基于BiLSTM-CNN串行混合模型的文本情感分析
2020-03-06 12:55:58王偉杰
計算機應用 2020年1期
趙 宏,王 樂,王偉杰
(蘭州理工大學 計算機與通信學院,蘭州 730050)
0 引言
互聯網技術的持續進步帶動自媒體的快速發展,以微博、Facebook、Twitter等為代表的自媒體為用戶提供了表達觀點和抒發個人情感的平臺,累積了海量帶有個人觀點和情感傾向的文本。對這些文本中個人觀點和情感傾向進行挖掘,可以及時獲取網民對熱點事件的觀點、網民對購物和社交活動的情感傾向,有助于政府相關部門對網絡輿情的把控,商家對客戶需求的精準理解[1]。
這些海量文本來源于互聯網的眾多用戶,形式多樣,無固定格式,很難用簡單的自動化手段進行處理;如果依靠人工處理,則存在工作量過大和實時性較差等問題[2]。自然語言處理領域的文本情感分析可以從表達形式自由的文本中提取作者的情感傾向,能夠應用于海量文本的情感分析中。
為了實現海量文本的情感分析,學者們通過統計學、機器學習和神經網絡等方法分析文本情感傾向[3]。
基于統計學的方法,首先對情感詞典中短語進行極性和強度標注;然后依據情感詞典,對待處理文本中提取的關鍵詞計算積極或消極的情感得分;最后經過總和,得到文本情感傾向。常用的情感詞典主要有詞匯網絡詞典(WordNet)、臺灣大學情感詞典(National Taiwan University Sentiment Dictionary,NTUSD)和評價詞詞典(General Inquirer, GI)等[4]。Hu等[5]依托WordNet詞典計算待處理文本的情感得分,取得了較好的效果。Kim等[6]利用手工采集的種子情感詞匯對現有情感詞典進行擴充,提高了文本情感分析的準確率。郗亞輝[7]利用情感詞間的交互信息和上下文約束關系擴展了情感詞典的功能,從而提高了文本情感分析的準確率,取得比較好的效果。Xu等[8]利用基本情感詞、字段情感詞和多義詞情感詞對情感詞典進行擴充,在評論文本上提高了文本情感分析的準確率。Hu等[5]、Kim等[6]、郗亞輝[7]和Xu等[8]都是依托情感詞典統計待處理文本的積極和消極情感詞的數目,從而得到文本的情感傾向,取得較好的效果;但文本情感分析的準確率和情感詞典規模的關聯度較大,從而使得模型的泛化能力較差,實時性不強。
基于機器學習方法,首先通過人工標注的形式構造結構化的文本特征,然后使用樸素貝葉斯(Naive Bayes, NB)、最大熵 (Maximum Entropy, ME)和支持向量機 (Support Vector Machine, SVM)等機器學習分類器對待處理文本進行情感分析。Pang等[9]根據傳統自然語言處理中的文本分類技術,綜合應用樸素貝葉斯、最大熵和支持向量機等文本情感分析方法,在提取英文電影評論文本情感上取得了顯著的效果。李婷婷等[10]提出了一種基于SVM和條件隨機場(Conditional Random Field, CRF)相結合的文本情感分析方法,利用多種文本特征,如詞性、情感、程度等,構造出不同的特征組合,提高了文本分類的準確率。朱遠平等[11]構建了一種優化的SVM決策樹分類器,依據類間距離進行分類,提高了SVM決策樹分類器在文本分類中的有效性。Cai等[12]先利用情感詞典對待處理文本構造結構化的文本特征;然后使用SVM和梯度提升樹(Gradient Boosting Decision Tree, GBDT)結合的混合模型進行文本情感分析,并取得了比單一模型更好的分類效果。Pang等[9]、李婷婷等[10]、朱遠平等[11]和Cai等[12]都是通過人工構造結構化的文本特征如詞性、情感等,使用機器學習分類器對待處理文本進行情感傾向分析。雖都取得顯著的分類效果,但過多地人工構造結構化的文本特征,實時性較差。
