面向深度學習識別高空農作物的方法
2020-03-07 12:48:22陳小幫左亞堯王銘鋒
計算機工程與設計 2020年2期
關鍵詞:模型
陳小幫,左亞堯,王銘鋒,馬 鐸
(1.廣東工業大學 計算機學院,廣東 廣州 510006;2.西安工業大學 電子信息工程學院,陜西 西安 710032)
0 引 言
早期農業研究中廣泛應用了遙感技術,主要基于衛星載體和高空平臺的土壤測量或植物電磁輻射,如作物生長[1]、作物土壤[2,3]、作物定位[4]、作物區繪制[5],等等。為了準確描述遙感的圖像,通常需要提取各種特征,其中包括線性特征、光譜特征、紋理特征、基于對象的特征等。特別地,高空或衛星農作物圖像的識別主要集中于圖像的光譜信息,如通過多光譜識別農作物[4]、可見光的區分作物[6]、超光譜的作物害蟲檢測[7]等等。但是,受限于技術手段,多光譜傳感器成像速度有限,并且在提取遙感圖像的特征信息過程中不夠全面,圖像識別準確率還存在一定的限制。同時,樣本標記的代價過高,其實施成本昂貴。因此,高光譜遙感技術對農作物高空或衛星圖像處理,其性能還有很大的提升空間。
在深度學習[8,9]的熱潮下,圖像識別處理的卷積神經網絡(convolutional neural network,CNN)能夠獲取各種結構豐富數據的本質特征,類似人類系統處理數據保留有用結構信息的作用,對農業圖像處理也有極其有效的作用。Sa等利用深度卷積神經網絡對不同水果圖像進行測試,為自動農業開發提供了更為先進的物體檢測方式[10];Lottes等利用卷積神經網絡進行區分農作物與雜草莖,驗證了該方法的可靠性并提高了莖檢測的準確性[11];Kamilaris等采用深度學習技術對農業問題進行了研究,結果驗證了深度學習技術優于常用的圖像處理技術并可提供更高的精度[12];傅隆生等提出的深度學習模型進行多簇獼猴桃果實圖像的識別方法,表明卷積神經網絡在田間果實識別方面具有良好的應用前景[13]。
然而,上述研究存在兩方面的不足。首先,利用衛星和載人飛機兩種手段獲取圖像,存在時間和空間分辨率相關的問題,并且數據集的獲取過程中受到諸多的因素干擾,存在一定的噪聲。其次,已有研究主要以近距離拍攝的圖像作為輸入,鮮少以高空農作物圖像直接作為輸入并結合深度學習來識別農作物的工作。
鑒于此,本文運用廉價和便捷的無人機作為采集手段,利用其高空間、高分辨率的優勢,更好、更方便地采集農作物圖像。并針對其訓練樣本有限的困境,探討如何結合數據增強、農作物圖像預處理等技術,改進VGG深度學習模型,解決無人機航拍圖像中的農作物識別的問題,實驗驗證了方法的有效性。
1 相關技術
