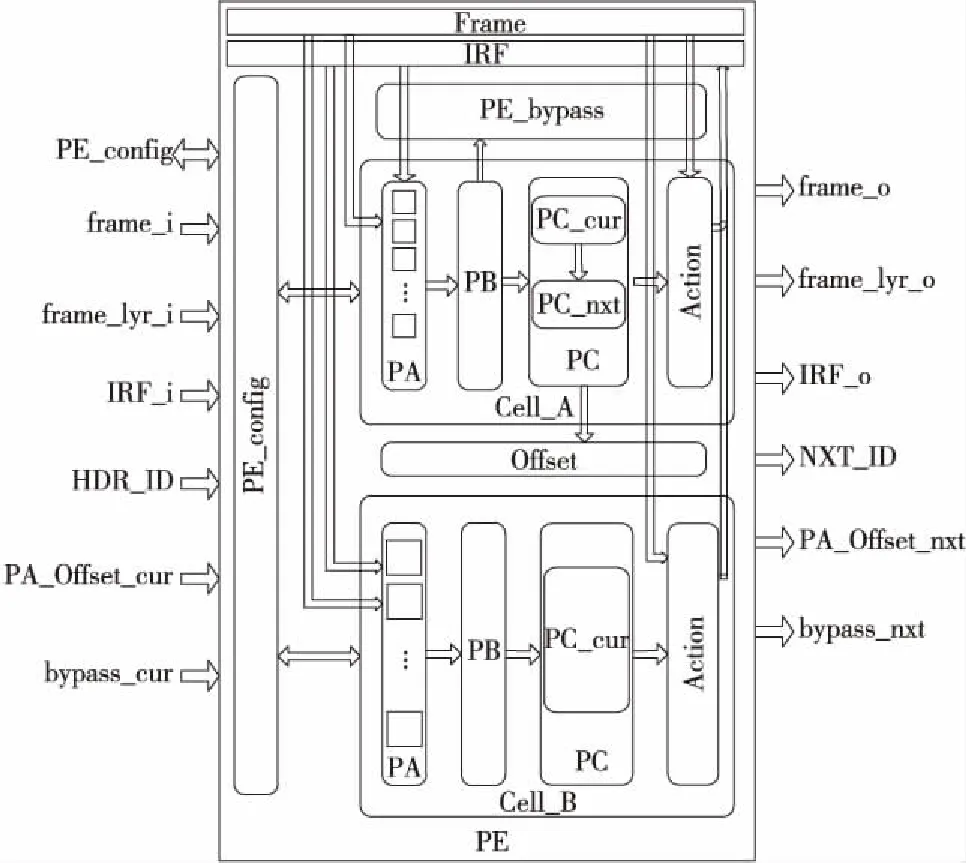
Figure 2 Structure of reconfigurable PE圖2 可重構PE結構框圖
在這里將Cell_A單元和Cell_B單元統稱為Cell單元,其用來實現對協議報文的解析,Cell單元的硬件實現邏輯可以根據協議幀格式進行配置,從而支持不同的協議幀的解析。Cell單元中包含PA、PB、PC和Action幾個部分,其中PB、PC主要為查找表結構,而Cell_A單元和Cell_B單元的區別將在下1小節中具體說明。
典型情況下,Frame數據通路中傳輸的是1 024 bit的數據包包頭信息,主要是向Cell單元提供數據,Cell單元可以在Frame中提取出任意指定的數據匹配域(即關鍵字段)。
IRF數據通路是用來暫存解析過程中所產生的結果(描述符)和需要跨層傳遞的臨時中間數據,其在第1層輸入的是由前端的報文預解析模塊產生的初始數據,如端口號、是否為環回報文等,然后每經過1層PE單元,寄存器的數量增加相應的量,為每層PE處理過程中所新產生的數據包描述信息。
PE_config單元是完成Cell單元中PB、PC的查找表的表項內容的配置。
PE_bypass單元主要實現跨層協議的處理,如Ethernet+IPv4+…的數據包,在PE_L2層完成了Ethernet的解析,而IPv4是在PE_L3層解析的,則需要跳過L2子層,此時PE_L2s內的PE_bypass單元就完成該工作,其根據上1層傳來的bypass_cur信號執行跳過本層的動作,同時為了匹配各層的延時,需要將數據通路的數據信號進行相應的延時。
Offset單元用來實現每層PE單元的Frame數據通路的起始數據訪問位置的偏移工作,對于1個數據包,上1層解析過的數據,在下1層不需要再次訪問,因此下1層的起始訪問數據將要越過上層已解析的數據,該單元就完成對應操作。這種做法可以減少偏移量的存儲位寬,同時縮小訪問范圍,降低硬件設計復雜度和硬件開銷。
3.1 Cell單元
Cell單元是每層PE實現對應協議解析的關鍵所在,其有2種不同的形式——Cell_A單元和Cell_B單元。如圖 2所示,Cell單元中均包含PA、PB、PC、Action幾個模塊。
