基于數據融合的CNN方法用于人體活動識別
2020-03-07 12:48:10韓欣欣周海英
計算機工程與設計 2020年2期
韓欣欣,葉 劍,周海英
(1.中北大學 大數據學院,山西 太原 030051;2.中國科學院計算技術研究所 泛在計算系統(tǒng)研究中心, 北京 100190;3.中國科學院計算技術研究所 移動計算與新型終端北京市重點實驗室,北京 100190)
0 引 言
借助與人體活動信息有關的傳感器、圖片或視頻來獲得活動的相關特征,從而解決人體活動識別(human activity recognition,HAR)問題。近年來,傳感器技術和處理傳感器數據的技術均取得了顯著的進步。在移動設備中嵌入小巧的、輕便的傳感器也變得普及,較大推動了研究熱點轉向借助傳感器數據解決HAR問題[1]。深度學習在圖像識別和語音識別方面的出色表現,促進了深度學習在基于傳感器的HAR的運用,且已有研究人員證明運用深度學習可以獲得較好性能[2,3]。
三軸加速度計是基于傳感器的HAR中較常使用的傳感器[4]。已有研究者發(fā)現軸之間的相關性能夠提高活動識別的準確率。例如,使用合成加速度來減少由于移動電話的不同放置位置引起的旋轉干擾[5,6]。排列傳感器數據以生成在一定程度上考慮了軸之間相關性的活動圖,通過將傳感器的時間序列信號轉換為包含軸間相關性的活動圖像,模型的識別準確率得到明顯提高[6,7]。然而,以上方法的提出依賴于研究者自身的知識和經驗,在一定程度上具有局限性。
本文的目的是減少存在的局限性同時更好地利用軸之間的相關性。因此基于數據融合的卷積神經網絡(convolutional neural network,CNN)方法在本文中被提出。該方法運用單通道數據融合方法獲得包含軸之間相關性的融合數據。然后將數據輸入到CNN中進行特征的提取和活動的分類。本文方法能有效利用軸之間的相關性并提高模型的分類準確率。本文使用WISDM公開數據集對網絡結構進行測試,實驗結果表明,提出的方法在準確率方面優(yōu)于CNN。
1 單通道數據融合方法