目前,深度學習在圖像識別的方向上取到較好的效果,其主要構成是卷積神經網絡。采用卷積核與池化等非線性操作,搭建網絡模型,可對多媒體數據具有很強的識別感知能力。并且,當目標領域中僅有少量有標簽的樣本數據甚至沒有時,遷移學習能夠通過遷移已有的知識來解決該類問題。
1.1 遷移學習
為克服無人機所拍攝的圖像數量過少,優化參數預訓練過程,則可選用已訓練好權重的卷積神經網絡,再用實際數據集進行有監督的參數微調,這正好與遷移學習思想一致。因此,本文引入遷移學習用于克服目標類別訓練樣本不足的問題。
遷移學習這種機器學習的方法是將一個預訓練的模型重新用在另一個任務中,與域和任務兩個概念有關,其定義可參見文獻[14]。在概率論的角度中,可表示為P(Y|X), 因此,任務可表示為T={Y,P(Y|X)}。
給定一個源域Ds, 一個對應的源任務Ts, 還有目標域Dt以及目標任務Tt, 在Ds≠Dt, Ts≠Tt的情況下,通過Ds和Ts的信息,學習到目標域Dt的條件概率分布P(Yt|Xt), 因此有標簽的目標樣本可遠遠少于源樣本。
模型訓練需要大量圖像,其采集工作量巨大。而引入遷移學習,一方面極大地減少訓練圖像數據集的規模,減輕無人機拍攝的工作量,同時可提高圖像訓練速度的問題。Maxime 等[15]在VOC2007和VOC2012上利用遷移學習方法訓練權重得到了很好的效果。
1.2 VGG模型
CNN是大多數最先進的計算機視覺解決方案的核心,適用于各種任務。它將特征提取和分類兩個模塊集成一個系統,通過識別圖像的特征來進行提取并基于有標簽數據進行分類。隨著時間的推移,所提出的CNN架構的準確度越來越高。典型的深度CNN主要由卷積層、池化層和全連接層組成,將原始像素級別的特征抽象成表達能力強的高層特征,提供簡易、高效的特征選取過程。
在此,本文只針對VGG16[16]原模型進行介紹。該模型為牛津大學VGG組提出,通過多次重復使用同一大小的卷積核來提取更復雜和更具表達性的特性,如圖1所示。
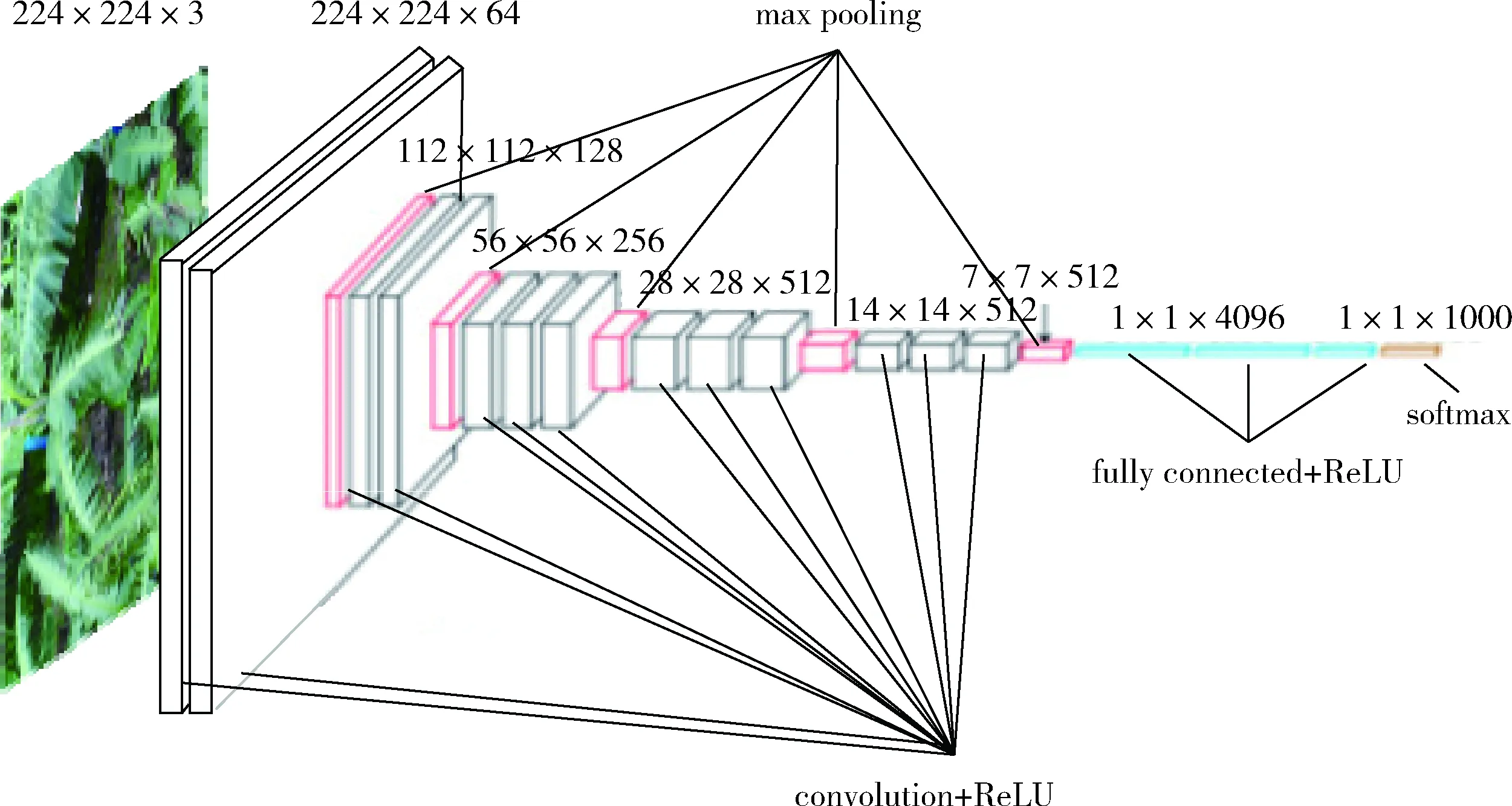
圖1 原模型VGG16
其網絡中含有參數的有16個層,采用若干個卷積層,之后緊跟一個可以壓縮圖像大小的池化層作為模型的基本框架。其中包含13個卷積層,有5個池化層,有3個全連接層與1個Softmax層。各部分采用計算算法如下:
(1)卷積層。可提取圖像的不同特征,其尺寸計算原理如式(1)和式(2)
(1)
(2)
式中:ho、hi為輸出、輸入高度;wo、wi為輸入、輸出寬度;hk、wk為卷積核高度、寬度;p為填充;s為步長;網絡模型統一采用3×3的卷積核。利用j個不一樣的卷積核對圖像進行卷積,可生成j個不一樣的特征圖,卷積層計算公式如式(3)所示
(3)