Cell中的PA模塊用來實現特定數據域的提取,每1個Cell單元中設置了若干個PA。PA模塊的輸入為前1級PE輸出的關鍵字段偏移量、本級Frame寄存器的待提取的數據幀,輸出為提取出來的關鍵字段。PB模塊的輸入為本級各PA模塊輸出的關鍵字段,其核心是1個匹配查找表,把關鍵字段組合和其中存儲的匹配模板一一比較,輸出匹配的模板所對應的協議類型信息。如果關鍵字段和任何特征模板都不匹配,則發送非法標識到PC單元,PB單元每個匹配模板還有1個對應的掩碼字,用來忽略不關心的比特。PC中有PC_cur和PC_nxt 2種表,其中PC_cur表用來根據PB表的匹配結果索引要執行的動作,PC_nxt表用來根據PB表的匹配結果索引下1層PE單元要提取的關鍵字的偏移量。Action用來執行PC表索引的對應的動作,這些動作的定義以超長指令字的形式表示,Action執行的指令的源操作數來自Frame(即數據包頭字段)、IRF或立即數寄存器,執行結果被寫入IRF。
在數據包頭解析的過程中,存在同時檢查多個關鍵字段的情況(如QinQ協議解析時就需要同時提取外層Type、內層Type和MAC 3個字段域,PA取出這些字段后,再將他們拼接成1個Keyword輸出給PB進行查表),特別是如果這些關鍵字段彼此是獨立還要考察其各種組合,則需要對應增加很多表項(如MAC域要進行的是比較操作,Type域要進行的是協議類型查找操作,假使MAC域有m種可能,Type域有n種可能,如果把這2個獨立的域合成1個Keyword給PB進行查表,則存在m×n種組合的可能性,即會使PB表增加m×n行,這將使存儲開銷激增),而各層協議的匹配任務數量(即需要支持的協議種類數量)差異也較大,業務類型越豐富的層匹配任務越多,如果只使用1種固定的Cell單元,同時滿足所有層次的需求,會引入很大冗余開銷,因為匹配任務數量少的層無需大的存儲表,而如果采用較小的Cell單元,某些層可能僅靠1個Cell單元無法完全解析,如果串聯多個Cell單元解析,則時鐘周期將大大增加,降低解析速度。因此,本文采用多個小單元任意組合的解決方案,即在不同層次上根據需要并行放置不同數量的Cell單元。同時使用多個Cell單元并行解析,這樣可以解耦復雜的解析操作,即將彼此獨立的條件匹配復雜操作進行分解,然后存儲到并行的多個Cell單元的表中,這樣不僅可以保證1層協議頭在PB處只需1個時鐘周期即可完成解析,降低了配置的復雜度;同時也可以去除表項之間的耦合關系,使獨立的匹配條件分別存儲到多張表中,減少表項的條目,即減小存儲開銷。