基于神經網絡的方法,首先利用詞向量模型將離散的文本詞匯轉化為含有語義信息的高維實數向量,然后以有監督的形式學習積極和消極的詞向量特征,從而得出文本的情感傾向。Bengio等[13]利用神經網絡構建語言模型,將詞向量映射到實數空間,通過計算詞之間的數值距離來判斷詞之間的相似性,簡化了文本情感提取方法。Kim[14]使用不同卷積核的卷積神經網絡對英文文本局部語義特征進行提取,實現了句子級的分類任務并取得很好的分類效果。梁軍等[15]提出了基于極性轉移和LSTM神經網絡的情感分析方法,在情感極性轉移模型中使用LSTM提取文本上文語義信息,提高了情感分析的準確率。曾誰飛等[16]將單詞詞典和詞性詞典的詞向量進行融合,構成Double word-embedding,送入BiLSTM進行訓練,進一步提高了文本情感分析的準確率。Ma等[17]提出了一種基于特征的合成存儲器網絡(Feature-based Compositing Memory Network,FCMN),利用FCMN提取待處理文本的三種特征豐富上下文的單詞表示。通過結合特征表示和詞嵌入,提高了注意力的性能,從而在文本情感分析中取得不錯的分類效果。Bengio等[13]、Kim[14]、梁軍等[15]、曾誰飛等[16]和Ma等[17]都通過神經網絡語言模型進行文本情感分析,并取得很好的分類效果;但沒有綜合考慮文本的上下文信息和局部語義特征對文本情感分析的影響。
以上文本情感分析方法各有優勢,相比而言,基于統計學的方法使用情感詞典統計帶有情感標注的短語計算情感得分,提高了文本情感分析的準確率;但文本情感分析的準確率和情感詞典規模的關聯度較大,實時性不強。基于機器學習的方法使用人工標注的方式構造結構化的文本特征,可以有效提高文本情感分析的準確率;但由于需要較多地人工構造特征,實時性仍然不強。另外,人工標注數據還需要一定的先驗知識,使得該方法應用于大規模文本數據時,效用下降。基于神經網絡的方法可以從向量化的文本詞匯中自動提取語義特征,不依賴人工構造的特征;但是,使用單一的神經網絡模型進行特征提取,不能同時提取文本上下文信息和局部語義特征。
綜上,針對現有文本情感分析方法實時性不強、難以應用到大規模文本、不能同時提取文本上下文信息和局部語義特征等問題,提出一種基于雙向長短時記憶神經網絡和卷積神經網絡(Bi-directional Long Short Term Memory and Convolutional Neural Network, BiLSTM-CNN)串行混合的文本情感分析方法。首先,使用Word2Vec對文本詞匯進行向量化,將評論文本詞匯轉化成高維實數向量;然后,通過BiLSTM-CNN串行混合模型提取文本上下文特征和局部語義特征;最后,使用Softmax分類器對文本進行情感傾向分類。
本文的主要工作如下:
1)利用BiLSTM提取文本上下文特征,充分考慮了自然語言中一個詞的語義不僅與它之前的信息有關,還與它之后的信息有關;
2)先利用BiLSTM對待處理文本進行上下文特征提取,再對已提取的上下文特征使用CNN進行局部語義特征提取。既能同時利用BiLSTM和CNN提取特征的優勢,又能很好地理解待處理文本的語義,從而提高文本情感分析的準確率。
1 BiLSTM-CNN串行混合模型的建立
基于BiLSTM-CNN串行混合模型如圖1所示,分為數據預處理、文本詞匯向量化、特征提取、情感分類等四個步驟。