單通道數據融合方法如圖1所示。若傳感器的數據形如一張二維圖片,即其僅有一個通道,則將其視為單通道格式。本文使用的傳感器為三軸加速度計,將三軸加速度數據按行排列。圖1中的輸入層中的數據共有3行。本文提出的單通道數據融合方法是將按行排列的三軸數據利用 3×1 卷積進行融合,可看作是數據融合的操作。對三軸加速度數據進行數據融合操作,能夠得到形為(1,200,1)的融合數據。可根據需要對三軸加速度數據重復進行數據融合操作以得到相應個數的融合數據。如果融合數據的數量是n,說明執(zhí)行n次3×1卷積運算。
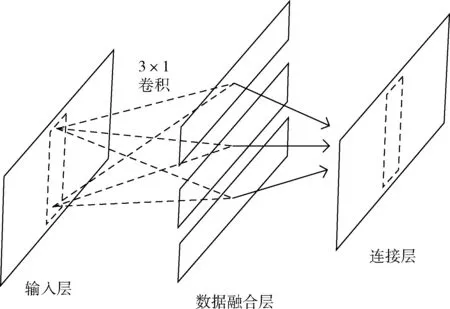
圖1 單通道數據融合方法
2 基于數據融合的CNN方法的實現
2.1 基于數據融合的CNN方法
本文提出的基于數據融合的CNN方法的總體流程如圖2 所示。首先通過單通道數據融合方法將加速度數據變?yōu)榘S之間相關性的融合數據。然后通過CNN對融合數據進行特征的提取和活動的分類。
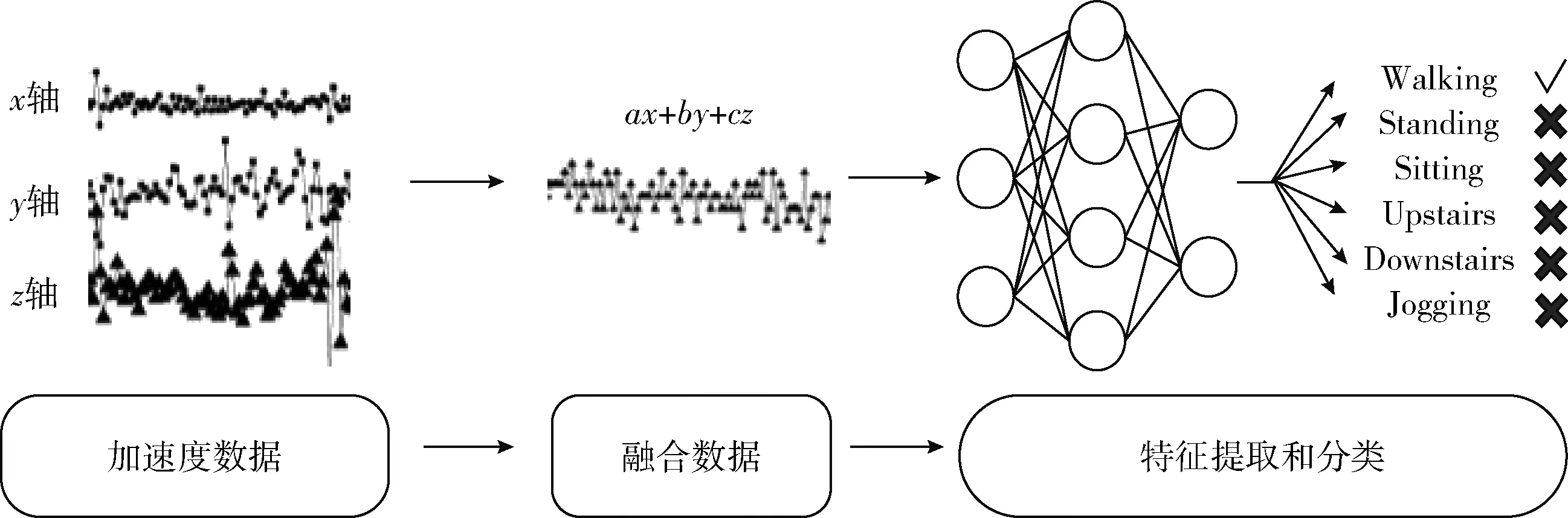
圖2 基于數據融合的CNN方法的總體流程
CNN包括卷積層、池化層、全連接層和Softmax層。卷積層的個數、池化層的位置、全連接層的大小等會導致網絡結構的不同,不同的網絡結構可能會得出不一樣的結果。CNN在人體活動識別領域得到了廣泛運用。如文獻[8]中作者提出了一個使用CNN實現的基于加速度計的人體活動識別方法,實驗結果表明其準確率高于支持向量機和深度信念網絡的準確率。
卷積層:卷積層的作用是提取特征。卷積層的特點有兩點:局部連接和權重共享。卷積層中的神經元與上一層特征圖中的局部區(qū)域相連接,卷積核和上一層中的局部區(qū)域執(zhí)行點積運算產生的輸出值是卷積層中的一個神經元。卷積的結果由等式(1)計算得到。對卷積的結果使用激活函數以向網絡中引入非線性。
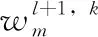
(1)
(2)