例如,上述Type和MAC 2個字段的匹配操作,如果分別使用2個并行的Cell單元來處理,則一共僅需m+n行表項,這將大大節約存儲開銷。因為每層協議解析僅需1張存儲下1層協議類型的表(即PC_nxt表),如果直接使用相同的Cell單元并行解析1層協議,則PC_nxt表資源會存在浪費,因此這里設計了2種形式的Cell單元:Cell_A和Cell_B。在Cell_A單元中PC模塊包含PC_cur和PC_nxt 2種表,而Cell_B單元的PC模塊僅有PC_cur這1張表。考慮到一些協議解析操作比較復雜,為了簡化硬件配置邏輯,PE有3種組合情況,Cell_A單元都是1個,但其可以分別含有0個、1個、2個Cell_B單元,具體使用哪種情況,在設計調用時要根據實際解析的數據包在各層解析所占用的硬件資源來確定。
使用2種形式的Cell單元并行解析的實現方式,通過PE_config單元的配置,可以使Cell_A、Cell_B單元協同工作,同時解析協議樹中同1層的多個協議。當2個Cell_B單元仍無法完全解析1層協議時,可以通過對相鄰2層PE單元中查找表的協同配置,使相鄰2層或多層PE單元來處理1個較為復雜的協議層。這樣,只要不超出硬件資源的容量,可以實現任意1種未知協議的解析,提高硬件資源的復用率和通用擴展性。
3.2 可重構處理單元的數據通路
3.2.1 關鍵字段提取單元PA
PA負責解析器中Frame數據和IRF數據的提取工作,其通過輸入的Offset值,對輸入數據中相應的字段值進行提取。PA可以分別訪問到Frame和IRF 2個數據存儲單元,具體訪問哪一路數據由PE_bypass單元指定。PA提取的數據作為關鍵字傳給PB。PA單元的結構如圖 3所示。
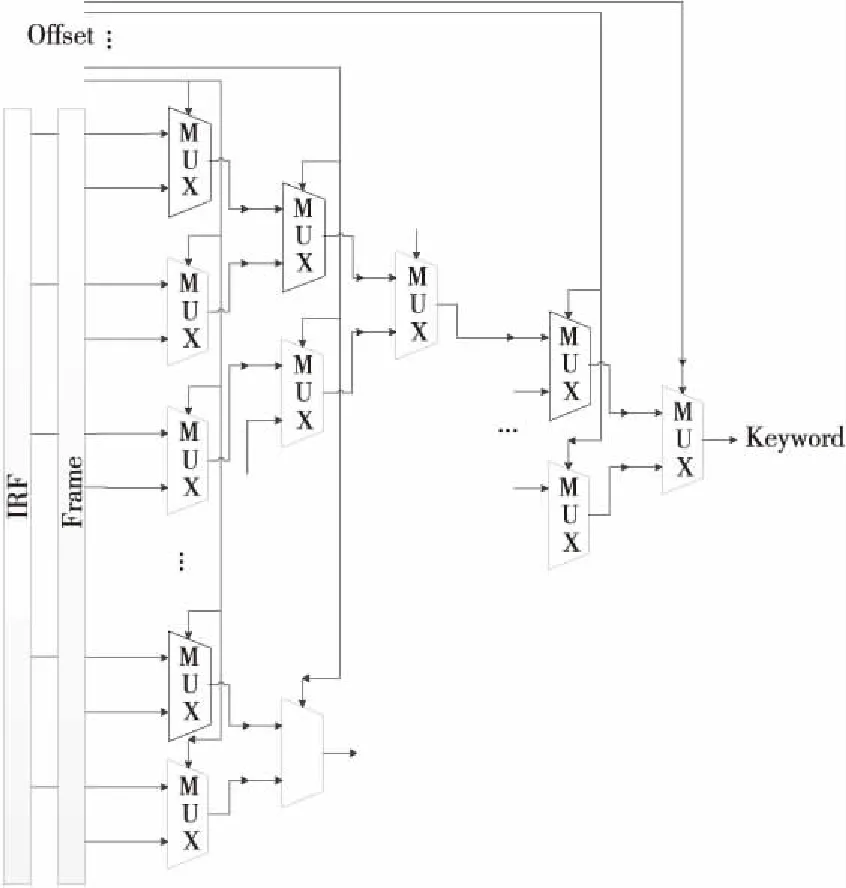
Figure 3 Internal structure of PA圖3 PA內部結構
如圖 3所示,PA用來實現特定數據域的提取,每1個Cell單元中設置了若干個PA,在實現提取時采用統一提取的方式,一次性提取出本級PE后續解析所需要的所有關鍵字段,以提高提取效率。由于前1層解析過的包頭數據在下1層解析中不需要再次訪問,因此通過偏移對齊每層協議頭部(偏移工作由Offset單元完成),可以減少用來描述可訪問數據的位寬,即縮小偏移量位寬,不僅節省硬件開銷,也提高了解析速度。