基于決策樹集成學習的桉樹蓄積預估模型研究
2020-03-15 01:15:44李曉偉吳保國蘇曉慧陳玉玲彭意欽于永輝范小虎
中國農業科技導報 2020年6期
李曉偉, 吳保國*, 蘇曉慧, 陳玉玲, 彭意欽, 于永輝, 范小虎
(1.北京林業大學信息學院,林業信息化研究所,北京 100083; 2.廣西壯族自治區國有高峰林場,南寧 530000)
林分生產力的準確預測對森林經營及其方案編制意義重大,是實現人工林可持續經營的基礎[1]。林分蓄積是衡量小班林分生產力的重要指標,國內外學者對蓄積預估模型已有大量研究,構建林分蓄積模型的方法很多,主要為傳統統計建模方法和機器學習方法。傳統方法包括多元非線性回歸方程[2]、借助樹高和斷面積等中間變量的聯立方程組法[3]、混合效應模型法[4-5]。傳統方法是在滿足數據獨立、正態分布和方差齊性等假設前提下進行的,但是由于森林數據的固有變異性,上述假設通常難以滿足[6]。此外,林分蓄積還受林分密度及經營水平等因素影響,林分生長系統具有非線性、復雜性本質特征,使得傳統的數學公式模型難以精準表述[6]。而機器學習方法可對非線性關系進行良好模擬,不僅在預測精度上有明顯優勢,而且應用方便[7],因此,構建機器學習模型進行林分蓄積量預估的研究也越來越多。目前,機器學習方法中應用較多的是人工神經網絡[8-12]。對于非神經網絡方法,林卓等[13]用支持向量機構建福建西北地區杉木人工林蓄積模型,高若楠[14]使用小班數據采用隨機森林方法對東北天然闊葉林蓄積生長量進行預估。決策樹機器學習方法在預測方面表現更好的解釋性,并且通過集成學習方式進行整合,既可以提高預測精度又可以減少產生過擬合的幾率,在生態研究等領域中應用較多[15-16]。但以小班數據為基礎,采用多種決策樹為基礎學習器的集成學習方法對考慮立地條件和密度因子的桉樹(EucalyptusrobustaSmith)人工林進行蓄積預測的研究比較欠缺。本研究以廣西國有高峰林場速生桉為研究對象,構建多種以決策樹為基礎結構器的非集成、集成學習模型,結合年齡、立地條件、密度因素研究蓄積預估。為采用蓄積預估模型作為生產力判斷的泛化研究進行一定探索,并結合具體研究地區為林場速生桉的造林決策提供支持。
