基于樹模型的企業信用風險管理預測
2020-03-15 05:49:21王濤
科海故事博覽·中旬刊 2020年2期
關鍵詞:機器學習
王 濤


摘 要 隨著大數據時代的來臨,信用越來越成為機構與機構之間和機構與政府之間能夠順利溝通的重要因素,但由于難以獲取中小企業的數據,針對一些企業征信的報告的研究探索分析還不夠豐富。然而企業信用預測不僅能夠分析出影響企業信用風險的重要特征,而且還可以對企業的抗風險能力作出預測,可見本文其重要意義。隨著機器學習的熱潮,決策樹算法發展最近幾年火速發展,該算法優點繁多,穩定,生成的決策規則易于理解,易于解釋,因此我們主要根據C&RT決策樹、隨機森林、梯度增強樹,這三個模型分別對中小企業的信用風險進行預測,對比分析,希望通過分析征信報告中所列特征的數據,能夠識別出高違約風險的企業,以達到警示放貸風險的目的。
關鍵詞 機器學習 決策樹 Bootstrap 隨機森林 adaBoost GBDT
中圖分類號:TP311.13 文獻標識碼:A 文章編號:1007-0745(2020)02-0052-03
在數據挖掘中決策樹方法[1]是一個有效并且常用的方法。它的目標是創建一個模型來預測樣本的目標值。這種決策樹的自頂向下歸納是貪心算法[2]一種,也是目前為止最為常用的一種訓練方法,與相對其他的訓練方法相比,決策樹最大的特點是符合人類的直覺,根據某些條件進行分類,具有很強的解釋性,有利于分析影響因素,[3]可使用決策樹方法分析影響違約風險因素。
隨機森林是一個包含多個決策樹的分類器,并且其輸出的類別是由個別樹輸出的類別眾數而定。隨機森林的引入最初是由Leo Breiman[4]在一篇論文中提出的。這篇文章描述了一種結合隨機節點優化和Bagging,利用了C&RT[5]過程構建不相關樹的森林的方法。梯度提升是一種用于回歸和分類問題的機器學習技術,其產生的預測模型是弱預測模型的集成,如采用典型的決策樹作為弱預測模型,這時則為梯度提升樹(GBDT)。梯度提升的思想源自Leo Breiman[6]的一個觀察:可以將提升方法解釋為針對適當成本函數的優化算法。也就是通過不斷的弱分類模型集成最終得到一個強分類器。
本文第一部分概述,第二部分介紹C&RT決策樹、隨機森林、梯度增強樹的基本理論,第三部分進行數據預處理,第四部分進行數值實驗,第五部分結論。
1 模型
在本篇文章中我們從最基本的決策樹模型開始,延伸到隨機森林、梯度提升樹,介紹這些模型的基本概念、核心思想、以及三者之間的對比差異,接下來再對三個模型進行數據實驗,分析不同效果。
1.1 決策樹
決策樹是一個傳統的根據條件聚集的學習模型,在這里我們主要分析classification and Regression Tree(C&RT)。那么我們的決策樹模型可以表示為:
其中,c為每一個分支,G(x)為全體樹,b(x)為分枝規則, 為在c分枝時的子樹。我們主要從三個角度來討論C&RT。
(1)分枝的數量:由于是C\&RT樹,那么我們假設每個節點都有且只有兩個子節點。
(2)分枝規則:
其中h(x)是分枝函數,分為左枝(c=1)和右(c=2)枝。上式第一項表示左(右)枝的數據集大小,第二項表示左(右)枝的純度大小。對于二分類決策樹來說,我們的純度用基尼指數來衡量
其中k是種類,n代表樣本數量,是當時等于1,否則等于0。
(3)分枝終止條件:所有的y都一樣,也就是純度等于0。所有的x都一樣,則無法分為左右枝。
依據以上的三個條件,我們可以建立算法表示C&RT決策樹模型。
現在討論過擬合情況,我們需要剪枝。設為訓練模型的誤差,那么對于過擬合情況來說則有,導致測試誤差大幅上升。為了降低擬合度,我們加入一個正則項:表示G樹的葉子數量。那么轉化為問題:
其中表示權衡參數。我們實驗時可以條件參數控制決策樹的深度,這個深度由葉子的數量來衡量,進而調控模型的過擬合程度[7]。
1.2 隨機森林
從決策樹的推導過程中發現,決策樹容易重現過擬合現象,也就是說當我們的測試集合不一樣時,預測的方差比較大,為了降低這個方差,我們引入隨機森林[8]。首先在這里引入Bootstrap[9]:采用重復抽樣方法從初始樣本中抽取一定數量的樣本,此過程允許重復抽樣。應用這個方法我們可以估計到很多不同的目標函數,然后再來求這些目標函數的均值即得到最終的目標函數。我們將C&RT與Bootstrap結合起來,也就是說我們有以下過程:
(1)從總樣本n中,抽取樣本數量;
(2)由此樣本訓練C&RT模型,得到目標函數;
(3)返回第一步,并且重復N次;
(4)最終目標函數為。
在實驗的時候,我們可以控制N的大小,進而控制模型的擬合度。
1.3 梯度提升樹(GBDT)