因此,在本設計中,PA只能訪問當前層協議幀頭部的數據,即整體訪問跨度等于所有協議幀頭部長度的最大值,本設計每個PA可訪問16字節的數據。同時,又由于匹配域(即關鍵字段)的長度不定,很難做到通用,如果使用固定邏輯會浪費硬件開銷,分散提取會增加數據偏移量的存儲開銷,因此為了降低后續處理硬件邏輯的復雜度,在該模塊采用固定長度的提取方案,即每個PA單元1次可提取出1個字節數據。長度超過1個字節的字段,則由多個PA分別提取后拼接,當長度不是字節整倍數時,則額外提取相鄰位補充成完整字節,多余的比特在匹配時再利用掩碼功能忽略掉。
3.2.2 關鍵字段匹配單元PB
PB是查找表結構,其表項內容如表 1所示,PB可以根據PA傳來的關鍵字和上級PE解析出的本層協議類型(HDR_ID)匹配出本層協議所執行的動作索引SUB_ID和下1層協議類型(NXT_ID)及Bypass信息。為了降低配置的復雜度,采用二級表結構將表項進行拆分,對于一些復雜運算先經過前級表進行轉換,變換成已有的簡單運算,再在后級表中進行匹配。

Table 1 Contents of PB table表1 PB表的表項結構
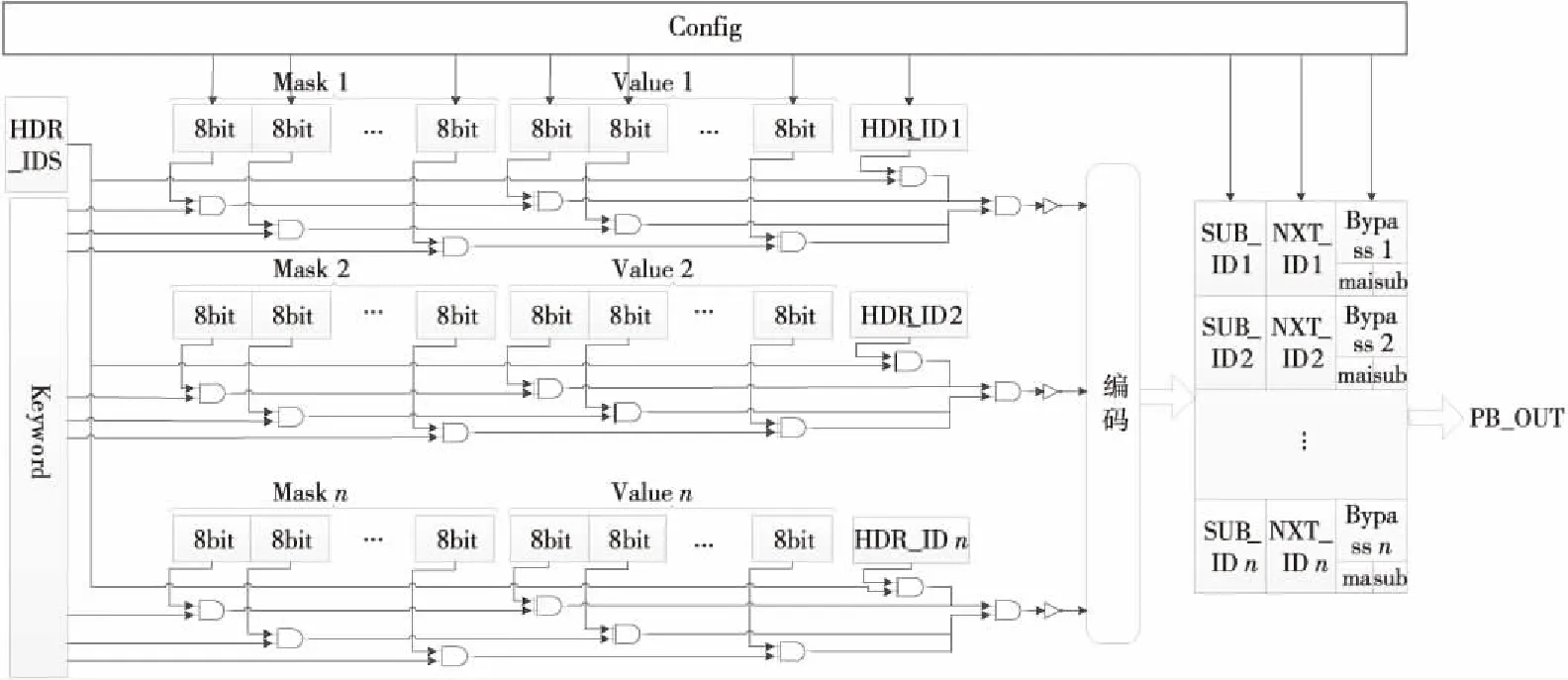
Figure 4 Internal structure of PB圖4 PB內部結構
PB單元的內部結構如圖 4所示,其接收到的關鍵字先與Mask進行掩碼操作,然后再與查找表中存儲的Value項進行匹配。這里使用掩碼操作是為了在提取時可以實現固定長度的統一提取操作,這樣不僅降低了硬件設計的復雜度,規范了數據的處理位寬,同時減小了存儲開銷。
3.2.3 動作及協議類型索引單元PC
PC中有PC_cur和PC_nxt 2種表,如表2所示,PC_cur表根據PB表的匹配結果(SUB_ID)索引要執行的動作的超長指令字VLIW(Very Long Instruction Word)信息和下1級PE單元的Frame數據通路的起始數據訪問位置的偏移(LYR_offset)信息,并分別將VLIW通過Action、LYR_offset輸出給本級PE的Offset單元;PC_nxt表根據PB表的匹配結果(NXT_ID)索引下1層PE單元的每個PA所要提取數據域的位置偏移信息PA_offset。