1 材料與方法
1.1 研究區概況
研究地點為廣西壯族自治區國營高峰林場,該林場為廣西最大國有林場,位于22°49′N~23°15′N,108°08′E~108°53′E,屬南亞熱帶氣候,夏長冬短,光熱充足,雨量充沛,年平均氣溫在21 ℃左右,極端最高溫40 ℃,最低溫-2 ℃,積溫為7 500 ℃左右,年降雨量為1 200~1 500 mm,多集中在每年6—9月[17-18]。地貌主要由山丘和丘陵構成。海拔為150~400 m,坡度為20~30°。土壤以赤紅壤為主,質地為中壤土或輕粘土。森林植被主要有桉樹、馬尾松(PinusmassonianaLamb)、杉木(CunninghamialanceolataHook)等樹種,其中桉樹類全部為速生桉樹種,主要包括尾葉桉(EucalyptusurophyllaS.T.Blake)、巨尾桉(Eucalyptusgrandis×urophylla)、尾巨桉(Eucalyptusurophylla×E.grandis)。
1.2 研究數據
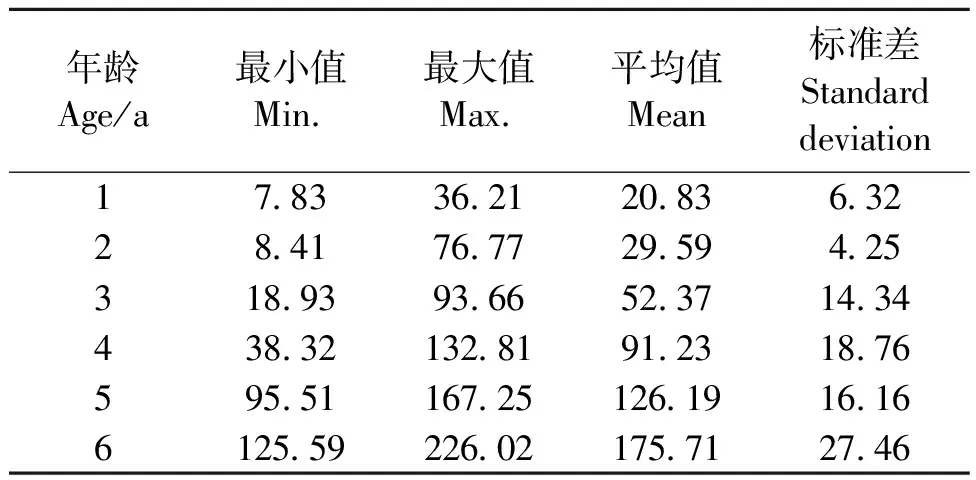
本研究以廣西壯族自治區桉樹人工林為研究對象,選擇2008年高峰林場森林資源規劃設計調查(簡稱二類調查)中優勢樹種為桉樹的3 500個小班以及2010年廣西國家森林資源連續清查(簡稱一類清查)的200個桉樹固定樣地兩個數據源作為研究數據。參照《森林資源規劃設計調查技術規程》[19]與《森林資源數據采集技術規范》[20]確定二類調查、一類清查各因子。提取小班和固定樣地數據中共有的立地因子(海拔高度、坡向、坡位、坡度、枯枝落葉厚度、腐殖質層厚度、土壤種類)和林分因子(林齡、公頃蓄積、公頃株數、平均胸徑、平均樹高)進行整理,其中二類調查數據用作模型訓練與驗證,一類清查數據用作模型泛化測試。用于此建模數據的因子統計量見表1與表2。
