基于深度學(xué)習(xí)的視覺SLAM回環(huán)檢測(cè)方法
2020-03-07 12:48:12余宇,胡峰
計(jì)算機(jī)工程與設(shè)計(jì) 2020年2期
余 宇,胡 峰
(重慶郵電大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,重慶 400065)
0 引 言
同步定位與建圖(simultaneous localization and mapping,SLAM)[1]自提出以來(lái),一直是機(jī)器人領(lǐng)域的重要研究?jī)?nèi)容,其主要目的是實(shí)現(xiàn)運(yùn)動(dòng)物體在陌生環(huán)境中自身定位及增量式的地圖構(gòu)建。進(jìn)入2000年以后,隨著計(jì)算性能的提高,主流的SLAM系統(tǒng)多采取攝像頭作為傳感器,這種基于視覺圖像信息來(lái)感受周圍環(huán)境的SLAM系統(tǒng)稱為視覺SLAM[2]。其系統(tǒng)核心功能被分為3個(gè)獨(dú)立的模塊,分別是前端視覺里程計(jì)、回環(huán)檢測(cè)和后端優(yōu)化。前端視覺里程計(jì)部分主要利用幀間的多視幾何關(guān)系計(jì)算出自身姿態(tài)變化,而后端優(yōu)化主要解決的問題是消除整個(gè)系統(tǒng)中由于各種原因產(chǎn)生的噪聲對(duì)位姿估計(jì)和建圖的影響。在視覺SLAM系統(tǒng)長(zhǎng)時(shí)間的自主導(dǎo)航運(yùn)行中,不可避免的會(huì)因?yàn)猷徑鼛g的誤差積累導(dǎo)致后端的優(yōu)化收斂出現(xiàn)嚴(yán)重的偏差,這樣的偏差在建圖過程中會(huì)反映為漂移。因此,在視覺SLAM系統(tǒng)中引入了回環(huán)檢測(cè)模塊,用于消除累計(jì)誤差,控制建圖的全局一致性。
1 相關(guān)工作
傳統(tǒng)的回環(huán)檢測(cè)方法分為兩種。一種是基于視覺里程計(jì)的方法,這種方法是利用視覺里程計(jì)中的幾何關(guān)系,假設(shè)相機(jī)回到了之前的位置,再進(jìn)行是否構(gòu)成回環(huán)的判斷,但由于視覺里程計(jì)自身存在偏移誤差,這種判斷邏輯準(zhǔn)確性較低,誤差較大[3]。另外一種方法是基于視覺圖像的方法[4,5],根據(jù)幀間相似性來(lái)判斷回環(huán),把回環(huán)檢測(cè)問題歸納成為一個(gè)場(chǎng)景識(shí)別問題。其主要思路是通過前端攝像頭獲取到場(chǎng)景影像數(shù)據(jù),運(yùn)用計(jì)算機(jī)視覺的方法來(lái)計(jì)算圖像間的相似性,從而判斷回環(huán)。因?yàn)槟軌蛴行У脑诓煌h(huán)境中工作,這一方法自21世紀(jì)初被提出以來(lái),已經(jīng)成為視覺SLAM研究中的重點(diǎn)。
基于視覺圖像方法的核心問題是如何計(jì)算圖像間的相似性,現(xiàn)階段較常使用方法是在圖像中標(biāo)定人工設(shè)計(jì)的關(guān)鍵點(diǎn),然后進(jìn)行特征描述子之間的相似度計(jì)算。在FAB-MAP[6]中使用了SIFT(scale-invariant feature transform)算法提取圖像特征,然后通過構(gòu)建視覺詞袋模型(bag of visual word,BoVW)進(jìn)行回環(huán)檢測(cè),因?yàn)樵陟o態(tài)環(huán)境中的較高準(zhǔn)確率得到了廣泛應(yīng)用。