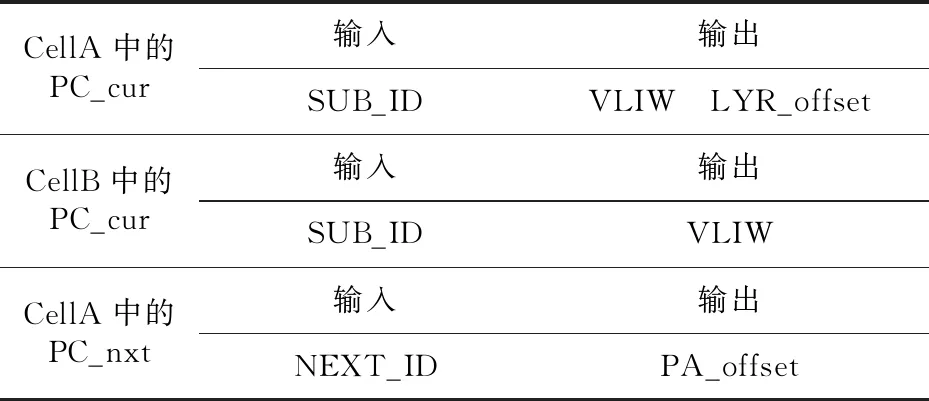
Table 2 Contents of PC table 表2 PC表的表項結構
PC_cur表的實現結構如圖 5所示,其主要使用SRAM(Static Random Access Memory)實現,為了節省存儲空間,在配置PC_cur表時,使其表項條目順序按照PB表中對應的SUB_ID條目的順序進行存儲,這樣在PC_cur表中可以省去SUB_ID的匹配過程,簡化了硬件設計復雜度。
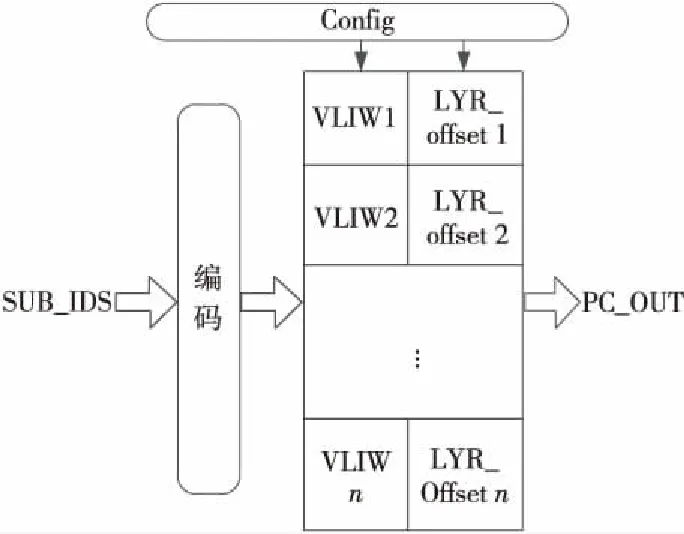
Figure 5 Internal structure of PC_cur圖5 PC_cur內部結構
PC_nxt表的內部實現如圖 6所示,其根據PB給出的NXT_ID信息,與自己表中的HDR_ID信息匹配出下1層PE單元的PA模塊所提取的關鍵字段的偏移量PA_offset信息。其表項內容通過配置可以做出相應的改變,以此來滿足不同協議解析的要求。
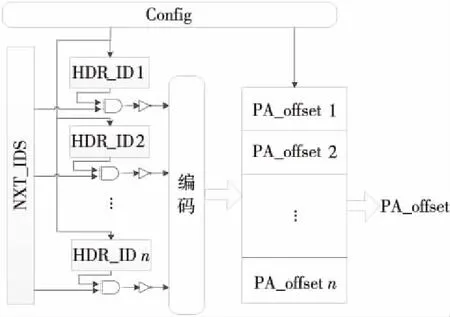
Figure 6 Internal structure of PC_nxt圖6 PC_nxt內部結構
3.2.4 動作執行單元Action
Action用來執行PC表索引出的對應動作,其接收來自PC的超長指令字(VLIW),解析指令,取源操作數并執行。Action內部有3種指令單元,如圖 7所示,每種指令單元各8個,共24個。1個超長指令字包含24個子指令,分別控制這24個指令單元。在本設計中對每級PE做了IRF的預分配,每個Action單元對應分配到24*8 bit的IRF空間,即每個指令對應8 bit的IRF空間,用來存儲指令的運行結果;同時,為了簡化IRF的存儲結構復雜度,在本設計中,將指令單元與存儲空間進行了綁定,而存儲空間的實際意義(即存儲的數據結構)由編譯器進行指定,與硬件結構無關。
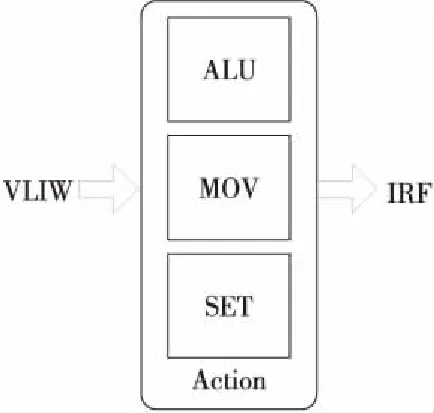
Figure 7 Diagram of Action圖7 Action框圖
