低頻快速切比雪夫矩的篡改圖像檢測算法①
2020-03-18 07:55:18鄭佳雯張威虎
計算機系統應用 2020年3期
鄭佳雯,張威虎
(西安科技大學 通信與信息工程學院,西安 710054)
數字圖像處理技術的快速發展在給人們帶來生活便捷的同時,也存在著圖像本身的真實性和完整性等問題,目前篡改后的數字圖像出現在醫學研究、新聞報道或法庭證據等重要場合,這會對社會造成極大的負面影響,因此,對于檢測數字圖像是否真實得到了人們的密切關注.當前圖像篡改檢測算法主要分為兩大類:一是主動檢測算法,另一種是被動檢測算法[1].被動檢測算法在沒有任何先驗信息的情況下,利用圖像的本身特性對原圖像進行真實性檢測,此類檢測算法已經得到了廣泛應用[2].
復制粘貼篡改是生活中常見的圖像篡改方式.復制粘貼篡改圖像的檢測方法可以分為兩類:基于特征點的檢測算法和基于圖像塊的檢測算法,基于圖像塊的算法在準確定位到篡改區域上優于基于特征點的算法.Ryu SJ 等[3]提出了一種基于Zernike 矩定位復制圖像區域的算法,設計了一種局部敏感散列的新型塊匹配,并通過檢查矩的相位來減少誤匹配,但對于較大尺度變換的檢測效果不是很好.Dixit R 等[4]利用傅里葉-梅林變換和對數極坐標映射以及使用K 均值聚類的基于顏色的分割技術,具有較好的平移和旋轉不變性,但算法的實時性差.谷宗運等[5]提出了一種基于Tchebichef矩的篡改圖像檢測算法,比較提取的DWT 和Tchebichef矩相鄰特征向量的相似性,實現篡改區域的定位,但對于多區域篡改區域定位效果較差.
針對上述算法的不足,本文提出一種低頻快速切比雪夫矩算法的篡改圖像檢測算法,首先采用非抽樣小波變換對圖像二維分解,對低頻部分進行重疊分塊,再提取圖像塊的快速切比雪夫矩特征,采用PatchMatch算法對特征向量進行匹配,最后用稠密線性擬合算法消除誤匹配以及形態學操作定位篡改區域.
1 構造特征向量
1.1 Tchebichef 矩
假設圖像f(x,y)上一點(p,q),位于大小為N×N圖像塊(p,p+N-1)×(q,q+N-1),其n+m階Tchebichef 矩為[6]:

其中,tn(x)和tm(y)為n階和m階正交切比雪夫多項式,定義如下:

其中,(·)l表示階乘冪.tm(y)定義類似.
正交切比雪夫多項式在x 處的tn(x)和在x+a處的tn(x+a)有如下關系[7]:

當a=1 時,有:
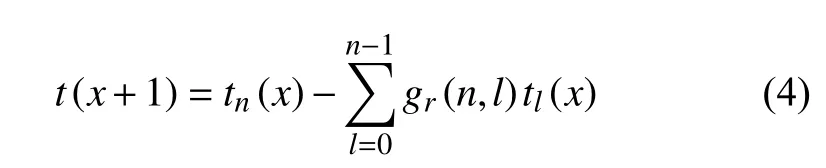
其中,gr(n,l)定義為:

1.2 改進的低頻快速Tchebichef 矩
對于圖像篡改,如果非平移不變,在復制和粘貼兩個相同的區域會被破壞,會出現漏檢情況.下采樣使得離散小波變換(DWT)不具有平移不變性,不僅會對DWT 系數產生巨大影響,還會對篡改區域產生不同的特征向量.另外,DWT 的偽吉布斯現象使得檢測邊緣和紋理等信號的效果不夠理想.對于DWT 存在的不足,這里采用具有平移不變性的非抽樣小波變換(UWT),由于UWT 不包括下采樣和小波系數縮減,因此稱為非抽樣的[8].
對圖像利用UWT 沿行和列進行二維分解,分別得到4 個子帶,即水平高通子帶LH,垂直高通子帶HL、對角高通子帶HH 以及低通子帶LL,每個子帶的尺寸不發生變化[9].
圖像進行過UWT 后,由于圖像的主要部分是低頻部分,所以提取圖像的低頻部分.對提取的低頻部分進行檢測,可以大大降低塊的個數,使得計算量僅為原來的1/4,同時低頻對噪聲不敏感,也可以加強特征的魯棒性.再對圖像進行分塊,假設待測圖像大小為M×N,用a×a像素的滑動窗口每次移動一個像素點對圖像進行掃描,可以得到(M-a+1)×(N-a+1)個重疊塊.
對于一個大小為N×N滑動塊(p+1,p+N)×(q,q+N-1),其n+m階水平方向的Tchebichef 矩為:


相同地,對于下一個大小為N×N滑動塊(p,p+N-1)×(q+1,q+N),其n+m階垂直方向的Tchebichef 矩為:

T分別表示輸出行f(p+x,q),0 ≤x ≤N-1,m階切比雪夫矩和輸入行f(p+x,q+N),0 ≤x ≤N-1,m階切比雪夫矩,定義如下:

基于上述理論,對于圖像f(x,y),低頻快速切比雪夫矩算法如下:
(1)對圖像進行UWT 二維分解,提取其低頻部分并進行重疊分塊;
(2)計算切比雪夫多項式和系數矩陣;
(3)計算所有的行向量.對于圖像f(x,y)每行的第一個行向量,計算其切比雪夫矩,每行的其余行向量計算其快速切比雪夫矩;
(4)計算所有的列向量的切比雪夫矩;
(5)計算圖像f(x,y)第一個塊的矩特征,基于步驟(4)的結果,采用快速切比雪夫矩計算第一行的所有塊的矩特征;
(6)基于步驟(2)和步驟(4)的結果,采用快速切比雪夫矩計算其他塊的矩特征.
2 PatchMatch 算法匹配
本文采用PatchMatch 算法進行特征匹配,它是一種圖像塊之間尋找最近鄰匹配的快速隨機算法,將正確的偏移量傳播并且迭代更新至全部偏移量,相比較傳統的kd-tree 算法而言,不僅可以大大減少處理時間,還可以提供準確的匹配率[11].算法步驟如下:
(1)初始化.對于每個像素s,隨機初始化偏移量:

其中,U(s)是一個二維隨機變量,并且均勻分布在整個圖像.由于我們正在尋找與目標相對較遠的匹配,這里我們不考慮 δ(s)=0,以及所有偏移量小于給定閾值的情況.雖然大多數初始隨機偏移量很少用到,但也有可能是最優的或近似最優的.
(2)傳播.在這個階段,圖像按照從上到下、從左到右的順序光柵掃描,則每個像素s偏移量更新為:

其中,ΔP(s)={δ(s),δ(sr),δ(sc)},sr和sc分別表示光柵按行和列掃描的像素s之前的像素.每個像素判斷相鄰塊的偏移量是否提供了更好的匹配,如果是,則采用相鄰塊的偏移量.若給定區域像素具有恒定偏移量,就可獲得正確偏移量,并迅速傳播,填充整個區域的下方和右側.每次迭代更新時,按照反轉的光柵順序(從下到上、從右到左)掃描圖像,以獲得更準確的偏移量.
(3)隨機搜索.由于傳播過程依賴于隨機初始的偏移量,所以不能達到最優匹配.為了盡量避免陷入局部最小值,采用隨機搜素,在修正式(13)后,對當前偏移量進行隨機采樣,設候選偏移量δi(s),i=1,···,L為:

其中,Ri是一個二維隨機變量,并且均勻分布在除去原點的半徑為2i-1的方形區域中.事實上,大多數的候選偏移量非常接近δ(s),隨機搜索后偏移量更新為:

其中,ΔR(s)={δ(s),δ1(s),···,δL(s)}.
3 后處理
除了平滑區域之外,通過特征匹配獲得的偏移量應該是細節化的.但是由于噪聲、壓縮、幾何變換、光照變化和相似區域等原因[12],PatchMatch 算法獲得的偏移量很少遵循該情況,因此后處理階段需要:(1)對偏移量進行正則化.(2)添加適當的約束.
由于隱式過濾得到的偏移量已經足夠規則,所以需要添加適當的約束.這里采用稠密線性擬合的方法[13],這是因為它復雜性低并且可以快速地得到正確的偏移量.
通過仿射模型,在像素s的適當N像素鄰域內擬合出真實偏移量:
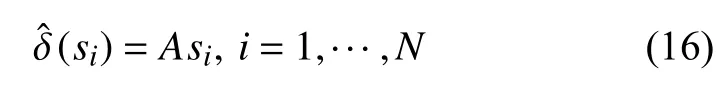
轉換參數A,設置為平方誤差之和的最小值.

雖然偏移量是二維的,但是參數A 可以針對每一維進行獨立地優化,因此,可以將 δ(x)視為一維偏移量,問題轉化為:

其中,δ=[δ(s1),δ(s2),···,δ(sN)]T是匹配階段的偏移量,a=[a0,a1,a2]T是識別仿射模型的參數向量,S是鄰域內所有像素齊次坐標的N×3 矩陣.

因此真實偏移量為:

這是一個多元線性回歸問題,解為:

因此,相應的平方誤差之和為:

H=S(STS)-1ST
其中,是對稱的,進一步簡化H矩陣為:
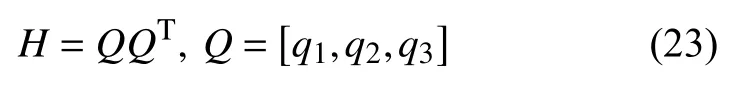
其中,qj為N行列向量,所以,有:

下面給出具體的后處理步驟:
(1)對得到的偏移量進行中值濾波操作.
(3)去除誤匹配對,包括較匹配區域對的距離像素更接近的匹配對,或小于匹配區域面積像素的匹配對.
(4)映射檢測到的區域.
(5)使用圓形的結構元素進行形態學操作,實現篡改圖像區域的定位完成檢測.
為了證明稠密線性擬合方法的有效性,對篡改圖像后處理階段的進行檢測,如圖1 所示.由圖1 可知,匹配階段的偏移量已經足夠規則,但還存在較多誤檢,后處理階段采用稠密線性擬合方法可有效降低誤檢率.

圖1 篡改圖像后處理的檢測結果
4 實驗分析
實驗是在Windows10 操作系統下,采用Matlab 軟件測試的.為了驗證本文方法的可行性和有效性,實驗采用的數據集為benchmark data[14],該數據集包括48 幅原圖像以及48 幅篡改圖像,篡改區域包括單區域和多區域.同時將本文方法與文獻[5]和文獻[14]進行對比來證明本文方法的優越性.
性能分析主要包括圖像層面和像素層面,本文從像素層面來衡量篡改檢測算法的性能,采用precision、recall和F這3 個指標,定義如下:

其中,precision為檢測準確率,即檢測為篡改圖像的數據集中有多少是真正的篡改圖像,包括把篡改圖像檢測為篡改圖像及把真實圖像檢測為篡改圖像;recall為檢測召回率,即數據集中的篡改圖像有多少被正確檢測了,包括把篡改圖像檢測為篡改圖像及把篡改圖像檢測為真實圖像;F為綜合評價指標.TP為篡改圖像中被正確檢測到的篡改像素數量,FP為篡改圖像中未篡改部分被檢測為篡改像素的數量,FN為篡改圖像中的篡改部分未被檢測到的篡改像素數量.precision和recall這2 個評價指標相互制約,F綜合考慮了這兩個指標,F值越大,算法的檢測性能越好.
本文對篡改區域為單一區域和多區域分別進行了實驗,單區域篡改圖像的檢測結果見圖2,單區域多次篡改圖像的檢測結果見圖3,多區域篡改圖像的檢測結果見圖4,表1 為3 種算法篡改檢測性能的比較.