而在ORB-SLAM[7]的回環(huán)檢測(cè)模塊中使用了FAST算法提取圖像關(guān)鍵點(diǎn),BRIEF算法作為特征描述子,同樣通過構(gòu)建BoVW進(jìn)行回環(huán)檢測(cè),因?yàn)槠淇焖俚膱D像特征提取速度,在實(shí)時(shí)性要求比較高的視覺SLAM系統(tǒng)中得到廣泛使用。Sünderhauf等[8]提出了使用GIST算法提取圖像特征,改進(jìn)的BRIEF算法作為特征描述子的回環(huán)檢測(cè)方法,該方法對(duì)圖像進(jìn)行全局特征提取,提高了有效回環(huán)的檢測(cè)率。但在回環(huán)檢測(cè)中無(wú)論是對(duì)圖像進(jìn)行全局特征提取還是局部特征提取,都是基于設(shè)計(jì)算法人員的人為經(jīng)驗(yàn),當(dāng)在現(xiàn)實(shí)環(huán)境中面對(duì)光照變化,天氣變化,季節(jié)變換等情況時(shí)會(huì)出現(xiàn)準(zhǔn)確率下降,不能夠穩(wěn)定的工作。而在實(shí)際場(chǎng)景中當(dāng)圖像劇烈變化時(shí),會(huì)出現(xiàn)視覺單詞無(wú)法匹配和旋轉(zhuǎn)不變性較差等問題。
近年來(lái),深度學(xué)習(xí)方法在計(jì)算機(jī)視覺方面的研究得到飛速發(fā)展,在圖像分類、圖像檢測(cè)、圖像分割等領(lǐng)域都取得了極大的成功,視覺SLAM系統(tǒng)的研究也開始嘗試和深度學(xué)習(xí)進(jìn)行結(jié)合。Konda和Memisevic[9]提出了一個(gè)端到端的卷積神經(jīng)網(wǎng)絡(luò)用于視覺里程計(jì)中,在實(shí)際環(huán)境中可以有效預(yù)測(cè)攝像機(jī)方向和速度的變化。Costante等[10]發(fā)現(xiàn)在圖像發(fā)生了光照變化和運(yùn)動(dòng)模糊的情況下,利用卷積神經(jīng)網(wǎng)絡(luò)能夠有效地進(jìn)行幀間估計(jì)確定位姿。Sünderhauf等[11]提出的利用物體對(duì)象進(jìn)行語(yǔ)義地圖的構(gòu)建方法中,使用了SSD卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行關(guān)鍵幀的物體檢測(cè),構(gòu)造出了信息更豐富的語(yǔ)義地圖。McCormac等[12]在提出的基于卷積神經(jīng)網(wǎng)絡(luò)的稠密三維地圖的構(gòu)建中,使用了卷積神經(jīng)網(wǎng)絡(luò)對(duì)生成的2D場(chǎng)景進(jìn)行物體分類,構(gòu)建出具有物體對(duì)象標(biāo)簽的地圖。在將深度學(xué)習(xí)的方法應(yīng)用到回環(huán)檢測(cè)方面,Chen等提出基于CNN(convolutional neural network)的回環(huán)檢測(cè)算法[13],在數(shù)據(jù)集上顯著提升了召回率。在實(shí)際運(yùn)行中,面對(duì)攝像頭所捕捉到的圖像場(chǎng)景光照變化和角度變形,導(dǎo)致回環(huán)檢測(cè)準(zhǔn)確率急速下降的問題時(shí),Xia等[14]提出基于AlexNet模型進(jìn)行特征提取然后使用SVM算法進(jìn)行二次訓(xùn)練的回環(huán)檢測(cè)模型,相比人工設(shè)計(jì)特征的算法具有更好的魯棒性。