基于Adam-BNDNN的網絡入侵檢測模型
2020-03-09 13:12:40
計算機測量與控制 2020年2期
(西南科技大學 計算機科學與技術學院,四川 綿陽 621010)
0 引言
入侵檢測系統(intrusion detection system,IDS)是計算機網絡中一種主動防御的成果,它為人類工作和生活提供安全保護。此前,許多學者提出了一些典型的IDS;文獻[1]結合改進的KNN和Kmeans實現I2K用于入侵檢測,結果表明該算法具備良好的檢測率和新攻擊識別能力,但檢測速度仍有待提升;文獻[2]提出一種結合多目標優化理論的克隆選擇算法,其能有效改善種群進化效率,增加種群多樣性,進而提高檢測率,但對于樣本容量較大時,檢測效率仍然比較低;文獻[3]先用信息增益(IG)對網絡數據進行特征提取,再用主成分分析(PCA)進行數據降維,最后用Naive Bayes來完成入侵分類檢測,該方法雖然檢測率高于KPCA、FPCA、PCA-LDA,但并未提高對各攻擊的檢測率。文獻[4]使用自適應SSO的分組過濾方法來完成入侵檢測,雖然在不降低網絡安全性的前提下,能有效減輕基于簽名的入侵檢測系統的負擔,但在黑名單分組過濾簽名匹配時還是消耗了較多時間。
隨著大數據時代到來,網絡數據的數量增多、格式多變、網絡入侵行為多樣化等,傳統網絡入侵檢測模型面臨著檢測精度低、誤報率高等問題。而近年來深度學習的興起,基于深度學習的IDS也慢慢開始得到應用。文獻[5]利用獨熱編碼對網絡包進行編碼形成二維數據,再用GoogLeNet進行特征提取并訓練Softmax分類器,其在檢測精度、漏檢率和誤檢率等都有很大提升;文獻[6]結合深度學習理論和神經網絡的極限學習機,提出一種自編碼器-極限學習機入侵檢測模型;用MODBUS數據集進行仿真實驗,結果表明其優于SVM、ELM、DBN、MLP、K-Means,符合網絡入侵檢測“高精度,低誤報率”的檢測要求。而本文結合DNN優異的特征學習能力、BN的規范化數據處理和Adam自適應梯度優化方法,提出了一種基于Adam-BNDNN的入侵檢測模型。
1 DNN概述
深層神經網絡(deep neural network,DNN)屬第三代人工神經網絡,它具有1個輸入層,1個輸出層和n個隱含層,結構如圖1 所示,在數據量大的情況下可以計算得更快,花費更少的代價[7]。

圖1 DNN網絡結構圖
DNN同樣和分為前向和后向。首先對權值W和閾值b進行初始化,前向時數據通過預處理后從輸入層經n個隱含層計算后傳入輸出層,輸出層激活后的輸出結果與期望結果進行對比得到誤差,誤差再以梯度下降的方式從輸出層經隱含層回傳至輸入層,以此便完成了一輪神經網絡的訓練。
1.1 He初始化權值
初始化時一般將閾值b初始化為0,傳統神經網絡權值初始化常用初始化為0和隨機初始化,但W初始化為0會出現每一層的學習能力相同,因而整個網絡的學習能力也有限;而隨機初始化實質上是一個均值為0方差為1高斯分布,若神經網絡層數增加,則會出現后面層激活函數的輸出值接近0,進而可能產生梯度消失。
而現在常用的權值初始化有Xavier初始化、He初始化等。Xavier初始化中輸入和輸出都被控制在一定范圍內,激活函數的值都盡量遠離0,則不會出現梯度過小的問題,公式如式(1):
(1)
但是Xavier對于激活函數ReLU不太適合,在更深層的ReLU中,激活函數的輸出明顯接近0,所以Xavier一般用于Sigmiod和Tanh。
而He初始化的出現解決了ReLU的問題,此方法基本思想是正向傳播時,激活值方差不產生變化,回傳時,激活值梯度方差不產生變化;對于ReLU和Leaky ReLU有不同的初始化方法,ReLU適用于公式(2),Leaky ReLU適用于公式(3),本文采用的便是基于ReLU的He初始化方法。
(2)
(3)
1.2 ReLU和Softmax激活函數
激活函數的選擇會對模型收斂速度、訓練時間產生非常大的影響。之前常用的激活函數有Sigmoid以及Tanh,Sigmoid將輸出結果規約到0~1之間,Tanh規約到-1~1之間,在隱層中相較而言Tanh要優于Sigmoid,因為Tanh的均值為0,關于原點對稱,具有對稱性;但兩者在訓練時都容易造成兩端飽和使得導數趨于零,以致權重無法更新最終造成梯度消失;而RuLU左邊是抑制的,右邊是有梯度的,一般不會造成梯度消失,因為神經網絡的輸入數據一般都大于0;且RuLU具有更快的計算速度和收斂速度,因此隱藏層使用RuLU比前兩者更好。3種激活函數的輸出圖像如圖2所示。