圖1 BiLSTM-CNN串行混合模型Fig. 1 Serial hybrid model based on BiLSTM-CNN
圖1中,數據預處理對文獻[18]中帶標注的評論文本去除噪聲,只保留具有語義信息的文本,降低噪聲對文本情感分析準確率的影響;文本詞匯的向量化利用Word2Vec工具將評論文本詞匯轉化成含有語義信息的實數向量;特征提取使用BiLSTM-CNN串行混合模塊,細分為BiLSTM提取文本的上下文信息和CNN提取局部語義特征;情感分類使用Softmax。最后,使用十折交叉驗證方法對基于BiLSTM-CNN串行混合模型進行訓練以及性能評估。
1.1 數據預處理
大量的評論文本由不同的用戶抒寫而來,形式自由,沒有固定的語法和模式,而評論文本不僅包含具有語義信息的文本,還存在大量的噪聲數據。為了減少噪聲數據對文本情感分析的影響,需要對評論文本進行以下預處理:
1)過濾掉所有的標點符號和特殊字符,只保留具有語義價值信息的中文文本。
2)使用jieba分詞工具進行詞語分割。
3)使用哈工大停用詞表、百度停用詞表和四川大學機器智能實驗室停用詞表[19]的交集,去除噪聲數據。
4)對標簽進行數字化,積極情感表示為1,消極情感表示為0。
1.2 文本詞匯向量化
數量巨大的評論由不同用戶自由書寫而來,沒有結構化或規范化的語法和模式,具有高度非結構化的特點,因此,不能直接使用現成的數學模型或統計模型來處理和分析,需要將評論中的文本詞匯轉化成實數向量再進行處理和分析。開源詞向量工具Word2Vec[20-21]利用詞袋模型(Continueus Bag Of Words, CBOW)或跳字模型(Skip-gram),能夠將文本詞匯轉化成含有一定語義信息的高維實數向量。
CBOW模型通過上下文詞匯預測中心詞,Skip-gram模型通過中心詞預測其上下文詞匯。CBOW在訓練的過程中,預測次數為x,其中x是評論文本的詞匯數量;Skip-gram預測次數則是k*x,其中k表示上下文的詞匯數量。兩種模型對比,CBOW相比Skip-gram訓練時間較短,但是對于一些低頻詞,CBOW模型的預測效果較差,模型泛化能力較弱。考慮到模型的泛化能力,本文選用Word2Vec的Skip-gram模型對文本詞匯進行向量化處理。
假設評論文本W={w(1),w(2),…,w(n)},以第t個詞為中心詞進行文本詞匯向量化操作,記為(V(w(t)),Context(w(t))),其中V(w(t))為評論文本W中心詞w(t)的詞向量,Context(w(t))為w(t)的上下文詞向量。使用Skip-gram模型的輸入、投影和輸出三層結構進行文本詞匯向量化轉變,如圖2所示。

圖2 Skip-gram模型Fig. 2 Skip-gram model
圖2中,評論文本W的第t個詞w(t)為中心詞,輸入層為中心詞w(t)的one-hot詞向量V(w(t));從輸入層到投影層是恒等投影,即將V(w(t))投影到V(w(t));投影層到輸出層根據評論文本詞匯的詞頻構建Huffman樹,并按照式(1)計算w(t)的上下文詞匯向量:
P(V(w(i))|V(w(t)))
(1)
其中:V(w(i))∈Context(w),t為中心詞序號,i為中心詞上下文詞匯與中心詞的距離。
從根節點開始,投影層的值沿著Huffman樹進行二元邏輯回歸(Logistic)分類,輸出w(t)周圍2n個上下文文本詞匯的詞向量。例如,如果n取2,則中心詞w(t)的前兩個詞為w(t-2),w(t-1),后兩個詞為w(t+1),w(t+2),它們對應的詞向量為V(w(t-2)),V(w(t-1)),V(w(t+1)),V(w(t+2)),即Context(w)={V(w(t-2)),V(w(t-1)),V(w(t+1)),V(w(t+2))}。