Gao等[15]通過非監(jiān)督學(xué)習(xí)中的自編碼(Autoencoder)算法提取圖像特征后,使用相似度矩陣作為度量方式進(jìn)行回環(huán)檢測(cè),在數(shù)據(jù)集上取得較好成績(jī)。雖然以上方法在和傳統(tǒng)人工設(shè)計(jì)特征相比都具有更高的準(zhǔn)確率和更強(qiáng)的魯棒性,但是都會(huì)出現(xiàn)過高維度的特征向量增加了計(jì)算復(fù)雜度,龐大的神經(jīng)網(wǎng)絡(luò)訓(xùn)練不適合應(yīng)用在常搭載SLAM系統(tǒng)的移動(dòng)平臺(tái),不適合的神經(jīng)網(wǎng)絡(luò)模型應(yīng)用在回環(huán)檢測(cè)中容易形成過擬合等問題。
2 基于深度學(xué)習(xí)的回環(huán)檢測(cè)算法
面對(duì)以上出現(xiàn)的問題,我們提出了基于深度學(xué)習(xí)的回環(huán)檢測(cè)算法。算法整體分為兩個(gè)部分(如圖1所示),基于卷積神經(jīng)網(wǎng)絡(luò)VGG-19[16]的圖像特征向量集構(gòu)造和基于局部敏感哈希(locality sensitive hashing,LSH)[17]算法的快速回環(huán)檢測(cè)。在第一個(gè)部分,我們通過VGG-19對(duì)圖像集進(jìn)行整體特征提取并構(gòu)造對(duì)應(yīng)特征向量矩陣,解決了人工設(shè)計(jì)的特征提取算法在回環(huán)檢測(cè)中面對(duì)光照和角度變化時(shí)準(zhǔn)確率下降問題。在第二個(gè)部分,我們提出基于余弦距離的LSH算法對(duì)構(gòu)造的特征向量矩陣進(jìn)行降維聚類,加速回環(huán)檢測(cè)識(shí)別,解決了高緯度的特征向量引起的計(jì)算性能開銷過大無(wú)法快速檢測(cè)回環(huán)的問題。

圖1 特征向量矩陣的構(gòu)造和LSH算法聚類過程
2.1 基于VGG-19的圖像特征向量集構(gòu)造
在圖像特征提取時(shí)選擇不同的算法會(huì)直接影響最終回環(huán)檢測(cè)的效果,而預(yù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)VGG-19在圖像特征提取上具有良好的特征表述能力與可操作性。在2014年的ILSVRC大賽中VGG-19使用了預(yù)訓(xùn)練的VGG-11參數(shù)做初始化,在圖像分類和定位項(xiàng)目上取得了優(yōu)異的成績(jī),說明在圖像任務(wù)中直接使用預(yù)訓(xùn)練的VGG-19具有較高增益。此外,VGG-19中使用了3*3的小卷積核來(lái)代替常見的大卷積核,更多的小卷積核的使用可以使決策函數(shù)在進(jìn)行特征辨別的時(shí)候更準(zhǔn)確,有效避免大卷積核對(duì)于圖像部分特征會(huì)出現(xiàn)多次卷積導(dǎo)致提取困難的情況,對(duì)于圖像的細(xì)節(jié)特征描述也會(huì)更加精確。因此,我們選擇了在ImageNet數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)VGG-19作為圖像特征提取的網(wǎng)絡(luò)結(jié)構(gòu)。
VGG-19一共擁有5個(gè)卷積層模塊和3個(gè)全連接層,因?yàn)镕C8層是為了比賽中圖像分類目的作輸出層所以不考慮作為特征提取層。對(duì)于其余卷積層和全連接層,我們?cè)诓煌瑪?shù)據(jù)集下作了效果比較(包括一個(gè)池化層)。如圖2所示,Conv1層提取特征過于粗糙不具有蘊(yùn)含圖像全局信息能力;Conv3層提取特征向量維度過高不適宜后續(xù)運(yùn)算;而FC7層提取特征稀疏性較好,特征向量維度適中且能夠?qū)D像做較好的區(qū)分,最終選擇了FC7層的輸出向量作為圖像特征表示。