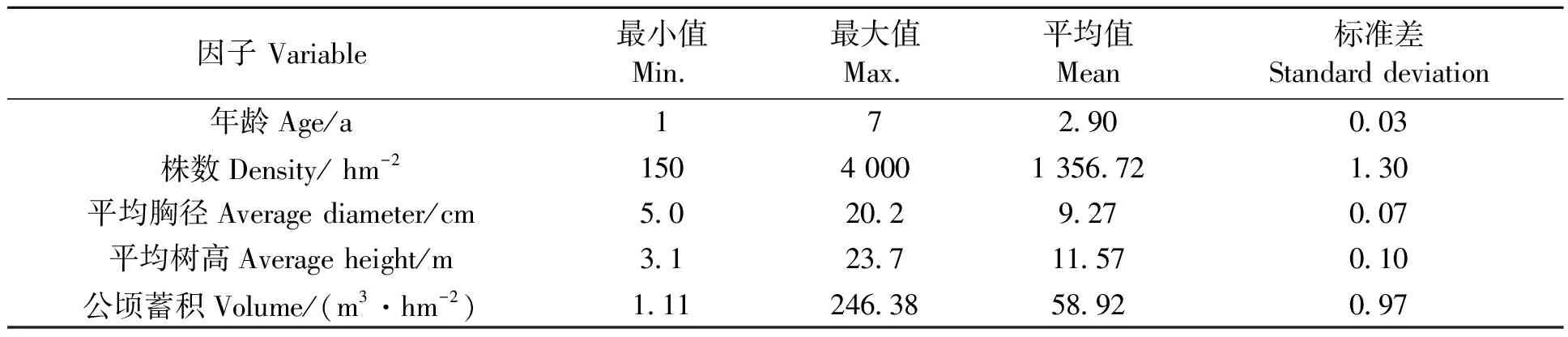
表1 建模數據林分因子統計
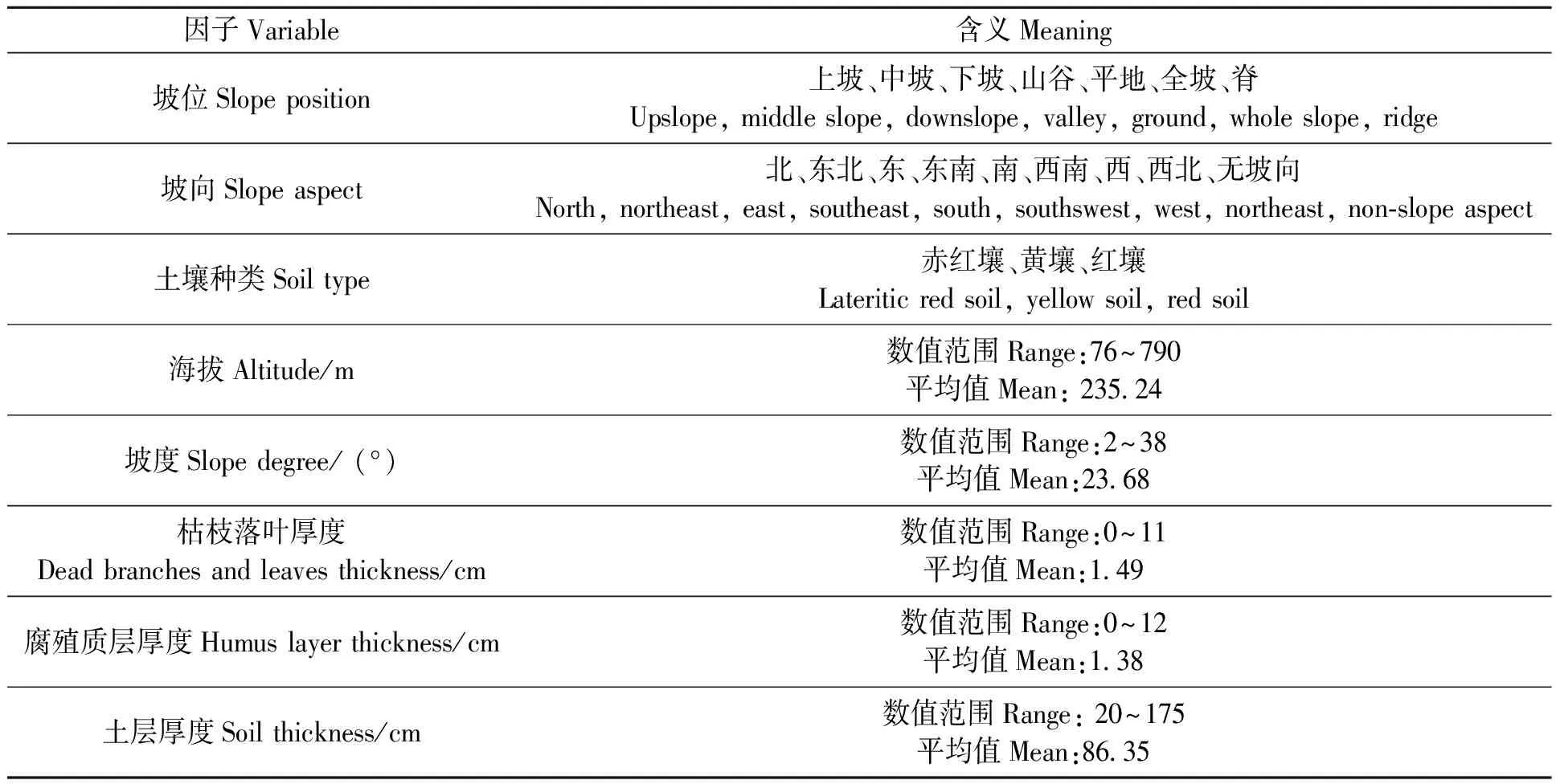
表2 建模數據立地因子統計
1.3 模型構建
集成學習主要分為并行與串行兩種,本文選擇決策樹集成學習構建2種并行算法(Bagging和隨機森林)和2種串行算法(梯度提升決策樹和XGboost)來構建桉樹小班蓄積模型。Bagging(bootstrap aggregating)算法[21]采用隨機有放回的選擇訓練數據。隨機森林[22]在以決策樹為基學習器構建Bagging集成的基礎上,進一步在決策樹的訓練過程中引入了隨機屬性(如小班數據中坡度、土壤厚度等字段)選擇。相比Bagging,隨機森林在當前結點的屬性集合中選擇一個包含m個屬性的集合。隨機森林的基學習器,分別采用CART模型與Ctree模型。梯度提升決策樹GBDT(gradient boosting decision tree)算法[23]基于回歸樹模型,采用迭代的方法最小化損失函數,進而得到最優解。GBDT中每一棵回歸樹結點劃分都是基于之前多個回歸樹的預測結果、采用梯度迭代法訓練新弱分類器,使得新回歸樹的預測結果與實際值之間的損失函數達到最小。回歸問題損失函數設定為均方差函數,其梯度結果與殘差公式一致。回歸樹劃分節點后樣本的取值采用平均值法。XGboost[24]方法作為GBDT的改進,基于梯度提升部分目標函數為損失函數加正則項,損失函數為訓練誤差,正則項為訓練樹復雜度,通過正則項控制模型復雜程度,模型更為精準。
模型構建分為數據清洗與預處理、特征選擇與數據集劃分和訓練模型構建與調優三步,具體流程如圖1所示。采用統計軟件R 3.5.4調用相關包進行模型訓練、驗證與結果分析。

圖1 模型構建流程