池化層:池化層結合了語義相似的特征,以在下一層中生成單個神經元[9]。平均池化選取輸入數據的局部區(qū)域的平均值作為輸出值傳遞到下一層。最大池化則是選取輸入數據的局部區(qū)域的最大值作為輸出值傳遞到下一層。
Softmax層:Softmax層的作用是將數據映射到 (0,1) 區(qū)間內以判斷最終結果的類別。因此解決分類問題時,Softmax層通常放在卷積層、池化層、全連接層的后面,即模型的最后。Softmax層中的神經元個數與分類任務中類別的個數相同。Softmax函數如等式(3)所示
(3)
CNN-DF(基于數據融合的CNN方法)如圖3所示。首先執(zhí)行數據融合操作以獲得包含軸之間相關性的融合數據。假設生成n個融合數據,每一個融合數據的大小均為(1,200,1)。對每一個融合數據分別進行卷積和池化操作以提取特征,其中卷積層的卷積核大小為1×7,卷積核的個數為50,池化層的步長為1。接下來的連接層將融合數據中提取到的特征逐行連接,生成的數據的通道數與池化層中數據的通道數一致。CNN中1維卷積核僅能考慮到數據的局部依賴性,2維卷積核與其相比還可以考慮到空間依賴性[10]。因此,對連接層的數據執(zhí)行n×7的卷積操作和池化操作。池化層的輸出數據經展平層將數據一維化后與Softmax層中的神經元連接,獲得輸出結果。
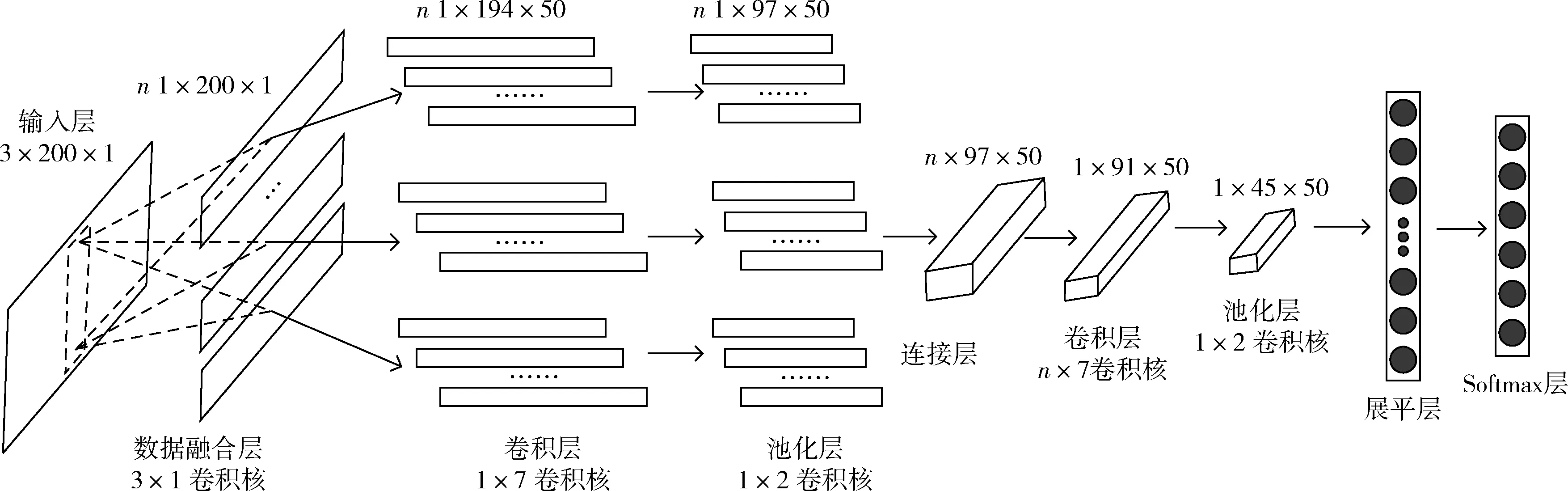
圖3 基于數據融合的CNN方法
2.2 學習率控制方法
Learning Rate Schedule:在對分類準確率有一定影響的超參數中,學習率是最重要的超參數之一。若設定的學習率太大,那么損失曲線可能存在一定范圍的波動甚至上升。若設定的學習率太小,可能導致所需的實驗的迭代次數較多。本文使用根據迭代次數動態(tài)變化的學習率。先在訓練伊始將學習率設定為相對較大值,使得模型的準確率能夠在較短時間內收斂到理想狀態(tài)。然而損失和準確率曲線可能會有一定的大幅波動。于是在訓練的中間階段將學習率減小,使得模型繼續(xù)學習有用信息且曲線的波動幅度變小。在訓練的后期階段,學習率進一步減小,曲線的波動幅度繼續(xù)變小。該方法能夠加快模型的訓練速度、降低過擬合程度和減少實驗的迭代次數。