在指令集設計中,盡量精簡指令集,以縮短指令長度,指令長度縮短可以降低PC模塊中的表項規模,簡化指令譯碼邏輯復雜度。各指令單元如圖 7所示,ALU單元用來執行大于(Greater than)、等于(Equal)等比較操作,MOV單元和SET單元分別執行復制(Move)、置數(Set)操作。Move子指令將Frame或IRF中的數據賦值到IRF寄存器中。Set子指令將數值域的值賦值到對應的IRF寄存器中。報文解析中用到的其它操作(如大于或等于等操作)都可以轉化為這幾種操作。這3種指令單元的指令格式如表 3所示。
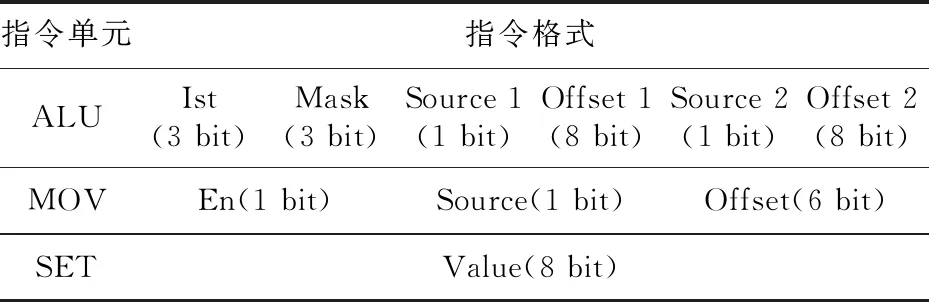
Table 3 Sub instruction format of Action表3 Action的子指令格式
ALU單元子指令共24 bit,分為6個域,分別為指令名稱域(Ist)、掩碼域(Mask)、操作數1源選擇域(Source 1)、操作數1偏移量域(Offset 1)、操作數2源選擇域(Source 2)、操作數2偏移量域(Offset 2)。Ist域用來指定操作類型;Mask域對操作數做掩碼操作,去除操作數中無用信息,其做掩碼時以字節為單位,最高支持64 bit;操作數源選擇域指示操作數來源于Frame還是IRF;操作數偏移量域指示從數據源中提取的具體數據位置偏移量。ALU單元的操作結果存放到IRF寄存器中。
MOV單元子指令共8 bit,分為3個域,分別為使能域(En)、操作數源選擇域(Source)、操作數偏移量域(Offset)。En域指示是否執行MOV操作;Source域指示操作數來源于Frame或IRF;Offset域指示從數據源中提取的具體數據位置偏移量。
3.3 存儲開銷分析
在可重構處理單元中,存儲開銷主要包括:存儲類型域內容的查找表、存儲偏移量信息及匹配域字段的查找表、存儲中間數據的寄存器IRF、存儲數據包包頭的Buffer。這幾個部分的開銷分析如下:假設PE中PA模塊的個數為Npa;PB模塊查找表可以支持的協議條目數為Pb;PC模塊中當前級查找表(PC_cur)支持的協議條目數為Pccur,下1級查找表(PC_nxt)支持的協議條目數為Pcnxt;ALU指令的位寬為A,MOV指令的位寬為M,SET指令的位寬為S,Action單元中指令單元總個數為Z;每層可重構處理單元(PE)所支持的最大和最小包頭長度分別為Max_header和Min_header。那么,各種存儲開銷計算公式如表 4所示。

Table 4 Storage overhead calculation formula表4 存儲開銷計算公式