Step1:數據清洗與預處理。數據預處理按順序包括干擾數據清除、定性因子量化處理與數據標準化處理。廣西壯族自治區速生桉樹的輪伐期為5~6 a,因此,首先剔除數據中樹木平均年齡大于 6 a 的數據,然后將土壤種類、坡位、坡向定性因子啞變量化[25]轉化為定量因子,最后,由于min-max標準化會受極端值影響,對數據進行Z-score標準化處理,以消除量綱帶來的影響。
Step2:特征選擇與數據集劃分。林分生長的主要影響因子包括立地質量、林分平均年齡、林分密度,因此選擇2個林分因子(年齡和公頃株數,表1)和8個立地因子(表2)作為輸入變量,公頃蓄積量為輸出變量。數據集劃分方式為70%訓練數據集,30%測試數據集,對于驗證數據集部分,不單獨劃分,而是統一采用十折交叉驗證的方法3次重復進行模型驗證。
Step3:參數單值預訓練、參數全范圍模型訓練與調優。采用任一訓練模型,初步選擇參數取值范圍中間值作為參數進行模型預訓練,將其結果做理論性可用性驗證。在理論可行性驗證成功基礎上進行參數全范圍訓練模型構建與調優,選擇非集成與集成兩種方式共9種模型,調用caret軟件包的train函數進行模型訓練。模型構建過程三個方面核心參數、參數訓練范圍見表3。
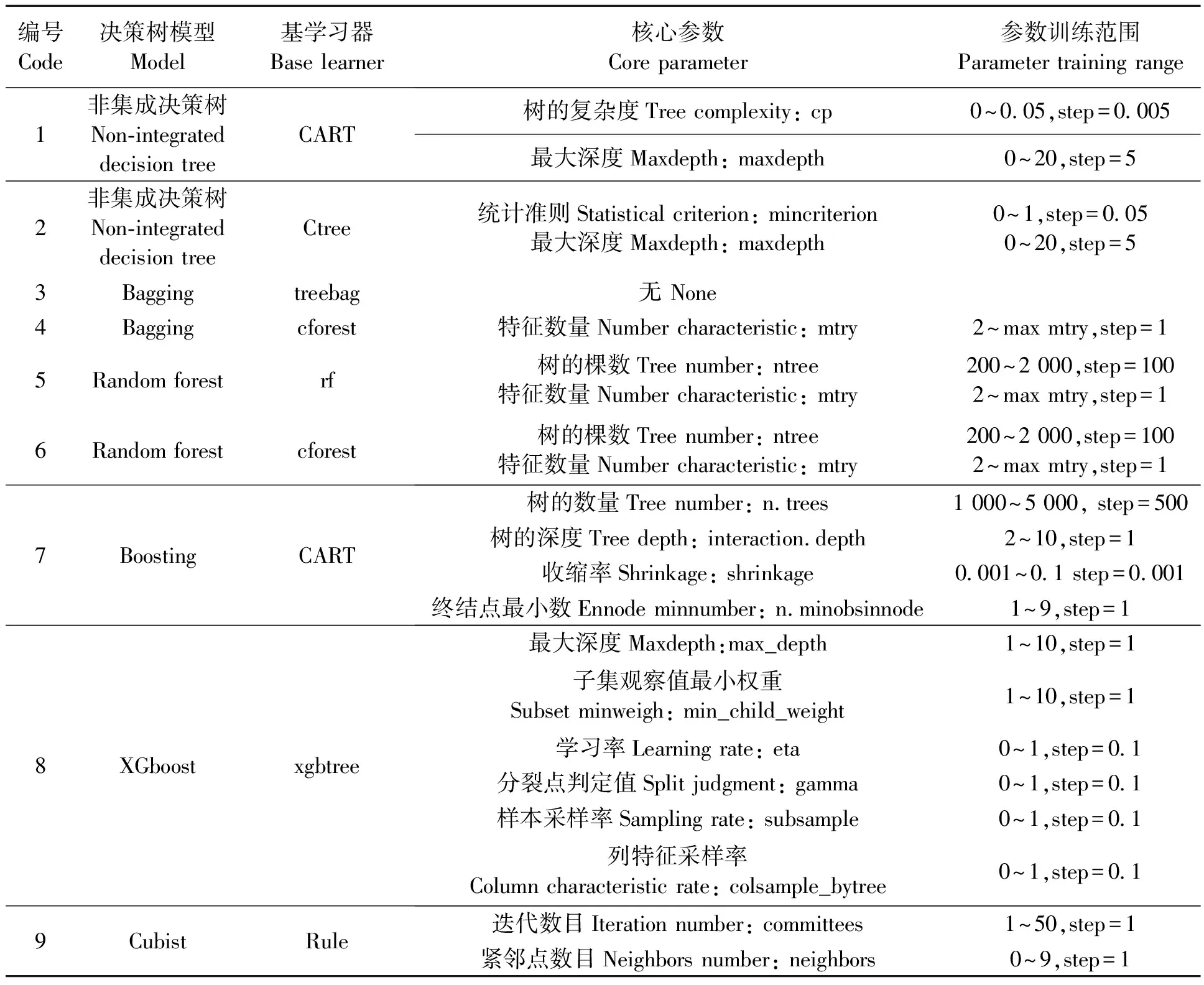
表3 模型構建與調優參數統計表
Step4:模型泛化預估測試。選擇Step3對比結果最優模型,以2015年廣西壯族自治區部分一類清查桉樹數據進行泛化測試,判斷其對廣西所有地區桉樹蓄積預估是否具有泛化性。對于訓練好的最優模型,首先用R語言封裝模型成為函數,之后使利用Java語言構建工程,輸入一類清查數據文件,選擇Step2中特征選擇的10個自變量,使用Rserve模式調用并執行模型程序包文件,計算樣地蓄積預測值[7],與觀測值進行線性回歸分析計算R2與P值,其結果作為泛化測試結果。
1.4 理論性可用性驗證