圖2 Sigmoid-Tanh-Softmax函數圖像
輸出層通常采用Sigmoid函數或Softmax函數將輸出層的輸出結果歸約到0~1之間,如公式(4)和(5):
(4)
(5)
其中,Sigmoid將輸出層每一個輸出節點的結果歸約到0~1之間,故輸出節點間的輸出結果相互是獨立的,且總和可能為1可能不為1;而Softmax輸出層中每一個輸出節點的結果是相互緊密關聯的,其概率的總和永遠為1。由于本模型采用One-hot來編碼分類結果,在輸出層時選用Softmax分類器較為方便。
1.3 Mini-batch梯度下降
神經網絡以梯度下降的方式來更新參數。在參數更新中,若使用整個數據集進行梯度下降,W和b每次更新都在整個數據集一次訓練完以后,這樣可能不利于魯棒性收斂,有可能造成局部最優;如果一次只用1個樣本進行訓練,W和b更新太頻繁,整個訓練的過程也會很長。
而介于兩者之間的Mini-batch,把整個數據集隨機分為Mini-batch的Size大小,W和b更新是在每個小批量后,且每次小批量訓練的數據更具有隨機性,這樣可以使得模型梯度下降參數更新更快,避免局部最優,同時加速模型的訓練。
2 模型設計
2.1 Adam-BNDNN的檢測模型
本文檢測模型主要分3個模塊,結構如圖3所示。

圖3 基于Adam-BNDNN的入侵檢測模型
數據獲取和預處理模塊:獲取網絡數據集,并對其進行特征提取、數值轉換、數據歸一化等預處理操作,使其滿足輸入數據的要求;并將其分為訓練集和測試集,分別用于模型訓練和模型測試。
入侵檢測模塊:結合預處理后數據的維度確定Adam-BNDNN網絡的輸入輸出節點,再根據隱層和其他參數從而確定整個網絡結構和訓練參數,用訓練集對模型進行訓練,完成訓練后保存模型用于測試。
檢測分類模塊:測試集使用保存的模型進行測試,并將檢測分類結果展示給用戶。
2.2 BN批量規范化優化
Batch Normalization[8](BN)是近些年以來深度學習的一個重要發現,其應用在隱藏層,經常同Mini-batch一起使用。主要將每個隱層的輸出結果進行歸一化處理再進入下一個隱層,但并不是簡單的歸一化,而是進行變換重構,引入λ、β這2個可學習的參數,如公式(6):
(6)
引入參數后,網絡即可學習出原始網絡所需的特征信息;BN操作如圖4所示。

圖4 BN操作結構圖
批量規范化(BN)操作流程:
1)數據先從輸入層輸入,經隱含層激活計算后得到激活值。
2)對隱含層激活值做批量規范化可以理解成在隱層后加入了一個BN操作層,這個操作先讓激活值變成了均值為0,方差為1的正態分布,即將其歸約到0~1之間,最后用γ和β進行尺度變換和偏移得到網絡的特征信息。
3)數據完成BN后再進入下一隱層。
BN的使用降低了初始化要求,可使用較大學習率,也使神經網絡的隱含層增強了相互間的獨立性,同時增大了反向傳播的梯度,進而避免了梯度消失的問題;且和Dropout一樣具有防過擬合的正則化效果。
2.3 Adam梯度下降優化
神經網絡傳統的隨機梯度下降(SGD)缺點是很難選擇一個比較合適的學習率,同時收斂速度也很慢,且容易達到局部最優。而以梯度下降為基礎的Adam優化算法[9],結合了RMSProp優化算法和Momentum優化算法。
RMSProp中神經網絡在訓練時可自動調整學習率,不用過多的人為調整;而Momentum則是調整梯度方向,使得在訓練時加速梯度下降的速度,從而加快訓練過程。參數更新如公式(7):
(7)