1.3 上下文信息提取
不同的用戶通過自媒體平臺發表的評論是自然語言的一種表現形式,形式雖然自由但結構上仍然存在上下文依賴關系。依據文本的上文信息和下文信息,能夠更準確地理解文本語義。經典的循環神經網絡(Recurrent Neural Network, RNN)能夠挖掘文本的時序信息和上下文語義信息,但RNN在學習任意長度的時間序列時,隨著輸入的增多,對很久以前信息的感知能力下降,產生長期依賴和梯度消失問題[22],而從RNN改進而來的長短時記憶(Long Short Term Memory, LSTM)網絡[23]能夠解決RNN的長期依賴和梯度消失問題。圖3所示是具有三個門控結構的LSTM網絡模型。
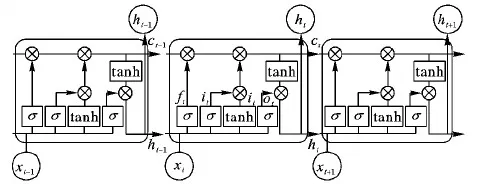
圖3 LSTM網絡模型Fig. 3 Network model of LSTM
LSTM模型中各個門計算如式(2)~(7)所示:
ft=σ(Wf·[ht-1,xt]+bf)
(2)
it=σ(Wi·[ht-1,xt]+bi)
(3)
ot=σ(Wo·[ht-1,xt]+bo)
(4)
ht=ot°tanhct
(5)
(6)
(7)
其中:Wf表示遺忘門連接的權重矩陣,bf表示遺忘門的偏移值,Wi表示輸入門連接的權重矩陣,bi表示輸入門的偏移值,Wo表示輸出門連接的權重矩陣,bo表示輸出門的偏移值,“°”表示兩個矩陣元素的相乘。
雖然LSTM解決了梯度消失和長期依賴問題,但LSTM只能學習文本的上文信息,而不能利用文本的下文信息。由于一個詞的語義不僅與文本的上文信息有關,還與文本的下文信息密切相關,因此,利用BiLSTM(Bi-directional Long Short Term Memory)[24]代替LSTM,引入下文信息。BiLSTM模型是由兩個LSTM網絡通過上下疊加構成,如圖4所示。

圖4 BiLSTM網絡模型Fig. 4 Network model of BiLSTM
BiLSTM模型中每一個時刻狀態計算如式(8)、(9)所示。輸出則由這兩個方向的LSTM的狀態共同決定,如式(10)所示:
(8)
(9)
(10)
其中:wt表示正向輸出的權重矩陣,vt表示反向輸出的權重矩陣,bt表示t時刻的偏置。
基于BiLSTM的語言模型結構如圖5所示,其中,V(w(i))表示第i個評論文本詞匯的詞向量,1≤i≤n。
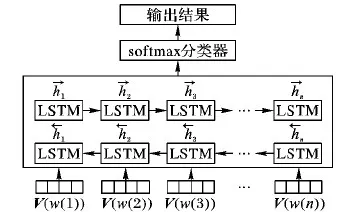
圖5 BiLSTM語言模型結構Fig. 5 Language model structure of BiLSTM
假設評論文本W={w(1),w(2),…,w(n)},首先將評論文本W中的詞w(i)利用Word2Vec轉化為對應的詞向量V(w(i)),并將詞w(i)組成的句子映射為句子矩陣Sij,其中Sij={V(w(1)),V(w(2)),…,V(w(i))},1≤i≤n。然后利用BiLSTM對句子矩陣Sij進行上下文特征提取,計算方法如式(10)所示,即利用正向的LSTM提取評論文本的上文信息特征,計算方法如式(8)所示,反向LSTM提取評論文本的下文信息特征,計算方法如式(9)所示。
1.4 局部語義特征提取
評論文本由不同的用戶書寫,用戶通過形容詞、副詞等情感詞匯表達其情感傾向。情感詞匯或句子間存在一定的層次結構和語義關系,卷積神經網絡(Convolutional Neural Network,CNN)[25]可以通過卷積層提取情感詞匯所表達的局部語義特征,因此,選用CNN進行文本局部語義特征提取。