蓄積預估屬于生長收獲模型,變化應符合生物S型生長曲線規律。隨機選擇一個小班,采用單變量法固定1.3 Step2中8個立地因子以及公頃株數,以時間為自變量,蓄積預估量為因變量,以1.3 Step3預訓練模型作生長曲線圖,評價模型是否符合樹木生長規律,進而判斷模型的理論可用性。若理論可用性通過,進入參數全范圍的模型訓練與調優、模型評價階段。若理論可用性不通過,回到數據預處理部分對針對業務問題對數據再處理。
1.5 模型評價
對于數字評價,交叉驗證模型評價方法采用3個指標進行評價和檢驗,分別是決定系數(R2)、均方根誤差(RMSE)以及平均絕對偏差(MAE)。
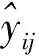
R2越接近1表示模型擬合效果越好,MAE與RMSE相對越低表示模型誤差越小。對于模型訓練集效果,選擇R2與RMSE,對于模型測試集效果選擇RMSE與MAE。
2 結果與分析
2.1 理論可用性分析
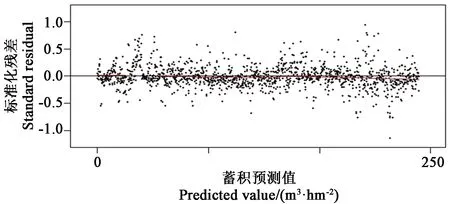
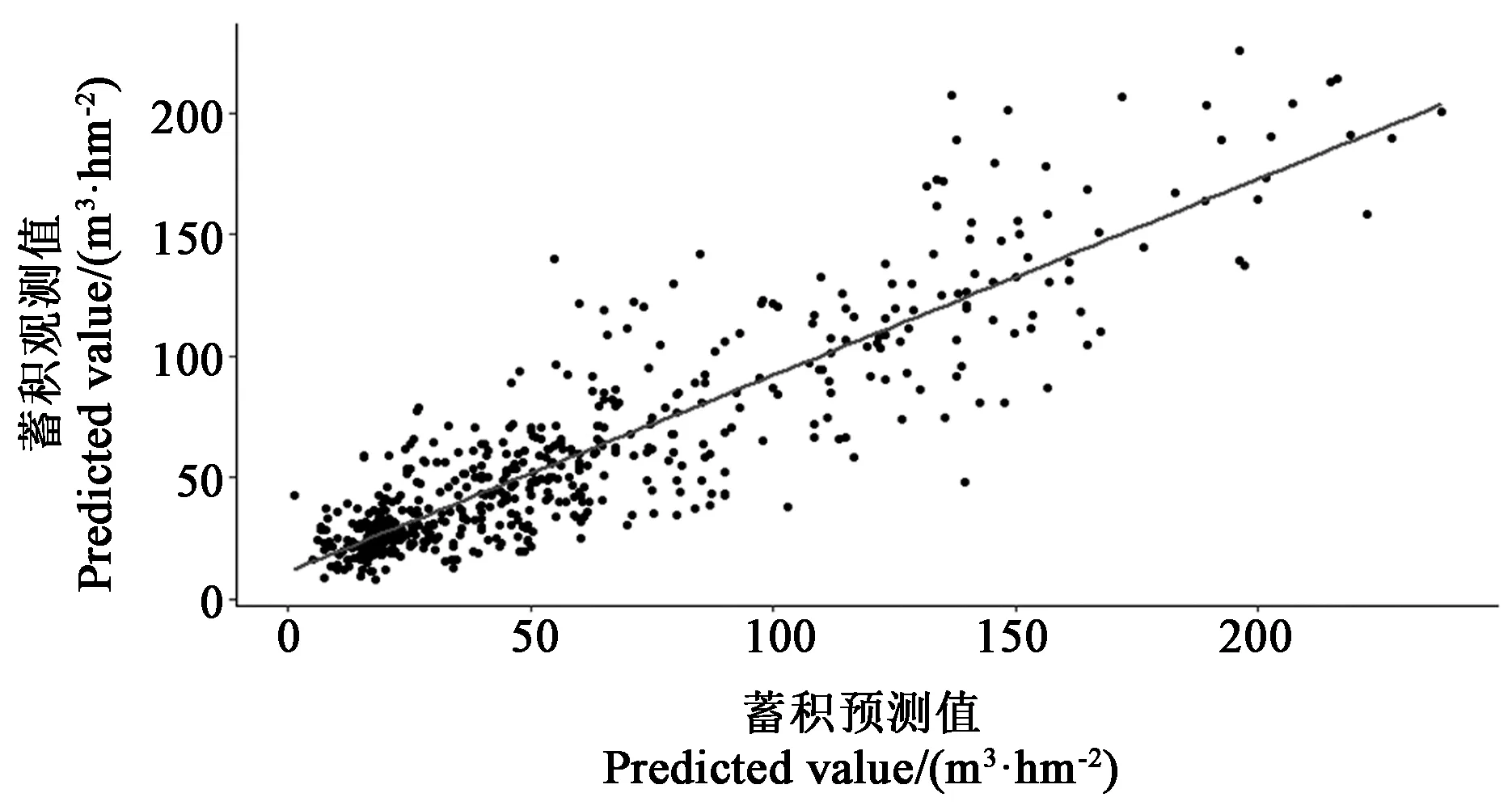
預訓練和修正訓練結果得到圖2所示。發現第5 a蓄積量相較第4 a增長量較小,整體不符合S型生長曲線,因此返回數據預處理階段進行數據再處理。分析原因,該地區桉樹主伐年齡為 5 a,在二類調查時對n<年齡 圖2 理論可用性預訓練與修正訓練結果 表4與表5分別顯示9個模型以最優R2為標準的最優參數組合以及模型在訓練集與測試集中的相關精度指標。 表4 模型訓練最優參數組合 由表5結果可知,相同方法、不同基學習器的模型訓練結果不同。其中單棵樹模型Ctree基學習器相比CART基學習器在訓練集上的R2與RMSE幾乎相同,但是在測試集上Ctree基學習器的R2與RMSE明顯降低。無論訓練集還是測試集,并行集成學習模型R2與RMSE均明顯低于采用CART基學習器模型;而在隨機森林方法中實驗結果出現反轉,即CART基學習器模型各指標在訓練集與非測試集結果均好于Ctree基學習器模型,并且模型整體精度與誤差數字均為相對最低,模型整體效果為前六種中相對最優。 