2.3 實現算法
算法1展示了實現本文提出的方法的偽代碼。在本文中,形如(1,200,1)的融合數據個數和數據融合層中的 3×1 卷積核的個數相同。
算法1:基于數據融合的卷積神經網絡方法
注釋:
NC:融合數據的數量
輸入:標簽數據集 {(xi,yi,zi),ai}, 無標簽數據集 {(xi,yi,zi)}
輸出:無標簽數據集的活動標簽
重復
前向傳播:
i←1
for每個標簽數據 (x,y,z) do
whilei≤Ncdo
使用等式(1)對輸入數據執(zhí)行數據融合操作
使用等式(1)和式(2)對融合數據執(zhí)行卷積操作
對卷積層的輸出執(zhí)行最大池化操作
i=i+1
end while
逐行連接池化層的輸出數據
使用等式(1)和式(2)對連接層的數據執(zhí)行卷積操作
對卷積層的輸出執(zhí)行最大池化操作
end for
使用等式(3)進行分類
反向傳播:
使用隨機梯度下降算法執(zhí)行反向傳播
直到權重收斂;
for每個無標簽數據 (x,y,z) do
使用訓練好的網絡預測活動標簽
end for
2.4 CNN-DF與CNN的比較
本節(jié)比較CNN-DF與CNN中第一個卷積層的輸出值之間的差異。圖4和圖5分別展現了兩種方法從輸入層到卷積層的變化過程。在圖4和圖5中,輸入層中的虛線框代表卷積核,卷積層中的虛線框表示卷積運算的輸出值。為了簡化等式,在本節(jié)中不考慮偏置項。
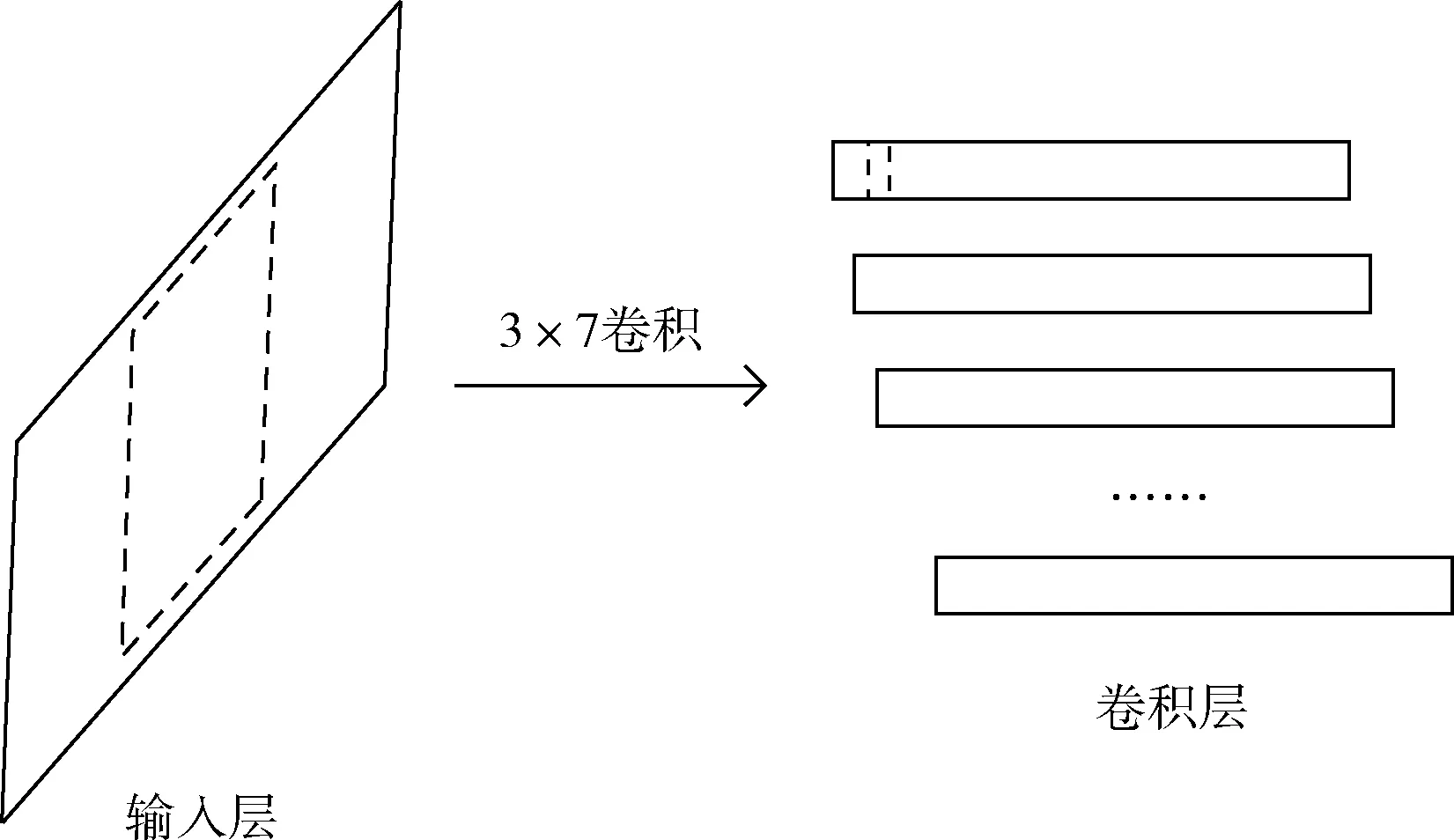
圖4 CNN的輸入層和卷積層
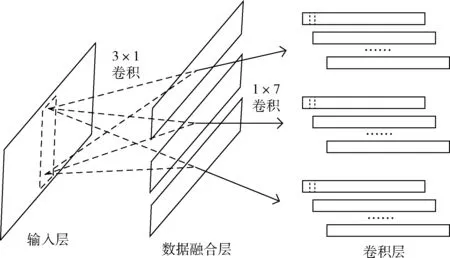
圖5 CNN-DF的輸入層,數據融合層,連接層和卷積層