對于包含1個Cell_A單元、2個Cell_B單元(每個Cell單元中包含24個PA單元、1個PB單元、1個PC單元、1個Action單元)的PE(可支持的協議條目為32,數據包包頭長度為1 024 bit)開銷如下:PB表總計38 496 bit;PC表總計49 632 bit;IRF寄存器總計704 bit;緩沖寄存器總計1 262 bit,即1層PE的總存儲開銷約為87.98 Kb。
3.4 基于本文PE的包解析器實例
本節將給出1個基于本文所設計的PE實現的支持如表 5所示的協議集合的數據包解析器作為示例,說明PE的配置方法。
以太網數據包包頭包含的首先是鏈路層協議,如Ethernet Ⅱ、Vlan、 IP-in-IP(802.1q)等;然后是

Table 5 Protocol set supported by the packet parser表5 數據包解析器支持的協議集合
MPLS層協議,典型的如MPLS L2/L3VPN等;接下來是網絡層協議(如IPv4、IPv6等)和傳輸層協議(如TCP、UDP等),本設計支持到傳輸層協議的解析。如圖 8所示,數據包的解析過程可以按照樹形結構進行分解,每1個樹的節點為1種協議,樹的每1層為1個解析層次,與之對應,采用層的硬件結構對數據包進行解析,每1級或2級PE單元對應協議樹的1層節點,通過配置可重構處理單元來實現本層協議的硬件解析邏輯。
根據數據包的層封裝結構的解析過程,將整個解析器設計為流水線(層)結構。在本示例中,為支持到傳輸層協議的解析,選用5層PE進行級聯,為能夠支持IP-in-IP、MPLS等協議的解析,每層PE單元內部包含1個Cell_A單元、2個Cell_B單元,每個Cell單元中均包含24個PA單元、1個PB單元、1個PC單元、1個Action單元,每層PE單元所支持的解析協議類型如表 5所示。在每級PE單元中,需要配置7張表(Cell_A中1個PB、1個PC_cur和1個PC_nxt,2個CellB中各1個PB和1個PC_cur),它們的具體內容由配套設計的編譯器生成(編譯器的設計本文不做討論),然后通過PE_config單元加載。根據3.3節的公式估算,所用存儲資源共計0.429 6 Mb。

Figure 9 Simulation results of packet parser圖9 數據包解析器功能仿真結果