首先梯度提升樹是自適應增強Adaboost和C&RT的結合。那么我們先來介紹AdaBoost。AdaBoost方法[10]是一種迭代算法,它通過輸入不同弱分類器,不斷的調整樣本匹配權重,得到新的弱分類器,最后將所有分類器疊加[11],那么Adaboost可以轉化為下面這個優化問題:
其中h(x)是第t次擬合數據最佳的梯度變化量,也就是先求出第t次的gt,然后再求其對應的最佳,最后我們求得的目標函數是,對應的GBDT可以轉化為下面的優化問題:
其中,那么稱為殘差。因此,在使用平方損失函數時,GBDT算法的每一步在生成決策樹時只需要擬合前面的模型的殘差。
2 數據預處理
在這一部分我們首先對數據作簡單的介紹,用python對數據做缺失值處理,為了從特征中提取更多的信息,必須對特征進行特定屬性處理。針對本文章的數據特點,出現了類別不平衡的問題,下面我們給出具體的解決辦法。
2.1 數據介紹
數據來源于全國部分中小企業的政府登記數據,樣本數量為14366個,178個特征,1個標簽。特征主要有以下部分:ID、企業類型、經營期限至、登記機關、企業狀態、郵政編碼、投資總額、核準日期、行業代碼、注銷時間、經營期限自、成立日期、行業門類、企業類別、管轄機關、經營范圍、城建稅、遞延收益、長期負債合計、長期借款、長期應付款、短期借款、遞延所得稅負債、非流動負債合計、負債合計等共178個。
2.2 缺失值處理
查看發現許多特征缺失嚴重。我們特別刪除缺失比例超過70%的特征:經營期限至,投資總額,注銷時間。
下面分析每個特征和標簽之間的相關系數,并刪除相關系數不存在的特征,即:長期負債合計_年初數,其他負債(或長期負債)_年初數,其他應交款_年初數,應付福利費_年初數,預提費用_年初數,長期負債合計_年末數等。經查看這些數據不僅缺失嚴重,而且值變化方差很小,故刪去。
最后對類型數據處理:郵政編碼、核準日期、經營期限、成立日期、經營范圍和特殊無信息特征ID,由于處理較困難,這些特征都刪去。
在這些處理之后我們有152個特征,1個標簽。為簡單起見,我們給每一列特征的缺失值賦值為該特征的均值。
2.3 類別不均衡處理
查看標簽值{0,1}在樣本中所占的比例,我們發現未違約所占比例為93.4%,違約比例為6.6%,那么在這里我們需要處理類別不平衡問題。在這里主要有三種方式,我們主要采用第三種方式,對數據進行擴充。
(1)對較多的那個類別進行欠采樣(under-sampling),舍棄一部分數據,使其與較少類別的數據相當。
(2)對較少的類別進行過采樣(over-sampling),重復使用一部分數據,使其與較多類別的數據相。
(3)對數據進行采用的過程中通過相似性同時生成并插樣“少數類別數據”,叫做SMOTE算法。具體SMOTE算法介紹可以參考[12],SMOTE算法是對較少數類別的樣本進行擴充,擴充的方法類似于k近鄰方法進行樣本間差值,最后得到新的數據集合。
3 數值實驗
這一部分主要介紹擬合模型、參數的選擇、以及擬合的效果與分析。主要利用三個模型來進行擬合數據。
·決策樹
·隨機森林
·梯度上升樹(GBDT)
我們將數據的70%的作為訓練集合,數據的30%作為測試集合,并做10層的交叉驗證。
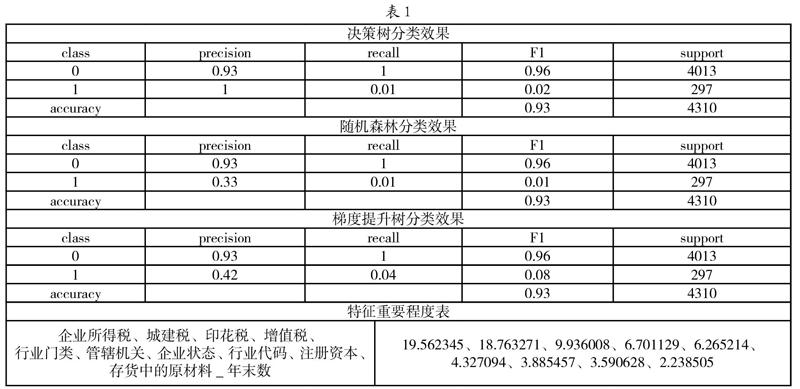
經查看表,我們可以看出企業所得稅、城建稅、印花稅對企業信用風險的影響因素最大(如表1)。下面對幾個稅種做簡要介紹。
企業所得稅:是對我國境內的企業和其他取得收入的組織的生產經營所得和其他所得征收的一種所得稅。
城建稅:是以納稅人實際繳納的產品稅、增值稅、營業稅稅額為計稅依據。該稅主要有以下兩個特征:(1)以納稅人實際繳納的產品稅、增值稅、營業稅稅額為計稅依據,分別與產品稅、增值稅、營業稅同時繳納;(2)加強城市的維護建設,擴大和穩定城市維護建設資金的來源。
印花稅:是對經濟活動和經濟交往中訂立、領受具有法律效力的憑證的行為所征收的一種稅。因采用在應稅憑證上粘貼印花稅票作為完稅的標志而得名。
再者對比分析三個模型,我們可以得到以下結論:
(1)決策樹在識別違約企業中,準確率最高。
(2)隨機森林和GBDT這兩個模型效果差不多,因此復雜模型針對風險問題可能是無力的。
(3)說明簡單模型的在某些情況下有可能是最好的。
4 結論
在中小企業信用評估過程中,企業借款違約不歸還本金和利息是比較常見的現象。如何控制企業風險是中小企業健康發展的關鍵。本文站在銀行角度,研究企業這一主題的信用違約風險的方法。通過總結和比較目前信用評估模型的基本原理和優缺點,提出了應用集成學習方法改進決策樹模型來度量企業信用違約風險的思路。