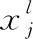
(2)池化層。主要對輸入進行抽樣,聚合統計卷積層的不同特征,減少特征計算量,防止過擬合。其操作運算原理如式(4)所示
(4)
(3)全連接層。第一個全連接層FC1有4096個節點,上一層POOL2是7×7×512=25088個節點,則該傳輸需要4096×25088個權值,所以其內存開銷很大。在softmax中,類標簽y可取k個不同的值,對于輸入的x, 設函數p(y=j|x;w) 是x屬于類別j的概率值,則計算公式如式(5)所示
(5)
式中:w為模型參數。
(4)激活函數。每個隱層的激活單元都是ReLU。相比其它激活函數,在線性函數中,深度網絡中的ReLU表達能力更強;而在非線性函數中,ReLU可令模型的收斂速度維持在一個穩定狀態。利用ReLU能夠在稀疏后的模型中更好地挖掘相關特征,擬合訓練數據。其激活函數定義如式(6)所示
f(x)=max(0,x)
(6)
2 模型改進
為了構建更適用于高空農作物圖像識別的模型,通過對高空農作物圖像進行特征分析,利用增強前后模型的識別準確度的變化,分別對3種模型進行實驗對比和分析,選取其適合的模型。并在此基礎上對模型進行了改進,以提高模型的識別率。
2.1 特征分析
本文利用無人機拍攝的農作物圖像與以往的圖像識別數據有較大的區別,比如高度和視角不同,會導致所拍攝的圖像大小和形狀也有所差異,對圖像處理帶來一些挑戰。
就拍攝距離而言,農作物圖像為高空圖像,與近距離產生的圖像相比,難于利用一般的神經網絡進行特征提取與識別;另外,近距離的圖像通常為單一類別,而高空的農作物圖像包含了多種類別。無人機拍攝圖像覆蓋面積廣大,包含多種作物,從而增加農作物分類識別的困難。
同時,要求所采用的神經網絡能實現較高的識別率,能夠對特征不分明情況下的農作物識別。比如通過輸出花的數據集與無人機拍攝圖像的特征,對比第一個卷積層的特征輸出,如圖2所示,可發現,肉眼便可以識別出近距離的雛菊,但難于準確辨認高空拍攝的黃瓜。

圖2 近距離植物與高空植物卷積層特征
2.2 模型的對比
為找出更加適合農業圖像識別的模型,對Inception-V3、VGG16和VGG19這3種模型進行對比,通過實驗進行選優。保證客觀性,所有模型的基本參數都設置為:學習率為0.01;迭代次數為10 000次;采用花的數據[17],其中包含5種花,共3670張圖片,經過翻轉增加了1倍的數據。
通過實驗,3種模型在數據翻轉前后的準確率見表1。
本文對比3種模型在數據翻轉后的準確率。用花的數據集翻轉后,Inception-V3準確率反而降低了,另外兩種模型都有所提高。
而反觀VGG16和VGG19兩者之間的準確率,相差并