(8)
其中:α、β1、β2、ε都有缺省值,也可以自行調整。
2.4 L2正則化
在網絡的訓練過程中若數據過少或者訓練過度則可能會產生過擬合現象,而正則化可以在學習中降低模型的復雜度,從而避免過擬合。正則化實質在損失函數中添加了正則項,對損失函數的參數做一些限制;一般有L1和L2正則化,本文選用L2正則化,L2正則化對b更新無影響,對w更新有影響;拿邏輯回歸為例,公式如(9)所示:
(9)

3 數據集選取和處理
3.1 實驗數據集選取
實驗選取的是NSL_KDD數據集[10],它是KDD CUP數據的濃縮版,其在KDD CUP數據集的基礎上進行的改進有:
1)KDD中冗余數據的去除:使分類結果不會偏向更頻繁的記錄。
2)KDD中重復數據的去除:使檢測更加準確。
3)數據集大小更合理:KDD共有500萬左右條數據,數據總量多且冗余、重復數據多,可能會造成檢測結果不理想以及訓練時間過長。而NSL數據集總量125973條,正常和各異常數據占比也符合真實網絡情況,用于訓練的時間也不會太長。
NSL一共有41維屬性特征和1維標志特征,具體信息如表1所示。

表1 NSL數據的屬性信息
3.2 數據預處理
3.2.1 特征提取
在NSL數據集的41維屬性特征中,每一維屬性特征對結果的影響都是不一樣的,為了合理選取網絡數據的屬性參數,文獻[11]選取了12個屬性特征,文獻[12]選取了14個屬性特征;文獻[13]選取了15個屬性特征;本文結合2種特征選取技術綜合考量后最終選擇21個最優特征屬性,如表2所示。

表2 NSL數據集21個屬性選取
3.2.2 數值化
21維屬性特征選取完以后,其中Protocol type、Service、Flag和Label是離散型數據,對離散型數據首先應數值化;
在Protocol type中,共有Tcp、Udp、Icmp三種協議類型,分別用數字1、2、3代替;
Service中共有70種服務名稱,分別用數字1~70代替;
Flag中共有11種網絡連接狀態,分別用數字1~11代替;
最后是Label標志的數值化,Label共有5種,分別標識Nor、Pro、Dos、U2r、R2l,為了便于后面檢測的分類工作,在數值化時使用One-hot進行編碼,如Normal編碼為10000。
3.2.3 歸一化
NSL數據經數值化后,有些數值區間較大,各特征間差異也大,若不經處理就做輸入數據,可能會使訓練結果偏向更大的數,繼而對訓練速度和精度也會有一定的影響。為了避免上述情況發生,一般使用公式(10)將其歸一化到0~1之間,
(10)
歸一化后一方面能提升模型收斂速度,另一方面提升模型的精度。
3.3 訓練集和測試集的劃分
NSL數據進行預處理以后,隨機取其2/3做訓練集,剩下1/3做測試集,如表3所示。檢測評價標準是2分類檢測結果和5分類檢測結果的準確率以及誤報率。

表3 訓練集和測試集劃分
4 實驗與對比分析
4.1 實驗參數選取
在數據預處理中選擇21維屬性特征,5維One-hot編碼標志特征,則Adam-BNDNN對應的輸入為21個節點,輸出為5個節點。
為了選擇模型訓練合適的Epoch,以3隱層Adam-BNDNN網絡21-50-30-20-5為例,選取總迭代次數200次,迭代Epoch和對應的代價Loss如圖5所示。

圖5 迭代Epoch和代價Loss曲線圖
結果顯示:在迭代100次以后,網絡的訓練代價趨于平緩。在迭代次數選取時,若迭代次數過少,則會造成訓練不足,若迭代次數過多也有可能會造成過擬合。因此,在模型訓練中,選取的迭代Epoch為100次。
接著是神經網絡隱層數選擇。為了選擇合適的隱層數量,分別選取隱層數為1~5的5種不同網絡結構5分類的平均準確率,網絡結構如表4所示。