圖2 VGG-19不同中間層的圖像特征效果
我們改變了VGG-19的輸出結(jié)構(gòu),使其能夠在前向傳播過程中直接輸出指定層的圖像特征向量。以輸入單張三通道圖像fi為例,首先我們會(huì)對(duì)圖像進(jìn)行去均值標(biāo)準(zhǔn)化處理
(1)
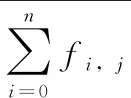
al=σ(zl)=σ(al-1*Wl+bl)
(2)
ReLU(x)=max(0,x)
(3)
其中,上標(biāo)l代表當(dāng)前層數(shù),al代表第l層的輸出,*代表卷積,W代表卷積核,b代表偏置量,σ(·) 代表了使用的激活函數(shù)ReLU。同時(shí),在每個(gè)卷積層的后面會(huì)接一個(gè)最大池化層,可以有效提高感受野大小,池化層的前向傳播方式是
S=βdown(C)+b
(4)
其中,β和b為標(biāo)量, down(C)表示對(duì)輸入的矩陣C進(jìn)行下采樣。在網(wǎng)絡(luò)末端有FC6和FC7作為全連接層,對(duì)隱藏層學(xué)到的分布式特征進(jìn)行映射,使用卷積核進(jìn)行全層卷積實(shí)現(xiàn)
(5)
同時(shí),為了加快圖像特征的提取,我們對(duì)VGG-19的BATCH做了調(diào)整,對(duì)于一次性輸入的k張圖像,能夠在前向傳播到FC7層時(shí)直接輸出一個(gè) (k,4096) 的特征矩陣M
(6)
2.2 基于余弦距離的局部敏感哈希算法
局部敏感哈希是一種用于高維空間數(shù)據(jù)向低維空間映射的最近鄰查詢算法。不同于一般的哈希算法,該算法的主要目的是讓在高維空間內(nèi)相似度高的數(shù)據(jù)通過特定的Hash函數(shù),能夠映射為同一個(gè)Hash值,在網(wǎng)頁(yè)去重、圖像和視頻檢索、聚類搜索等領(lǐng)域均取得了比較好的應(yīng)用效果。
首先在度量空間Μ=(M,d) 內(nèi)定義一個(gè)LSH函數(shù)簇F={h∶M→S}, 同時(shí)定義距離閾值R>1和σ>1, 對(duì)于任意兩點(diǎn)p,q∈Μ有
ifd(p,q)≤RthenPRh(h(p)=h(q))≥P1
(7)
ifd(p,q)≥σRthenPRh(h(p)=h(q))≤P2
(8)
其中,函數(shù)d(p,q) 表示向量之間的度量,PRh表示概率,當(dāng)P1>P2時(shí),我們就把這樣的一個(gè)LSH函數(shù)簇F稱為是 (R,σR,P1,P2) 敏感的。對(duì)于不同的度量方式我們可以確定不同的LSH函數(shù)簇,在本文中我們采用隨機(jī)超平面的思想[18],把基于余弦距離的LSH函數(shù)簇應(yīng)用在了回環(huán)檢測(cè)上。
我們先定義了特征向量之間的余弦距離度量,其中Α,Β分別為兩張圖像的特征向量,Αi,Βi分別代表向量Α,Β的各分量
(9)
在高維空間中對(duì)于任意兩個(gè)特征向量A,B∈Μ均存在被一隨機(jī)超平面分割為可能的3種情形(如圖3所示)。
基于此,我們可以構(gòu)造在歐幾里得空間內(nèi)基于余弦距離度量的LSH函數(shù)hμ
(10)
其中,v表示我們的圖像特征向量,μ表示生成的隨機(jī)超平面。對(duì)于v中的任意兩向量v1,v2都存在θ1,θ2。 在θ1<θ2的情況下,當(dāng)v1,v2兩向量的夾角小于θ1時(shí)有
(11)