表5 模型訓練與測試結果 非集成學習與集成學習的模型評價量化指標明顯不同,集成學習模型整體優于非集成模型。無論訓練集還是測試集,并行集成學習中采用相同基學習器的隨機森林模型相關指標優于一般并行Bagging方法。串行集成學習方法中模型評價指標R2與RMSE最優的依次為XGboost模型、增強回歸樹模型。對于串行與并行兩種集成學習方式,同時選擇CART作為基學習器,結合模型評價指標,模型訓練集結果由好到壞依次為XGboost、隨機森林、增強回歸樹與Cubist,模型測試集結果由好到次依次為XGboost、隨機森林、Cubist與增強回歸樹。 2.3.1變量重要性評估 選擇非集成決策樹類、并行集成類以及串行集成類中效果最優的CART的單棵決策樹、隨機森林以及XGboost三種模型,計算得到各自變量相對于因變量每公頃蓄積的影響重要性。由圖3可知,對于立地、樹木以及密度三類自變量因子,三種模型的自變量重要性排名幾乎一致,特別是前5名重要性自變量三個模型相同,說明重要的幾個變量對于蓄積預估的影響程度不會因模型不同而改變,只是在貢獻度次序上有相對的改變。對于各自變量重要性排名,占比最高的為樹木因子中的年齡,其對于因變量重要性顯著高于其他因子,三種模型分別為達到86.5%、83.5%、78.0%。其次對于因變量存在影響的三個自變量在CART、隨機森林以及XGboost模型中的重要性數值排序分別為:土層厚度(3.0%)、腐殖質層厚度(2.9%)、海拔(2.4%);土層厚度(4.5%)、密度(3.0%)、海拔(2.4%);海拔(4.9%)、土層厚度(3.8%)、密度(3.2%)。而坡向、坡位、坡度、土壤種類等因素重要性在三個模型中占比都低于1%,影響極小。 注:圖中編號1~10分別為海拔(m)、坡向、坡位、坡度(°)、枯枝落葉厚度(cm)、腐殖質層厚度(cm)、土層厚度(cm)、土壤種類、年齡(a)、密度(hm-2)。 