對于圖4,將 [[x1,x2,x3,x4,x5,x6,x7], [y1,y2,y3,y4,y5,y6,y7], [z1,z2,z3,z4,z5,z6,z7]] 設為CNN的輸入層的數據。則相應的將卷積核設為 [[a1,a2,a3,a4,a5,a6,a7], [b1,b2,b3,b4,b5,b6,b7], [c1,c2,c3,c4,c5,c6,c7]]。 輸出值可以根據等式(4)計算得到
(4)
對于圖5,3×1卷積用于融合三軸加速度數據。在本節(jié)為了進行比較分析,將融合數據的數量設置為3。對有3行n列的數據進行3×1卷積時,會生成形為1行n列的數據。執(zhí)行n次3×1卷積將會生成n個形為1行n列的數據。將數據融合層的卷積核設為 [[a1],[b1],[c1]],[[a2],[b2],[c2]],[[a3],[b3],[c3]]。 等式(5)中的fd_output為輸入數據在經過卷積操作后的輸出值,等式中的i=1,2,3
fd_output=xai+ybi+zci
(5)
對數據融合層的每行數據分別進行卷積操作,卷積核的大小為1×7。將卷積層的卷積核設為 [f1,f2,f3,f4,f5,f6,f7]。 其結果由等式(6)計算得到
(6)
比較等式(4)和等式(6),可以發(fā)現等式(6)中多了參數fi, 卷積核大小為1×7則意味著有7個參數f。 因此,等式(6)的輸出具有更多的可能性,意味著CNN加入單通道數據融合方法后比不使用數據融合方法的CNN可以提取到更多的有用信息。
3 實驗及結果分析
在實驗中使用隨機梯度下降算法訓練活動識別模型。使用10折交叉驗證(CV)方法來評估提出的方法。若實驗迭代的次數小于375次時,將學習率的大小設置為0.005。若實驗迭代的次數超過375次時,將學習率的大小設置為0.001。表1展現了實驗設置的參數值。
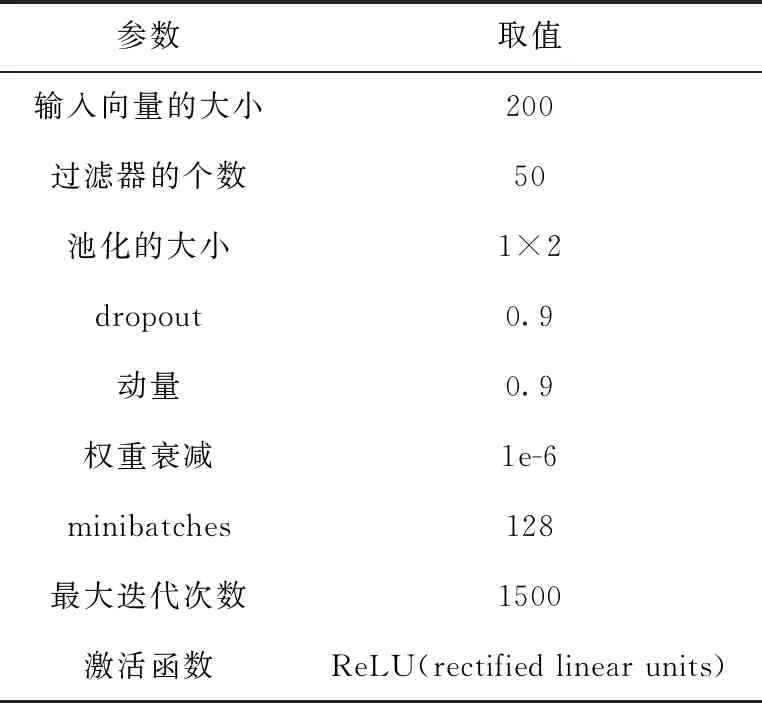
表1 實驗的具體參數值
3.1 實驗數據集
WISDM Actitracker數據集被用來對本文提出的方法進行測試。該數據集中共有1 098 213個樣本,這些樣本來自于29個用戶。實驗數據集中包括走路、慢跑、上樓梯、下樓梯、坐著和站立這6種活動。采樣率為20 Hz。