當(dāng)v1,v2兩向量的夾角大于θ2時(shí)有
(12)
那么我們便可以把式(10)中的hμ稱為在余弦距離度量下 (θ1,θ2,(π-θ1)/π,(π-θ2)/π) 敏感的,將其應(yīng)用在回環(huán)檢測(cè)策略中便可以大幅度降低匹配所需查詢時(shí)間。
2.3 基于LSH算法的回環(huán)檢測(cè)策略
如果直接采用式(10)對(duì)HashTable進(jìn)行構(gòu)造,往往會(huì)出現(xiàn)待匹配向量查詢范圍窄和聚類區(qū)分度不夠等問題,進(jìn)而導(dǎo)致FalsePositive和FalseNegative增加。我們?yōu)榱诉M(jìn)一步提高LSH算法聚類的準(zhǔn)確性和回環(huán)檢測(cè)的性能,可以使用“AND”和“OR”兩種策略來(lái)對(duì)式(7)和式(8)中的P1,P2進(jìn)行調(diào)整。“AND”策略指的是通過增加超平面的方法,對(duì)于空間中的任意兩個(gè)向量v1,v2, LSH函數(shù)簇F={h1,h2,h3…h(huán)l}, 當(dāng)且僅當(dāng)每一個(gè)hn(v1)=hn(v2){n=1,2…l} 時(shí),才有h(v1)=h(v2)。 通過這種策略使P1,P2變?yōu)镻1l,P2l, 減小了FalsePositive的情況。“OR”策略指的是在函數(shù)簇F={h1,h2,h3……h(huán)l} 中只要存在任意一個(gè)hn(v1)=hn(v2){n=1,2…l} 時(shí),便有h(v1)=h(v2), 通常是以增加映射以后的HashTable實(shí)現(xiàn),假設(shè)增加以后HashTable數(shù)量為t, 則通過這種策略使P1,P2變?yōu)?-(1-P1)t, 1-(1-P2)t, 減小了FalseNegative的情況。
在本文中我們改進(jìn)了“OR”策略,并將改進(jìn)以后的“OR”策略與“AND”策略結(jié)合,以此增加待匹配圖像的搜索范圍,提高回環(huán)檢測(cè)的準(zhǔn)確率。我們首先定義了l為超平面的個(gè)數(shù),通過生成l個(gè)Hash函數(shù)構(gòu)成哈希函數(shù)簇F={hi|i=1,2,…l}, 然后對(duì)每一個(gè)特征向量ν進(jìn)行映射以后得到的一個(gè)l位的Signature(后文中以S表示)。最后把被映射為相同S的特征向量聚為一類并投射到同一個(gè)Bucket中,這樣的Bucket集合便構(gòu)成了我們的HashTable,具體步驟如下:
算法1:構(gòu)造HashTable算法
輸入:通過VGG-19提取的圖像特征向量矩陣:Μ={vi|i=1,2,…n}, 哈希函數(shù)簇:F={hi|i=1,2,…l}, 隨機(jī)超平面?zhèn)€數(shù):l。
輸出:HashTable集合T={bi|i=1,2,…m}。
步驟1 對(duì)每一個(gè)特征向量vi(i=1,2,…n), 通過哈希函數(shù)簇F進(jìn)行映射(由式(10)決定),得到每一個(gè)特征向量的l位S, 構(gòu)成集合Si(i=1,2,…n)。
步驟2 對(duì)集合Si(i=1,2,…n) 進(jìn)行聚類,相同的S生成一個(gè)Bucket,由此構(gòu)建了新的集合T={bi|i=1,2,…m}。
步驟3 返回T。
基于構(gòu)造的HashTable,我們?cè)诨丨h(huán)檢測(cè)的時(shí)候,對(duì)“OR”策略進(jìn)行了改進(jìn)。首先定義了一個(gè)偏移量γ, 然后對(duì)于任一待匹配的圖像,允許與有γ個(gè)位偏差的S所對(duì)應(yīng)的特征向量進(jìn)行余弦距離比較(由式(9)決定),具體步驟如下:
算法2:回環(huán)檢測(cè)算法
輸入:待匹配的圖像:f, 哈希函數(shù)簇:F={hi|i=1,2,…l} (注意,輸入的哈希函數(shù)簇應(yīng)保持和構(gòu)建Hash Table時(shí)一致),閾值:τ, 偏移量:γ。
步驟1 將f輸入到VGG-19中,經(jīng)過前向傳播算法得到對(duì)應(yīng)特征向量vf。
步驟2 將vf經(jīng)過哈希函數(shù)簇F映射得到對(duì)應(yīng)的Sf。
步驟3 在構(gòu)建的HashTable中,計(jì)算與Sf有γ個(gè)位偏差的所有可能映射,構(gòu)成待匹配集合V。
步驟4 對(duì)屬于集合V中的所有特征向量與vf進(jìn)行余弦相似度計(jì)算。

2.4 算法時(shí)間復(fù)雜度分析
如果單純使用暴力匹配方式計(jì)算所有特征向量之間的余弦距離,算法時(shí)間復(fù)雜度將達(dá)到O(n2)。 而我們?cè)跇?gòu)建HashTable的算法1中,時(shí)間復(fù)雜度為O(l*n), 其中,l是超平面?zhèn)€數(shù),n是特征向量矩陣中的向量個(gè)數(shù)。在回環(huán)檢測(cè)的算法2中,時(shí)間復(fù)雜度取決于集合V, 遠(yuǎn)小于數(shù)據(jù)集大小,可以近似為O(1), 有效降低了算法時(shí)間復(fù)雜度。如圖4所示,圖4(a)表明了HashTable的規(guī)模隨超平面增加基本呈線性增長(zhǎng),圖4(b)表明匹配耗時(shí)隨偏移量增加呈正態(tài)分布。
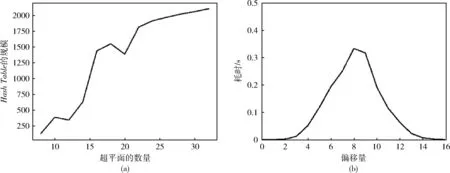
圖4 Hash Table的規(guī)模和匹配耗時(shí)隨偏移量增加的變化趨勢(shì)
3 實(shí)驗(yàn)結(jié)果與分析
3.1 實(shí)驗(yàn)數(shù)據(jù)集
在本文中我們使用了由牛津大學(xué)機(jī)器人團(tuán)隊(duì)收集的NewCollege和CityCentre兩個(gè)視覺SLAM回環(huán)檢測(cè)數(shù)據(jù)集,在數(shù)據(jù)集中分別包含2146張和2474張由移動(dòng)機(jī)器人在室外環(huán)境中采集的左右對(duì)圖像(如圖5所示),在數(shù)據(jù)集中下標(biāo)是奇數(shù)的為左攝像頭采集,偶數(shù)的為右攝像頭采集,圖像格式為Jpg,尺寸為640*480像素,數(shù)據(jù)集中包含有回環(huán)真值方便研究人員對(duì)比實(shí)驗(yàn)結(jié)果。實(shí)驗(yàn)硬件平臺(tái)為2.7 GHz Intel Core i5處理器,8 GB DDR3內(nèi)存。

圖5 New College和City Centre數(shù)據(jù)集中左右攝像頭采集圖像
為了更好體現(xiàn)算法性能,我們根據(jù)左右攝像頭采集的圖像重新分割了數(shù)據(jù)集,其中NewCollegeLeft表示左攝像頭采集到的所有圖像,NewCollegRight表示右攝像頭所采集的所有圖像。以此類推,我們也對(duì)CityCentre數(shù)據(jù)集進(jìn)行了分割,構(gòu)造了CityCentreLeft和CityCentreRight兩個(gè)子數(shù)據(jù)集(見表1)。

表1 數(shù)據(jù)集劃分
3.2 回環(huán)檢測(cè)準(zhǔn)確性比較