用于文本語義提取并進行分類的卷積神經網絡模型如圖6所示。
假設評論文本W={w(1),w(2),…,w(n)},首先將評論文本W中的詞w(i)利用Word2Vec轉化為對應的詞向量V(w(i)),并將詞w(i)組成的句子映射為句子矩陣Sij,其中Sij={V(w(1)),V(w(2)),…,V(w(i))},1≤i≤n。CNN將Sij作為卷積層的輸入,該卷積層用大小為r*k的濾波器對句子矩陣Sij進行卷積操作,提取Sij的局部語義特征,計算方法如式(11)所示:
cij=f(F·V(w(i:i+r-1))+b)
(11)
其中:F代表r*k的濾波器,f代表ReLU的非線性轉換,V(w(i:i+r-1))代表Sij中從i到i+r-1共r行詞向量,b代表偏置量,cij代表CNN提取的由i個詞組成的第j個句子的局部語義特征。

圖6 CNN提取情感特征模型Fig. 6 Emotional features model extracted by CNN
1.5 局部語義特征提取
文本情感特征提取流程如圖7所示。
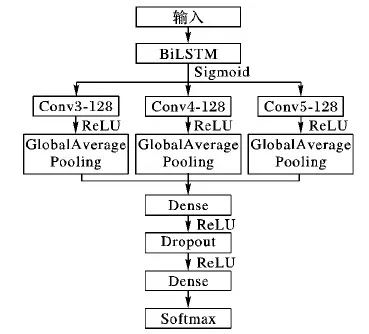
圖7 文本情感提取流程Fig. 7 Flowchart of text sentiment extraction
圖7所示流程解釋如下。
1)輸入層。使用文獻[18]中的數據集,對其包含的6個領域的評論文本進行預處理,并將處理后的評論文本進行詞匯向量化轉化,步驟如下:
a)對評論文本進行預處理操作,具體操作見1.1節。
b)使用Word2Vec對預處理后的評論文本進行文本詞匯向量化轉化。建立詞向量字典,使每一個文本詞匯唯一對應一個已訓練詞向量,其中,詞向量維度設置為100。將字典中沒有出現的文本詞匯的詞向量設置為0。
2)嵌入層。將文本詞匯中的詞向量進行拼接,生成句子級詞向量矩陣,生成式如(12)所示:
Sij=V(w(1))⊕V(w(2))⊕…⊕V(w(i))
(12)
其中:w(1),w(2),…,w(i)表示文本詞匯;V(w(1)),V(w(2)),…,V(w(i))表示文本詞匯對應的詞向量;Sij表示由i個詞向量拼接成的第j個句子詞向量矩陣;⊕表示詞向量的拼接操作。
3)BiLSTM。以Embedding層的句子矩陣Sij為BiLSTM層的輸入,設置隱層大小為128,激活函數為Sigmoid。將輸入序列分別從模型的兩個方向輸入,通過隱藏層提取文本的上文信息特征和文本的下文信息特征,最后,通過式(13)將兩個方向的隱層輸出進行拼接:
hijt=BiLSTM(sijt)
(13)
其中:Sijt表示在t時刻輸入的第j個句子的i個詞向量組成的句子矩陣;hijt表示在t時刻BiLSTM的輸出。
4)Conv。使用濾波器為3×100,4×100,5×100各128個CNN提取局部語義特征[11],并通過式(14)進行計算:
oijt=CNN(hijt)
(14)
其中:hijt表示在t時刻BiLSTM的輸出,oijt表示t時刻CNN的輸出。
CNN中激活函數使用ReLU,步長stride設置為1。利用全局平均池化對卷積層的輸出矩陣進行降維,使用Keras中的concatenate()方法對CNN中不同卷積核提取的局部語義特征進行融合,最后使用全連接層進行連接。
5)輸出。通過Softmax函數進行文本情感分類,分類函數如式(15)所示:
yi=softmax(widijt+bi)
(15)