3.2 數據預處理
對原始數據進行標準化是本文預處理數據的方法。Z標準化(zero-mena normalization)利用數據的兩個特征值:平均值、標準差來對數據進行預處理,為普遍運用的標準化技術。使用Z標準化處理數據的結果可通過等式(7)計算得到
(7)
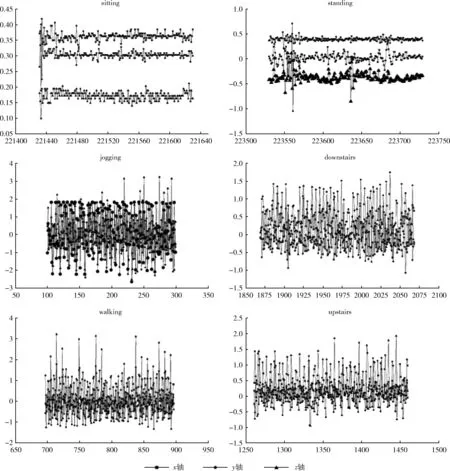
圖6 標準化后每個活動的三軸加速度數據
3.3 融合數據數量的影響
在本節(jié)中,為了公正地比較模型的準確率,過濾器的個數被設定為50。全部實驗中的過濾器個數不再改變。融合數據的多少會對模型的最終結果造成一定的影響。太少的融合數據可能使得其本身不含有充分的有效信息。相反,如果數量太多,可能會導致部分數據冗余并增加參數數量,甚至會出現過擬合或準確率下降的情況。
圖7顯示了增加融合數據的數量對CNN-DF準確率的影響。當融合數據的數量為1時,模型的準確率為96.36%是曲線的最低點,表明1個融合數據中所含有的有效信息太少。融合數據的數量從1增加到4時,模型的準確率從96.36%增加到98.69%,其中數量從1增加到2時準確率增幅最大。當融合數據的數量為6時,模型的準確率為98.80%是曲線的最高點。融合數據的數量從6增加到10時,曲線略微波動下降,最終下降至98.58%。融合數據的數量的連續(xù)增加不一定會導致準確率的增加,但會增加參數的數量,這可能導致過擬合。

圖7 擁有不同數量融合數據的模型準確率的比較
3.4 與CNN的比較
基于數據融合的CNN方法是在CNN之前加了數據融合階段,那么將該方法與CNN進行比較,可以判斷數據融合階段對模型的分類準確率是否有影響。本節(jié)對CNN和CNN-DF從兩點進行比較:準確率和不同數量的訓練數據對模型準確率的影響。
CNN和CNN-DF兩個模型的準確率見表2。從表2中可以看出,使用單通道數據融合方法的CNN-DF準確率達到98.80%,比CNN的準確率98.60%高0.20個百分點。CNN-DF和CNN中均使用了考慮到空間依賴性的二維卷積核,因此CNN-DF準確率的提高是由于使用了包含軸之間相關性的融合數據。