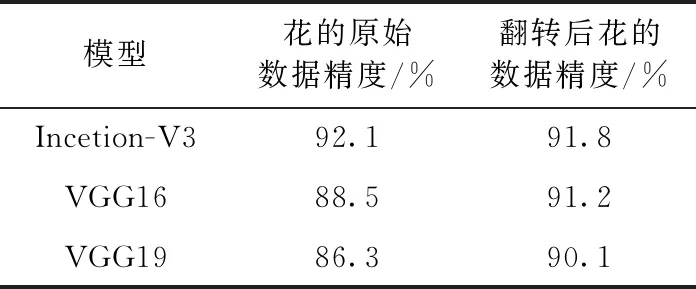
表1 3種模型在數據翻轉前后的平均準確度
不大,但前者平均精度更高,在訓練過程中比后者更快,性能更好,因此本文選取VGG16為基本的模型。
在花的數據集上,VGG能得到很好的表達效果,但是部署在GPU上并非易事,因為該網絡模型在內存和時間上的計算要求比較高。VGG的卷積層通道數大,且網絡架構weight數量相當大,很消耗磁盤空間,訓練非常慢,由于其全連接節點的數量較多,再加上網絡比較深,VGG16有533 MB+,VGG19有574 MB。這使得部署VGG比較耗時。
2.3 擬合優化
為了防止訓練數據不足而導致過擬合,本文在原模型的第二個全連接層fc7添加正則化因子,提高圖像的識別率。
此外,考慮到獲取更好的分類結果,本文采用SVM分類器[18]替換掉原模型VGG16的分類器Softmax。由Vapnik開發的SVM用于二分類,其目標是找到最佳超平面f(w,x)=w·x+b以分隔給定的數據集成為兩類。SVM通過優化參數w解決問題
(7)
其中,WTW是L1標準化,C是懲罰因子, y′是實際標簽,b是閾值。
為了優化擬合問題,提供更穩定的結果,采用hinge loss函數
(8)
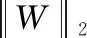
為驗證改進模型的效果,本文默認正則因子為0.04,采用上文提到的花的數據進行訓練,迭代次數均設置為 10 000 次,批處理BatchSize為200,并設置學習速率為0.01。設置SVM懲罰因子為9個因子,分別為0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8和0.9,實驗結果表明,加入正則化后所得到的準確率幾乎比無正則化的高,其對比結果如圖3所示。
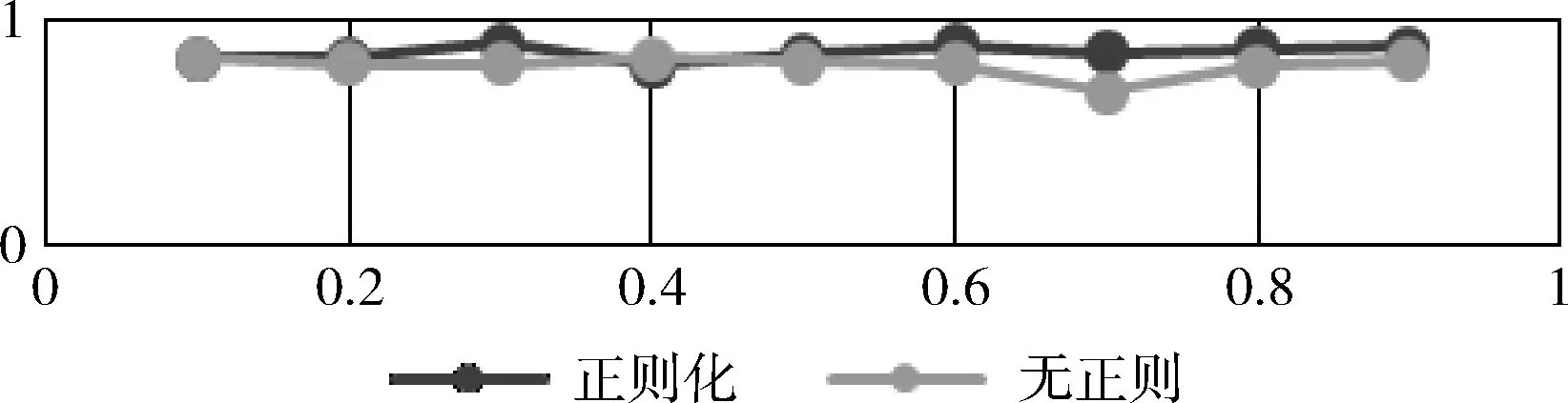
圖3 模型有無正則化的準確率對比
原模型VGG16與改進后模型對比。兩種模型均用 Imagenet 數據集訓練好了權重,再采用花的數據進行訓練與測試,迭代次數均設置為10 000次,批處理BatchSize為200,并設置學習速率為0.01。原模型獲得精度為0.885,在不改變正則化因子并均設置為0.04下,調整分類器SVM的懲罰因子為0.3時,改進后的模型精度為0.8904。因此,改進后的模型識別率更高,而且可進行因子調整,從而提高識別率,靈活性更強,更適合作為農作物圖像識別的模型。
3 識別處理