本文采用的數據是全國部分中小企業的政府登記數據。我們采用協方差矩陣的形式,摘除部分步相關特征,在此數據的基礎上做缺失值處理。然而由于本數據類別不平衡問題嚴重,我們采用SMOTE算法進行數據預處理。接下來用決策樹,隨機森林,GBDT來進行分類評估效果,并取得了滿意的效果。
本文的主要結論如下:
第一:本文以中小企業這一貸款主體參與主體為切入點,研究其違約風險度量方法的問題,目前國內外對中國國內中小企業信用違約風險度量較少且都不夠深入,本文將中小企業信用風險評估與集成學習聯系在一起,對中小企業的違約風險進行了初步探究與度量。
第二:本文終結了決策樹中集中流行的風險評估方法及其它們的應用。通過比較幾類模型的優缺點和幾種模型的側重點得到:決策樹容易過擬合,隨機森林可以有效的降低過擬合,GBDT可以關注于分錯的目標,提高分類的準確率,進而得出在本數據情況下,決策樹模型在識別企業有信用違約風險有很大優勢。
第三:本文最后得出對中小企業風險影響的重要特征有以下十項:企業所得稅、城建稅、印花稅、增值稅、行業門類、管轄機關、企業狀態、行業代碼、注冊資本、存貨中的原材料_年末數,可以看出對中小企業運行影響最大的因素是稅收,隨著這幾年中小企業生存環境惡劣,對中小企業減稅不乏是一種很不錯的政策。
參考文獻:
[1] QUINLAN J R.Simplifying decision trees[J].International journal of man-machine studies,1987,27(03):221–234.
[2] BLACK P E.Greedy algorithm[J].Dictionary of Algorithms and Data Structures,2005:2.
[3] 唐劍琴.基于決策樹算法的P2P網貸借款人違約風險度量研究[D]. 湖南師范大學.2016.
[4] BREIMAN L.Random forests[J].Machine learning, 2001,45(01):5–32.
[5] SHALEV-SHWARTZ S,BEN-DAVID S.Understanding machine learning:From theory to algorithms[M].[S.l.]:Cambridge university press,2014.
[6] BREIMAN L.Arcing the edge[R].[S.l.]:Technical Report 486,Stati stics Depart-ment,University of California at...,1997.
[7] ABDI H,WILLIAMS L J.Principal component analysis[J].Wiley interdisci-plinary reviews:computational statistics,2010,02(04):433–459.
[8] RODRIGUEZ J J,KUNCHEVA L I,ALONSO C J.Rotation fore st:A new clas-sifier ensemble method[J].IEEE transactions on pattern analysis and machine in-telligence,2006,28(10):1619–1630.
[9] BREIMAN L.Bagging predictors[J].Machine learning,1996, 24(02):123–140.
[10] FREUND Y,SCHAPIRE R E.A decision-theoretic generalization of on-line learning and an application to boosting[J].Journal of computer and system sci-ences,1997,55(01):119–139.
[11] FRIEDMAN J H.Greedy function approximation:a gradient boosting machine[J].Annals of statistics,2001:1189–1232.
[12] CHAWLA N V,BOWYER K W,HALL L O,et al.SMOTE:synthe tic minority over-sampling technique[J].Journal of artificial intelligence research,2002,16:321–357.
上海對外經貿大學,上海
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