其中:wi表示Dense層到輸出層的權重系數矩陣,bi表示相應的偏置,dijt表示在t時刻Dense層的輸出向量。
2 實驗與結果分析
2.1 實驗環境
構建操作系統為64位Windows 7,英特爾core i7- 5500u 2.40 GHz雙核CPU,8 GB內存,開發環境為Keras,開發工具為JetBrains PyCharm,開發語言為Python的實驗環境。
2.2 實驗數據集
實驗選用文獻[15]中的數據集,該數據集包含兩萬多條中文標注語料,覆蓋書店、酒店和電腦商城等6個領域的評論,共21 105條,取6個領域的部分樣例如表1所示。

表1 數據集部分樣例 Tab. 1 Some examples in the dataset
2.3 評價標準
為驗證模型在文本情感分析的性能,使用準確率(Precision)、召回率(Recall)和F-measure[26],計算式如式(16)~(18)所示:
(16)
(17)
(18)
其中:TP(True Positive)表示積極情感預測為積極情感的數量,FP(False Positive)表示消極情感預測為積極情感的數量,FN(False Negative)表示積極情感預測為消極情感的數量。
2.4 超參數選擇
由于實驗參數的設定對實驗結果的影響比較大,實驗采用參數固定法,詞向量分別取100維、200維;CNN隱層節點數分別取32、64和128;BiLSTM隱層節點數分別取64、128和256,進行多次實驗。實驗中選用Adam作為優化函數,選用交叉熵作為損失函數。通過對比多次實驗的結果,發現當取表2參數時,BiLSTM-CNN串行混合模型的分類效果最好。

表2 模型參數設置 Tab. 2 Model parameter setting
為增強模型泛化能力,在CNN和全連接層之間加入Dropout層,如圖8所示,Dropout不同的取值會影響模型輸出的準確率,當Dropout取值為50%時,準確率最高。
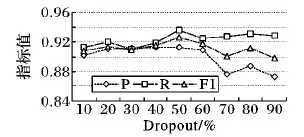
圖8 Dropout曲線Fig. 8 Dropout curve
Word2Vec向量化工具通過設置Window_size的大小來實現文本詞匯的語義理解,Window_size過大或過小都會引起文本情感分析效果不佳等問題。通過設置Window_size的大小分別為1,2,…,10進行對比實驗,結果如圖9所示,當Window_size取值為7時,綜合評價指標F1達到全局最優。
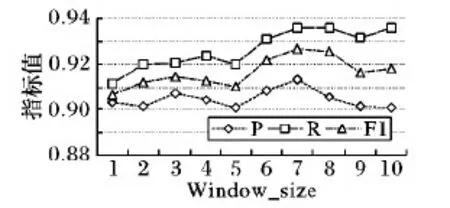
圖9 Window_size曲線Fig. 9 Window_size curve
2.5 模型性能比較
為驗證本文文本情感分析方法的有效性,在相同的實驗環境下使用包含6個領域的評論文本作為實驗數據。首先,利用Word2Vec向量化工具將評論文本轉化成實數向量,其次,分別構造單一的Word2Vec-CNN、Word2Vec-LSTM、Word2Vec-BiLSTM情感分析算法模型以及本文情感分析算法模型,最后,進行實驗對比,實驗結果如表3所示。

表3 所提模型與單一模型的性能比較 Tab. 3 Comparison of the proposed model and single models in performance