在性能評(píng)價(jià)上我們采用了準(zhǔn)確率-召回率(precision-recall,P-R)曲線和平均準(zhǔn)確率來(lái)展示算法對(duì)于回環(huán)檢測(cè)的性能。首先我們比較了在不同超平面和偏移量的情況下的P-R曲線。
從圖6和圖7中可以看出,無(wú)論是在NewCollege或CityCentre數(shù)據(jù)集上,我們?cè)谠O(shè)定16個(gè)超平面和8位偏移量的情況下均取得了最好的效果,隨著超平面數(shù)量和偏移量的下降,算法性能開始出現(xiàn)下滑。不難發(fā)現(xiàn),算法在CityCentre數(shù)據(jù)集上的效果普遍優(yōu)于在NewCollege數(shù)據(jù)集上的效果,這是因?yàn)镃ityCentre數(shù)據(jù)集中的圖像場(chǎng)景中有更多的人和車輛,預(yù)訓(xùn)練的VGG-19模型對(duì)于這樣的場(chǎng)景識(shí)別能力更強(qiáng)。接下來(lái),我們分別提取了FAB-MAP[6]、ORB-SLAM[7]、文獻(xiàn)[14]中基于Alexnet的回環(huán)檢測(cè)方法以及文獻(xiàn)[15]中基于Autoencoder的回環(huán)檢測(cè)方法,并在數(shù)據(jù)集上與本文提出的算法做了平均準(zhǔn)確率對(duì)比。

圖6 在數(shù)據(jù)集City Centre上的P-R曲線

圖7 在數(shù)據(jù)集New College上的P-R曲線
從表2中可以看出,基于深度學(xué)習(xí)使用了Autoencoder和AlexNet的算法在平均準(zhǔn)確率上均高于傳統(tǒng)的人工設(shè)計(jì)特征進(jìn)行提取的算法。再一次驗(yàn)證了,基于深度學(xué)習(xí)的圖像特征提取具有更好的光照不變性和對(duì)圖像場(chǎng)景的識(shí)別能力。其中,本文提出的算法在兩個(gè)數(shù)據(jù)集上相比FAB-MAP的平均準(zhǔn)確率提高了12%,相比ORB-SLAM提高了15%,相比Autoencoder提高了8%。另外,在NewCollege數(shù)據(jù)集上,本文提出的算法略低于AlexNet的算法,在CityCentre數(shù)據(jù)集上,本文提出的算法與基于AlexNet的算法大致相當(dāng)。這是因?yàn)樵诨贏lexNet的算法中直接使用了高維的特征向量進(jìn)行二次訓(xùn)練,提高了模型的擬合能力。
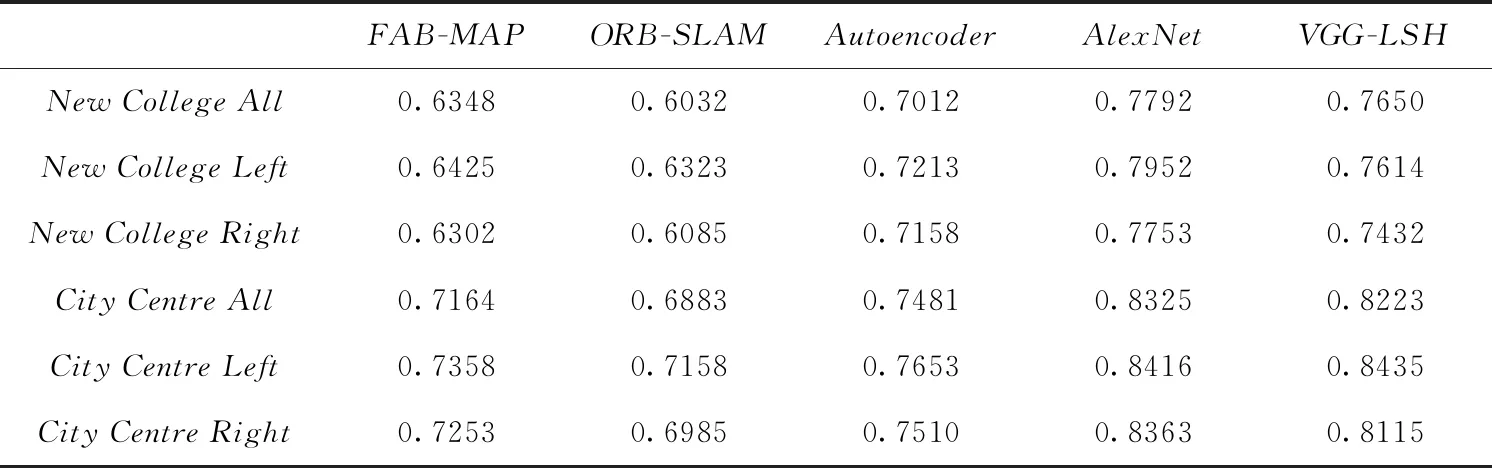
表2 算法在數(shù)據(jù)集上的平均準(zhǔn)確率
3.3 時(shí)間性能比較
在視覺SLAM系統(tǒng)中為了實(shí)現(xiàn)機(jī)器人的同步定位與建圖,對(duì)于回環(huán)檢測(cè)模塊的實(shí)時(shí)性有著較高的要求。基于此,從以下3個(gè)方面對(duì)算法的時(shí)間性能進(jìn)行了比較。首先,我們隨機(jī)抽取了兩個(gè)數(shù)據(jù)集中的2000張圖像,對(duì)于不同算法構(gòu)造單張圖像特征描述的平均耗時(shí)進(jìn)行了比較。
從表3中可以看出相比于另外3種算法,基于AlexNet的算法和本文提出的算法大幅度降低了構(gòu)建圖像特征描述所需耗時(shí),原因在于傳統(tǒng)方法中的關(guān)鍵點(diǎn)提取與特征描述子的構(gòu)建需要耗費(fèi)一定的時(shí)間,而基于深度學(xué)習(xí)的方法能夠直接輸出圖像的特征表述。另外,僅僅從構(gòu)造單張圖像的特征描述所花費(fèi)時(shí)間上進(jìn)行比較,本文提出的算法與基于AlexNet的算法差異不大,主要原因是因?yàn)閮烧咴跇?gòu)建單張圖像的特征描述上具有相似結(jié)構(gòu)。