確定好模型之后,研究工作進入農作物圖像識別的過程。本研究采用Phantom 4 Advanced無人機拍攝。有效像素為20 MP,鏡頭距離地面為5 m、10 m、15 m、30 m,可清晰拍攝尺寸為5472像素×3078像素的圖像,圖像格式為jpeg,水平分辨率與垂直分別率均為72dpi。
為解決圖像數據不足的問題,在進行農作物圖像識別之前,除了采用遷移學習思想,還進行了圖像數據增強。并且,分析高空農作物圖像特點,進行預處理以提高圖像識別率。
本文處理平臺為筆記本計算機,處理器為Inter(R)Core(TM)i5-8250U CPU@1.60 GHz×8,磁盤為109.4GB,運行環境為:Ubuntu18.04.1 64位、python3、pycharm2018.2.1社區版、tensorflow1.10版本以及可視化工具tensorboard、jupyter,選取的框架為Tensorflow[19]。
3.1 數據增強有效性
為了克服無人機拍攝的農作物圖像數據少,遠遠不滿足模型訓練的特征提取的缺點,需利用標記好的原始圖片進行裁剪,從而增強數據,以防止圖像數據過度擬合。
一般增加訓練數據可通過圖像滑動、圖像旋轉、光學畸變、漸暈效果、顏色漸變、圖像裁剪等方法,從而使得圖像的魯棒性得到提高。Krizhevsky等[20]曾利用ImageNet進行實驗并得到了很好的驗證效果。此外,結合百度的最新研究成果[21],其中的數據增強實現誤差為5.3%,是 ImageNet 上達到的最好結果,表2為1張圖進行圖像增強后的數據量。從表中可知顏色漸變與圖像裁剪方式增加的數據量比較大。然而,神經網絡對光源變換、顏色變換比較敏感,圖像在改變光照、變換神經網絡的情況下,目標農作物將被識別成另外一類。在此,本文主要采用裁剪的方式增加數量集。一方面可以保證數據集的增加,同時也能減少工作量節約時間。
按照VGG模型輸入層的要求,分割圖片為224像素×224像素。由于無人機高空拍攝的目標農作物處于中心范圍,在原始5472像素×3078像素的圖片中心上裁剪出2240像素×2240像素的中心圖片,再將中心圖片分割成100張224像素×224像素的圖片并編號為n_1到n_100。
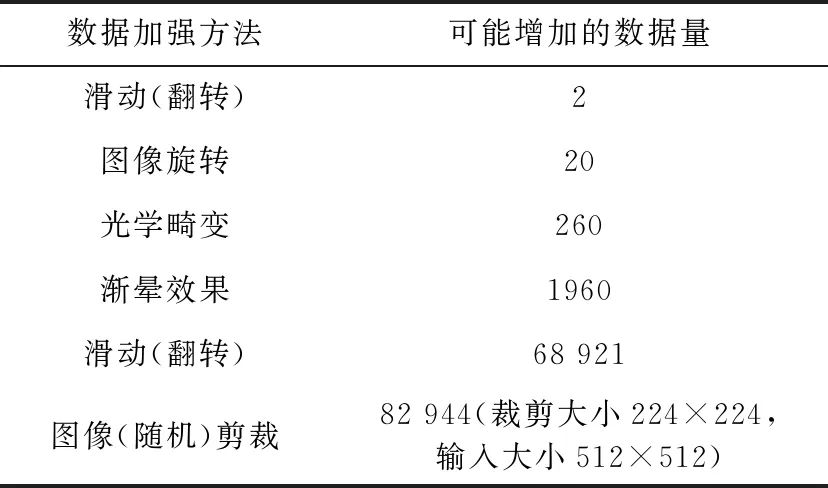
表2 不同增強方式的可能增加數量
n張原始圖片有n張中心圖片,可分割成100n張224像素×224像素的圖片,由此可實現一變多而增加樣本數量。圖像數據增強過程如圖4所示。
盡管通過數據增強對數據量進行擴充,但是為了進一步補充訓練數據的有效性,還通過google搜索圖像的方式,獲取無人機所拍攝的農作物類別,人工挑選充實到圖像訓練樣本集合。