表2 模型的準確率比較
不同數量的訓練數據對模型準確率的影響如圖8所示。在圖8中,CNN-DF的曲線保持在CNN的曲線之上,無論訓練數據的數量是多少,CNN-DF的準確率始終比CNN的準確率高。結果表明,使用單通道數據融合方法能夠提高模型的準確率。
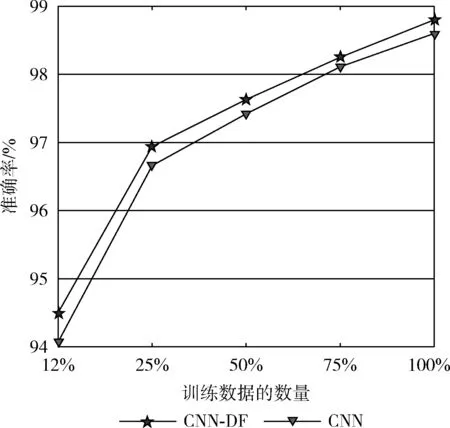
圖8 模型在不同數量訓練數據情況下的準確率的比較
3.5 與現有方法的準確率比較
為了驗證提出的方法的有效性,本文將其與一些現有方法進行比較。結果見表3。在文獻[11]中一種分類器方法集合即J48、邏輯回歸和多層感知器算法的集合被提出,通過實驗驗證了該方法與上述3種算法相比其性能更好。文獻[12]中的結果表明,深模型可以有效地提高準確率,而不需要對特征進行手工設計。在文獻[13]中發(fā)現資源限制和簡單的設計方法可能使得淺層特征比通過深度學習方法提取到的特征具有更強的判別性。文獻[13]的作者提出將淺層特征和深度學習特征相結合并與僅使用深度特征的文獻[14]中的方法對比,發(fā)現兩種特征相結合的方法的準確率更高達到了98.60%。CNN-DF不是根據人類領域知識去手動的提取特征,而是使用CNN進行特征提取和分類,這與上述方法不同。

表3 提出的方法與現有方法的比較
表3通過與現有方法進行比較,發(fā)現基于數據融合的CNN方法將準確率提高了0.20個百分點。提出的方法實現了最高準確率,這表明它是解決HAR問題的有效方法。
圖9為提出的方法的分類結果。將CNN-DF與表3中準確率最高的方法進行對比。表4展現了CNN-DF與Ravì et al[13]的活動的分類結果,表中的最后一行是兩種方法之間的準確率差值。該準確率差值清楚地表明了哪種方法實現了更高的準確率,哪種活動的準確率提高得更明顯。觀察表4能夠看出坐著和站立的準確率提高的最多,分別為1.49%和1.43%。