2.3.2模型解釋 相比于其他機器學習模型,決策樹具有一定的模型可解釋性,從而根據其樹杈分支的決策過程可以從中探究各自變量屬性在蓄積預估模型的劃分順序與劃分節點數字,從而對機器學習方法應用于蓄積預估提供更好的解釋性。單棵樹模型相比集成學習方法,從實驗工程的角度可以還原決策的屬性劃分過程,具有更好的模型解釋性。屬性劃分為五級,第一、二級為年齡,第三級為土層厚度與枯枝落葉厚度,第四級為密度與海拔,層級越小劃分屬性影響越大。年齡值、土層與枯枝落葉厚度、密度與海拔值越大,蓄積越大。 模型調用結果如表6所示。由表6可知,桉樹在1~6 a蓄積平均值持續增長,且從第3 a開始蓄積增長值明顯擴大,但是相對應標準差也顯著地提升。殘差整體殘差分布較為均勻,不存在異方差情況(圖4)。模型經檢驗后調整后R2為0.785,P值為2.2e-16,符合檢驗標準(圖5)。 表6 蓄積預估結果 圖4 XGboost模型在泛化測試數據集上殘差圖 圖5 XGboost模型在泛化測試數據集上值的散點圖 本研究選擇二類調查數據用作模型擬合與驗證,選擇一類清查數據用作模型泛化。二類調查數據特點是數據量大,研究范圍相對集中,可以滿足該地區決策樹集成學習等機器學習模型對于數據訓練量的基本要求,并且較多訓練數據量可以在一定程度上增加模型擬合精度。泛化測試即模型對于未知數據預測的相對準確性,兩個核心要求體現在待測試的未知數據不同于訓練數據集所屬地區以防止過擬合以及未知數據精度有一定保證從而可以反饋泛化測試結果。一類清查數據精度相對較高、調查范圍大而分散的兩個特點符合模型泛化測試核心要求。 對于模型判定數字指標,基于二調數據,XGboost在森林蓄積預估問題上有著最優的模型效果,R2超過0.8,同比陳玉玲等[7]采用BP神經網絡模型進行華北落葉松蓄積預估精度有一定的提高。模型泛化應用結果R2為0.785,P值小于0.000 1,符合檢驗,說明該模型精度達到應用水平。