為了驗證數據增強對數據訓練是否有效,利用改進的模型,進行數據集增強前后的實驗。對花的數據集翻轉后,其數據集比原來的增加了1倍,默認正則化因子為0.04,迭代次數均設置為10 000次,并設置學習速率為0.01,調整上文提到的SVM的9個懲罰因子。實驗結果表明,翻轉后的準確率在懲罰因子為0.04時達到了0.9082,其對比如圖5所示。

圖4 圖像數據裁剪增強過程
通過實驗數據顯示,利用花的原數據進行訓練的準確率有較大的波動,翻倍后,準確率波動相對不大,并且都能在0.8以上,存在最高準確率,因而,數據翻倍后對模型識別準確度是有效的。
3.2 數據處理的對比
在數據預處理中,通常可以刪除不相關的實例以及噪聲或冗余數據,如此高質量的數據將帶來高質量的結果并降低數據挖掘的成本。
本文先利用裁剪后的農作物圖像進行翻轉增加1倍數據集,生成圖片路徑和標簽列表,隨機打亂數據集,防止特定序列對學習帶來不利的影響。進而設置隊列,將圖片分批次載入,這樣在訓練時可從隊列中獲取一個batch,傳送至網絡訓練,又有新的圖片進入隊列,循環反復。如此,隊列能起到訓練數據到網絡模型間的數據管道的作用,減少一時過多地占用內存。在讀取到圖片后,則進行圖像格式解碼,防止不同類型的圖像混在一起,這里圖像統一用jpeg。
此外,無人機拍攝的為農作物彩色圖像,而識別的彩色圖像所包含的信息量較大,受光源變換以及顏色變換等比較敏感,也會增加數據訓練的成本,本文對圖像特征進行歸一化,將像素值縮放到[0,1],并進行白化從而獲取好的特征。為了提高數據的準確率,對農作物數據集進行了灰度處理,分別保存為無灰度和灰度的兩種數據集,并利用改進的模型進行了實驗。實際數據集為9類農作物,訓練數據、測試集與驗證集按8∶1∶1比例,所設置迭代次數均為10 000次,學習速率為0.001,正則化因子為0.04,通過調整上文提到的分類器SVM的9個懲罰因子,最后得到數據集有無灰度化的準確率,如圖6所示。

圖6 有無灰度化的準確率
實驗數據顯示,當SVM懲罰因子為0.8時,兩種數據集分別取得最高的準確率0.9680與0.9817。并且,經過灰度化的農作物數據集普遍比無灰度化的數據集的準確率高,由此易看出,經過灰度處理,更有利于提取高空農作物圖像的特征,提高圖像識別準確率。
3.3 訓練的變化圖
為克服數據集不足的缺點,結合遷移學習的思想,利用Imagenet數據集為VGG16模型提供最優的初始權值,再通過預處理后的農作物圖像對上文改進的模型結構進行微調。實際高空農作物圖像數據集為9類農作物,訓練數據、測試集與驗證集按8∶1∶1比例,實驗設置迭代次數均為10 000次,學習速率為0.001。通過TensorBoard獲取測試集的準確率與損失函數圖,其變化如圖7所示。
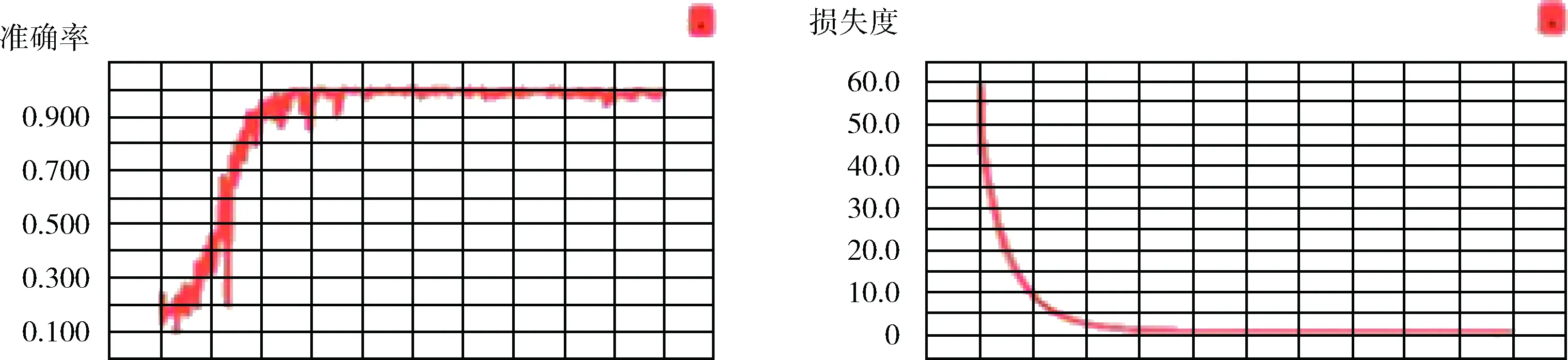