對于下樓梯,提出的方法的準確率達到了95.51%,相較Ravì et al[13]提高了1.07%。而對于慢跑、上樓梯和走路來說,這3種活動的準確率提升幅度較小僅為0.12%、0.20%和0.16%。觀察圖6能夠看出站著和坐立的3條曲線較為獨立相交部分較少。慢跑、走路和上樓梯的3條曲線在圖中相交部分較多,數據的分布較為密集。當活動的x軸、y軸和z軸曲線相交部分較少即數據的差異較明顯時,其識別準確率將有明顯提高;而當活動的x軸、y軸和z軸曲線相交部分較多時,其識別準確率僅有小幅提升。本文提出的CNN-DF適用于解決人體活動識別問題,更適用于解決三軸加速度數據差異較大的活動識別問題。
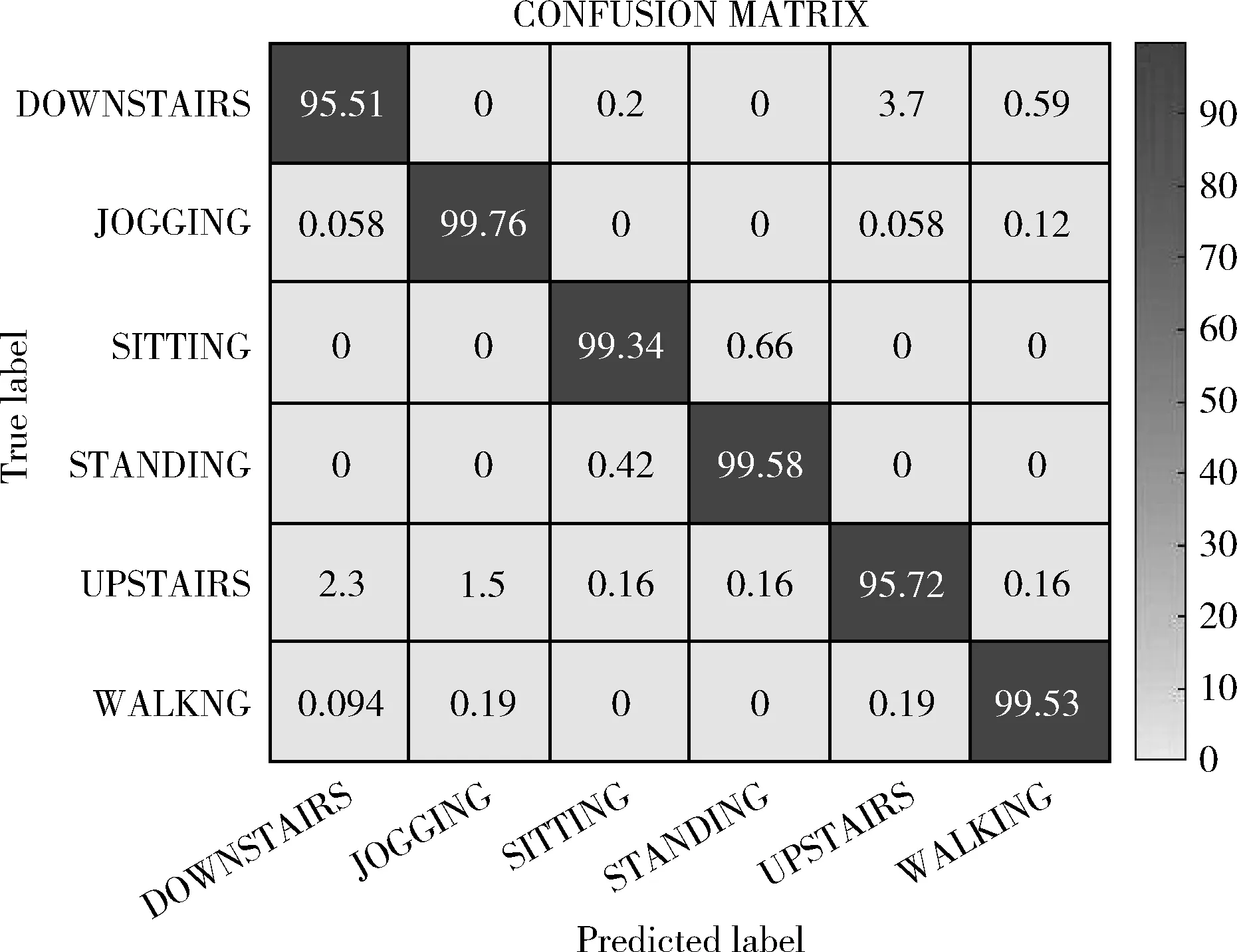
圖9 提出的方法的混淆矩陣

表4 提出的方法與表3中準確率最高的方法的比較
4 結束語
在本文中,我們提出了一種基于數據融合的CNN方法,主要包括兩個階段,數據融合階段和CNN階段。所提出的方法旨在充分利用傳感器內軸之間的相關性來提高模型的準確率。結果表明提出的方法是有效的,該方法的準確率高于CNN的準確率。進一步分析該方法可以發(fā)現其適用于解決三軸數據差異較大的活動識別問題。本文研究了在使用單一傳感器的情況下如何通過借助軸之間的相關性來對模型的準確率做出改善。在更加復雜的應用場景下如何同時使用多個傳感器,如何更好地利用軸之間的相關性仍是一個值得探索的問題。
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
今日農業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年2期)2021-08-22 07:31:10
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
海峽姐妹(2018年3期)2018-05-09 08:20:40
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