圖2 單區域篡改圖像的檢測結果

圖3 單區域多次篡改圖像的檢測結果

圖4 多區域篡改圖像的檢測結果
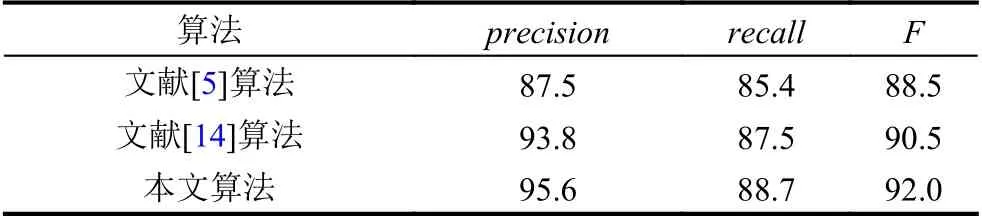
表1 3 種算法檢測性能的比較(%)
由圖2~圖4 可知,文獻[5]和文獻[14]都會出現漏檢測的情況,尤其對于圖4(c)出現兩個不同的篡改區域,而只定位出一個篡改區域,雖然文獻[14]的檢測結果優于文獻[5]的檢測結果,但是檢測到的篡改區域還是會遺漏一些篡改區域的細節信息,綜合來說,本文算法的檢測結果是最好的.為了更加準確地體現本文算法的優越性,由表1 可知,本文算法的綜合評價標準F是最高的,其中precision分別提高了8.1%和1.8%,recall分別提高了3.3%和1.2%,F分別提高了3.5%和1.5%,與上圖中的檢測結果一致.這是因為文獻[5]采用DWT 和Tchebichef 矩結合的特征向量,比較其相似性定位篡改區域,特征向量沒有很好地表示篡改圖像信息,會存在漏檢測的情況;文獻[14]對每個重疊分塊提取快速切比雪夫矩特征,特征匹配使采用kdtree 算法,kd-tree 算法不能很好地實現篡改圖像的匹配;本文算法采用低頻快速切比雪夫矩作為特征向量,PatchMatch 算法進行特征匹配,最后用稠密線性擬合算法消除誤匹配,這樣可以較好地描述圖像信息,防止漏檢和誤檢的情況.
我們還比較了本文算法和文獻[5]和文獻[14]在數據集benchmark data 中每幅圖片的平均運行時間,來證明本文算法的實時性,實驗結果如表2 所示.由表2可知,除了圖3(b)之外,其他圖片都是本文算法的運行時間最短,最后一列是數據集中每幅圖片的平均運行時間,可知本文算法的平均運行時間是最短的.這是由于本文算法采用UWT 實現圖像分解,提取低頻部分的快速切比雪夫矩特征,并且采用PatchMatch 算法進行匹配,可以縮短算法運行時間,提高本文算法的實時性.

表2 3 種算法運行時間的比較(單位:s)
最后我們比較了本文算法和文獻[5]和文獻[14] 在數據集benchmark data 中每幅圖片的平均誤匹配率(誤匹配對/匹配對),實驗結果如表3 所示.由表3 可知,本文算法的匹配對是最多的,誤匹配對是最少的,誤匹配率是最低的.這是因為相比較文獻[5]的相似性匹配及文獻[14]的kd-tree 匹配,本文算法采用PatchMatch算法進行匹配得到規則的偏移量,并且采用稠密線性擬合方法進行后處理降低誤匹配,具有很好的匹配效果.

表3 3 種算法誤匹配率的比較
5 結論與展望
本文提出了一種低頻快速切比雪夫矩的篡改圖像檢測算法.利用非抽樣小波變換分解圖像并提取其低頻部分,對于重疊塊提取其快速切比雪夫矩特征,PatchMatch 算法匹配塊特征,最后剔除誤匹配并定位其篡改區域.相比之前算法,F達到了92.0%,分別提高了3.5%和1.5%,本文算法對于單區域、單區域多次以及多區域的篡改均有很好的定位結果,并且有效地降低了運行時間,提高了算法的實時性,最后也降低了誤匹配率實現很好的匹配效果.后續工作將放在對篡改區域進行旋轉、加噪、壓縮以及模糊等處理的檢測及精確定位上.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