由表3可知,本文文本情感分析算法模型在召回率和綜合評價指標F1方面,優于單一的CNN、LSTM和BiLSTM文本情感分析算法模型。在準確率方面,本文的文本情感分析算法模型優于單一的CNN和LSTM文本情感分析算法模型,與單一的BiLSTM文本情感分析算法模型準確率相當,且在綜合評價指標F1上,本文文本情感分析模型比單CNN、單LSTM和單BiLSTM文本情感分析模型分別提高了2.02個百分點、1.18個百分點和0.85個百分點。分析其原因,單CNN文本情感分析模型只考慮了局部語義特征對文本情感分析模型的影響,沒有考慮評論文本的上下文關系;單LSTM文本情感分析模型只考慮文本的下文信息,沒有考慮文本的上文信息以及局部語義特征對文本情感分析的影響;單BiLSTM文本情感分析模型充分考慮了上下文對文本情感分析的影響,但忽略了文本局部語義特征在文本情感分析的重要性。綜合考慮文本上下文和局部語義特征對文本情感分析的影響,本文所提的BiLSTM-CNN串行混合模型的文本情感分析算法明顯優于其他三種單一的文本情感分析算法。
2.6 同類相關工作對比
在相同的實驗環境下,使用包含6個領域的評論文本作為實驗數據。首先對數據預處理后的評論文本使用Word2Vec文本詞匯向量化工具將評論文本詞匯轉化成含有語義信息的實數向量;然后將詞向量矩陣分別作為LSTM-CNN模型、BiLSTM-CNN并行特征融合模型和本文模型的輸入;最后分別按照如下方式構造LSTM-CNN[27]、BiLSTM-CNN并行特征融合模型[28]和本文模型。
1)LSTM-CNN模型[27]:首先采用LSTM提取前向文本特征,然后使用CNN提取局部語義特征,最后由Softmax層對文本進行情感分析。
2)BiLSTM-CNN并行特征融合模型[28]:首先利用BiLSTM和CNN分別提取文本上下文特征和提取局部語義特征,然后將分別提取的上下文特征和局部語義特征進行融合,最后由Softmax層對文本進行情感分析。
3)本文模型:首先使用BiLSTM提取文本上下文特征,然后利用不同卷積核的CNN對已提取的上下文特征進行局部語義特征提取,最后由Softmax對文本進行情感分析。
由表4可知,本文模型在準確率、召回率和綜合評價指標F1方面,均優于LSTM-CNN模型和BiLSTM-CNN并行特征融合模型,且本文文本情感分析模型相比LSTM-CNN模型和BiLSTM-CNN并行融合模型在綜合評價指標F1上分別提高了1.86和0.76個百分點。分析其原因:LSTM-CNN[27]忽略了文本的上文信息,因此在文本情感分析綜合評價指標上表現一般;BiLSTM-CNN并行特征融合模型[28]分別提取了上下文信息和局部語義特征并進行融合,在提取局部語義特征時忽略了上下文信息;而本文模型是先提取評論文本的上下文特征再對已提取的上下文特征使用CNN提取局部語義特征,綜合考慮了上下文信息和局部語義特征對文本情感分析的影響,得到了較好的結果。

表4 所提模型與混合模型的性能比較 Tab. 4 Comparison of the proposed model and hybrid models in performance
3 結語
本文提出一種基于BiLSTM-CNN串行混合模型用于文本情感分析研究。該模型充分利用BiLSTM和CNN模型的優勢,先使用BiLSTM對文本上下文特征進行提取,再利用不同卷積核的CNN對已提取的上下文信息進行局部語義特征提取,從而能夠更好地準確理解評論文本的語義信息。在包含6個領域的評論文本數據集上進行模型的訓練和測試,實驗結果表明,所提出的基于BiLSTM-CNN串行混合模型能夠更加準確地完成文本情感分析任務。
本文只是考慮了積極和消極二元文本情感分析,在接下來的工作中,將考慮多元文本情感分析,得出文本更為豐富的語義信息。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