圖7 準確率與損失度
結果顯示,在迭代次數不斷增加情況下,測試集的分類誤差逐漸降低,隨著訓練迭代到4000次時,準確率便趨于穩定,且后面驗證集和訓練集間的誤差值相差不大,由此可得模型具有良好狀況。4000次迭代后,訓練損失值基本上收斂穩定,說明網絡模型訓練已達到了預期的效果。
3.4 識別結果
首先,結合遷移學習的思想,采用Imagenet訓練好權重的VGG16模型實現農作物圖像的識別。Imagenet數據集包含1000類的自然場景圖像,圖像總量大于100萬,與識別目標農作物圖像具有相似性,利用它進行大規模網絡訓練是比較合適的。在給定的Imagenet數據集為一個源域Ds和識別出該數據集圖像為學習任務Ts, 無人機拍攝的圖像作為目標域Dt和識別出農作物為目標學習任務Tt。 通過利用Ds和Ts中的知識,遷移學習便能實現目標預測函數f(*) 在Dt中性能的提高。其過程如圖8所示。
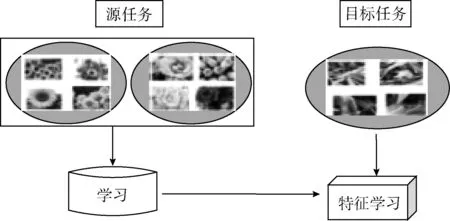
圖8 遷移學習過程
在實際的農作物圖像數據集中,包含兩種輸入,一種是模型微調時已標記農作物圖像的輸入,另一種為待識別農作物圖像的輸入,每種數據集均需要進行灰度化、去均值等預處理,使圖像符合網絡訓練的要求。
其次,對訓練好權重的VGG16模型進行改進。在其第二個全連接層添加正則化因子,并將分類器softmax改為SVM分類器,實現模型優化,防止過擬合。
接著,利用已標記農作物圖像對改進的模型進行微調,合理丟棄數據,防止過擬合,計算識別結果和標記的差異,調整參數,以此達到較高的識別準確率。
最后,保存微調后的參數,輸入待識別農作物圖像,通過SVM分類器顯示識別結果。
完整的農作物圖像識別算法如圖9所示。

圖9 農作物圖像識別算法
隨機選取一張無人機高空拍攝的農作物圖像,預處理后,輸入到上文微調好的模型中進行圖像識別,所得結果如圖10所示。該結果為最后全連接層的特征分類,顯示玉

圖10 隨機測試識別結果
米所占的特征概率比較大,與實際相符。然而,特征概率值并不高,說明高空圖像識別的特征提取還有待完善。
4 結束語
本文通過遷移學習和數據增強方式有效地解決了無人機拍攝的目標圖像數據集少造成的不足。分析高空拍攝農作物圖像的特點,對輸入圖像進行預處理并改進傳統模型,提高模型的精確度與農作物的識別率。然而,高空圖像的特征提取還不夠完善,所取得的結果還有待提高,是本文接下來的工作。能將深度學習與農業相結合、農業與無人機結合、深度學習與無人機結合,對促進傳統農業向現代農業的發展,具有很高的研究價值與應用前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