本研究以海拔、坡向、坡位、坡度以及土壤相關等立地屬性來作為立地因素,以每公頃種植株數作為密度因素。林卓等[13]、王少杰等[5]分別使用斷面積、計算密度指數作為密度因素。僅考慮變量獨立性以及與其他自變量較小的交互性,株數相對更合適。受年齡影響的林分因子是否可以作為自變量引入模型仍有待討論,李宗俊[26]認為可以先預估林分因子再代入模型進行二次訓練的方法也是參考選項但可能面臨自變量多重共線性等問題。 決策樹模型相比神經網絡可以避免潛在的數據的過度擬合等特點[7]。集成學習方法精度顯著高于非集成方法,原因在于單一的決策樹模型具有一些不足,如模型的不穩定性(數據中微小的變動可能會引起樹的巨大變化,從而影響解釋性)、次優的預測能力等[27]。作為基學習器的模型,在集成學習方法上CART效果好,非集成學習上條件推斷樹更好。采用串行集成學習方法普遍好于一般并行集成學習,但是若并行集成考慮到隨機性而采用隨機森林的方式則與串行集成學習差異不明顯,該結果與Fernández-Delgado等[28]關于回歸問題采用的多種機器學習方法對比研究結果一致,原因是相比于條件推斷樹對于切分結果偏度的糾正,隨機森林在切分屬性的選擇上的隨機性改變更有效的減小了誤差,說明基于屬性劃分的選擇對于誤差的影響效果要大于切分后切分值的偏度修改。模型參數訓練范圍與歐強新[19]的研究類似,但是最優參數組合存在明顯不同,說明因變量、自變量屬性的不同會影響同類模型的訓練情況。對于集成學習,本研究探討了并行與串行兩種方式,后續可以采用混合集成方式進一步研究。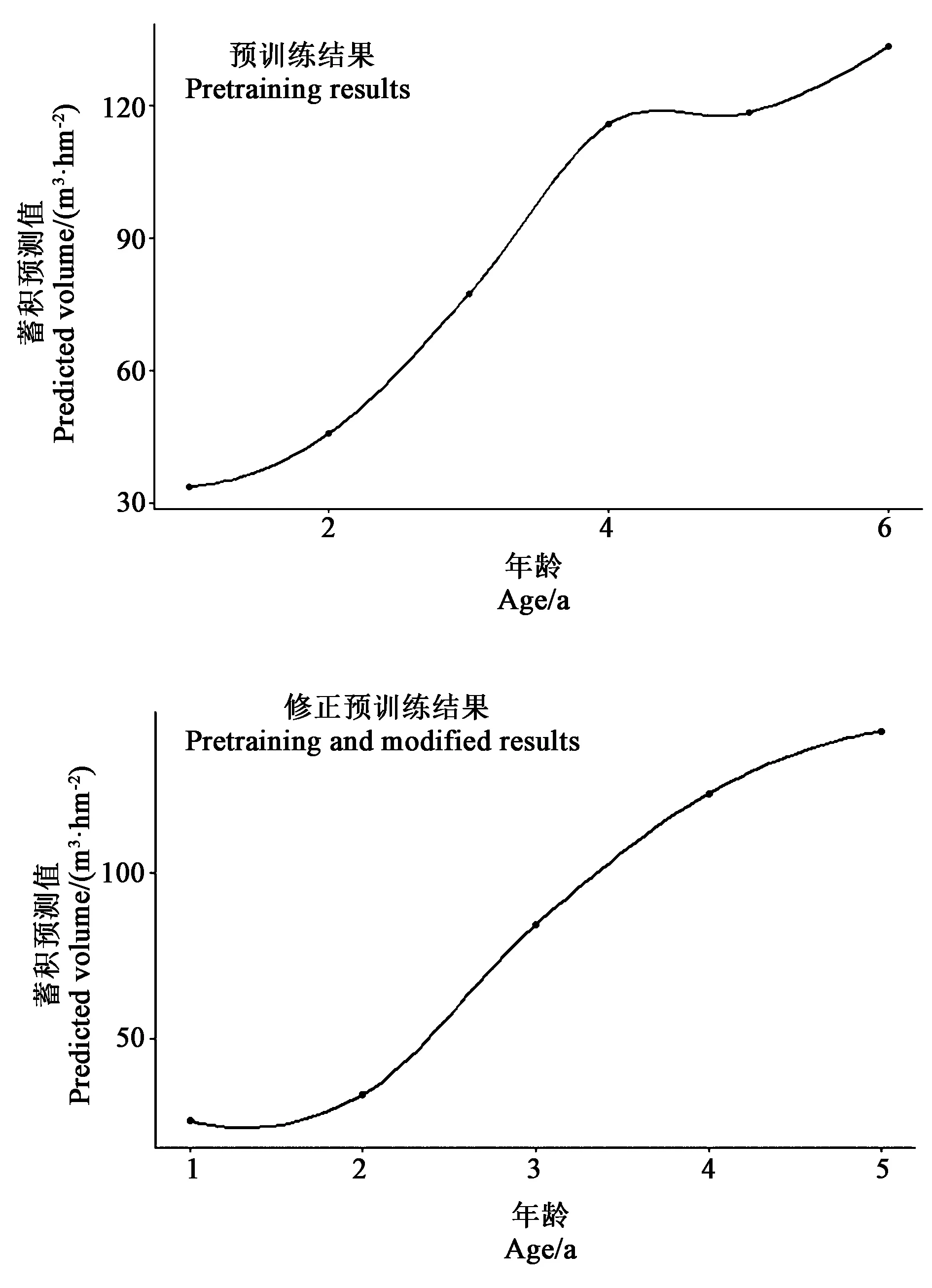
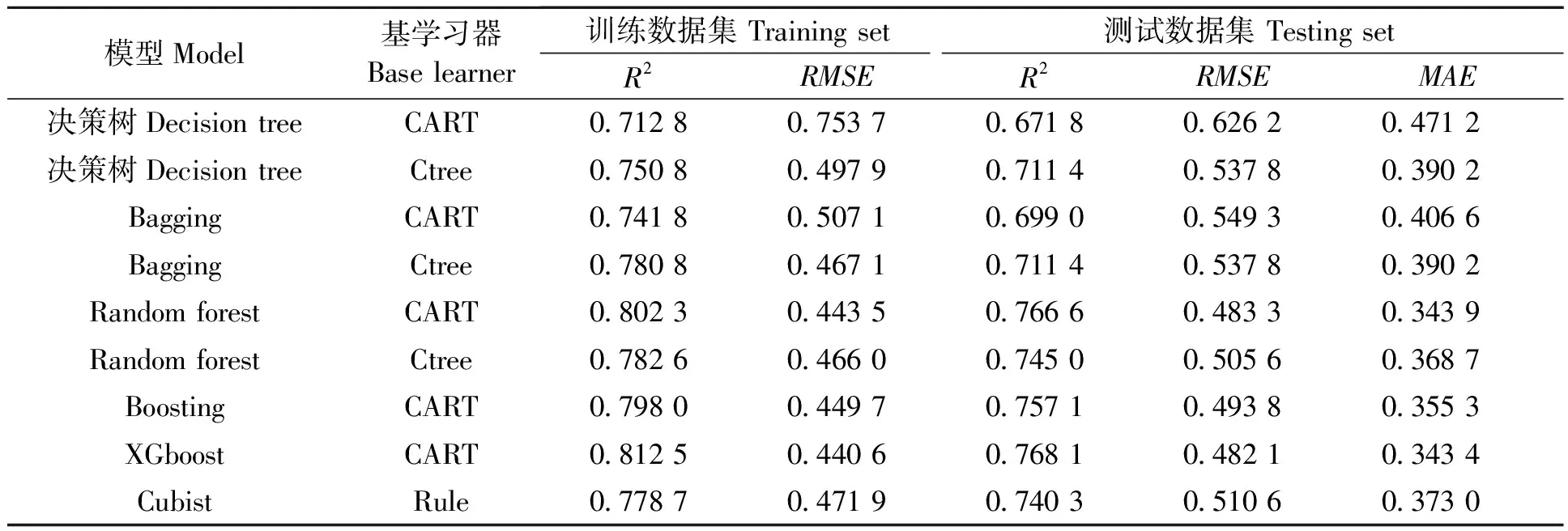
2.2 模型結果與對比分析

2.3 模型變量重要性評估與解釋

2.4 模型泛化預估
3 討論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