表3 算法在數(shù)據(jù)集上構(gòu)造特征描述時(shí)間比較
接下來(lái),基于VGG-19構(gòu)造的圖像特征矩陣,我們比較了在檢測(cè)回環(huán)時(shí)直接使用暴力匹配與LSH算法進(jìn)行降維以后再進(jìn)行匹配的耗時(shí)(設(shè)定超平面?zhèn)€數(shù)為16,偏移量為8,時(shí)間單位:s)。
從表4中可以看出,相比于暴力匹配的遍歷方法,LSH算法大幅度提升了檢測(cè)回環(huán)的時(shí)間性能,滿足了回環(huán)檢測(cè)模塊對(duì)于實(shí)時(shí)性的要求。

表4 暴力匹配與LSH降維后進(jìn)行匹配耗時(shí)
最后,我們對(duì)以上算法在NewCollege和CityCentre上做了匹配時(shí)間比較,匹配時(shí)間指的是對(duì)于新加入的圖像進(jìn)行特征提取和在數(shù)據(jù)集中檢測(cè)回環(huán)的時(shí)間之和,結(jié)果見表5(時(shí)間單位:s)。

表5 算法在數(shù)據(jù)集上的匹配時(shí)間比較
從表5中可以看出,本文提出的算法在時(shí)間性能上具有較大優(yōu)勢(shì),相比FAB-MAP提高了59%,相比ORB-SLAM提高了29%。另外,相比于AlexNet,我們?cè)诳梢越邮盏姆秶鷥?nèi)犧牲了一部分準(zhǔn)確率,但提高了28%的時(shí)間性能,更能夠滿足視覺SLAM系統(tǒng)的實(shí)際應(yīng)用。
4 結(jié)束語(yǔ)
目前,視覺SLAM與深度學(xué)習(xí)的結(jié)合還處于初步階段,深度學(xué)習(xí)中的卷積神經(jīng)網(wǎng)絡(luò)是通過模擬人類大腦神經(jīng)的工作方式而構(gòu)造的,雖然大多數(shù)科研人員認(rèn)為卷積神經(jīng)網(wǎng)絡(luò)技術(shù)是一個(gè)“黑盒”模型,但不妨礙其在計(jì)算機(jī)視覺領(lǐng)域的巨大成功。而視覺SLAM進(jìn)行環(huán)境感知的形式都是通過圖像或者視頻等形式進(jìn)行,因此將深度學(xué)習(xí)的方法應(yīng)用到視覺SLAM中是一項(xiàng)非常有意義的研究。基于此,本文提出的結(jié)合卷積神經(jīng)網(wǎng)絡(luò)和LSH算法的視覺SLAM回環(huán)檢測(cè)算法較已有的回環(huán)檢測(cè)算法顯著提高了檢測(cè)效率和準(zhǔn)確率,能夠有效降低光照、天氣、角度等變化對(duì)回環(huán)檢測(cè)的影響,并滿足視覺SLAM系統(tǒng)對(duì)于實(shí)時(shí)性的要求。在未來(lái),我們希望對(duì)如何建立一個(gè)端到端的基于深度學(xué)習(xí)的完整視覺SLAM系統(tǒng)展開研究。
猜你喜歡
艦船科學(xué)技術(shù)(2022年15期)2022-09-14 09:21:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動(dòng)化學(xué)報(bào)(2017年11期)2017-04-04 02:52:58
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