表4 Adam-BNDNN網絡的不同隱層數結構
經實驗得出,隱層數為3和4時整體檢測率差不多,但4隱層時U2r和R2l的檢測率低于3隱層,隱層數為5時精度大幅度下降,綜合考量則最合適的隱層數為3。
確定了網絡的Epoch和網絡結構后,Adam-BNDNN所有參數設置如表5所示。

表5 Adam-BNDNN參數
4.2 實驗結果及分析
用NSL-KDD數據集仿真實驗后,分別使用2分類檢測結果和5分類檢測結果的準確率以及誤報率來評估模型的檢測性能,結果如表6所示。
為了驗證模型的檢測效果,分別用淺層神經網絡(SNN),K最近鄰(KNN),深層神經網絡(DNN)、Alpha-OSELM[13]與本文做對比,2分類結果如表7所示,5分類結果如表8所示。
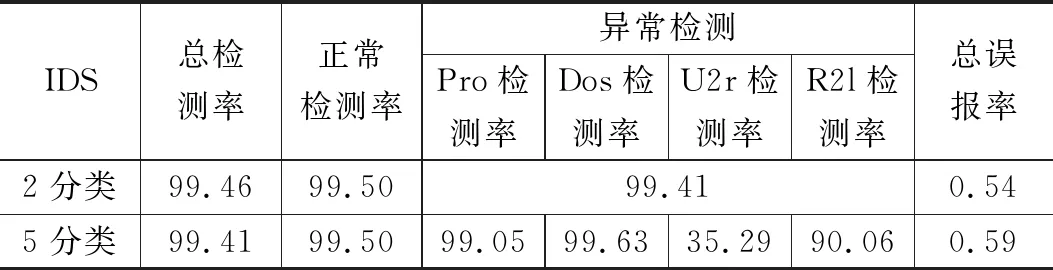
表6 Adam-BNDNN模型檢測的分類結果 %
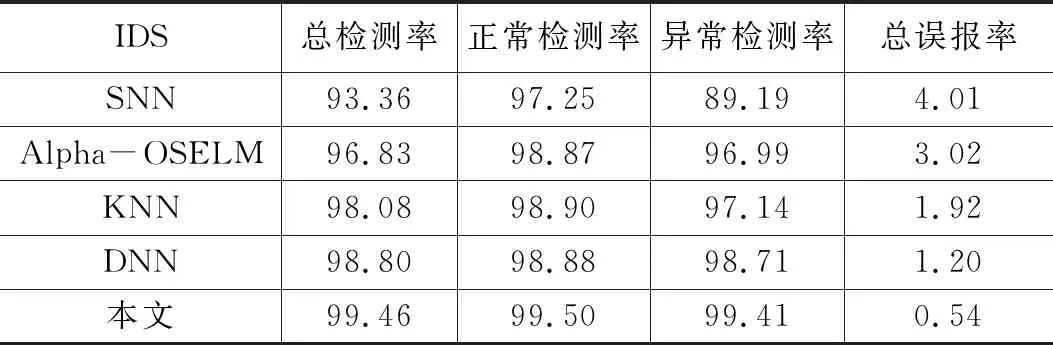
表7 各IDS的2分類結果 %

表8 各IDS的5分類結果 %
從表6可以看出,2分類的整體檢測率要比5分類高,整體誤報率要比5分類低。因為在2分類檢測中,若類型為R2l的攻擊誤檢為U2l,對于2分類檢測結果是正確的,但在5分類檢測中則是錯誤的。
從表7,表8可以看出本文檢測模型的整體檢測率要優于其他IDS,整體誤報率要低于其他IDS。但5分類中U2r的檢測結果并不是很好,主要因為在125973條樣本數據中U2r只有52條,數據總量過于少,檢測率沒有其他4類高也是可以理解的;總體上證明了檢測模型的可行性。
5 總結
針對傳統入侵檢測算法對網絡入侵檢測能力不足的問題,本文結合網絡流量數據的特性,提出一個基于Adam-BNDNN的網絡入侵檢測模型,用屬性簡約后的NSL-KDD數據集來仿真實驗,并與其他算法進行了對比分析,從而證明本模型的可行性。下一步工作將搭建真實網絡環境,采集實時數據進行網絡入侵檢測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