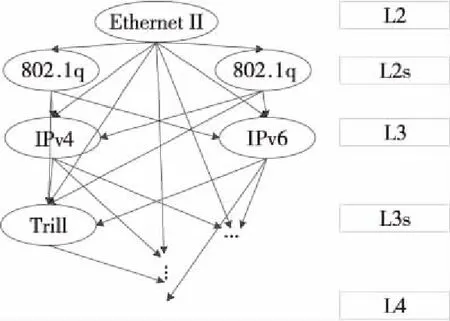
Figure 8 Schematic diagram of message protocol tree structure圖8 報文協議樹結構示意圖
4 性能分析
本文提出1種可重構的以太網數據包解析器中可重構單元的實現,以EthernetⅡ+Vlan+IPv4+MPLS+TCP數據包為例對其功能進行驗證分析,如圖 9所示為其功能仿真結果。
將圖9輸出結果與Wireshark工具軟件的輸出結果進行了比較,結果顯示一致。并使用Synopsys公司的邏輯綜合工具對本設計做了DC綜合分析,使用40 nm的工藝庫,最終系統能達到的時鐘頻率為240 MHz,由于測試實例使用了5級PE單元,每級時延為4個時鐘周期,故此數據包解析器處理1個數據包大約需83 ns,由本文PE按照流水線級聯方式組成的解析器理論上每個時鐘周期可以輸出1個數據包,因此由解析器決定的最高數據包吞吐率可達每秒2.4億個數據包(假設不存在環回報文)。同時,對1級PE(包含3個Cell單元,每個Cell單元中包含24個PA單元、1個PB單元、1個PC單元、1個Action單元)的面積做了評估,其面積為3 528 761.77,約為147.56萬門。
5 結束語
針對目前網絡體系中數據中轉設備的更新速度難以跟上網絡結構的更新速度的問題,以及為了降低硬件部署成本的現實需求,本文提出了1種以可重構的方式實現更改解析邏輯的數據報文解析器基本處理單元,并對其進行了功能測試及資源分析,其靈活性可以很好地滿足現實需求。通過測試這種結構可以看出,該結構支持多種協議且具有較高的轉發速率。該設計對軟件定義網絡(SDN)[11]的交換機芯片設計具有重要的價值。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
時代農機(2015年3期)2015-11-14 01:14:29
科技傳播(2015年20期)2015-03-25 08:20:30
信息安全研究(2015年3期)2015-02-28 20:18:12
西安航空學院學報(2014年5期)2014-07-13 01:27:52
家電科技(2014年5期)2014-04-16 03:11:28
汽車零部件(2014年2期)2014-03-11 17:46:27
